我是想匯出豆瓣頁面的電影資訊
我的代碼:
import requests
from bs4 import BeautifulSoup
start=0
result=[]
header={"User-Agent":"Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/75.0.3770.100 Safari/537.36"}
for i in range(0,10):
html_1=requests.get("https://movie.douban.com/explore#!type=movie&tag=%E7%83%AD%E9%97%A8&sort=recommend&page_limit=20&page_"+str(start)+"=0",headers=header)
html_1.encoding="utf-8"
start+=25
soup=BeautifulSoup(html_1.text,"html.parser")
for item in soup.find_all("div","list-wp"):
item=item.div.a.p.string
print(item)
網頁部分源代碼:
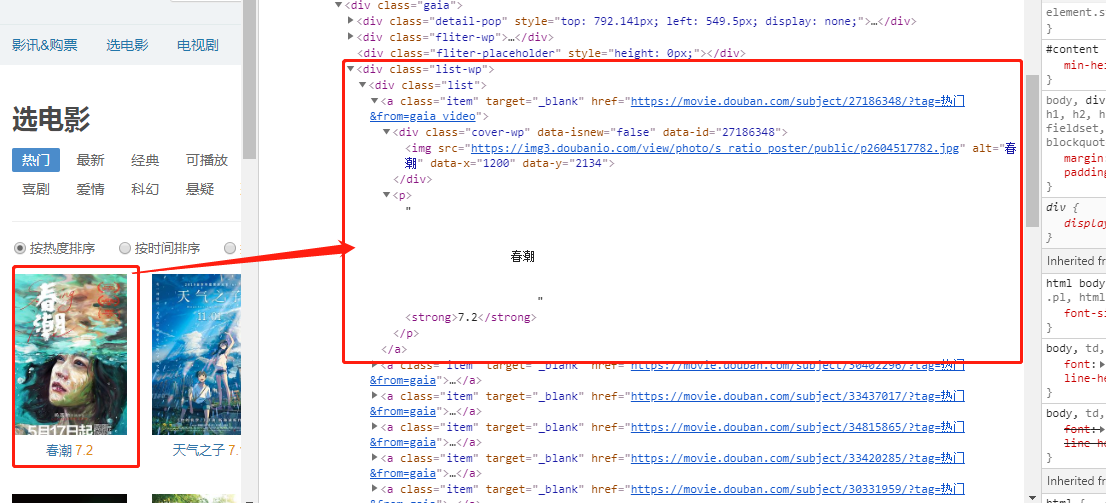
但執行就顯示:AttributeError: 'NoneType' object has no attribute 'p'。
如果我洗掉“p”,就變成了'NoneType' object has no attribute 'string'。
啊啊啊快瘋了
另外,我也發現有個奇怪的地方,我Google查看網頁源代碼時,是不顯示全部代碼,所以我就在檢查的element查看,截圖里的就是這個地方看的,難道是受這個影響么?~~求大神幫忙解答
轉載請註明出處,本文鏈接:https://www.uj5u.com/qita/41823.html
標籤:其他技術專區