我們以 fox新聞 網的文章來舉例子,把整篇文章爬取出來,
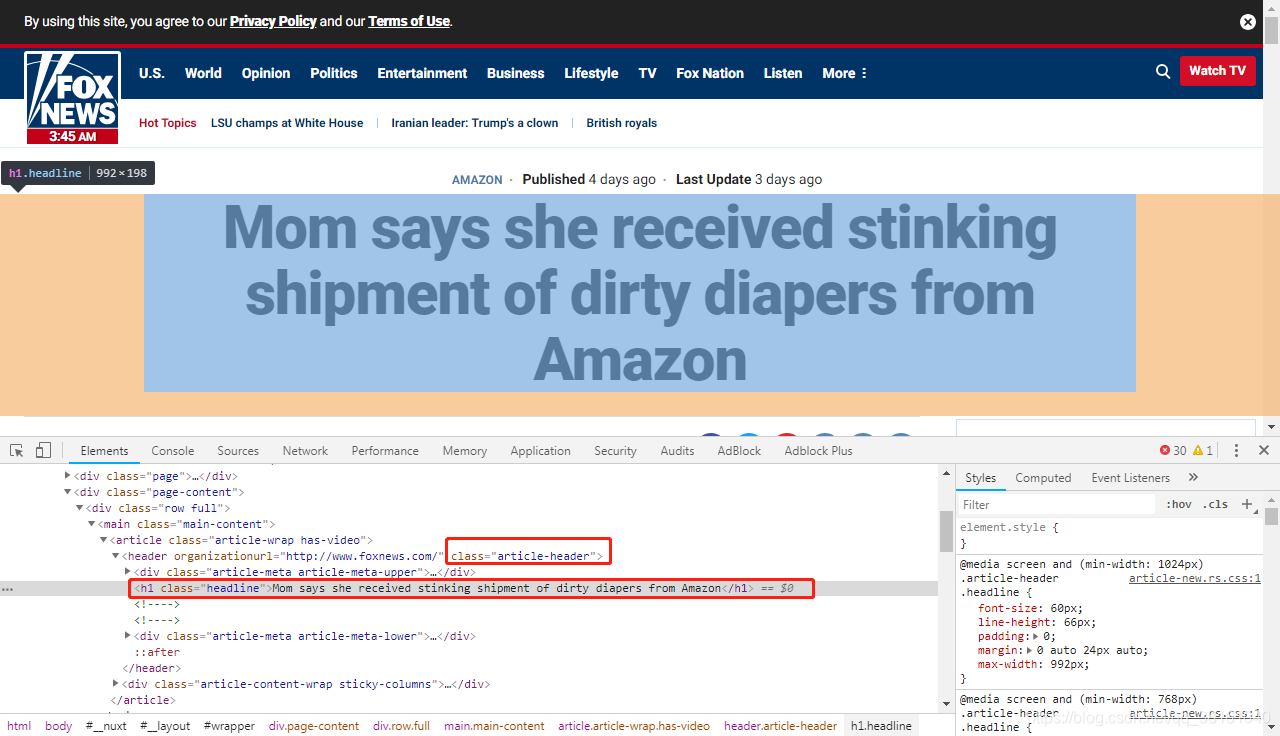
首先是標題,通過結構可以看出來 class 為 article-header 的節點下的 h1 里的內容即是標題,通過 string 可以獲取 dom 節點里的文本內容,
# 獲取文章標題
alert_header = soup.find('header', class_="article-header").find('h1')
print(alert_header.string)
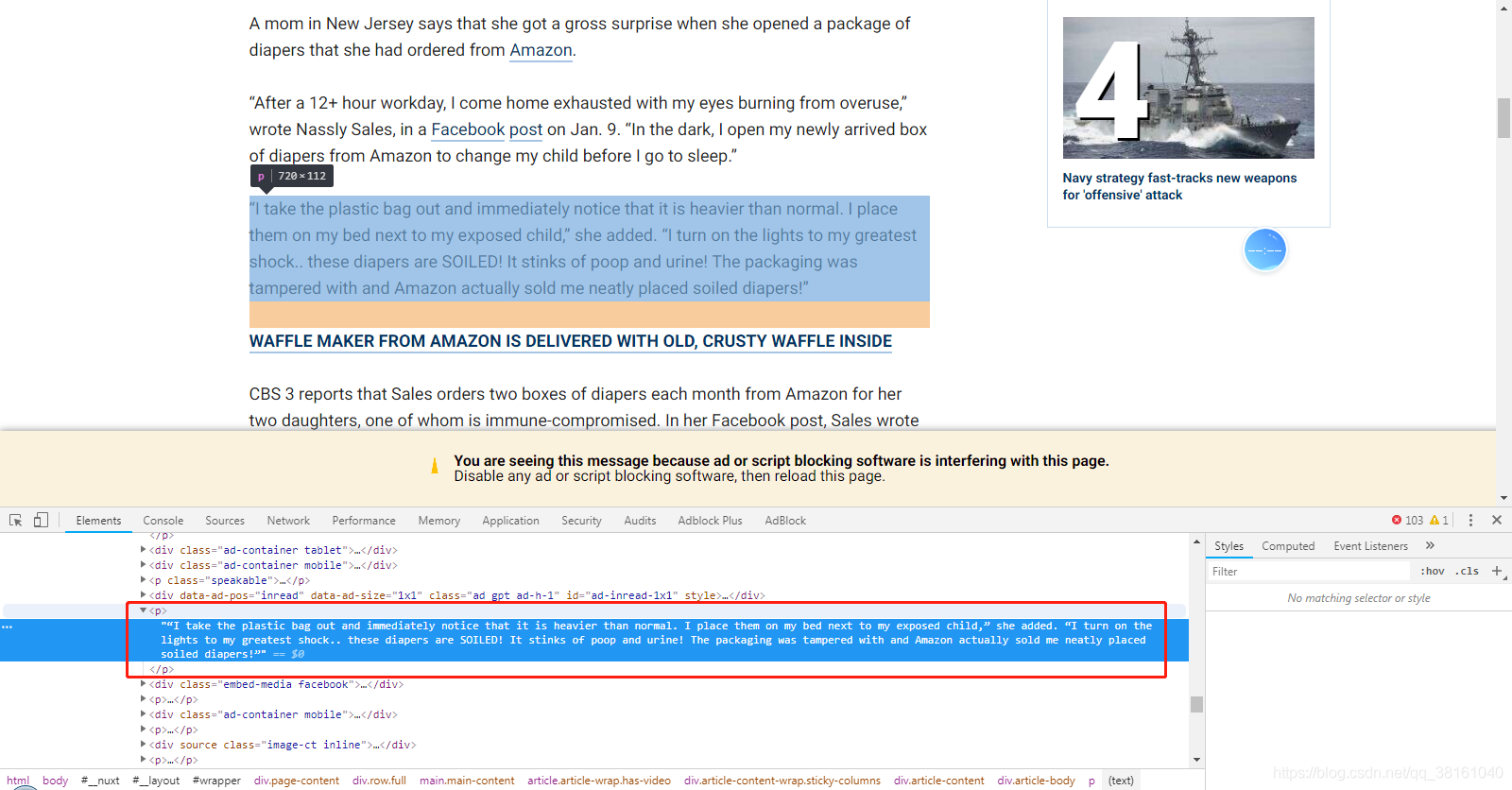
然后是正文,通過結構可以看出來 class 為 article-body 的節點下的 p 元素組成了正文內容,通過 contents 可以獲取 body 下所有的節點,再遍歷所有的節點,把所有 p 元素的下的內容列印出來,
from urllib.request import urlopen
from bs4 import BeautifulSoup
url = urlopen('https://www.foxnews.com/tech/mom-received-dirty-diapers-amazon')
soup = BeautifulSoup(url, 'html.parser') # parser 決議
# 獲取文章標題
alert_header = soup.find('header', class_="article-header").find('h1')
print("標題如下:")
print(alert_header.string)
# 獲取文章正文
alert_body = soup.find('div', class_="article-body").contents # 所有body里的p節點
# 列印文章正文
print("正文如下:")
for i in alert_body:
if(i.name == "p"):
print(i.getText())
print()
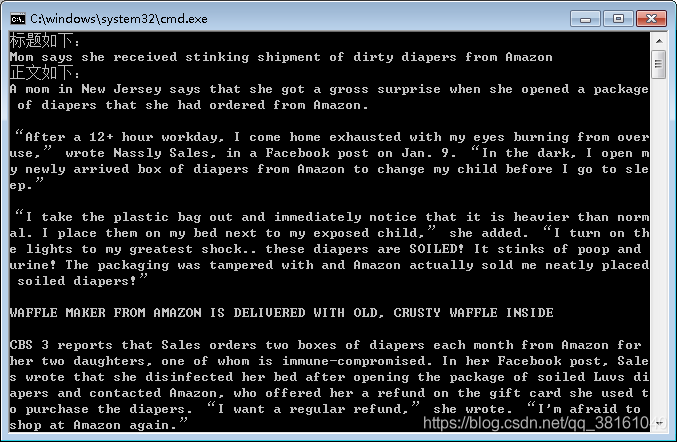
運行效果圖:
如果中間夾雜了廣告,可以看看文章正文跟廣告在結構上有什么區別,然后進一步把廣告剔除,
喜歡的點個贊?吧!
轉載請註明出處,本文鏈接:https://www.uj5u.com/qita/41826.html
標籤:其他
上一篇:Tensorflow (CPU)提取image和lable卡住的情況
下一篇:2020-09-10