專案:答題卡識別
github地址
github地址
解決程序如下
預處理
先對圖片進行Canny邊緣檢測,然后進行膨脹操作,膨脹操作的目的在于,如果紙張的外輪廓不是很明顯,Canny邊緣檢測后紙張
外輪廓不連續有小洞,使用膨脹操作填充小洞
處理的結果如下:
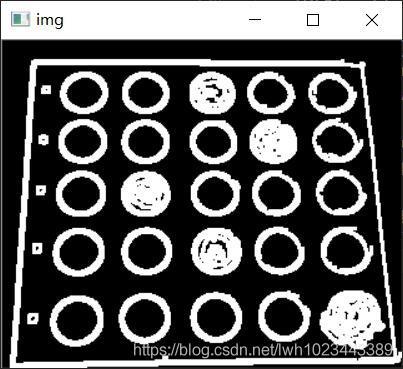
輪廓檢測
提取面積最大的輪廓MaxContour,并進行自適應輪廓近似,自適應輪廓近似中取epsilon = 0.0001 * 周長
具體代碼如下:
#步長設定為周長的0.0001倍,一般來說取epsilon = 0.001倍周長
step = 0.0001 * cv2.arcLength(cnts[0], True)
epsilon = step
#不斷遞增epsilon直到近似所得輪廓正好包含四個點
while len(cnt) != 4:
cnt = cv2.approxPolyDP(cnts[0], epsilon, True)
#步增epsilon
epsilon += step
處理結果如下:
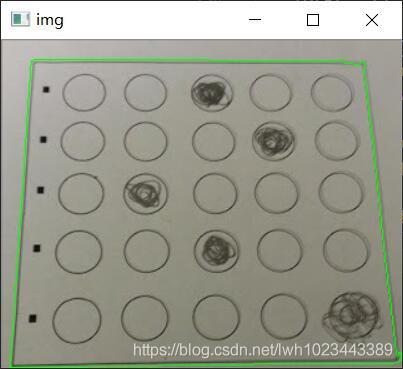
透視變換
透視變換前需要先進性預處理,把輪廓的四個點按照左上、右上、右下、左下的順序進行排序,排序部分代碼如下:
#將四個輪廓點排序
pts = np.zeros((4, 2), np.float32)
res = np.sum(points, axis=1)
pts[0] = points[np.argmin(res)]
pts[2] = points[np.argmax(res)]
res = np.diff(points, axis=1)
pts[1] = points[np.argmin(res)]
pts[3] = points[np.argmax(res)]
然后找到最大寬和最大高,具體代碼如下:
#計算邊長
w1 = np.sqrt((pts[0][0] - pts[1][0]) ** 2 + (pts[0][1] - pts[1][1]) ** 2)
w2 = np.sqrt((pts[2][0] - pts[3][0]) ** 2 + (pts[2][1] - pts[3][1]) ** 2)
w = int(max(w1, w2))
h1 = np.sqrt((pts[1][0] - pts[2][0]) ** 2 + (pts[1][1] - pts[2][1]) ** 2)
h2 = np.sqrt((pts[0][0] - pts[3][0]) ** 2 + (pts[0][1] - pts[3][1]) ** 2)
h = int(max(h1, h2))
進行完所有預處理之后,就可以開始我們最后也是最重要的一步——透視變換了,具體的代碼如下:
#目標四個點
dst = np.array([
[0, 0],
[w - 1, 0],
[w - 1, h - 1],
[0, h - 1]
], np.float32)
#透視變換
mat = cv2.getPerspectiveTransform(pts, dst)
paper1 = org1.copy()
paper1 = cv2.warpPerspective(paper1, mat, (w, h))
if show_process:
imshow(paper1)
運行結果如下:
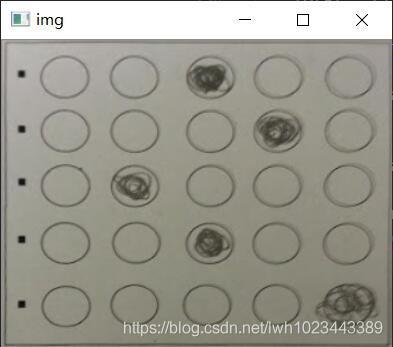
預處理
得到透視變換的圖片之后,也是先要進行預處理操作,首先為了消除不同圖片曝光程度不同的影響,需要先對圖片進行自適應直方圖均衡化
處理結果如下:
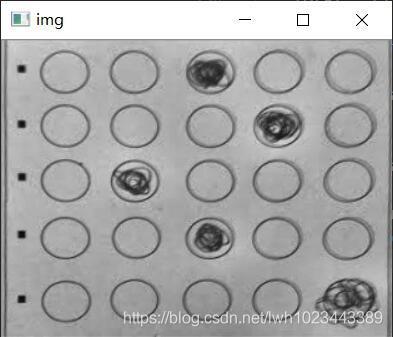
然后對圖片進行二值化,以便輪廓檢測,但進行完二值化的圖片還有一個問題,就是在涂答題卡的時候,如果沒有涂的飽滿,
就可能會造成檢測結果不準確,所以為了使檢測結果更加準確,還需要進行閉運算操作,處理后的結果如下:
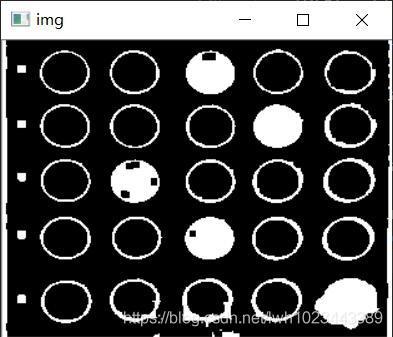
輪廓檢測 + 輪廓過濾
首先提取全部輪廓,結果如下:
可以看到提取到了很多輪廓,其中很多都是我們不需要的輪廓,于是我們需要使用一些過濾演算法,把我們需要的輪廓(25個橢圓)保留下來
這里的過濾演算法步驟如下所示:
- 首先獲得待檢測輪廓的外接圖形,如果是圓,則獲得輪廓的外接圓
- 然后可以按照面積過濾,當 輪廓面積 / 外接圖形面積 的比值
ratio滿足:ratio > 0.8 and ratio < 1.2時符合要求 - 然后可以按照周長過濾,當 輪廓周長 / 外接圖形周長 的比值
ratio滿足:ratio > 0.8 and ratio < 1.2時符合要求
具體的代碼比較復雜,如下:
#用于保存保留下來的輪廓
cntsex = []
#上下邊界閾值
thresh_lower = 0.8
thresh_upper = 1.2
eps = 1e-6
show = org1.copy()
for cnt in cnts:
cntcopy = cnt.copy()
#按照h方向坐標對輪廓的所有點排序,找到最大的y
cntcopy = sorted(cntcopy, key=lambda x: x[0][1], reverse=True)
maxy = cntcopy[0][0][1]
#按照w方向坐標對輪廓的所有點排序,找到最大的x
cntcopy = sorted(cntcopy, key=lambda x: x[0][0], reverse=True)
maxx = cntcopy[0][0][0]
#獲得橢圓的中心
(x, y), radius = cv2.minEnclosingCircle(cnt)
center = (int(x), int(y))
radius = int(radius)
#獲得橢圓的長軸和短軸
a = maxx - x
b = maxy - y
if b == 0:
continue
ratio = a / b;
if ratio > 2 or ratio < 0.5:
continue
if radius == 0:
continue
#面積過濾
areaex = np.pi * a * b
area = cv2.contourArea(cnt)
ratio = area / areaex
if ratio < thresh_upper and ratio > thresh_lower:
cntsex.append(cnt)
show = cv2.drawContours(show, [cnt], 0, (0, 255, 0), 1)
show = cv2.ellipse(show, center, (int(a), int(b)), 0, 0, 360, (0, 0, 255), 1)
在此之后我們就得到了所有比較像橢圓的輪廓,但是這還不夠,因為有一些用于裝訂的橢圓也被保留了下來,可以觀察到
這些用于裝訂的橢圓的特征是他們的面積比答題的橢圓要小得多,于是我們對所有輪廓進行排序,key = 輪廓的面積
然后將面積比較小的通過特定演算法過濾掉,具體代碼如下:
#第二次過濾
cnts = []
maxarea = -1e6
for cnt in cntsex:
area = cv2.contourArea(cnt)
if area > maxarea:
maxarea = area
maxgap = 0.5 * maxarea
cntsex = sorted(cntsex, key=lambda x: cv2.contourArea(x), reverse=True)
prvarea = cv2.contourArea(cntsex[0])
cnts.append(cntsex[0])
for i in range(1, len(cntsex)):
if abs(prvarea - cv2.contourArea(cntsex[i])) > maxgap:
break
cnts.append(cntsex[i])
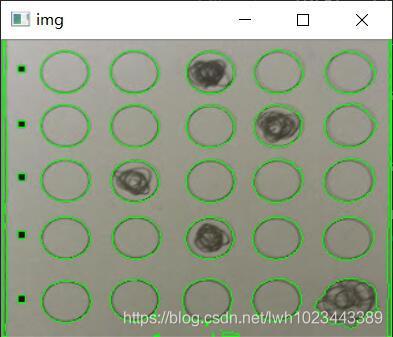
最后的處理結果如下:
排序 + 檢測
然后需要按照從上到下,從左到右的順序對輪廓進行排序,本程式在排序的同時完成檢測,具體的代碼如下:
#對多個輪廓按照從上到下的順序排序
cnts = sorted(cnts, key=lambda x: x[0][0][1])
rows = int(len(cnts) / 5)
TAB = ['A', 'B', 'C', 'D', 'E']
ANS = []
#檢查每一行(即每一題)的答案
for i in range(rows):
subcnts = cnts[i*5:(i+1)*5]
subcnts = sorted(subcnts, key=lambda x: x[0][0][0])
total = []
for (j, cnt) in enumerate(subcnts):
mask = np.zeros(paper1.shape, dtype=np.uint8)
cv2.drawContours(mask, [cnt], -1, 255, -1) #-1表示填充
mask = cv2.bitwise_and(paper1, paper1, mask=mask)
total.append(cv2.countNonZero(mask))
idx = np.argmax(np.array(total))
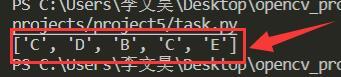
ANS.append(TAB[idx])
print(ANS)
處理結果如下:
轉載請註明出處,本文鏈接:https://www.uj5u.com/qita/41832.html
標籤:其他
上一篇:求大佬指點
下一篇:06.15 廢物日記第一篇