??網路爬蟲中,網路請求是基礎部分,沒有網路請求以及回應,網路爬蟲的后續資料分析也就失去了意義,Python中的網路請求,主要由Requests庫來完成,本篇,我們就來一起認識一下Requests庫及其基本使用方法,
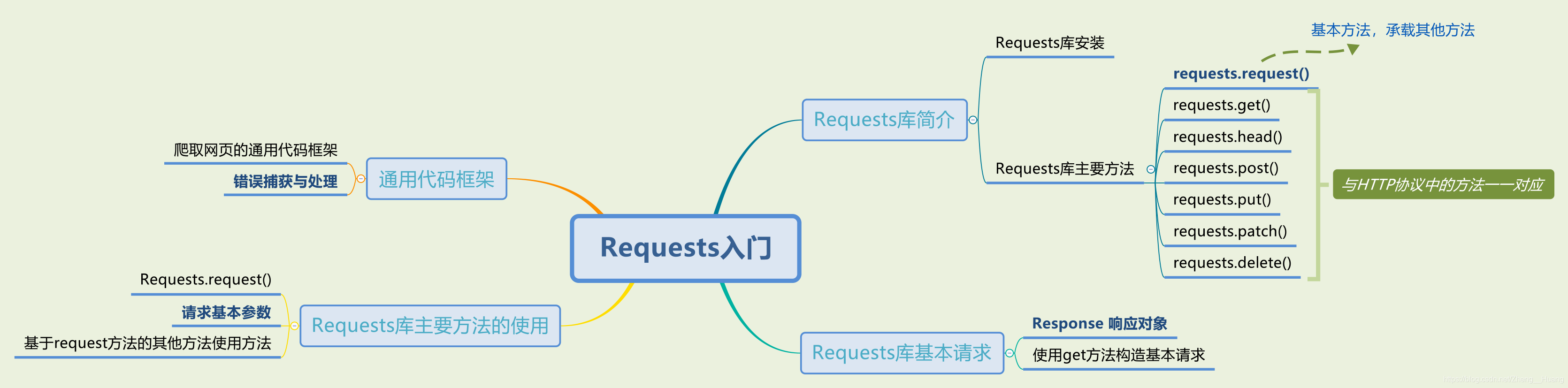
Requests庫簡介
??Requests庫是一個簡潔而優雅的Python第三方庫,更好地貼合人們的使用習慣,故在http類別庫中,Requests庫非常受開發者青睞,Requests庫支持Keep-Alive持久化連接、帶有Cookie的對話、SSL認證、動解碼、HTTP(S)代理支持、流下載、檔案分塊上傳等當今使用的諸多功能,其他功能介紹和說明檔案參見官方檔案,Requests: HTTP for Humans
?Requests庫的安裝
pip install requests
?Requests庫的主要方法
Requests庫主要有7個方法,大部分與HTTP(S)協議中的請求方法相同
| 方法 | 說明 |
|---|---|
| requests.request() | 構造一個請求以支撐以下各個方法 |
| requests.get() | 獲取資源的方法,同HTTP GET |
| requests.head() | 獲取資源回應頭部資訊的方法,同HTTP HEAD |
| requests.post() | 向網站提交post請求的方法,同HTTP POST |
| requests.put() | 向網站提交put請求的方法,同HTTP PUT |
| requests.patch() | 向網站提交patch區域修改請求,同HTTP PATCH |
| requests.delete() | 向網站提交洗掉資源請求,同HTTP DELETE |
-
另外,其他的HTTP方法requests庫也都支持,由于不常用就不一一列舉
-
實際上,所有的其他方法都是通過呼叫基本方法
requests.request()實作的
使用Requests庫構造基本請求
??網頁訪問中最常用的請求方法是GET方法,下面我們就使用GET方法構造一個基本的請求,
?Requests.get()方法
通過以下代碼
r = requests.get(url)
#url是一個字串型變數,保存了要請求資源的URL
Requests庫構造了一個向服務器請求資源的Request請求物件,該命令回傳的結果是一個包含服務器資源的Response回應物件r
Requests.get()方法的完整使用格式
requests.get(url,params=None,**kwargs)
其中:
- url: 想要請求的資源的
URL,統一資源定位符 - params: 可選,默認為None,表示在url中的額外引數,可以是字典或位元組流格式,
- **kwargs: 可選,12個控制訪問的引數,見下
實際上,requests.get()方法呼叫了requests.request()方法,封裝前代碼如下
requests.request('get',url,params=params,**kwargs)
get方法將params引數作為含有默認引數的關鍵字引數單獨列出,所以,requests.request()方法一共有13個引數(包含params),以字典方式讀入,
?Response回應物件
上述請求回傳了一個Response回應物件,包含了從服務器回傳的資源相關資訊,主要具有如下屬性
| 屬性 | 說明 |
|---|---|
| r.status_code | HTTP請求回傳狀態碼 |
| r.text | HTTP回應內容(字串形式) |
| r.encoding | 由HTTP header得到的回應主體編碼方式,也為當前物體編碼方式(也可以通過后期配置) |
| r.apparent_encoding | 從回應主體中分析得到的編碼方式(備選) |
| r.content | HTTP回應內容的二進制形式 |
?使用get方法構造請求
下面用一個樣例來說明如何使用requests.get()方法構造一個get請求,以訪問百度為例
r = requests.get("https://www.baidu.com")
查看回應物件的編碼資訊
#每一行后的注釋內容為回傳值
r.encoding
#'ISO-8859-1'
r.apparent_encoding
#'utf-8'
實際上,從回應頭部欄位中得到的主體編碼格式(事實上,回應頭部沒有指定編碼格式時,默認格式即為ISO-8859-1)是錯誤的(無法正確顯示中文),需要自己調整·r.encoding為其主體實際編碼utf-8,才能正確顯示中文
正確設定主體的編碼格式后,就可以正確得到回應的主體內容,另外還可獲取回應頭部資訊等
爬取網頁的通用代碼框架
??通用代碼框架是用來爬取網頁的一段通用代碼,通過對爬取網頁的通用代碼框架的定制可以可靠而靈活地爬取網頁內容,也能夠獲得通向其他頁面的鏈接,在使用requests.get()方法訪問網頁時難免會拋出例外,所以在學習通用代碼框架前還要了解Requests庫的例外資訊以及處理方法,
?Requests庫的例外處理
??使用Requests庫發送請求時可能會收到來自各個環節的各種例外,若不加以處理,可能會導致程式例外終止,所以認識和處理例外是爬蟲開發中必需的環節,
| 例外 | 說明 |
|---|---|
| requests.ConnectionError | 網路連接錯誤,如無法建立連接、DNS決議錯誤、連接被拒絕(非4xx回應代碼)等 |
| requests.HTTPError | HTTP錯誤例外(需要手動拋出,見注釋) |
| requests.URLRequired | 缺失URL例外 |
| requests.TooManyRedirects | 回應的重定向超過閾值,產生重定向例外 |
| requests.ConnectTimeout | 服務器連接超時例外 |
| requests.Timeout | 請求超時(非連接超時,指連接后的請求階段超時) |
- 其中,
ConnectionError指在網路TCP層產生的例外,這類例外會強制終止程式;而HTTPError指在HTTP協議(應用層)產生的例外,使用r.raise_for_status()方法手動拋出例外,只要回傳代碼非200,就會拋出這個例外,
?通用代碼框架
import requests
def get_uri(url):
try:
r = requests.get(url, allow_redirects=False)
r.raise_for_status()
r.encoding = r.apparent_encoding
return r.text
except:
return "An error has been thrown"
print("Requests.get Skeleton")
print(get_uri("http://192.168.0.6:8080/a"))
- 示例中的
get_uri函式即為封裝完成的簡單爬蟲通用代碼框架 - 示例中,服務器回傳了404錯誤,被
raise_for_status()方法捕獲;若將示例中的url改為一個不存在的服務器或非法url,不需要該陳述句也會直接拋出錯誤,在經過try-except陳述句的例外捕獲后,程式不會退出,而可以進行下一步程式內錯誤提示與處理, - 如果將示例中的url改為真實存在的,則會直接輸出網頁源代碼,可以通過進一步操作決議處理,
- 對except陳述句捕獲條件的更精確定義可以區分不同的錯誤,從而對不同錯誤定制不同的解決辦法
Requests庫主要方法的使用
?request基本方法與引數
首先介紹一下Requests庫的基本方法——Requests.request()方法,Requests庫中的其他主要請求方法都是通過呼叫Requests.request()方法完成的
requests.request('Method', url, **kwargs)
其中
Method為指定的方法名稱url為請求的目標資源統一識別符號**kwargs為請求附加的其他引數,其他所有基于requests.request()的方法引數與其相同,有部分方法可能將部分常用引數作為關鍵字引數顯式定義,沒有較大影響
| 引數 | 說明 |
|---|---|
| params | 作為引數加入到要訪問的url鏈接中 |
| data | 作為Request報文主題內容,以表單形式傳送,可以為字典,元組等 |
| json | json格式的Request報文內容 |
| headers | 較常用,定義了Request報文的請求頭部引數,可以為字典 |
| cookies | HTTP Request中的cookie資訊,可為字典、CookieJar或Request中的Cookie |
| auth | 用于HTTP協議認證,為元組 |
| files | Request報文主體(以檔案形式),為字典,字典的Key為檔案型別變數 |
| timeout | 設定Request的超時時間,單位為秒 |
| proxies | 設定訪問的代理服務器,為字典,分別為協議指定代理服務器 |
| allow_redirects | 允許重定向,boolean型,默認True,允許重定向 |
| stream | 流下載(獲取內容立即下載),boolean型,默認True,允許流下載 |
| verify | SSL認證證書開關,默認True,使用SSL認證證書 |
| cert | 本地的SSL證書路徑 |
-
注意:data引數是將引數加入Request報文中,而params引數是將引數加入要訪問的url鏈接中,比如,params={‘a’: 1},url=
'https://www.baidu.com/',最后請求生成的url為'https://www.baidu.com/?a=1' -
headers是一個常用引數,用于定義請求報文的頭部資訊,接受字典形式的資料,如果未經定義,會輸出默認引數
{'User-Agent': 'python-requests/2.24.0', 'Accept-Encoding': 'gzip, deflate', 'Accept': '*/*', 'Connection': 'keep-alive'} -
files引數示例
files = {'file1': open('data.xls', 'rb')} r = requests.post{'https://192.168.0.6:8080/post', files=files} -
proxies示例
proxies = {'http': 'http://192.168.0.4', 'https': 'https://192.168.0.5'}
關于get方法,上文已經做過講解,本段中不再重復贅述,下面介紹一些其他的requests庫方法
?Requests.post()方法
Requests.post()方法通過HTTP協議的post方法向服務器傳遞資料,關于HTTP中的post方法請讀者自行了解,下面僅介紹Requests.post()方法的具體使用
post方法的封裝
def post(url, data=None, json=None, **kwargs):
r"""Sends a POST request.
:param url: URL for the new :class:`Request` object.
:param data: (optional) Dictionary, list of tuples, bytes, or file-like
object to send in the body of the :class:`Request`.
:param json: (optional) json data to send in the body of the :class:`Request`.
:param \*\*kwargs: Optional arguments that ``request`` takes.
:return: :class:`Response <Response>` object
:rtype: requests.Response
"""
return request('post', url, data=data, json=json, **kwargs)
可以看到,post方法將data和json引數單獨列出,分別表示post請求主體內容(以web表單形式編碼)和以json格式編碼的主體內容,以web表單形式編碼的條件為data是一個字典;如果想要發送未經編碼的資料(不要默認web表單編碼),則直接以字串作為data
下面三個示例分別用web表單格式、json格式和****作為post方法的請求主體,后附服務器收到資訊(節選)
payload = {'b': 2}
r = requests.post("http://192.168.0.6:8080/post", data=payload)
import json
payload = {'b': 2}
r = requests.post("http://192.168.0.6:8080/post", json=json.dumps(payload))
r = requests.post("http://192.168.0.6:8080/post", data="b=2")
{"args":{},"data":"\"{\\\"b\\\": 2}\"","files":{},"form":{},"headers":{"Content-Length":"12","Content-Type":"application/json"},"json":"{\"b\": 2}",}
{"args":{},"data":"","form":{"b":"2"},"headers":{"Content-Length":"3","Content-Type":"application/x-www-form-urlencoded"},"json":null}
{"data":"b=2","headers":{"Content-Length":"3"},"json":null}
-
在發送未經編碼的請求物體時,首部欄位中不存在
Content-Type如果以元組作為
data,將同樣以web表單形式編碼,但是如果當個元組使用同一個key的時候,使用元組可以避免字典中鍵名稱重復的問題
payload = (('b', 1), ('b', 2))
r = requests.post("http://192.168.0.6:8080/post", data=payload)
#下面是服務器收到的主體內容
"form":{"b":["1","2"]}
?Requests.put()方法
HTTP協議中put方法與post方法基本類似,只是使用put方法時會將該url下原有資料覆寫,而post方法只是新增一個資料,在Requests庫中兩個方法的格式幾乎相同,這里就不再贅述,
?Requests.patch()方法
于HTTP協議中的patch方法類似,用法類似于Requests.put(),區別在于patch僅提供需要修改的部分資料,而put需要提交在該url下的全部資料,
?Requests.delete()方法
與HTTP協議中的delete方法類似,能夠請求服務器洗掉url所指定的資源,可能需要在請求引數中加入認證資訊,
?Requests.head()方法
與HTTP協議中的head方法類似,用法類似于Requests.get()方法,區別僅在于回傳報文中只有頭部資訊而沒有主體,
轉載請註明出處,本文鏈接:https://www.uj5u.com/qita/41843.html
標籤:其他
上一篇:富士通DX90_S2更換硬碟流程