為啥那個網頁打不開?
uj5u.com熱心網友回復:
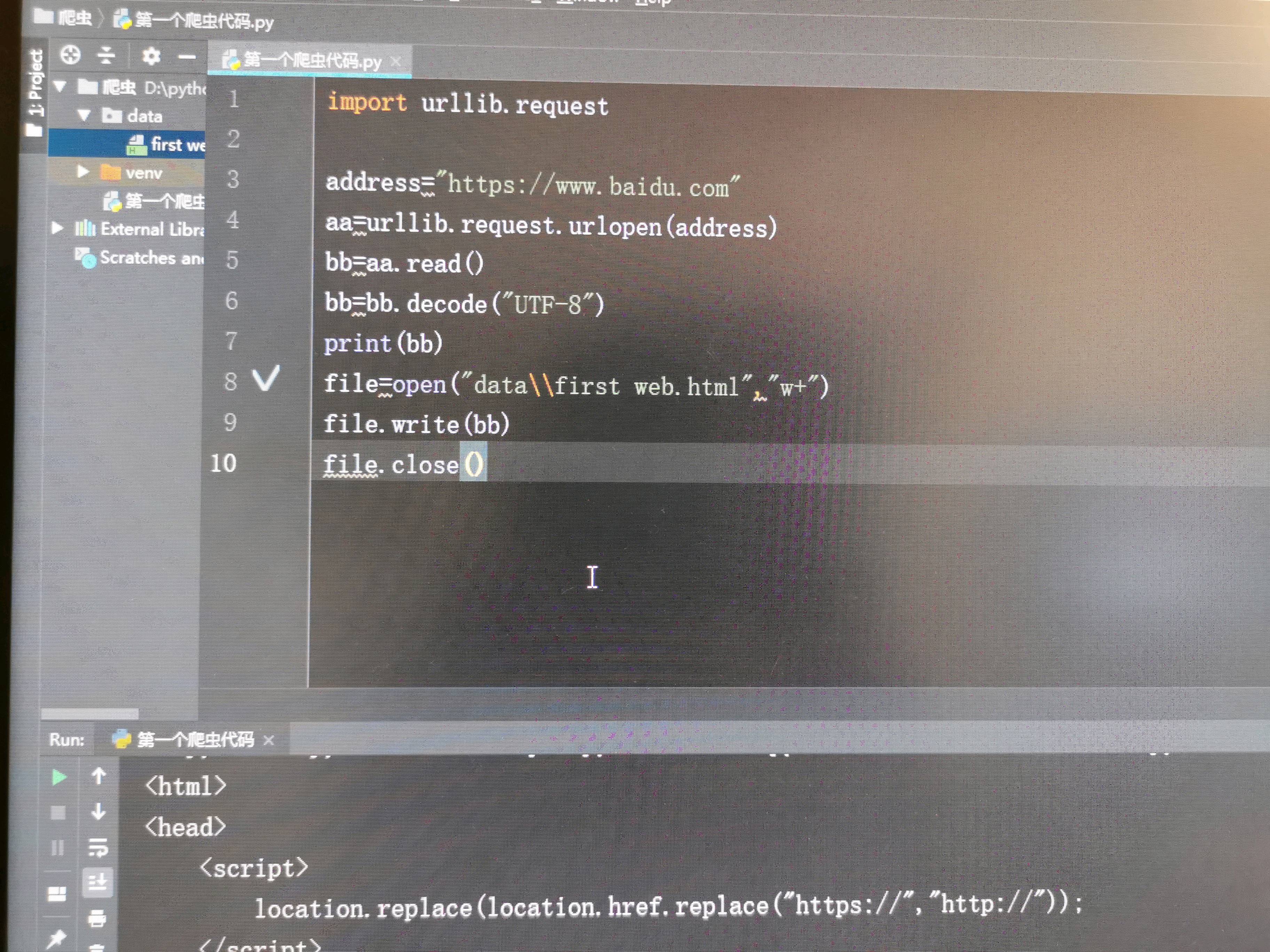
你是不是想把爬取的內容存盤到一個.html的檔案里面,可是你的那個檔案路徑有問題啊!要么寫絕對路徑,要么寫相對路徑啊!你的那樣好像寫錯了吧!uj5u.com熱心網友回復:
這個應該能用,我試過幾個其他的網址,新浪搜狗可以,百度打不開,就一直轉。
uj5u.com熱心網友回復:
我好像沒有理解你到底要講什么,一開始
uj5u.com熱心網友回復:
就是把網站的首頁 寫到一個網頁檔案里面然后用瀏覽器打開,有幾個能打開,有幾個就不能打開
uj5u.com熱心網友回復:
喔喔,原來是這樣uj5u.com熱心網友回復:
百度這個網址好像需要添加一個請求頭,不然爬到的內容沒有實際的那么多,不過,打開這個網頁后實作不了搜索uj5u.com熱心網友回復:
建議是requests 請求連接
import requests
url = "https://www.baidu.com/"
res = requests.get(url)
print(res.status_code)
print(res.text)
轉載請註明出處,本文鏈接:https://www.uj5u.com/qita/41889.html
上一篇:大佬們給指點一下唄