from selenium import webdriver
from bs4 import BeautifulSoup
import openpyxl
import time
# from selenium.webdriver.common.keys import Keys
# 初始化瀏覽器
browser = webdriver.Chrome('chromedriver_win32/chromedriver.exe')
# 結構化資料串列
position_list = []
def get_position_list(url):
browser.get(url)
#huoq獲取網頁原始碼
html_doc = browser.page_source
#使用beautisoup決議網頁結構,轉成soup物件
soup = BeautifulSoup(html_doc,'html.parser')
#print(soup.title)
#定位元素,提取關鍵資訊
#獲取所有條目 li
# div_docs = soup.select('.el')
#li_doc = li_docs[0]
all_list1 = {}
def get_job_info():
all_list = browser.find_element_by_id("resultList").find_elements_by_class_name("el")
#結構化資料串列
position_list = []
# 遍歷當前頁所有條目
for div_doc in all_list[1:]:
# print(li_doc.attrs)
# 資料清洗,結構化
position = {}
# 獲取li標簽的屬性值
# attrs = div_doc.attrs
position['positionname'] = div_doc.select_one('.t1').find('a').string
position['company'] = div_doc.select_one('.t2').find('a').string
position['district'] = div_doc.select_one('.t3').string
position['salary'] = div_doc.select_one('.t4').string
position['public_date'] = div_doc.select_one('.t5').string
position_list.append(position)
# print(position_list)
return position_list
return all_list1
# 保存至Excel
# 打開Excel
wb = openpyxl.Workbook()
# 定位到當前表格
ws = wb.active
# 設定表頭
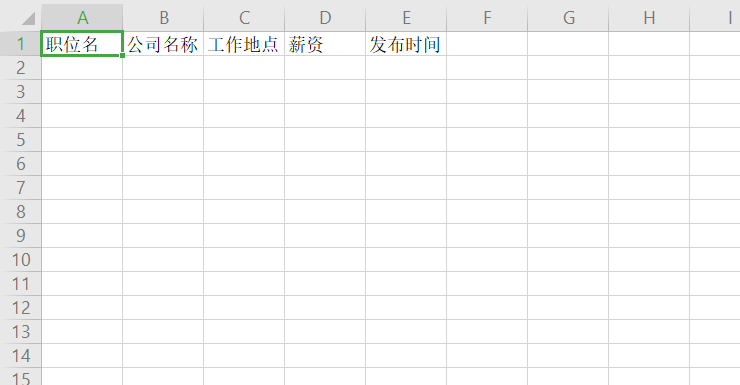
head_row = ['職位名',
'公司名稱',
'作業地點',
'薪資',
'發布時間',
]
ws.append(head_row)
#翻頁,獲取所有資料
for i in range(1,21):
print('正在爬取第{0}頁'.format(i))
# 打開目標網站,python搜索結果頁
url = 'https://search.51job.com/list/070300,000000,0000,00,9,99,python,2,{0}.html?'.format(i)
# list = get_position_list(url)
browser.get(url) #打開網站
# print(list)
for position in position_list:
data_row = [
position['positionname'],
position['company'],
position['district'],
position['salary'],
position['public_data'],
]
ws.append(data_row)
#爬取一頁,等待3秒,爬取下一頁
time.sleep(3)
# 保存Excel
wb.save('前程無憂職位資料采集.xlsx')
#關閉瀏覽器
print('程式已結束')
browser.close()
uj5u.com熱心網友回復:
uj5u.com熱心網友回復:
問題有點多啊你這,處理函式都沒呼叫起來?怎么獲取資料呢,只是個跑了個列印回圈,還有處理函式get_position_list也不用嵌套函式啊啊,兩處public_date 下面是public_data 一個e 一個auj5u.com熱心網友回復:
# -*- coding:utf-8 -*-
from selenium import webdriver
from bs4 import BeautifulSoup
import openpyxl
import time
browser = webdriver.Chrome(r'D:\chromedriver_win32\chromedriver.exe')
# 結構化資料串列
def get_position_list(url):
browser.get(url)
html_doc = browser.page_source
soup = BeautifulSoup(html_doc,features='lxml')
all_list = soup.find('div','dw_table').find_all('div','el')
position_list = []
for div_doc in all_list[1:]:
position = {}
position['positionname'] = div_doc.select_one('.t1').find('a').string.strip()
position['company'] = div_doc.select_one('.t2').find('a').string.strip()
position['district'] = div_doc.select_one('.t3').string.strip()
position['salary'] = div_doc.select_one('.t4').string
position['public_date'] = div_doc.select_one('.t5').string.strip()
position_list.append(position)
return position_list
wb = openpyxl.Workbook()
# 定位到當前表格
ws = wb.active
# 設定表頭
head_row = ['職位名',
'公司名稱',
'作業地點',
'薪資',
'發布時間',
]
ws.append(head_row)
for i in range(1,3):
print('正在爬取第{0}頁'.format(i))
# 打開目標網站,python搜索結果頁
url = 'https://search.51job.com/list/070300,000000,0000,00,9,99,python,2,{0}.html?'.format(i)
list = get_position_list(url)
for position in list:
data_row = [
position['positionname'],
position['company'],
position['district'],
position['salary'],
position['public_date']
]
ws.append(data_row)
#爬取一頁,等待3秒,爬取下一頁
time.sleep(3)
# 保存Excel
wb.save('前程無憂職位資料采集.xlsx')
#關閉瀏覽器
print('程式已結束')
browser.quit()
這個版本能用,問題都搞了
轉載請註明出處,本文鏈接:https://www.uj5u.com/qita/41893.html
上一篇:匯編編程
下一篇:關于python坐標檢索