https://b-ok.cc/book/705673/1dadbc
我想用python代碼下載這個網頁上的書,查看源代碼,下載鏈接是
href="https://bbs.csdn.net/dl/705673/bea2bd"
點進去可以下載
可是我python代碼爬取得到的是
"/dl/705673/19017a
并不能下載檔案
代碼如下
headers={
"User-Agent":"Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/78.0.3904.108 Safari/537.36"
}
response = requests.get(url,headers = headers)
print(response.headers)
#print(response.content)
soup = BeautifulSoup(response.content,"lxml")
print(soup)
用F12看了一下,當我點擊下載的時候,會出現下圖
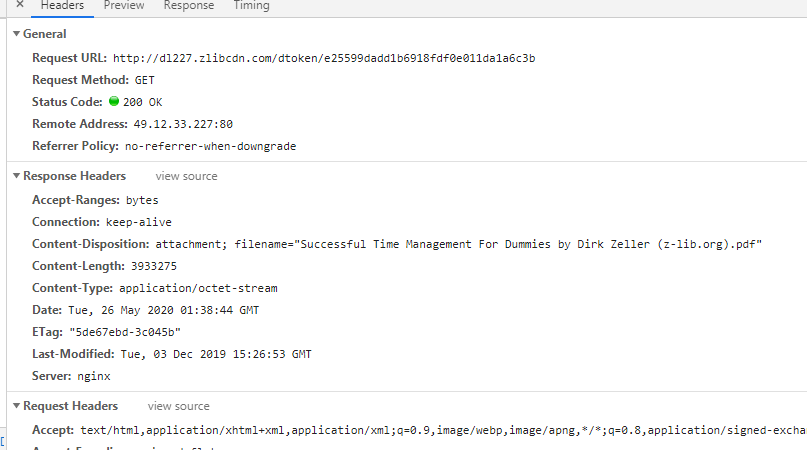
試了一下,里面的url打開就是下載
http://dl219.zlibcdn.com/dtoken/04a9c8e8420fa472c6301b70c2afeb75
但是每次點擊下載,URL都不一樣
請教各位大神怎么解決?
uj5u.com熱心網友回復:
你都爬取到鏈接了 ,你爬到的鏈接其實是不全的,你F12,滑鼠放到鏈接上就能看到鏈接前面要補齊一部分才是正常下載鏈接。你都爬到了,再多做一步處理就好了
uj5u.com熱心網友回復:
把url前半部分加上就可以了嘛uj5u.com熱心網友回復:
鏈接可能不全,你加上一起的轉載請註明出處,本文鏈接:https://www.uj5u.com/qita/41914.html
上一篇:安卓APP的http訪問權限
下一篇:android.media.MediaCodec$CodecException: Error 0xfffffc0e