自從突破性的 Fermi 架構發布近 5 年以來,可能是時候重繪其下的主要圖形架構了,Fermi 是第一個實作完全可擴展圖形引擎的 NVIDIA GPU,其核心架構可以在 Kepler 和 Maxwell 中找到,下面的文章,尤其是下面的“壓縮管道知識”圖片應該作為基于各種公共材料的入門,例如關于 GPU 架構的白皮書或 GTC 教程,本文重點關注 GPU 作業原理的圖形觀點,盡管一些原則(例如著色器程式代碼如何執行)對于計算來說是相同的,
- 費米白皮書
- 開普勒白皮書
- 麥克斯韋白皮書
- Fermi GF100 上的快速鑲嵌渲染
- 編程指南及其背后的 GPU 架構原因
管道架構圖

GPU 是超級并行作業分配器
為什么這么復雜?在圖形中,我們必須處理產生大量可變作業負載的資料放大,每個drawcall可能會生成不同數量的三角形,裁剪后的頂點數量與我們最初的三角形不同,在背面和深度剔除之后,并非所有三角形都需要螢屏上的像素,三角形的螢屏尺寸可能意味著它需要數百萬像素或根本不需要,
因此,現代 GPU 讓它們的基元(三角形、線、點)遵循邏輯流水線,而不是物理流水線,在 G80 統一架構之前(想想 DX9 硬體、ps3、xbox360)之前,流水線在芯片上以不同的階段表示,作業會一個接一個地運行,G80 本質上為頂點和片段著色器計算重用了一些單元,具體取決于負載,但它仍然有一個用于基元/光柵化等的串行程序,借助 Fermi,流水線變得完全并行,這意味著芯片通過重用芯片上的多個引擎來實作邏輯流水線(三角形經過的步驟),
假設我們有兩個三角形 A 和 B,他們的部分作業可能在不同的邏輯流水線步驟中,A 已經被轉換并且需要被光柵化,它的一些像素可能已經在運行像素著色器指令,而其他像素則被深度緩沖區(Z-cull)拒絕,其他像素可能已經被寫入幀緩沖區,有些可能實際上正在等待,除此之外,我們可以獲取三角形 B 的頂點,因此,雖然每個三角形都必須經過邏輯步驟,但它們中的許多可以在其生命周期的不同步驟中被主動處理,作業(在螢屏上獲取 drawcall 的三角形)被分成許多較小的任務,甚至可以并行運行的子任務,每個任務都計劃到可用的資源,
想象一條呈扇形散開的河流,并行管道流,彼此獨立,每個人都在自己的時間線上,有些可能比其他分支更多,如果我們根據三角形對 GPU 的單元進行顏色編碼,或者它當前正在處理的 drawcall,它將是多色閃爍燈 :)
GPU架構

由于 Fermi NVIDIA 具有類似的原理架構,有一個Giga Thread Engine管理所有正在進行的作業,GPU 被劃分為多個GPC(圖形處理集群),每個 GPC 具有多個SM(流式多處理器)和一個Raster Engine,在這個程序中有很多互連,最顯著的是允許跨 GPC 或其他功能單元(如ROP(渲染輸出單元)子系統)遷移作業的Crossbar ,
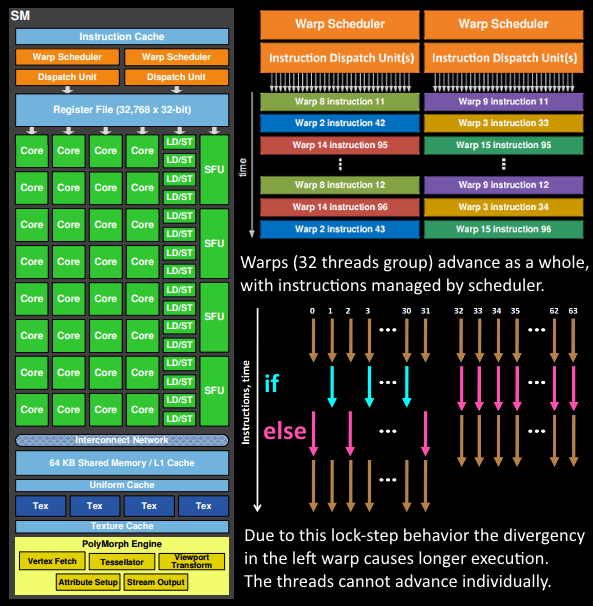
程式員想到的作業(著色器程式執行)是在 SM 上完成的,它包含許多對執行緒進行數學運算的核心,例如,一個執行緒可以是頂點著色器或像素著色器呼叫,這些核心和其他單元由Warp 調度程式驅動,它們管理一組 32 個執行緒作為 warp 并將要執行的指令交給調度單元,代碼邏輯由調度程式處理,而不是在內核本身內部,它只會看到類似“將暫存器 4234 與暫存器 4235 相加并存盤在 4230 中”的內容從調度員,與核心非常智能的 CPU 相比,核心本身相當愚蠢,GPU 將智能提升到更高的水平,它執行整個集成(或多個,如果你愿意的話)的作業,
這些單元中有多少實際上在 GPU 上(每個 GPC 有多少個 SM,多少個 GPC..)取決于芯片配置本身,正如您在上面看到的,GM204 有 4 個 GPC,每個 4 個 SM,但 Tegra X1 有 1 個 GPC 和 2 個 SM,兩者都采用 Maxwell 設計,SM 設計本身(核心數量、指令單元、調度程式......)也隨著時間的推移而發生了變化(見第一張圖片),并幫助芯片變得如此高效,它們可以從高端臺式機擴展到筆記本電腦移動的,
邏輯管道
為簡單起見,省略了一些細節,我們假設 drawcall 參考了一些索引和頂點緩沖區,這些緩沖區已經填充了資料并存在于 GPU 的 DRAM 中,并且僅使用頂點和像素著色器(GL:fragmentsshader),
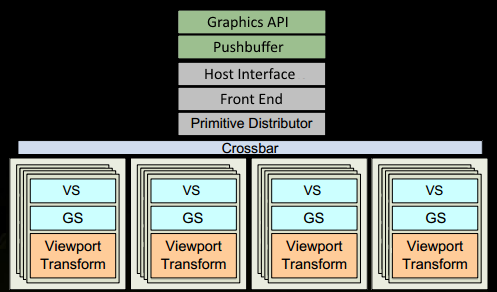
- 該程式在圖形 api(DX 或 GL)中進行繪制呼叫,這會在某個時候到達驅動程式,該驅動程式會進行一些驗證以檢查事情是否“合法”,并將命令插入到pushbuffer內的 GPU 可讀編碼中,在 CPU 方面可能會發生很多瓶頸,這就是為什么程式員使用好 api 以及利用當今 GPU 的強大功能的技術很重要的原因,
- 在一段時間或明確的“重繪”呼叫之后,驅動程式已經在 pushbuffer 中緩沖了足夠的作業并將其發送給 GPU 處理(作業系統的一些參與),GPU的主機介面接收通過前端處理的命令,
- 我們通過處理 indexbuffer 中的索引并生成我們發送到多個 GPC 的三角形作業批次,在Primitive Distributor中開始我們的作業分配,
- 在 GPC 中,其中一個 SM 的Poly Morph Engine負責從三角形索引 ( Vertex Fetch ) 中獲取頂點資料,
- 獲取資料后,32 個執行緒的 warp 被安排在 SM 內,并將在頂點上作業,
- SM 的 warp 調度程式按順序發出整個 warp 的指令,執行緒以鎖步方式運行每條指令,如果它們不應該主動執行它,可以單獨屏蔽,需要這種掩蔽可能有多種原因,例如,當當前指令是“if (true)”分支的一部分并且執行緒特定資料評估為“false”時,或者當一個執行緒達到回圈的終止標準但另一個執行緒未達到時,因此,在著色器中有大量分支發散會顯著增加扭曲中所有執行緒所花費的時間,執行緒不能單獨前進,只能作為經線!然而,經線是相互獨立的,
- warp 的指令可能會一次完成,也可能需要幾個調度輪次,例如,與執行基本數學運算相比,SM 通常具有更少的加載/存盤單元,
- 由于某些指令比其他指令需要更長的時間來完成,尤其是記憶體加載,warp 調度程式可能會簡單地切換到另一個不等待記憶體的 warp,這是 GPU 如何克服記憶體讀取延遲的關鍵概念,它們只是切換活動執行緒組,為了使這種切換非常快,調度程式管理的所有執行緒在暫存器檔案中都有自己的暫存器,著色器程式需要的暫存器越多,執行緒/扭曲的空間就越少,我們可以在之間切換的扭曲越少,在等待指令完成(最重要的記憶體獲取)時我們可以做的有用作業就越少,
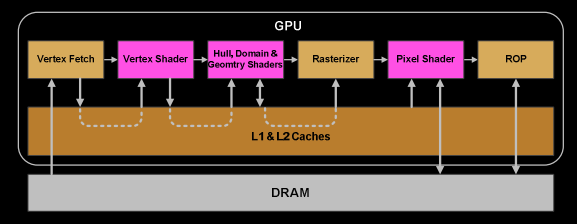
- 一旦扭曲完成了頂點著色器的所有指令,它的結果將由Viewport Transform處理,三角形被裁剪空間體積裁剪并準備好進行光柵化,我們對所有這些跨任務通信資料使用 L1 和 L2 快取,
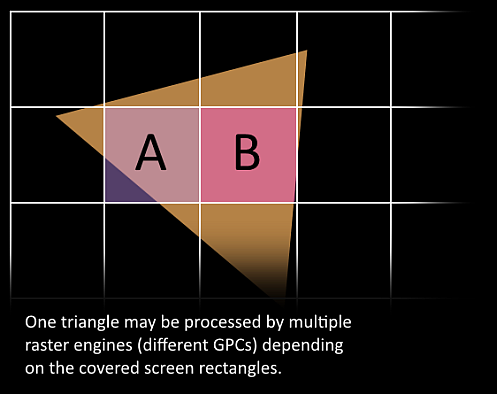
- 現在它變得令人興奮,我們的三角形即將被切碎,并可能離開它目前所在的 GPC,三角形的邊界框用于決定哪些光柵引擎需要對其進行處理,因為每個引擎都覆寫了螢屏的多個圖塊,它通過Work Distribution Crossbar將三角形發送到一個或多個 GPC ,我們現在有效地將我們的三角形分割成許多較小的作業,
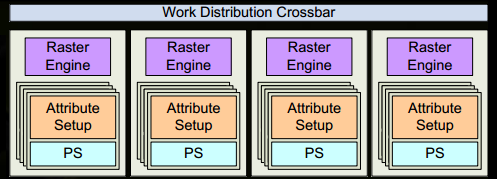
- 目標 SM 的屬性設定將確保插值(例如我們在頂點著色器中生成的輸出)采用像素著色器友好格式,
- GPC的光柵引擎處理它接收到的三角形,并為它負責的那些部分生成像素資訊(還處理背面剔除和 Z 剔除),
- 我們再次批量處理 32 個像素執行緒,或者更好地說是 8 次 2x2 像素四邊形,這是我們在像素著色器中始終使用的最小單元,這個 2x2 四邊形允許我們計算諸如紋理 mip 映射過濾之類的導數(四邊形內紋理坐標的大變化會導致更高的 mip),2x2 四邊形中樣本位置實際上并未覆寫三角形的那些執行緒將被屏蔽(gl_HelperInvocation),本地 SM 的扭曲調度程式之一將管理像素著色任務,
- 與我們在頂點著色器邏輯階段相同的扭曲調度程式指令游戲現在在像素著色器執行緒上執行,鎖步處理特別方便,因為我們幾乎可以免費訪問像素四邊形中的值,因為所有執行緒都保證將其資料計算到相同的指令點(NV_shader_thread_group),

- 我們到了嗎?幾乎,我們的像素著色器已經完成了要寫入渲染目標的顏色的計算,并且我們還有一個深度值,在這一點上,我們必須考慮三角形的原始 api 排序,然后再將該資料交給 ROP(渲染輸出單元)子系統之一,該子系統本身具有多個 ROP 單元,這里執行深度測驗,與幀緩沖區混合等,這些操作需要以原子方式進行(一次設定一種顏色/深度),以確保我們沒有一個三角形的顏色和另一個三角形的深度值,當它們都覆寫相同的像素時,NVIDIA 通常應用記憶體壓縮來降低記憶體帶寬要求,從而增加“有效”帶寬(請參閱GTX 980 pdf),
噗!我們完成了,我們已經將一些像素寫入渲染目標,我希望這些資訊有助于理解 GPU 中的一些作業/資料流,它還可能有助于理解為什么與 CPU 同步確實有害的另一個副作用,必須等到一切都完成并且沒有新作業提交(所有單元都空閑),這意味著在發送新作業時,需要一段時間才能再次完全加載,尤其是在大型 GPU 上,
在下圖中,您可以看到我們如何渲染 CAD 模型并通過對影像有貢獻的不同 SM 或 warp id 對其進行著色(NV_shader_thread_group),結果不會是幀連貫的,因為作業分配會因幀而異,場景是使用許多繪圖呼叫渲染的,其中幾個也可以并行處理(使用 NSIGHT,您也可以看到一些繪圖呼叫并行性),

進一步閱讀
- Fabian Giesen的圖形管道之旅
- Paulius Micikevicius的性能優化指南及其背后的 GPU 架構
- Pomegranate: A Fully Scalable Graphics Architecture描述了并行階段的概念和它們之間的作業分配,
- 植物大戰僵尸必讀
轉載請註明出處,本文鏈接:https://www.uj5u.com/qita/421821.html
標籤:其他