Dive Into Deep Learning
- 2. 預備知識
- 2.1 資料操作
- 第一題
- 第二題
- 2.2 資料預處理
- 第一題
- 2.3 線性代數
- 第一題
- 第二題
- 第三題
- 第四題
- 第五題
- 第六題
- 第七題
- 第八題
- 2.4 微積分
- 第一題
- 第二題
- 第三題
- 第四題
- 2.5 自動微分
- 第一題
- 第二題
- 第三題
- 第四題
- 第五題
- 2.6 概率
- 第一題
- 第二題
- 第三題
- 第四題
(剛剛開始學習深度學習,爭取把節課的練習都記錄下來,菜雞一個,如果哪個地方有錯誤或是沒有理解到位煩請各位大佬指教)
2. 預備知識
2.1 資料操作
第一題
運行本節中的代碼,將本節中的條件陳述句X == Y更改為X < Y或X > Y,然后看看你可以得到什么樣的張量
X = torch.arange(12, dtype=torch.float32).reshape((3,4))
Y = torch.tensor([[2.0, 1, 4, 3], [1, 2, 3, 4], [4, 3, 2, 1]])
X < Y, X > Y
運行結果
(tensor([[ True, False, True, False],
[False, False, False, False],
[False, False, False, False]]),
tensor([[False, False, False, False],
[ True, True, True, True],
[ True, True, True, True]]))
第二題
用其他形狀(例如三維張量)替換廣播機制中按元素操作的兩個張量,結果是否與預期相同?
若為 (2x1x3) + (1x3x2) 則報錯
a = torch.tensor([[[1,2,3]],[[5,3,5]]]) # 2x1x3
b = torch.tensor([[[1,2],[3,5],[6,7]]]) # 1x3x2
a + b
---------------------------------------------------------------------------
RuntimeError Traceback (most recent call last)
Input In [103], in <module>
1 a = torch.tensor([[[1,2,3]],[[5,3,5]]])
2 b = torch.tensor([[[1,2],[3,5],[6,7]]])
----> 3 a + b
RuntimeError: The size of tensor a (3) must match the size of tensor b (2) at non-singleton dimension 2
若為(1x2x3) + (2x1x3)
a = torch.tensor([[[1, 2, 3], [4, 5, 6]]]) # 1x2x3
b = torch.tensor([[[7, 8, 9]], [[4, 5, 6]]]) # 2x1x3
a + b
結果為(2x2x3)
tensor([[[ 8, 10, 12],
[11, 13, 15]],
[[ 5, 7, 9],
[ 8, 10, 12]]])
關于廣播機制,參考pytorch官方給出的解釋:
1.每個張量至少有一個維度,
2.在迭代維度大小時,從尾隨維度開始,維度大小必須相等,其中之一為 1,或者其中之一不存在,
站內找到了<狗狗狗大王>的一篇文章解釋的非常詳細:
前提2: 按順序看兩個張量的每一個維度,x和y每個對應著的兩個維度都需要能夠匹配上,什么情況下算是匹配上了?滿足下面的條件就可以:
if 這兩個維度的大小相等
elif 某個維度 一個張量有,一個張量沒有
elif 某個維度 一個張量有,一個張量也有但大小是1
2.2 資料預處理
os.makedirs(dir_name2, exist_ok=True) 可以遞回的創建檔案夾
exist_ok引數為True時,判斷若檔案夾存在就不創建
os.path.join() 拼接檔案路徑
第一題
創建包含更多行和列的原始資料集,(1) 洗掉缺失值最多的列,(2) 將預處理后的資料集轉換為張量格式,
import os
import pandas as pd
import torch
os.makedirs(os.path.join('..', '2.1', 'data2'), exist_ok=True)
data_file = os.path.join('..', '2.1', 'data2', 'house_tiny.csv')
with open(data_file, 'w') as f:
f.write('NumRooms,Alley,Floor,Price\n')
f.write('NA,Pave,2,127500\n')
f.write('2,NA,1,106000\n')
f.write('4,NA,NA,178100\n')
f.write('NA,NA,2,140000\n')
f.write('NA,NA,2,152000\n')
data = pd.read_csv(data_file)
inputs, outputs = data.iloc[:, 0:3], data.iloc[:, 3]
num = inputs.isnull().sum() # 獲取缺失值最多的個數
Max_NaN = inputs.isnull().sum().idxmax() # 獲取缺失值最多個數的索引
inputs = inputs.drop(Max_NaN, axis=1) # 在inputs里洗掉缺失值最多的項
inputs = inputs.fillna(inputs.mean()) # 用同一列的均值替換該列的缺失項
inputs = pd.get_dummies(inputs, dummy_na=True)
x, y = torch.tensor(inputs.values), torch.tensor(outputs.values) # 轉化為張量形式
運行結果
(tensor([[3.0000, 2.0000],
[2.0000, 1.0000],
[4.0000, 1.7500],
[3.0000, 2.0000],
[3.0000, 2.0000]], dtype=torch.float64),
tensor([127500, 106000, 178100, 140000, 152000]))
df.isnull().sum()?????? 統計每列含有多少行數的null值,回傳行數
.idxmax()?????????獲取pandas中series最大值對應的索引,
drop函式默認洗掉行,列需要加axis = 1
2.3 線性代數
第一題
證明一個矩陣 A 的轉置的轉置是 A ,即 (AT)T=A
A = torch.randn(4, 3)
A == A.T.T
運行結果
tensor([[True, True, True],
[True, True, True],
[True, True, True],
[True, True, True]])
第二題
給出兩個矩陣 A 和 B ,證明“它們轉置的和”等于“它們和的轉置”,即 AT+BT=(A+B)T
A = torch.arange(12).reshape(3,4)
B = torch.randn(3,4)
A.T + B.T == (A + B).T
運行結果
tensor([[True, True, True],
[True, True, True],
[True, True, True],
[True, True, True]])
第三題
給定任意方陣 A , A+AT總是對稱的嗎?為什么?
A = torch.randn(4, 4)
(A + A.T).T == (A + A.T)
運行結果
tensor([[True, True, True, True],
[True, True, True, True],
[True, True, True, True],
[True, True, True, True]])
第四題
我們在本節中定義了形狀 (2,3,4) 的張量X,len(X)的輸出結果是什么?
X = torch.arange(24).reshape(2, 3, 4)
len(X)
運行結果
2
第五題
對于任意形狀的張量X,len(X)是否總是對應于X特定軸的長度?這個軸是什么?
X = torch.arange(24).reshape(2, 3, 4) # 2x3x4張量
Y = torch.arange(24).reshape(4, 6) # 4X6張量
Z = torch.ones(1) # 1維張量
len(X), len(Y), len(Z)
運行結果
2 4 6
len()???回傳tensor第零維的長度
第六題
運行A / A.sum(axis=1),看看會發生什么,你能分析原因嗎?
- 若A為方陣
A = torch.arange(16).reshape(4, 4) # 4X4
A / A.sum(axis=1)
運行結果
tensor([[0.0000, 0.0455, 0.0526, 0.0556],
[0.6667, 0.2273, 0.1579, 0.1296],
[1.3333, 0.4091, 0.2632, 0.2037],
[2.0000, 0.5909, 0.3684, 0.2778]])
- 若A不為方陣
A = torch.arange(12).reshape(3, 4) # 3X4
B = torch.arange(12).reshape(4, 3) # 4x3
A / A.sum(axis=1) # 或 B / B.sum(axis=1)
運行結果
RuntimeError Traceback (most recent call last)
Input In [78], in <module>
----> 1 A / A.sum(axis=1)
RuntimeError: The size of tensor a (4) must match the size of tensor b (3) at non-singleton dimension 1
若A為方陣,A.sum(axis=1)為沿著1軸降維,結果與A陣的長度相等,可以進行矩陣按元素的除法操作
若A不是方陣,A.sum(axis=1)為沿著1軸降維,結果與A陣的長度不相等,所以無法按元素進行運算
第七題
考慮一個具有形狀 (2,3,4) 的張量,在軸0、1、2上的求和輸出是什么形狀?
A = torch.arange(24).reshape(2,3,4) # 2x3x4
A.sum(axis=0).shape, A.sum(axis=1).shape, A.sum(axis=2).shape
運行結果
torch.Size([3, 4])
torch.Size([2, 4])
torch.Size([2, 3])
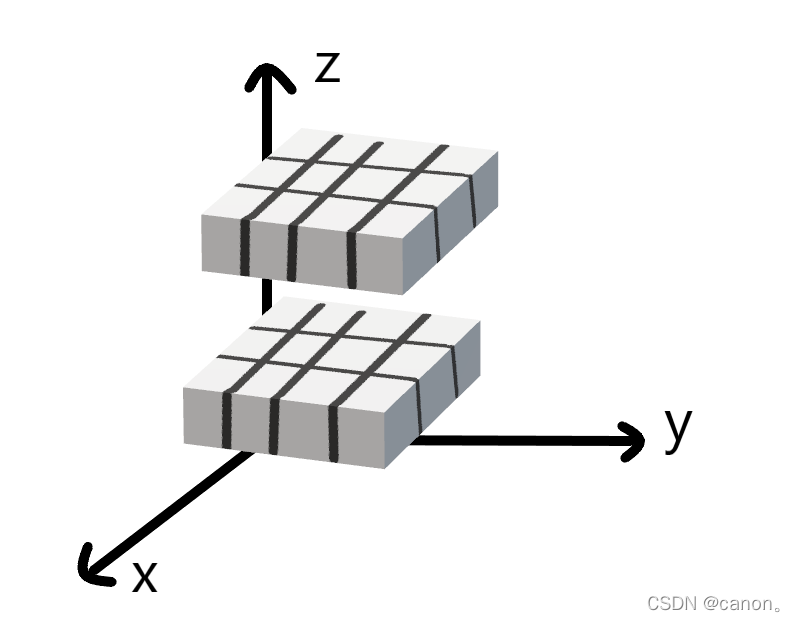
??????????????????????在軸0,1,2上求和分別為沿著z,x,y軸壓縮后的形狀
第八題
為linalg.norm函式提供3個或更多軸的張量,并觀察其輸出,對于任意形狀的張量這個函式計算得到什么?
A, B = torch.randn(2,3,4), torch.randn(3, 4)
outputs1 = torch.linalg.norm(A) # 2x3x4張量
outputs2 = torch.linalg.norm(B) # 3x4張量
A, B, outputs1, outputs2
運行結果
(tensor([[[ 2.1417, -1.2939, -0.0506, 0.0582],
[ 0.9437, 0.3785, -0.0736, -0.1000],
[-0.2323, 1.3399, 0.6603, 0.8154]],
[[-0.1303, -0.4355, -0.2770, 1.8112],
[ 0.7443, -0.1177, 0.8033, 0.0264],
[ 0.5158, -0.1448, -0.7694, -0.5072]]]),
tensor([[-1.1264, 0.0546, 0.4413, -0.1869],
[-1.7601, -0.4381, -0.2288, -1.7541],
[-0.1453, 1.0307, -0.8918, 0.7459]]),
tensor(4.0225),
tensor(3.2180))
相當于求L2范數,可表示張量的大小
2.4 微積分
第一題
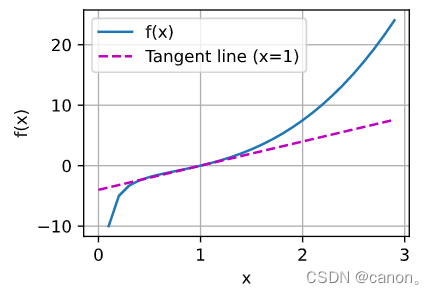
繪制函式 y = f ( x ) = x 3 ? 1 x y=f(x)=x^{3}-\frac{1}{x} y=f(x)=x3?x1?和其在 x = 1 x=1 x=1處切線的影像,
plot(x, [x ** 3 - 1 / x, 4 * x - 4], 'x', 'f(x)', legend=['f(x)', 'Tangent line (x=1)'])
運行結果
第二題
求函式 f ( x ) = 3 x 1 2 + 5 e x 2 f(x)=3x_{1}^{2}+5e^{x_{2}} f(x)=3x12?+5ex2?的梯度,
[ 6 x 1 6x_{1} 6x1?, 5 e x 2 5e^{x_{2}} 5ex2?]???分別對第一項的x1和第二項的x2求導??梯度為向量形式
第三題
函式 f ( x ) = ∥ x ∥ 2 f(x)=\left \| x \right \|_{2} f(x)=∥x∥2?的梯度是什么?
? f ( x ) ? x = ? ∥ x ∥ 2 ? x = x ∥ x ∥ 2 \frac{\partial f(x)}{\partial x}=\frac{\partial \left \| x \right \|_{2}}{\partial x}=\frac{x}{\left \| x \right \|_{2}} ?x?f(x)?=?x?∥x∥2??=∥x∥2?x?
L2范數可看成 x 2 \sqrt{x^{2}} x2 ?, 則 f ( x ) f(x) f(x)梯度為 x 2 \sqrt{x^{2}} x2 ?對 x x x求導: f ′ ( x ) = 2 x 2 x 2 = x x 2 = x ∥ x ∥ 2 f^{'}(x)=\frac{2x}{2\sqrt{ x^{2}}}=\frac{x}{\sqrt{x^{2}}}=\frac{x}{\left \| x \right \|_{2}} f′(x)=2x2 ?2x?=x2 ?x?=∥x∥2?x?
第四題
你可以寫出函式 u = f ( x , y , z ) u=f(x,y,z) u=f(x,y,z),其中 x = x ( a , b ) x=x(a,b) x=x(a,b) , y = y ( a , b ) y=y(a,b) y=y(a,b), z = z ( a , b ) z=z(a,b) z=z(a,b) 的鏈式法則嗎?
d u d a = d u d x d x d a + d u d y d y d a + d u d z d z d a \frac{du}{da}=\frac{du}{dx}\frac{dx}{da}+\frac{du}{dy}\frac{dy}{da}+\frac{du}{dz}\frac{dz}{da} dadu?=dxdu?dadx?+dydu?dady?+dzdu?dadz?
d u d b = d u d x d x d b + d u d y d y d b + d u d z d z d b \frac{du}{db}=\frac{du}{dx}\frac{dx}{db}+\frac{du}{dy}\frac{dy}{db}+\frac{du}{dz}\frac{dz}{db} dbdu?=dxdu?dbdx?+dydu?dbdy?+dzdu?dbdz?
2.5 自動微分
requires_grad是Pytorch中通用資料結構Tensor的一個屬性,用于說明當前量是否需要在計算中保留對應的梯度資訊
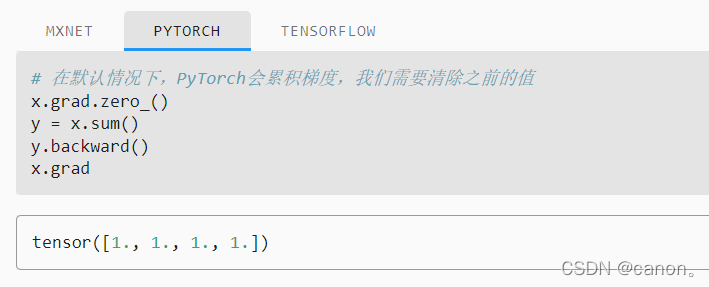
向量x求和,相當于向量乘一個單位向量E,故求梯度后為1
第一題
為什么計算二階導數比一階導數的開銷要更大?
因為計算二階倒數需要先計算出一階導數
第二題
在運行反向傳播函式之后,立即再次運行它,看看會發生什么,
import torch
x = torch.arange(4.0, requires_grad=True)
y = 2 * torch.dot(x, x)
y.backward()
y.backward() # 立即再執行一次反向傳播
x.grad
運行結果
RuntimeError: Trying to backward through the graph a second time, but the saved intermediate results have already been freed. Specify retain_graph=True when calling .backward() or autograd.grad() the first time. # 在試圖第二次反向傳播時,第一次反向傳播的結果已經被釋放了
在第一次 .backward時指定retain graph=True
import torch
x = torch.arange(4.0, requires_grad=True)
y = 2 * torch.dot(x, x)
y.backward(retain_graph=True) # 保留計算圖不被釋放
y.backward()
x.grad
運行結果
tensor([ 0., 8., 16., 24.])
pytorch默認不能連續執行反向傳播,如需線序執行需要更新x.grad
第三題
在控制流的例子中,我們計算d關于a的導數,如果我們將變數a更改為隨機向量或矩陣,會發生什么?
import torch
def f(a):
b = a * 2
while b.norm() < 1000:
b = b * 2
if b.sum() > 0:
c = b
else:
c = 100 * b
return c
a = torch.randn(size=(2,2), requires_grad=True) # a為2x2
d = f(a)
d.backward()
運行結果
RuntimeError: grad can be implicitly created only for scalar outputs # 不對向量或矩陣進行反向傳播
對于非標量(向量或矩陣)來說,需要指定gradient的長度與其長度相匹配
第四題
重新設計一個求控制流梯度的例子,運行并分析結果,
import torch
def f(a):
b = a / 2
while b > 1:
b = pow(a, 2)
if b < 3:
c = b * 2
else:
c = b * 3
return c
a = torch.randn(size=(), requires_grad=True)
d = f(a)
d.backward()
a.grad == d / a
運行結果
tensor(True)
與2.5.4例子思想一致
第五題
使 f ( x ) = s i n ( x ) f(x)=sin(x) f(x)=sin(x),繪制 f ( x ) f(x) f(x) 和 d f ( x ) d x \frac{df(x)}{dx} dxdf(x)? 的影像,其中后者不使用 f ′ ( x ) = c o s ( x ) f^{'}(x)=cos(x) f′(x)=cos(x)
錯誤代碼
import torch
import matplotlib.pyplot as plt
import numpy as np
x = torch.arange(-3*np.pi, 3*np.pi, 0.1,requires_grad=True)
y = torch.sin(x)
y.sum().backward()
plt.plot(x, y, label='y=sin(x)')
plt.plot(x, x.grad, label='dsin(x)=cos(x)')
plt.legend(loc='upper center')
plt.show()
報錯:
RuntimeError: Can't call numpy() on Tensor that requires grad. Use tensor.detach().numpy() instead.
不能對將要grad的張量呼叫numpy(),應用tensor.detach().numpy()來代替
錯誤代碼
y.backward()
報錯:
grad can be implicitly created only for scalar outputs
y為標量時可進行反向傳播,每一個輸入x對應一個標量輸出y*,故將 y.sum 可得到一個標量
import torch
import matplotlib.pyplot as plt
import numpy as np
x = torch.arange(-3*np.pi, 3*np.pi, 0.1,requires_grad=True)
y = torch.sin(x)
y.sum().backward()
plt.plot(x.detach(), y.detach(), label='y=sin(x)')
plt.plot(x.detach(), x.grad, label='dsin(x)=cos(x)')
plt.legend(loc='upper center')
plt.show()
運行結果
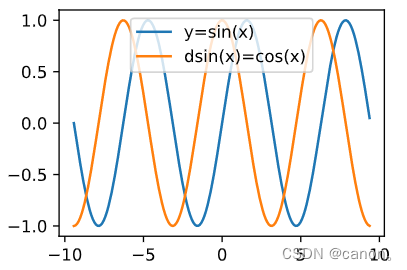
2.6 概率
%matplotlib inline 為魔法函式: IPython有一組預先定義好的所謂的魔法函式,可以通過命令列的語法形式來訪問它們,“%”后就是魔法函式的引數
該函式的功能是內嵌繪圖,并且省掉了plt.show()torch.cumsum(input, dim, *, dtype=None, out=None) ?? 回傳維度dim中輸入元素的累計和
第一題
進行 m=500 組實驗,每組抽取 n=10 個樣本,改變 m 和 n ,觀察和分析實驗結果,
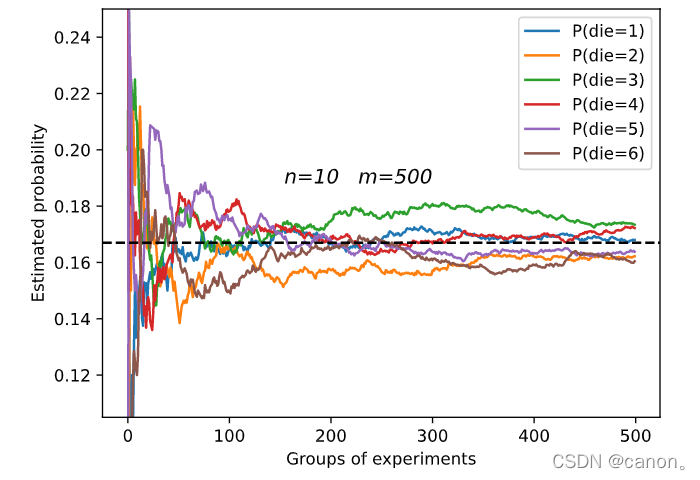
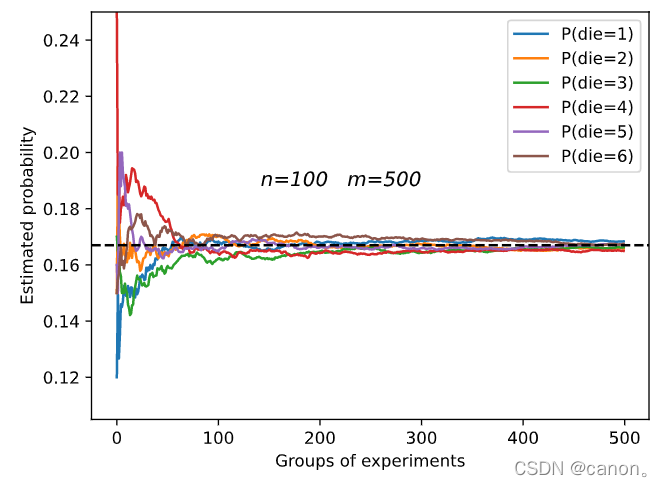
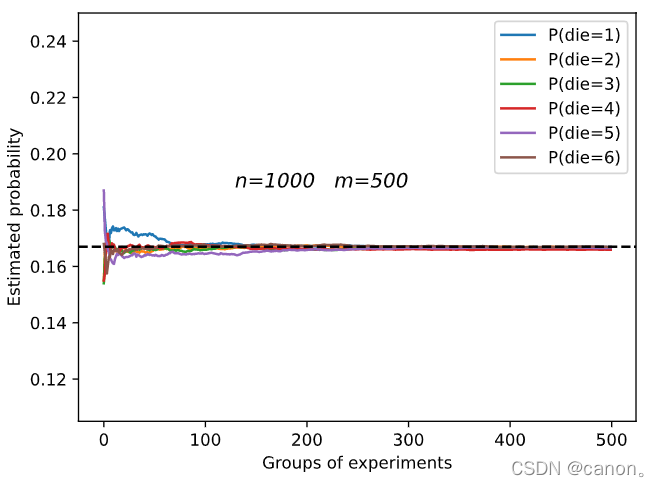
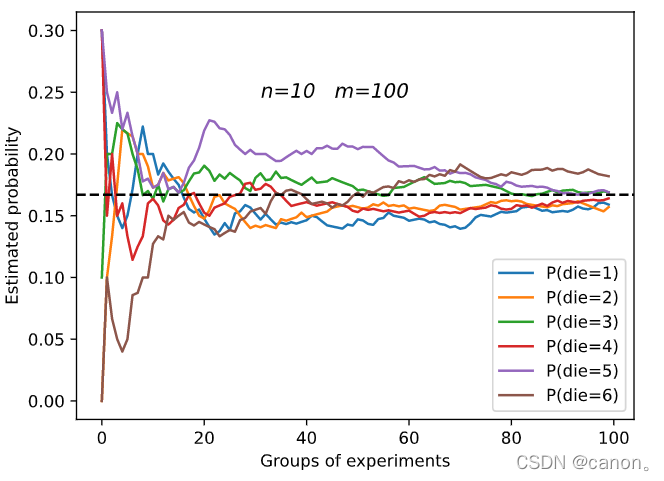

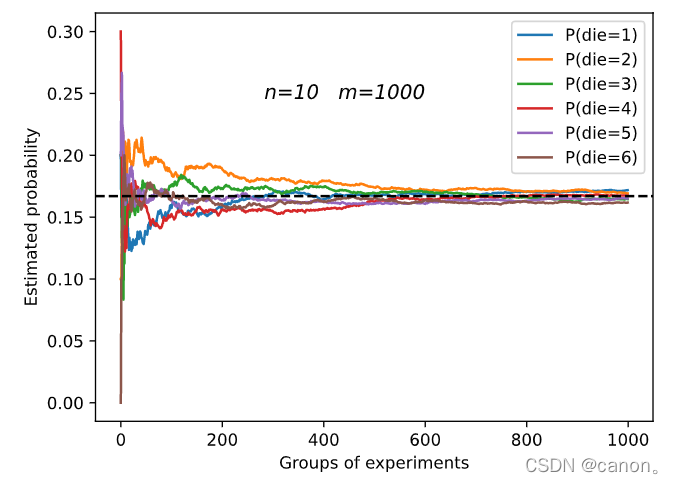
增加m或增加n都會增加樣本容量,這樣會使結果更加趨向于真實的概率
第二題
給定兩個概率為 P(A) 和 P(B) 的事件,計算 P(A∪B) 和 P(A∩B) 的上限和下限,
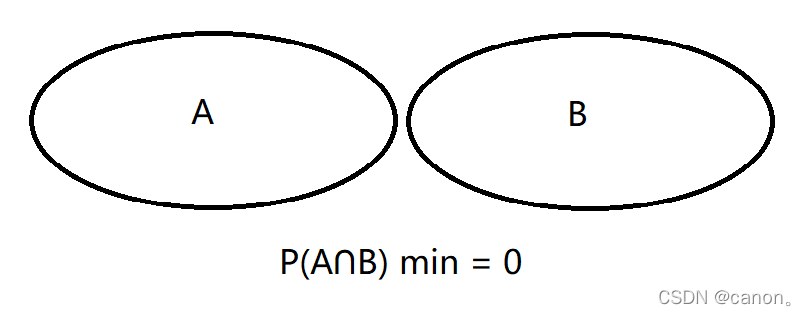
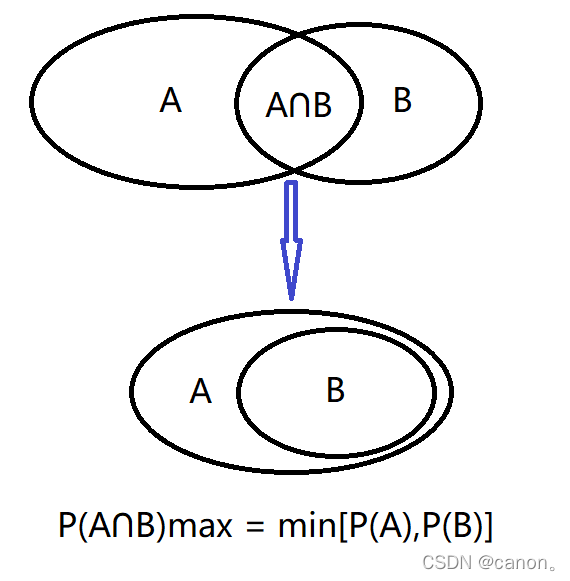
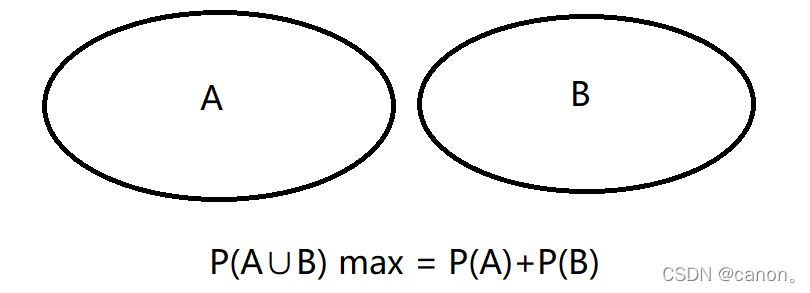
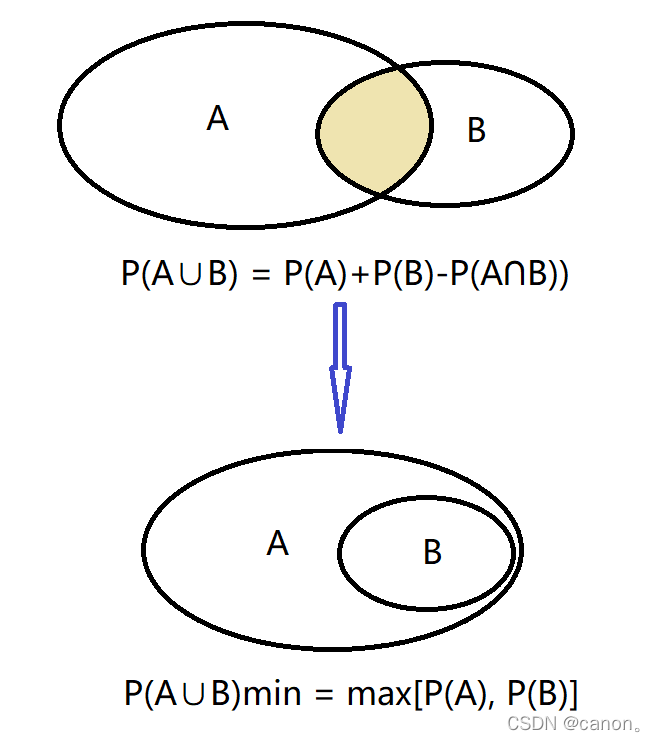
第三題
假設我們有一系列隨機變數,例如 A 、 B 和 C ,其中 B 只依賴于 A ,而 C 只依賴于 B ,你能簡化聯合概率 P(A,B,C) 嗎?
馬爾可夫鏈是一組具有馬爾可夫性質的離散隨機變數的集合,具體地,對概率空間 ( ? , F , P ) (\mho ,F,\mathbb{P}) (?,F,P)內以一維可數集為指數集(index set) 的隨機變數集合 X = { X n : n > 0 } X=\left \{ X_{n}:n>0 \right \} X={Xn?:n>0},若隨機變數的取值都在可數集內: X = s i , s i ∈ s X=s_{i},s_{i}\in s X=si?,si?∈s ,且隨機變數的條件概率滿足如下關系: P ( X t + 1 ∣ X t , . . . , X 1 ) = P ( X t + 1 ∣ X t ) P(X_{t+1}|X_{t},...,X_{1})=P(X_{t+1}|X_{t}) P(Xt+1?∣Xt?,...,X1?)=P(Xt+1?∣Xt?)
????????????????? P ( A B C ) = P ( A ) P ( B ∣ A ) P ( C ∣ B A ) = P ( A ) P ( B ∣ A ) P ( C ∣ B ) P(ABC)=P(A)P(B|A)P(C|BA)=P(A)P(B|A)P(C|B) P(ABC)=P(A)P(B∣A)P(C∣BA)=P(A)P(B∣A)P(C∣B)
見 2022版《張宇概率論與數理統計9講》P7,4.注
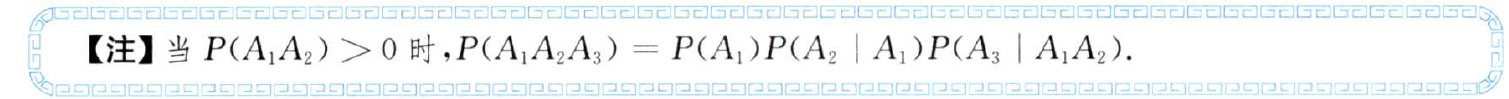
第四題
在 2.6.2.6節中,第一個測驗更準確,為什么不運行第一個測驗兩次,而是同時運行第一個和第二個測驗?
因為每次測驗的特征不一樣,就會導致每次測驗受不同的影響,若運行兩次第一個測驗則會造成這種影響的疊加,同時運行第一個和第二個測驗能夠很有效的抵消這種影響,
轉載請註明出處,本文鏈接:https://www.uj5u.com/qita/421850.html
標籤:AI
上一篇:[Python從零到壹] 三十七.影像處理基礎篇之影像融合處理和ROI區域繪制
下一篇:2022年的第一篇程式人生。。。