目錄
單變數統計
方差分析
代碼實作
SelectKBest特征選取
遞回特征消除(RFE)
皮爾遜系數(相關系數)
基于樹模型的特征選擇
輕量級的高效梯度樹
隨機森林
迭代選擇
每文一語
單變數統計
方差分析
在單變數統計中,我們計算每個特征和目標值之間的關系是否存在統計顯著性,然后選擇具有最高置信度的特征,對于分類問題,這也被稱為方差分析(analysis of variance,ANOVA),
這些測驗的一個關鍵性質就是它們是單變數的(univariate),即它們只單獨考慮每個特征,因此,如果一個特征只有在與另一個特征合并時才具有資訊量,那么這個特征將被舍棄,
單變數測驗的計算速度通常很快,并且不需要構建模型,另一方面,它們完全獨立于你可能想要在特征選擇之后應用的模型,
注意:不需要構建模型,利用純理論的數學思維去構建出來
想要在 scikit-learn 中使用單變數特征選擇,你需要選擇一項測驗——對分類問題通常是 f_classif(默認值),對回歸問題通常是 f_regression——然后基于測驗中確定的 p 值來選擇一種舍棄特征的方法,所有舍棄引數的方法都使用閾值來舍棄所有 p 值過大的特征(意味著它們不可能與目標值相關),計算閾值的方法各有不同,最簡單的是 SelectKBest和 SelectPercentile,前者選擇固定數量的 k 個特征,后者選擇固定百分比的特征,
代碼實作
from sklearn.feature_selection import SelectPercentile
select=SelectPercentile(percentile=50) #選取50%的特征
select.fit(X_train,y_train)
X_train_selected=select.transform(X_train)
print(X_train.shape)
print(X_train_selected.shape)
案例分析
import numpy as np
from sklearn.datasets import load_breast_cancer
from sklearn.feature_selection import SelectPercentile #SelectPercentile選擇百分比,SelectKBest選擇個數
from sklearn.model_selection import train_test_split
#使用sklearn自帶的資料集
cancer=load_breast_cancer()
#向資料中添加噪聲特征,前30個特征來自原資料集,后50個是噪聲
rng=np.random.RandomState(42)
#構造噪聲特征
noise=rng.normal(size=(len(cancer.data),50))
X_w_noise=np.hstack([cancer.data,noise])
#分割資料集用于測驗和訓練
X_train,X_test,y_train,y_test=train_test_split(X_w_noise,cancer.target,random_state=0,test_size=.5)
#特征選取
select=SelectPercentile(percentile=50) #選取50%的特征
select.fit(X_train,y_train)
X_train_selected=select.transform(X_train)
print(X_train.shape)
print(X_train_selected.shape)
很明顯的就發現特征變化了,而且是50%,還可以看看那些特征被選取
#查看哪些特征被選中
mask=select.get_support()
print(mask)
import matplotlib.pyplot as plt
plt.matshow(mask.reshape(1,-1),cmap='gray_r')
plt.xlabel('sample index')
plt.show()
這一類的特征選取方法比較的直接,也就是說直接保留多少占比的特征數量,在某些時候的模型訓練中,我們需要根據特征的權重進行自定義的篩選,
SelectKBest特征選取
這類選取方法和相關系數選取比較的相似,可以通過這些物件的得分,選取重要的資料列
import pandas as pd
import numpy as np
# 分類常用的
from sklearn.feature_selection import SelectKBest,f_classif,chi2,mutual_info_classif
# 分別是卡方檢驗,計算非負特征和類之間的卡方統計 chi
# 樣本方差F值,f_classif
# 離散類別互動資訊, mutual_info_classif
# 回歸常用的
from sklearn.feature_selection import f_regression,mutual_info_regressionselector= SelectKBest(score_func= chi2,k=len(X.columns))
selector.fit(X,y)
score=-np.log10(selector.pvalues_)
# print(score)
score_index=np.argsort(score)[::-1]
for i in range(len(score)):
print("%0.2f %s"%(score[score_index[i]],X.columns[score_index[i]]))
上述的數值大小代表著特征的重要性(下面有一個完整的代碼實體)
from sklearn.feature_selection import SelectKBest
from sklearn.feature_selection import chi2
from sklearn.datasets import load_iris
import pandas as pd
from sklearn.preprocessing import MinMaxScaler
from scipy.stats import chi2_contingency
import numpy as np
model = SelectKBest(chi2, k=8)#選擇k個最佳特征
X_new = model.fit_transform(X, y)
#feature_data是特征資料,label_data是標簽資料,該函式可以選擇出k個特征
print("model shape: ",X_new.shape)
scores = model.scores_
print('model scores:', scores) # 得分越高,特征越重要
p_values = model.pvalues_
print('model p-values', p_values) # p-values 越小,置信度越高,特征越重要
# 按重要性排序,選出最重要的 k 個
indices = np.argsort(scores)[::-1]
k_best_features = list(X.columns.values[indices[0:8]])
print('k best features are:\n ',k_best_features)
print(k_best_features)簡而言之,使用SelectKBest選取,可以調整里面的引數值,最終確定最重要的幾個特征
遞回特征消除(RFE)
遞回消除特征法使用一個基模型來進行多輪訓練,每輪訓練后,移除若干權值系數的特征,再基于新的特征集進行下一輪訓練,
sklearn官方解釋:對特征含有權重的預測模型(例如,線性模型對應引數coefficients),RFE通過遞回減少考察的特征集規模來選擇特征,首先,預測模型在原始特征上訓練,每個特征指定一個權重,之后,那些擁有最小絕對值權重的特征被踢出特征集,如此往復遞回,直至剩余的特征數量達到所需的特征數量,
RFE 通過交叉驗證的方式執行RFE,以此來選擇最佳數量的特征:對于一個數量為d的feature的集合,他的所有的子集的個數是2的d次方減1(包含空集),指定一個外部的學習演算法,比如SVM之類的,通過該演算法計算所有子集的validation error,選擇error最小的那個子集作為所挑選的特征,
"""
使用RFE進行特征選擇:RFE是常見的特征選擇方法,也叫遞回特征消除,它的作業原理是遞回洗掉特征,
并在剩余的特征上構建模型,它使用模型準確率來判斷哪些特征(或特征組合)對預測結果貢獻較大,
"""
from sklearn import datasets
from sklearn.feature_selection import RFE
from sklearn.linear_model import LogisticRegression
model = LogisticRegression()
rfe = RFE(model, 3)
rfe = rfe.fit(X, y)
print(X.columns[rfe.support_])
print(rfe.support_)
print(rfe.ranking_)
RFE的穩定性很大程度上取決于迭代時,底層用的哪種模型,比如RFE采用的是普通的回歸(LR),沒有經過正則化的回歸是不穩定的,那么RFE就是不穩定的,假如采用的Lasso/Ridge,正則化的回歸是穩定的,那么RFE就是穩定的,
皮爾遜系數(相關系數)
皮爾遜相關也稱為積差相關(或者積矩相關),我們假設有兩個變數X,Y,那么兩變數間的皮爾遜相關系數計算如下:

# 查看其他指標和income的相關性,并對其相關性系數排序
# 正相關與負相關,越接近1說明該變數值越大目標標簽的值越容易分類為1
df.corr()[["n23"]].sort_values(by="n23",ascending=False)# 可以根據相關性的值進行取值帶入模型(特征選取與篩選)第一次選取
corr=df.corr()[["n23"]].sort_values(by="n23",ascending=False).iloc[1:10].index.values.astype("U")
corr_name=corr.tolist()
corr_name
利用該方法還可以繪制熱力圖:sns.clustermap(df.corr())

Pearson相關系數的一個明顯缺陷是,作為特征排序機制,他只對線性關系敏感,如果關系是非線性的,即便兩個變數具有一一對應的關系,Pearson相關性也可能會接近0,
基于樹模型的特征選擇
一般基于模型所做出的特征選擇,效果比單變數的要好,但是不管是所有的特征選取的方法都需要結合實際的經驗,來辨別特征的有效性,
輕量級的高效梯度樹
from sklearn.model_selection import train_test_split,cross_val_score #拆分訓練集和測驗集
import lightgbm as lgbm #輕量級的高效梯度提升樹
X_name=df.corr()[["n23"]].sort_values(by="n23",ascending=False).iloc[1:].index.values.astype("U")
X=df.loc[:,X_name.tolist()]
y=df.loc[:,['n23']]
X_train, X_test, y_train, y_test = train_test_split(X,y,test_size=0.2,stratify=y,random_state=1)
lgbm_reg = lgbm.LGBMRegressor(objective='regression',max_depth=6,num_leaves=25,learning_rate=0.005,n_estimators=1000,min_child_samples=80, subsample=0.8,colsample_bytree=1,reg_alpha=0,reg_lambda=0)
lgbm_reg.fit(X_train, y_train)
#選擇最重要的20個特征,繪制他們的重要性排序圖
lgbm.plot_importance(lgbm_reg, max_num_features=20)
##也可以不使用自帶的plot_importance函式,手動獲取特征重要性和特征名,然后繪圖
feature_weight = lgbm_reg.feature_importances_
feature_name = lgbm_reg.feature_name_
feature_sort = pd.Series(data = feature_weight ,index = feature_name)
feature_sort = feature_sort.sort_values(ascending = False)
# plt.figure(figsize=(10,8))
# sns.barplot(feature_sort.values,feature_sort.index, orient='h')
lgbm_name=feature_sort.index[:15].tolist()
lgbm_name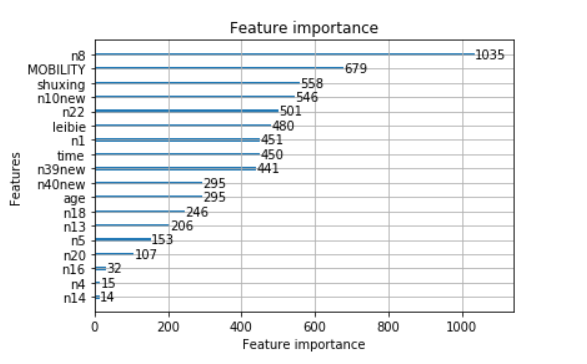
隨機森林
from sklearn import metrics
import warnings
warnings.filterwarnings("ignore")
from sklearn.ensemble import RandomForestClassifier
import matplotlib.pyplot as plt
selected_feat_names=set()
for i in range(10): #這里我們進行十次回圈取交集
tmp = set()
rfc = RandomForestClassifier(n_jobs=-1)
rfc.fit(X, y)
#print("training finished")
importances = rfc.feature_importances_
indices = np.argsort(importances)[::-1] # 降序排列
S={}
for f in range(X.shape[1]):
if importances[indices[f]] >=0.0001:
tmp.add(X.columns[indices[f]])
S[X.columns[indices[f]]]=importances[indices[f]]
#print("%2d) %-*s %f" % (f + 1, 30, X.columns[indices[f]], importances[indices[f]]))
selected_feat_names |= tmp
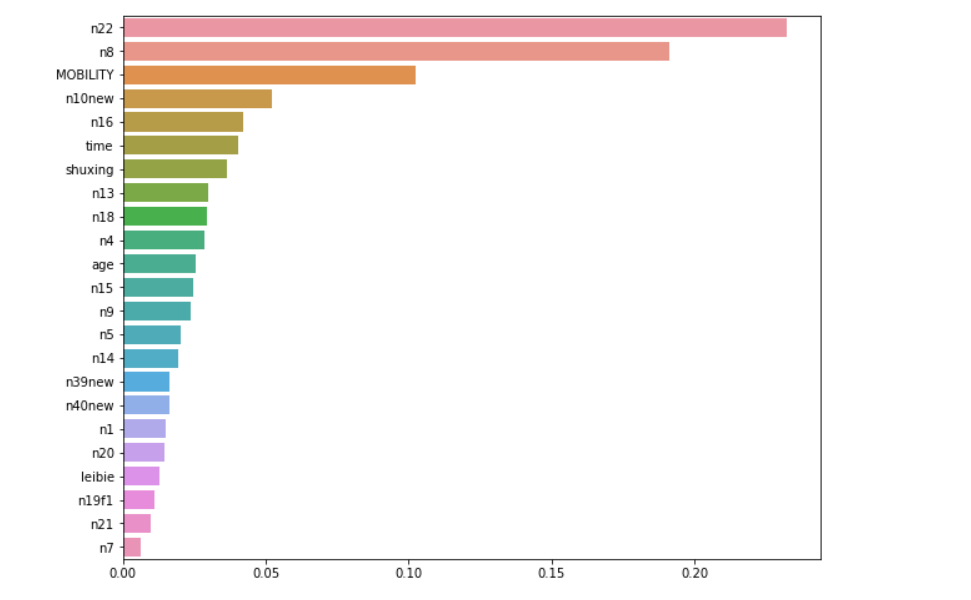
imp_fea=pd.Series(S)
plt.figure(figsize=(10,8))
sns.barplot(imp_fea.values,imp_fea.index, orient='h')
print(imp_fea)
print(len(selected_feat_names), "features are selected")
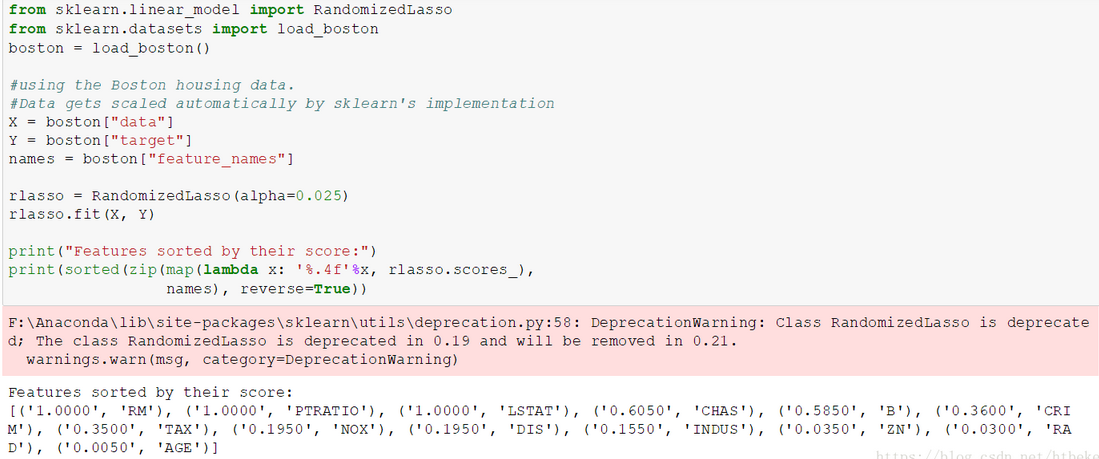
 其實還有很多,比如在回歸問題中,基于懲罰項的特征選取;L1、L2模型也是可以的
其實還有很多,比如在回歸問題中,基于懲罰項的特征選取;L1、L2模型也是可以的
迭代選擇
在迭代特征選擇中,將會構建一系列模型,每個模型都使用不同數量的特征,有兩種基本方法:開始時沒有特征,然后逐個添加特征,直到滿足某個終止條件;或者從所有特征開始,然后逐個洗掉特征,直到滿足某個終止條件,由于構建了一系列模型,所以這些方法的計算成本要比前面討論過的方法更高,
其中一種特殊方法是遞回特征消除(recursive feature elimination, RFE),在前面也介紹了,它從所有特征開始構建模型,并根據模型舍棄最不重要的特征,然后使用除被舍棄特征之外的所有特征來構建一個新模型,如此繼續,直到僅剩下預設數量的特征,為了讓這種方法能夠運行,用于選擇的模型需要提供某種確定特征重要性的方法,正如基于模型的選擇所做的那樣,
每文一語
堅持走好每一步,探尋機遇才能不慌不亂!加油!
轉載請註明出處,本文鏈接:https://www.uj5u.com/qita/421858.html
標籤:AI
上一篇:java畢設專案車牌號碼識別系統開源了,很好玩,建議嘗試
下一篇:RTX3060安裝pytorch