Kafka作為一個訊息中間件,其應用相當廣泛,尤其在大資料領域,基本都會用到,由于筆者參與大資料作業,因此本文將從我的角度和經驗出發,講一下Kafka為什么廣泛應用于大資料領域,對于Kafka不是很熟悉的朋友可以點擊下方連接跳轉進行閱讀:
Kafka從入門到放棄(一) —— 初識Kafka
Kafka從入門到放棄(二) —— 生產者
Kafka從入門到放棄(三) —— 消費者
背景&場景
在大資料場景下,資料經常需要經過ETL(抽取-轉換-加載)的處理,從一端流向另一端(當然也有ELT,根據各個企業不同的考量決定不同的架構),比如從各個業務系統經過處理后落地到資料倉庫,資料倉庫有時候又要把資料提供給業務系統,
由于資料流向比較多,如果不做好資料鏈路規劃,很容易造成開發重復、成本增加,出現問題也比較難以排查,因此,合理構造資料管道是很重要的,而Kafka在資料管道的構建中發揮了很大的優勢,
特點&原因
批流一體
大資料處理分為流處理和批處理,流處理對實時性要求比較高,資料像水流一樣源源不斷的流動;批處理就是批量處理,就是字面意思,比如當天處理前一天的資料,
由于Kafka是一個基于流的資料平臺,在資料處理方面可以做到實時,所以經常在流處理架構中用到它,
另外它也提供資料存盤,可以將一段時間內的資料存盤起來,后續對擠壓得資料進行批量處理;也可以在資料到達得時候及時獲取并處理,
可用性&可靠性
之前的幾篇文章中說的那些特點多少包含了Kafka在這方面的情況,
Kafka通過zookeeper維護集群的資訊,同時Kafka也有Controller,它不單能完成broker的作業,同時還負責磁區Leader的選舉,
另外,Kafka的磁區可以有副本,而且分leader和follower,當leader掛掉后follower能頂替其位置,保證其可用性,
在生產者方面,發送訊息到Kafka有確認機制以及重試機制,詳情可以看這篇文章:Kafka從入門到放棄(二) —— 生產者
在消費者方面,提交偏移量的策略選擇以及重磁區可以保證資料可靠性,
Kafka還支持“exactly once”語意,exactly once是有且只有一次,可以簡單理解為:資料到達并保存了,但還沒回傳確認訊息的時候掛了,生產者再發一次,Kafka再存一次,這種是at least once;而exactly once則只保存一次,沒有重復,
一般在消費者端實作exactly once是通過設定唯一鍵,Kafka也可以通過設定唯一標識對應每一條資料,這種方式是冪等性(簡單理解為:多次操作,結果是一致的),
高吞吐
Kafka可以作為生產者和消費者之間的緩沖區,生產和消費的速度就可以不一致了,消費者的吞吐能力差的時候,可以將資料積壓到Kafka,慢慢消費,
伸縮性
這個其實也和高吞吐有關,Kafka可以動態擴容,通過增加磁區或者增加消費者,提高吞吐能力,
解耦&集成
大資料處理的程序中,不管是源端還是目標端都有很多,經常需要將日志匯入HDFS,或者從MySQL導數到Oracle,如果每個流程都建一條鏈路,會變得難以維護,而且有可能造成重復開發,
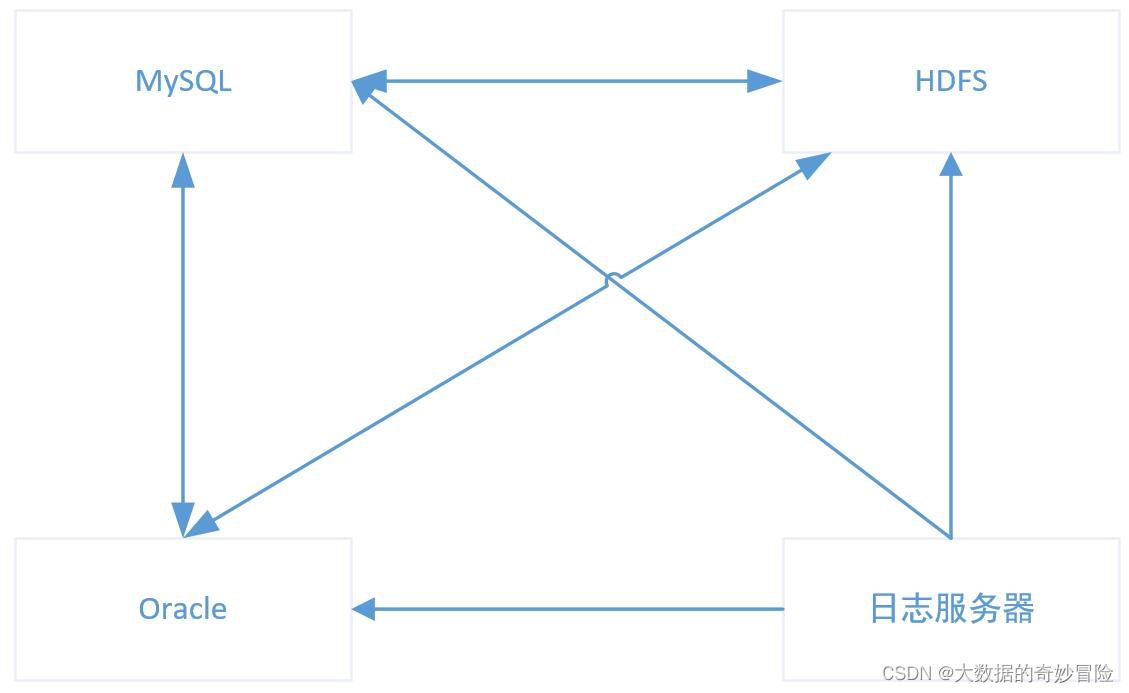
引入Kafka,可以解耦生產者和消費者,同時可以將多源異構的資料集成起來,就可以減少重復開發,提高效率,
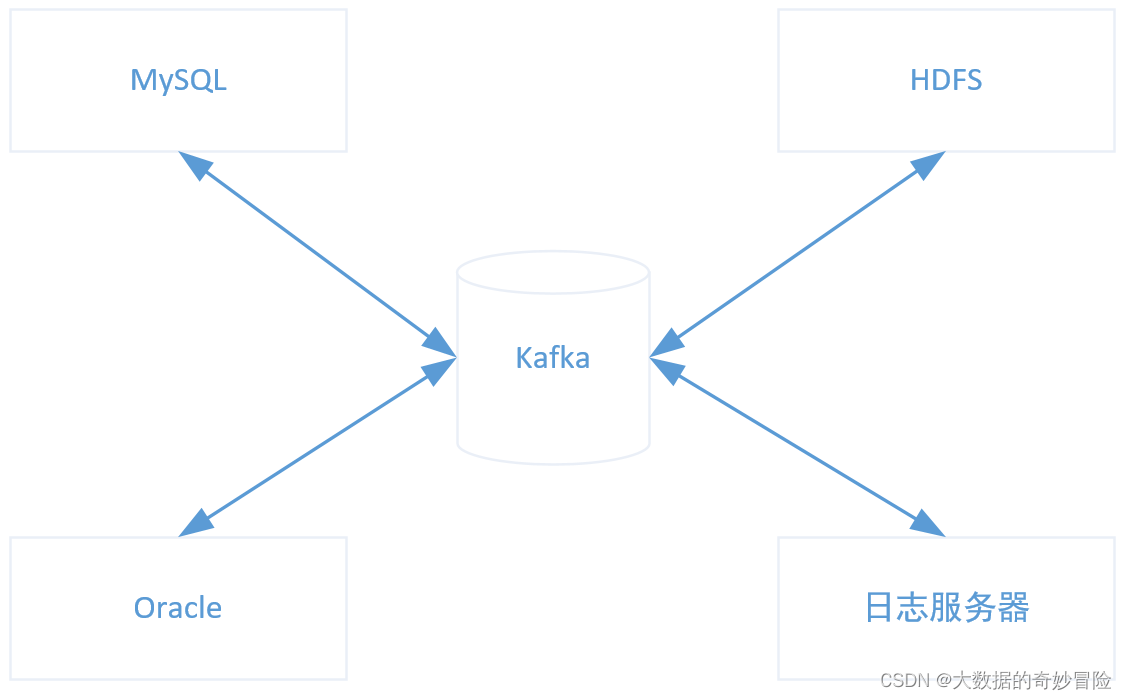
總結
Kafka由于其具有批流一體、可靠性、可用性、解耦、伸縮性、高吞吐的特性,使其在大資料領域應用十分廣泛,常作為資料總線,多用于資料采集以及資料服務,
轉載請注明出處:CSDN“大資料的奇妙冒險”
轉載請註明出處,本文鏈接:https://www.uj5u.com/qita/421868.html
標籤:其他
上一篇:Centos7安裝jdk8
下一篇:一文搞懂quartz任務調度框架