文章目錄
- 前言
- 模型訓練完整步驟
- 模型保存與加載
- GPU訓練
- “借雞生蛋“
- 模型使用
本博文優先在掘金社區發布!
前言
我們這邊還是以CIARF10這個模型為例子,
現在的話先說明一下,關于CIARF10的一個輸出
這個是一個十分類的模型,所以輸出結果是一個矩陣一個tensor其中它的shape是你的(batch_size,10)這樣的結果,假設你的batch_size = 1
那么你得到的結果應該是[[1,2,3,4,5,6,7,8,9,10]]這種型別的,你的輸入的標簽是這樣的[ 9 ]
所以,如果你想要判斷你的結果,你只需要看看這個輸出的串列里面最大的那個數字的下標,這里是9,剛好和我們的這個標簽的數值一樣,那么預測正確,在pytorch里面提供了一個方法,叫做argmax(1)表示橫向獲得最大值的下標,argmax(0)表示縱向,所以用這種方法我們可以去獲取我們訓練的一個準確度,
模型訓練完整步驟
我們的訓練集一般時分兩個部分的,一個是專門拿給你訓練的,一個是專門用來做驗證的,當然你自己定義的資料集也一樣類似,
總之需要兩個部分,驗證的那個部分的不要進入訓練網路就行,
完整代碼如下:有注釋
import torchvision
from torch import nn
import torch
from torch.utils.data import DataLoader
from torch.nn import Conv2d, MaxPool2d, Flatten, Linear, Sequential, CrossEntropyLoss
from torchvision import transforms
from torch.utils.tensorboard import SummaryWriter
trans = transforms.Compose([transforms.ToTensor()])
#獲取訓練集
dataset = torchvision.datasets.CIFAR10(root="./dataset",train=True,transform=trans,download=True)
dataset2 = torchvision.datasets.CIFAR10(root="./dataset",train=False,transform=trans,download=True)
train_dataloader = DataLoader(dataset,batch_size=64)
test_dataloader = DataLoader(dataset2,batch_size=64)
test_len = len(dataset2)
class MyModule(nn.Module):
def __init__(self):
super().__init__()
self.model = Sequential(
Conv2d(3, 32, kernel_size=(5, 5), padding=2),
MaxPool2d(2),
Conv2d(32, 32, (5, 5), padding=2),
MaxPool2d(2),
Conv2d(32, 64, (5, 5), padding=2),
MaxPool2d(2),
Flatten(),
Linear(1024, 64),
Linear(64, 10)
)
def forward(self,x):
x = self.model(x)
return x
if __name__ == '__main__':
writer = SummaryWriter()
mymodule = MyModule()
loss = torch.nn.CrossEntropyLoss()
learnstep = 0.01
optim = torch.optim.SGD(mymodule.parameters(),lr=learnstep)
epoch = 1000
train_step = 0 #每輪訓練的次數
mymodule.train()#模型在訓練狀態
for i in range(epoch):
print("第{}輪訓練".format(i+1))
train_step = 0
for data in train_dataloader:
imgs,targets = data
outputs = mymodule(imgs)
result_loss = loss(outputs,targets)
optim.zero_grad()
result_loss.backward()
optim.step()
train_step+=1
if(train_step%100==0):
print("第{}輪的第{}次訓練的loss:{}".format((i+1),train_step,result_loss.item()))
# 在測驗集上面的效果
mymodule.eval() #在驗證狀態
test_total_loss = 0
right_number = 0
with torch.no_grad(): # 驗證的部分,不是訓練所以不要帶入梯度
for test_data in test_dataloader:
imgs,label = test_data
outputs_ = mymodule(imgs)
test_result_loss=loss(outputs_,label)
right_number += (outputs_.argmax(1)==label).sum()
# writer.add_scalar("在測驗集上的準確率",(right_number/test_len),(i+1))
print("第{}輪訓練在測驗集上的準確率為{}".format((i+1),(right_number/test_len)))
if((i+1)%500==0):
# 保存模型
torch.save(mymodule.state_dict(),"mymodule_{}.pth".format((i+1)))
模型保存與加載
模型的保存的話很簡單,這里主要有兩種方法,
一個是直接把模型和是訓練好的資料也保存,
torch.save(yourmodlue,path)
modlue = torch.load(path)
第二個方法是保存資料,你把資料加載到你的模型里面就行
torch.save(yourmodlue.state_dict(),path)
modlue.load_state_dict(torch.load(path))
GPU訓練
首先說一下的是哪些東西可以放置GPU上面
模型,資料,損失函式
只要是你一點,后面有cuda()這個提示的就可以~前提是你得先判斷一下是不是可以在GPU上面跑,也就是你的本地環境行不行,
torch.cuda.is_available()
于是代碼改成了這樣
import torchvision
from torch import nn
import torch
from torch.utils.data import DataLoader
from torch.nn import Conv2d, MaxPool2d, Flatten, Linear, Sequential, CrossEntropyLoss
from torchvision import transforms
from torch.utils.tensorboard import SummaryWriter
trans = transforms.Compose([transforms.ToTensor()])
#獲取訓練集
dataset = torchvision.datasets.CIFAR10(root="./dataset",train=True,transform=trans,download=True)
dataset2 = torchvision.datasets.CIFAR10(root="./dataset",train=False,transform=trans,download=True)
train_dataloader = DataLoader(dataset,batch_size=64)
test_dataloader = DataLoader(dataset2,batch_size=64)
test_len = len(dataset2)
if(torch.cuda.is_available()):
device = torch.device("cuda")
print("使用GPU訓練中:{}".format(torch.cuda.get_device_name()))
else:
device = torch.device("cpu")
print("使用CPU訓練")
class MyModule(nn.Module):
def __init__(self):
super().__init__()
self.model = Sequential(
Conv2d(3, 32, kernel_size=(5, 5), padding=2),
MaxPool2d(2),
Conv2d(32, 32, (5, 5), padding=2),
MaxPool2d(2),
Conv2d(32, 64, (5, 5), padding=2),
MaxPool2d(2),
Flatten(),
Linear(1024, 64),
Linear(64, 10)
)
def forward(self,x):
x = self.model(x)
return x
if __name__ == '__main__':
writer = SummaryWriter()
mymodule = MyModule()
mymodule = mymodule.to(device) #模型轉移GPU
loss = torch.nn.CrossEntropyLoss()
learnstep = 0.01
optim = torch.optim.SGD(mymodule.parameters(),lr=learnstep)
epoch = 1000
train_step = 0 #每輪訓練的次數
mymodule.train()#模型在訓練狀態
for i in range(epoch):
print("第{}輪訓練".format(i+1))
train_step = 0
for data in train_dataloader:
imgs,targets = data
imgs = imgs.to(device)
targets =targets.to(device)
outputs = mymodule(imgs)
result_loss = loss(outputs,targets)
optim.zero_grad()
result_loss.backward()
optim.step()
train_step+=1
if(train_step%100==0):
print("第{}輪的第{}次訓練的loss:{}".format((i+1),train_step,result_loss.item()))
# 在測驗集上面的效果
mymodule.eval() #在驗證狀態
test_total_loss = 0
right_number = 0
with torch.no_grad(): # 驗證的部分,不是訓練所以不要帶入梯度
for test_data in test_dataloader:
imgs,label = test_data
imgs = imgs.to(device)
label = label.to(device)
outputs_ = mymodule(imgs)
test_result_loss=loss(outputs_,label)
right_number += (outputs_.argmax(1)==label).sum()
# writer.add_scalar("在測驗集上的準確率",(right_number/test_len),(i+1))
print("第{}輪訓練在測驗集上的準確率為{}".format((i+1),(right_number/test_len)))
if((i+1)%500==0):
# 保存模型
torch.save(mymodule.state_dict(),"mymodule_{}.pth".format((i+1)))
然后我們簡單地,測驗一下,也就是跑一下
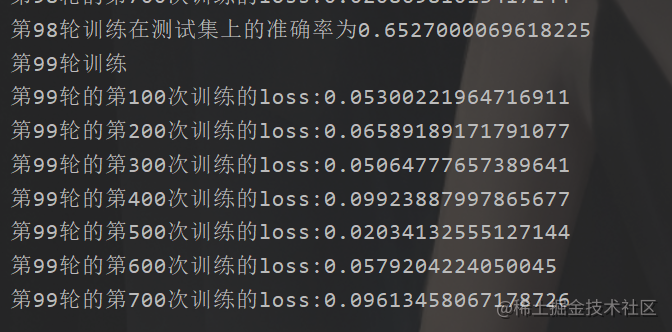
這個速度,不行,得訓練到猴年馬月,
“借雞生蛋“
自家電腦哪里頂得住這個,
我們還是直接使用谷歌的平臺吧,這個得那啥~只要有谷歌賬號就是免費的,
而且是國外的,一些資料集下載賊快
然后睡一覺就好了,
模型使用
這個其實和我們校驗的時候使用一樣,我們主需要呼叫我們的模型,然后把你的圖片搞進去,

這個是我們對于的那個下標的動物,
from PIL import Image
import torchvision
import torch
from MyModule import MyModule
path_img = "dog.jpg"
image = Image.open(path_img)
compose = torchvision.transforms.Compose([
torchvision.transforms.Resize((32,32)),
torchvision.transforms.ToTensor()
])
#看你是那種保存的模型
module_path = "mymodule_500.pth"
image = compose(image)
module = MyModule()
module.load_state_dict(torch.load("mymodule_500.pth"))
image = torch.reshape(image,(1,3,32,32))
module.eval()
with torch.no_grad():
out = module(image)
print(out.argmax(1))
然后我們可以看到輸出
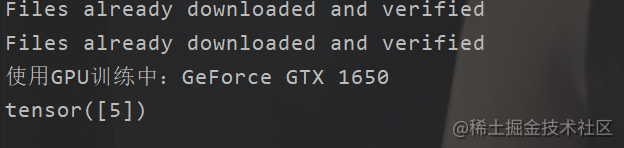
然后我這邊也是下載了一張圖片

不過值得一提的是,我這里訓練了500次的模型只是得到了62%左右的準確率
那么后面我就可以跟換資料集,對神經網路進行稍微調整~實作不同的目的,
此外我們還有很多神經網路模型,例如 VGG,那個層數太多了,而且官方有封裝好了的,就在torchvision里面,
轉載請註明出處,本文鏈接:https://www.uj5u.com/qita/423118.html
標籤:AI