什么是梯度?
一、數學知識:
一、簡介
- 導數(derivate):高中所學的二維空間中的增長速率,(標量)
- 偏微分(partial derivate):對于空間中,某一方向的增長,(標量)
- 梯度(gradient):對函式的各個自變數的偏微分的集合,(矢量)
二、實體
- 函式
z
=
y
2
?
x
2
z = y^2 - x^2
z=y2?x2
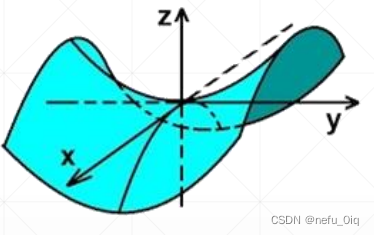
- 偏導數: ? z ? x = ? 2 x \frac{\partial z}{\partial x}=-2x ?x?z?=?2x, ? z ? y = 2 y \frac{\partial z}{\partial y}=2y ?y?z?=2y
- 梯度: ? f = ( ? z ? x , ? z ? y ) = ( ? 2 x , 2 y ) \nabla f=(\frac{\partial z}{\partial x},\frac{\partial z}{\partial y})=(-2x,2y) ?f=(?x?z?,?y?z?)=(?2x,2y)
三、梯度的含義
- 神經網路的特征之一,從資料樣本中學習, 而loss函式就是我們可以自動確定的抓手,當然,使得loss函式達到最小值時,就是我們要尋找的引數,這時就引入了導數的概念,
- 導數的引入,可以使我們容易獲得極值點,
f
′
(
x
)
=
0
f'(x)=0
f′(x)=0,可是使得我們通過微分方程來輕松獲得極值點,但是導數僅僅是對一維函式所說的,但是在現實生活中,往往存在很多維度的屬性,這時候并不能用導數來完成這一作業,所以我們引入了梯度,
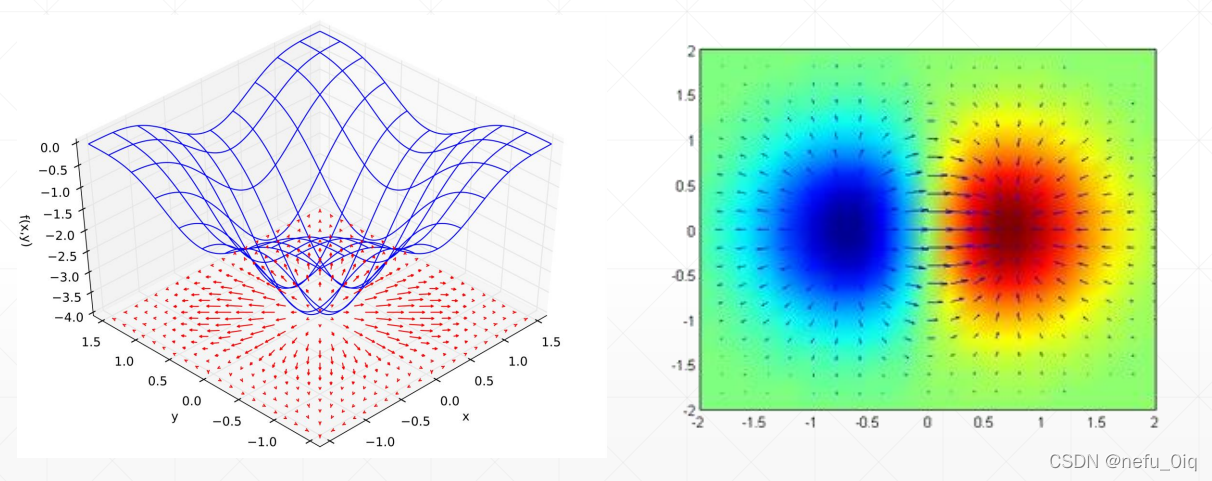
四、迭代法求取最小值
1、簡單例子
通過使用 θ t + 1 = θ t ? a t ? f ( θ t ) \theta_{t+1}=\theta_{t}-a_t\nabla f(\theta_t) θt+1?=θt??at??f(θt?)
- 函式: f ( θ 1 , θ 2 ) = θ 1 2 + θ 2 2 f(\theta_1,\theta_2)=\theta_1^2+\theta_2^2 f(θ1?,θ2?)=θ12?+θ22?
- 目標函式: m i n θ 1 , θ 2 ( f ( θ 1 , θ 2 ) ) \underset{\theta_1,\theta_2}{min}(f(\theta_1,\theta_2)) θ1?,θ2?min?(f(θ1?,θ2?))
- 更新規則:
- θ 1 = θ 1 ? a d d θ 1 f ( θ 1 , θ 2 ) \theta_1=\theta_1-a\frac d{d\theta_1}f(\theta_1,\theta_2) θ1?=θ1??adθ1?d?f(θ1?,θ2?)
- θ 2 = θ 2 ? a d d θ 2 f ( θ 1 , θ 2 ) \theta_2=\theta_2-a\frac d{d\theta_2}f(\theta_1,\theta_2) θ2?=θ2??adθ2?d?f(θ1?,θ2?)
2、相關問題
-
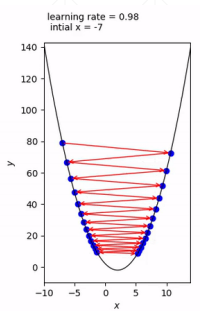
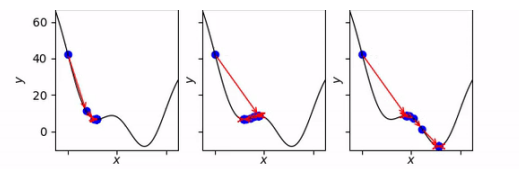
Learning rate的設定:Learning rate設定不合理會影響最終生成的答案,如果LR太大則可能會跨越,太小可能會計算速度變慢,如下圖所示
-
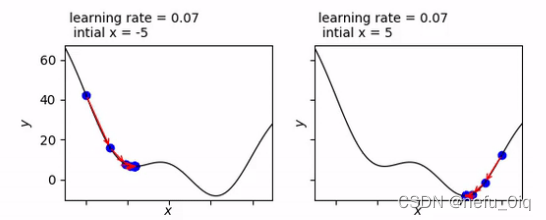
初始值的設定:初始值設定不合理會影響最終生成的答案,如圖下圖所示
-
就上圖而言如何逃離最小值呢?可以引入慣性,可以變換到其他位置,如圖所示:
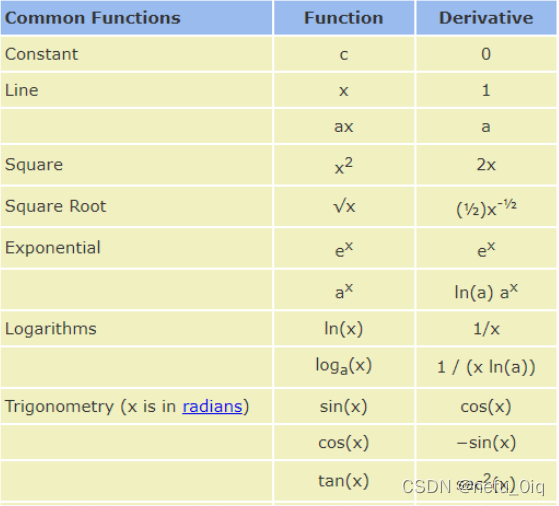
五、常見的梯度函式
轉載請註明出處,本文鏈接:https://www.uj5u.com/qita/423160.html
標籤:AI
上一篇:19.初識Pytorch之完整的模型套路-整理后的代碼 Complete model routine - compiled code