目錄
- 表格合并
- 縱向合并
- 縱向合并
- 資料清洗
- 洗掉缺失資料行
- 資料填充
- 統一資料格式
- 去除重復資料
- pandas 中很實用的方法——apply() 方法
- 附:匿名函式
表格合并
縱向合并
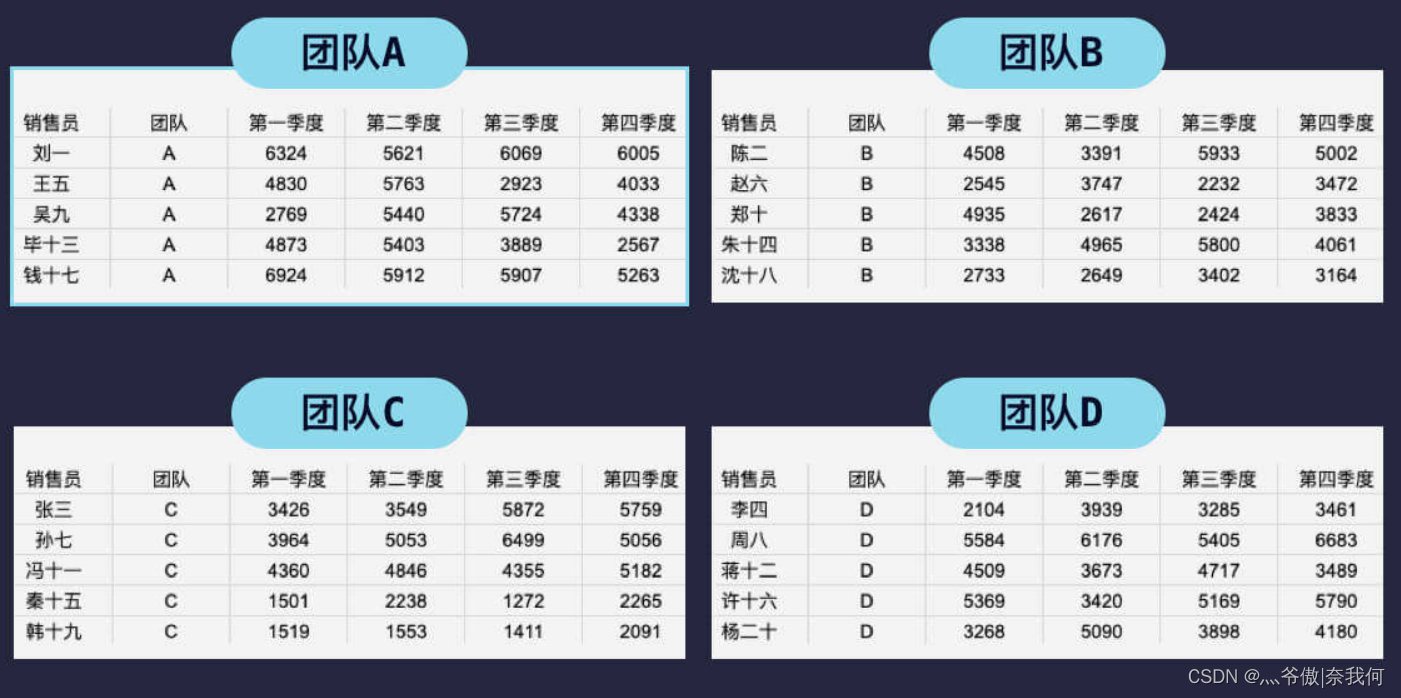
在日常作業中,表格合并是個較為常見的需求,還是以之前的銷售資料為例,一般是每個團隊只統計自己團隊的銷售資料,然后匯總給負責人進行資料匯總,得到最后的總表,
ABCD 四個團隊的銷售表分別如下,我們縱向合并表格,也就是將表格內容從上往下進行疊加,
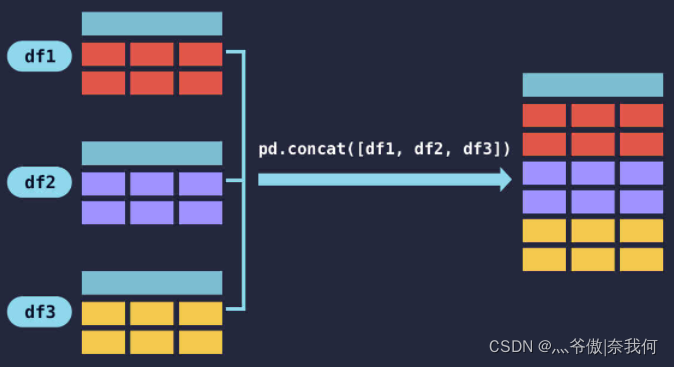
這在 pandas 中使用 concat() 方法,將要合并的表放入串列中作為引數
pd.concat([df1, df2])
應用到我們的例子中,完整代碼如下:
import pandas as pd
df_a = pd.read_csv('2019年團隊A銷售資料.csv')
df_b = pd.read_csv('2019年團隊B銷售資料.csv')
df_c = pd.read_csv('2019年團隊C銷售資料.csv')
df_d = pd.read_csv('2019年團隊D銷售資料.csv')
df = pd.concat([df_a, df_b, df_c, df_d])
print(type(df))
# 輸出:<class 'pandas.core.frame.DataFrame'>
可以看到,合并后也是一個 DataFrame 型別的表格,
縱向合并
除了表格的縱向合并,還有一種情況——表格的橫向合并,
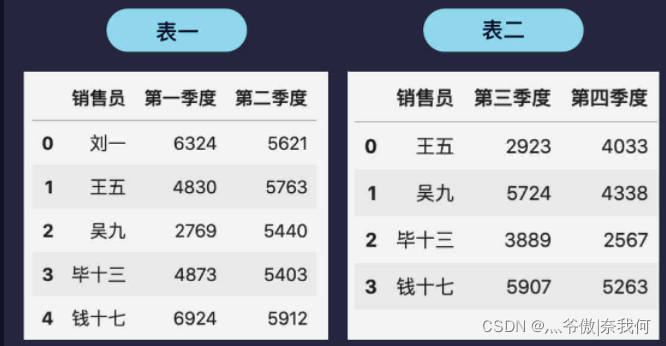
假設團隊 A 的銷售資料分為上半年和下半年的資料,兩個表分別如下圖所示:
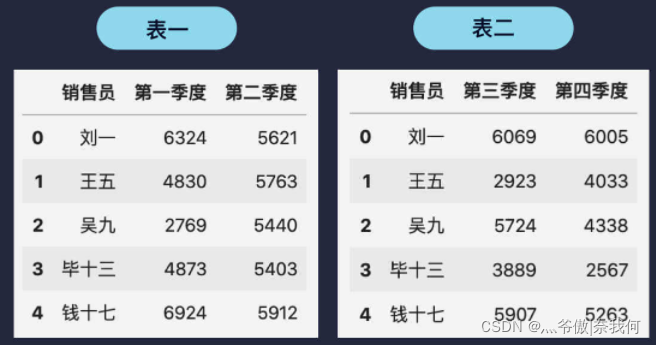
將這兩個表格進行橫向合并最簡單的方法是 pd.merge(表一, 表二),合并后得到如下所示的新表:
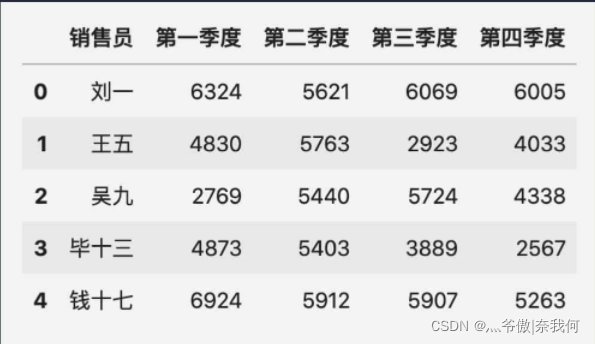
上面的例子是 merge() 方法最簡單的情況,只傳入兩個需要橫向合并的表格作為引數,merge() 方法還有兩個比較重要的引數分別是 on 和 how,
引數 on 表明用于合并的列名,可以使用串列指定多個列名,這些列名必須同時存在于兩個表格當中,如果沒有指定引數 on,那么 pandas 會自動將兩個表格都有的列名作為引數 on 的值,
在上面的列子中引數 on 默認就是銷售員,合并時 pandas 會將銷售員這列值一樣的行進行橫向合并,并不是簡單地按順序合并,因此兩張表的排列順序不一樣也能正確地進行合并,
上面例子中的兩個表格情況比較簡單,銷售員都是一樣的,假設劉一在第三四季度離職了,表格變成了下面這樣:
這時候,pd.merge(表一, 表二) 后的結果如下:
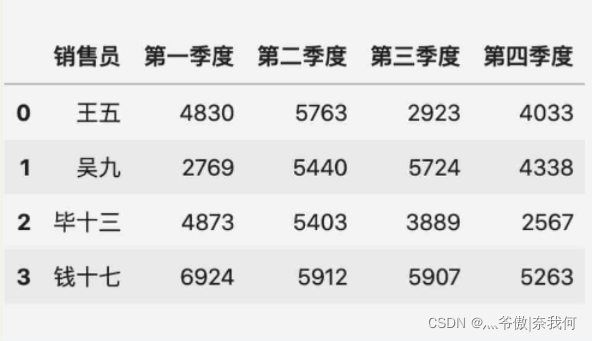
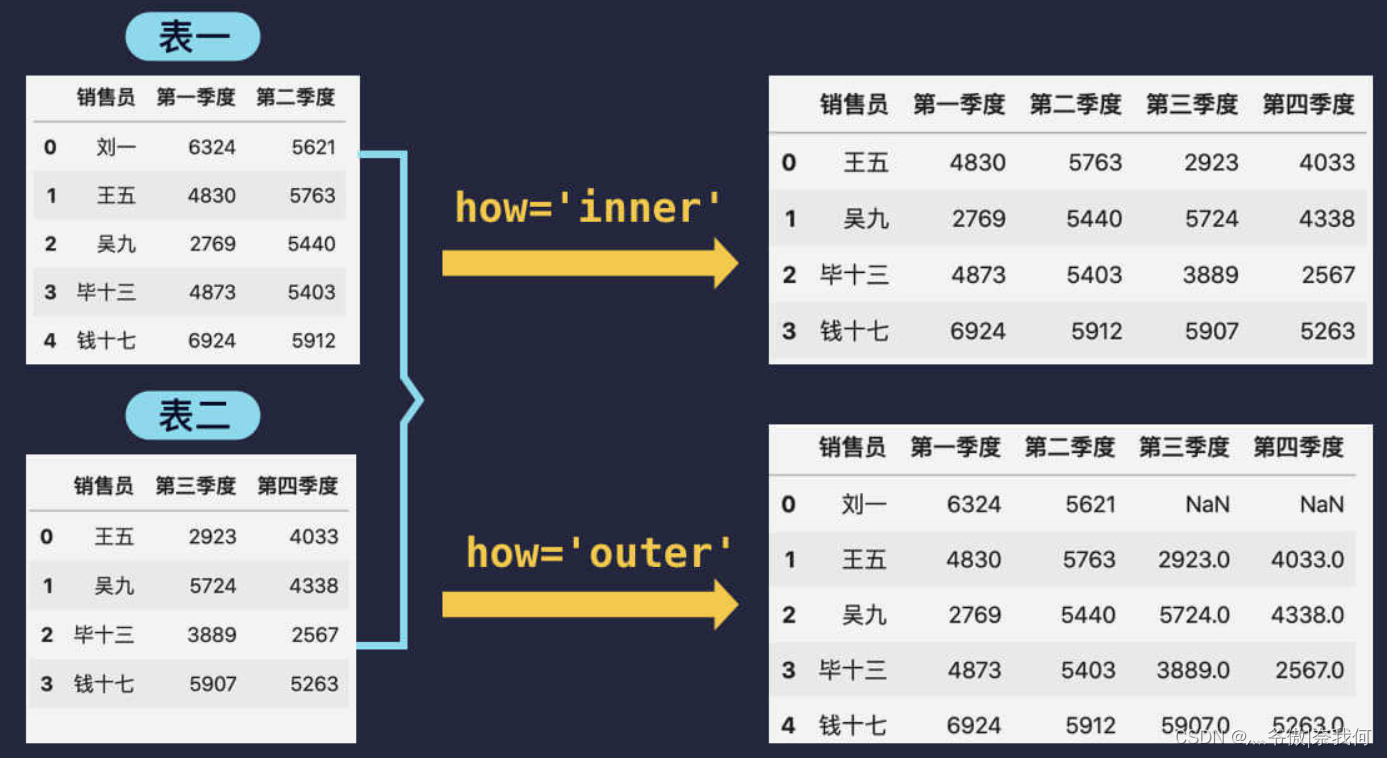
可以看到,合并后劉一的資料被剔除了,這其實是引數 how 導致的,引數 how 指定了合并的方式,總共有四種方式可選,默認為 inner,
- left
- right
- outer
- inner(默認)
inner(內連接)表示只保留引數 on 指定的列(上面的例子中是銷售員)中兩個表格都出現的部分,因為劉一只在表一中出現,因此合并后就剔除了劉一這行資料,
outer(外連接)和 inner 相反,它會保留兩個表格中所有的資料,資料缺失部分以 NaN 填充,即以 NaN 填充上面的例子中劉一在第三四季度的資料,
注意,如果某列中用 NaN 補全了空位,那這一列資料就會變為浮點型資料,
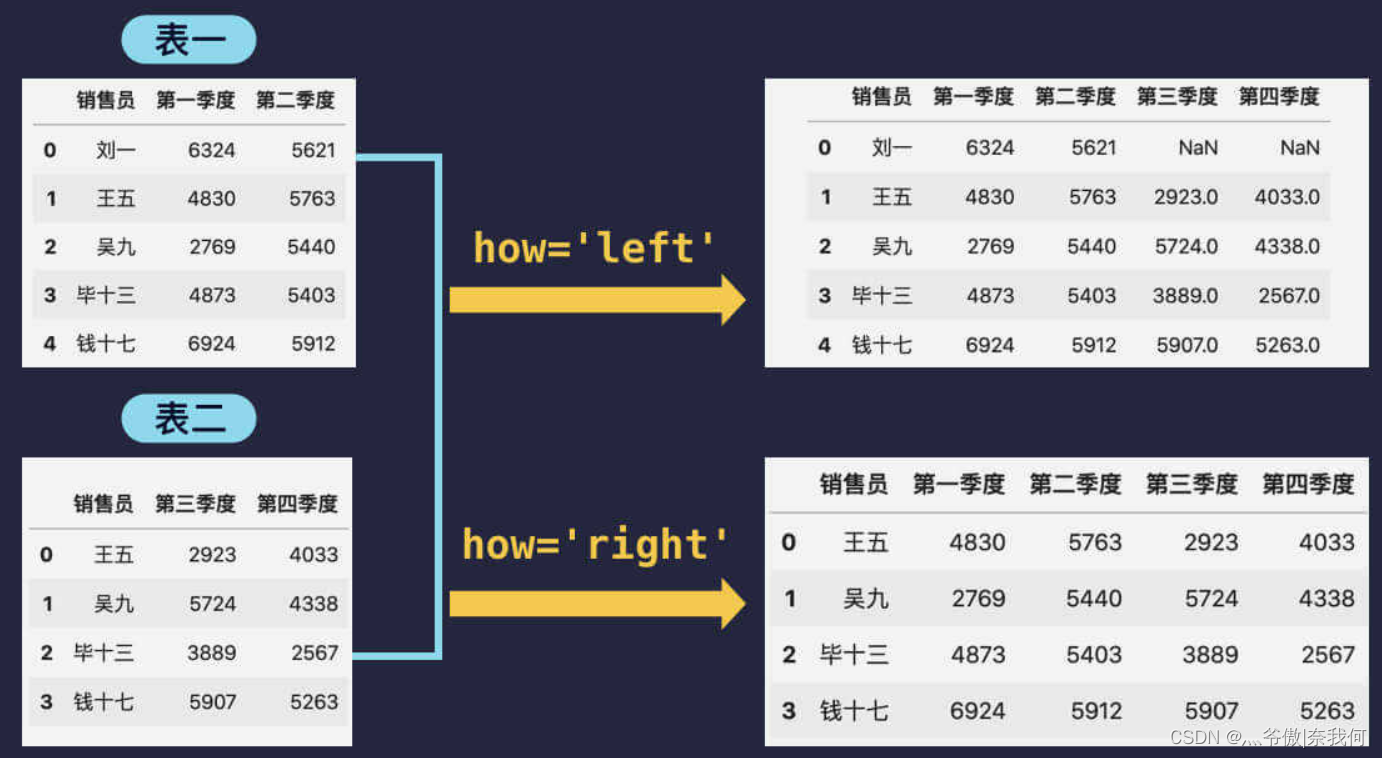
left(左連接)表示將表二合并到表一中,具體指保留表一的全部資料,將表二中兩表中共同的銷售員資料進行合并,剔除表二中獨有的資料,缺失資料同樣也是用 NaN 填充,right(右連接)正好相反,表示將表一合并到表二中,
資料清洗
之前我們的資料都是很完整,格式也都是統一的,但有些時候,我們的資料可能存在部分缺失、格式不統一、甚至資料錯誤等情況,這時候這些資料就成了“臟”資料,我們需要對其進行資料清洗,
資料缺失是最常見的問題之一,導致這個問題的原因可能是:人工填寫時遺漏、本身就沒有這項資料等等,
我對豆瓣圖書 Top250 資料進行了些洗掉,故意造成資料缺失,以便于我們對它進行資料清洗,
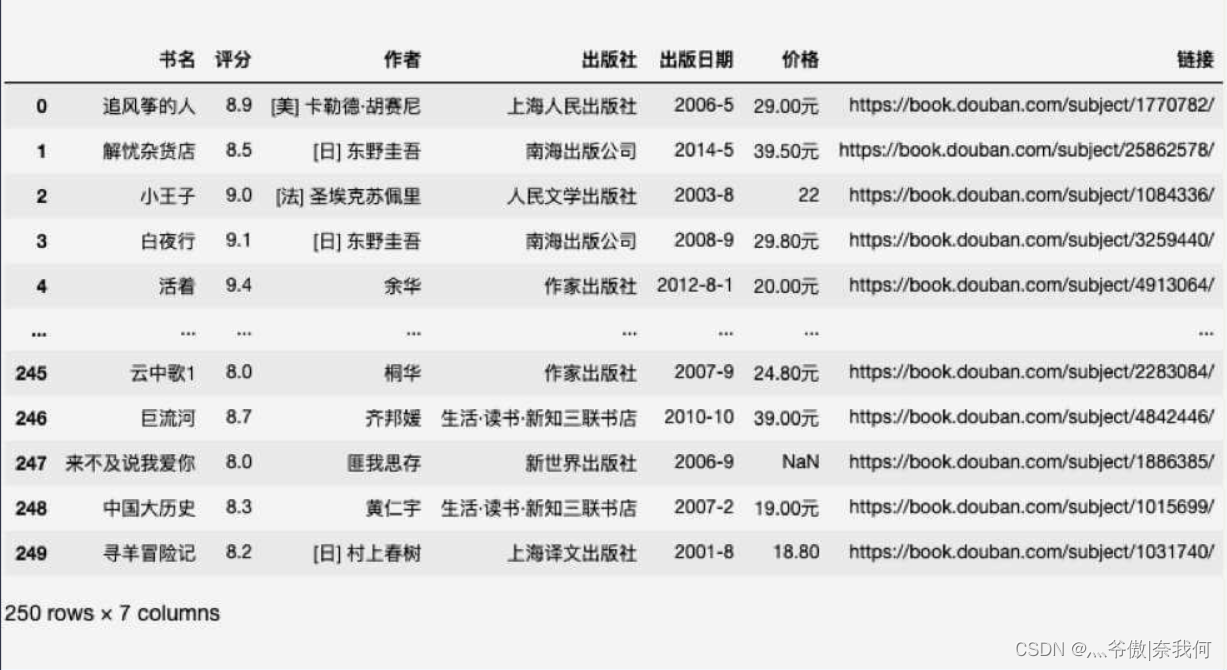
讀取表格檔案后,呼叫 info() 方法和 describe() 方法可以看到如下資訊:
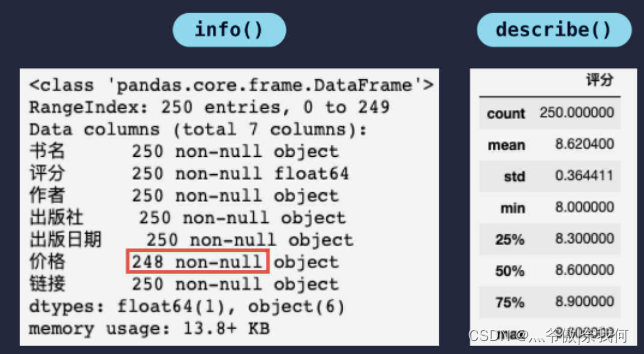
從中可知:總共 250 條資料,價格缺失了 2 條資料,資料缺失會引起后續資料分析的錯誤,常見的處理資料缺失的方法有 洗掉缺失資料行 和 為缺失資料賦值,
洗掉缺失資料行
假設我們認為有缺失資料的那一行資料都不可信,需要將其洗掉,只需一行代碼即可:
df.dropna()
dropna() 方法的作用是洗掉所有包含 NaN 的行,執行后上表中資料缺失的那 2 行資料就會被洗掉,
dropna() 方法同樣也是回傳洗掉后的表格,不會對原表格有影響,如需直接在原表格上洗掉,傳入 inplace=True 即可,
但上面的方法過于簡單粗暴,可能只是一個不影響分析的資料缺失了,也會被無情地洗掉,所以我們要有策略地進行洗掉,
我們可以傳入 how='all' 來控制當這一行資料都為 NaN 時才洗掉這一行,how 默認為 any,表示只要有一個 NaN 就會洗掉這一行,
df.dropna(how='all')
我們也可以傳入 thresh 引數來控制當一行中非空值數量小于多少時才洗掉此行,比如當一行資料中,非空值數量小于 5 個時洗掉這一行,代碼就可以這樣寫:
df.dropna(thresh=5)
當我們只想分析價格時,其他資料的缺失對我們的分析沒有影響,這時可以通過 subset 引數決定哪幾列有資料缺失時才進行洗掉,比如,當書名和價格這兩列有資料缺失時可以這樣寫:
df.dropna(subset=['書名', '價格'])
綜上:

資料填充
除了洗掉缺失資料行,有些情況下我們還能為缺失資料賦值,比如價格缺失了,我們可以將缺失價格設定為 0,方法如下:
df['價格'].fillna(0)
首先是選取有資料缺失的列,然后呼叫 fillna() 方法,該方法會將傳入的引數填充到該列所有缺失的資料中,
我們同樣可以傳入 inplace=True 來直接更改原表格,pandas 中大部分方法都是回傳修改后的表格,而不會修改原表格,我們都可以傳入 inplace=True 來直接修改原表格,如果不想修改原表格,只需將修改后的表格保存到新的變數中即可,
但將缺失價格直接設成 0 并不是最優解,它會拉低整體的價格,我們可以將其設定成比較接近的值,比如價格的平均值:
df['價格'].fillna(df['價格'].mean())
像這樣處理后,資料的偏差會小一些,上面的代碼是理想情況,實際上會報錯,為什么呢?我們再來看一下我們的資料表格,
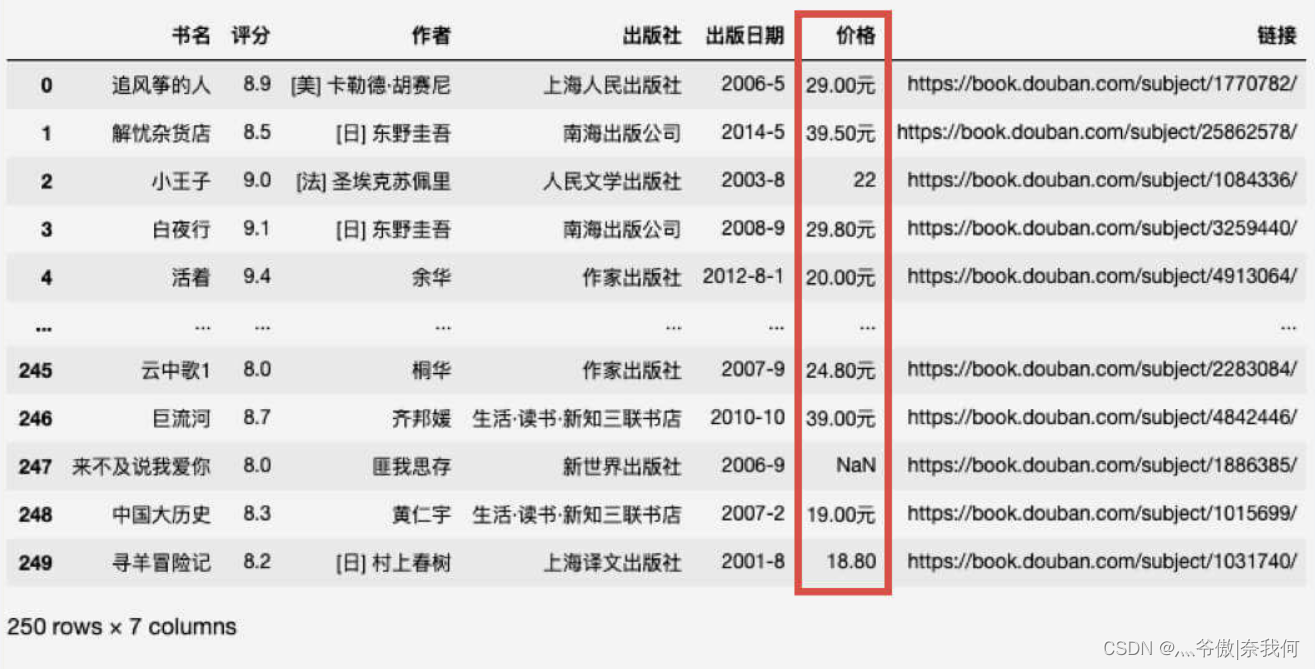
可以看到,除了資料缺失知道,價格這一列的資料格式還不統一,有的是整數,有的是小數,還有的后面加上了元,這樣的資料我們也沒有辦法進行分析,需要將其格式統一,我們需要去除“元”字,再統一保留一位小數,
統一資料格式
首先是去除“元”字,這其實就是字串處理,在 Python 中,可以使用 replace() 方法進行字串替換,我們可以像下面這樣去除“元”字:
'29.00元'.replace('元', '')
而在 pandas 中也有這些字串方法,它藏在了 str 屬性下面,所以在 pandas 中我們可以這么寫:
df['價格'].str.replace('元', '')
先訪問 str 屬性,再呼叫里面的字串方法,Python 里的字串方法,比如 replace()、upper()、lower()、split() 等等在其中,
需要注意的是,因為字串不可變,這些方法都只是回傳新的資料,不會更改原字串,因此,我們還需要像下面這樣才能將原表格中價格這一列的資料替換成修改后的資料:
df['價格'] = df['價格'].str.replace('元', '')
這樣處理完之后看上去是數字,但實際上型別還是字串,我們需要使用 astype() 方法進行型別轉換,價格是小數,所以我們將其轉換成浮點數型別(float),
df['價格'] = df['價格'].str.replace('元', '').astype('float')
對價格進行處理后的表格是這樣的:
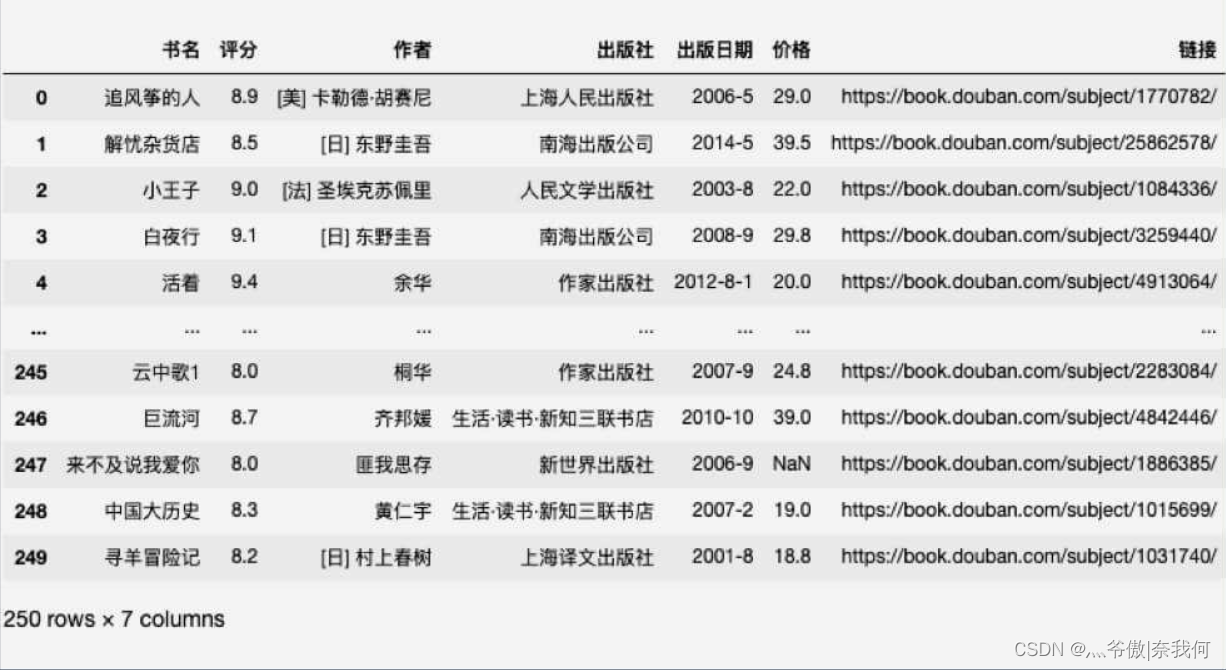
除了缺失資料還是 NaN,其他價格都統一成了保留一位小數的浮點數,這時我們再執行 df.describe() 看一下處理過后的資料:
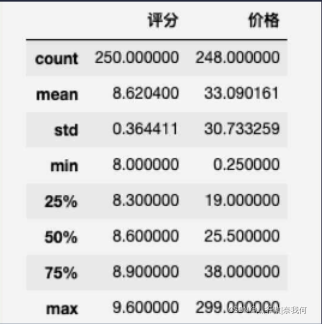
因為價格這一列被我們處理成數字了,所以統計資訊中出現了價格相關的資訊,并且這時再執行 df[‘價格’].fillna(df[‘價格’].mean()) 也不會報錯了,
但算出來的平均價格是 33.090161,然而我們并不需要精確到小數點后這么多位,因此我們可以使用 round() 方法進行四舍五入,引數是要保留的小數位數,所以最后的代碼如下:
df['價格'].fillna(df['價格'].mean().round(1), inplace=True) # 保留 1 位小數
去除重復資料
首先我們故意創建一個含有重復資料的表格進行演示:
import pandas as pd
df = pd.DataFrame({'用戶名': ['劉一', '陳二', '劉一', '張三'], '交易金額': [25.8, 15.5, 56.3, 46.2]})
repeat = pd.concat([df, df])
print(repeat)
用戶名 交易金額
0 劉一 25.8
1 陳二 15.5
2 劉一 56.3
3 張三 46.2
0 劉一 25.8
1 陳二 15.5
2 劉一 56.3
3 張三 46.2
我將同一份表格進行了合并,得到了一個含有重復資料的表格,我們可以呼叫 drop_duplicates() 方法洗掉完全重復的行,即每一列的資料都完全相同的行,
print(repeat.drop_duplicates())
結果:
用戶名 交易金額
0 劉一 25.8
1 陳二 15.5
2 劉一 56.3
3 張三 46.2
我們還可以通過 subset 引數指定按列去重,即只要這一列的資料重復就會洗掉重復的內容,
print(repeat.drop_duplicates(subset=['用戶名']))
用戶名 交易金額
0 劉一 25.8
1 陳二 15.5
3 張三 46.2
可以看到,按照用戶名進行去重劉一的兩條記錄只剩一條了,去重默認是保留第一條不重復的資料,如果你想保留最后一條不重復的資料,可以傳入 keep='last',
print(repeat.drop_duplicates(subset=['用戶名'], keep='last'))
用戶名 交易金額
1 陳二 15.5
2 劉一 56.3
3 張三 46.2
假設資料的順序是按交易時間排的,上面的代碼就能得到每個用戶最近一次的交易記錄,

前面說的是如何去重,那么我們想要知道不重復的資料有哪些該怎么辦呢?其實也很簡單,只要在對應的列上呼叫 unique() 方法即可,
print(repeat['用戶名'].unique())
# 輸出:['劉一' '陳二' '張三']
print(len(repeat['用戶名'].unique()))
# 輸出:3
可以看到,總共 8 條資料交易記錄,實際上只是 3 名用戶產生的交易,除了使用 len(repeat[‘用戶名’].unique()) 統計不重復的個數之外,我們也可以直接使用 nunique() 方法得到它,
print(repeat['用戶名'].nunique())
# 輸出:3
綜上:

pandas 中很實用的方法——apply() 方法
apply() 方法的第一個引數是一個函式,當我們傳入函式后,apply() 方法會將該函式應用到表格列里的每一個資料中,并將表格資料作為引數傳給函式,(有點映射的味道)
比如:
# 沒使用apply() 方法
df['價格'] = df['價格'].str.replace('元', '').astype('float')
# 使用了apply() 方法
def format_price(x):
return float(x.replace('元', ''))
df['價格'] = df['價格'].apply(format_price)
看上去代碼更多了,但只是定義函式比較長,我們使用匿名函式的話也可以一行搞定:
f['價格'] = df['價格'].apply(lambda x: float(x.replace('元', '')))
之前我們使用的是 pandas 中的方法進行資料處理的,前提是你得先知道有 str 屬性、astype() 方法等,而使用 apply() 方法則很靈活,我們可以直接獲取到資料,使用 Python 的方式進行處理,同時處理的規則可以非常靈活,只要按需求定義一個函式即可,
附:匿名函式
Python 中的匿名函式:

下面這張是匿名函式和普通函式的對比圖:

使用匿名函式并不能提高代碼的運行效率,只是讓代碼看上去更加的簡潔而已,有些只會用一次的函式,不知道如何給它命名時,直接用匿名函式會很方便,
我們還可以將匿名函式賦值給變數,這樣匿名函式也擁有了姓名,
轉載請註明出處,本文鏈接:https://www.uj5u.com/qita/423179.html
標籤:其他
上一篇:當redis 主節點宕機重啟以后,該節點不能跟選舉后的master資料主從同步
下一篇:JUC并發編程-生產者消費者實體