感覺每天又有了希望,又有動力,感覺學習盡頭十足
Spark是什么
Spark是一個用來實作快速而通用的集群計算的平臺,
在之前,學習了MR,學習了hadoop,用mapreduce來對資料進行處理,但是hadoop是用批處理的,而且還有延遲,況且,出來了Hive,Hive將sql轉化為mr算子,可以不用去寫mr代碼就可以對資料進行分析,
Spark是集群計算,是在hadoop集群中進行的,Spark的一個主要特點就是能夠在記憶體中進行計算,在記憶體中計算比在磁盤上運算要快很多,同時現在學習Spark的代價也很小了,大資料相關的軟體都在慢慢實作SQL化,SPark,Flink 都支持SQL進行處理,
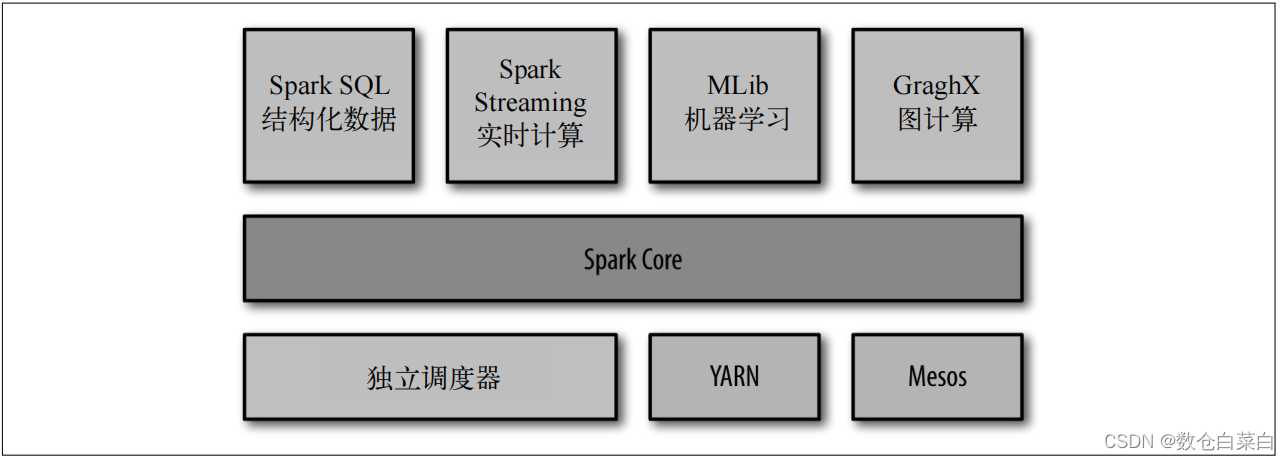
Spark是一個軟體的大集合,從上面的圖中可以看到,在以Spark Core為基礎和重點的基礎上,增加了SQL,實時計算,機器學習,圖計算,
Spark Core是什么
spark core實作了spark的基本功能,包括任務調度,記憶體管理,錯誤恢復和存盤系統互動等模塊,
Spark SQL是什么
SPark SQL是用Spark來操作結構化資料的程式包,通過Spark SQL可以使用Hive SQL來查詢資料,同時Hive的默認引擎是mr,也可以換成Spark,
同時呢,只介紹這兩個,因為這兩個將會在后面的博客出現幾個月甚至一年,等實力夠了再去學習其它的,
初識Spark
在博客中講解的Spark都是基于windows本地的,不是在命令列上面sbt,
關于spark的本地安裝,可以去b站看看尚硅谷的Spark視頻,
命令列和本地運行的差別
- 在本地運行時,可以在idea上寫代碼,但是需要自行初始化SparkContext
- 命令列提交之后就會出結果,本地運行直接在Idea中出結果
初始化SparkContext
想要在本地撰寫Spark Core代碼,需要本地的Hadoop 和 Spark環境,
匯入Spark的包,創建SparkContext,
先創建一個SparkConf物件來配置你的應用,然后基于這個SparkConf來創建SparkContext物件,
val cf =new SparkConf().setMaster("local").setAppName("") val sc = new SparkContext(cf)
為什么要這樣做呢?
- 集群url,告訴Spark如何連接集群,因為是本地集群,所以SetMaster的時候是local
- 為此次程式命名
初始化Spark Context后,就可以創建RDD來進行代碼了,
關閉的時候 通過 sc.stop()就可以推出應用
通過RDD來實作W C
首先看一下資料源
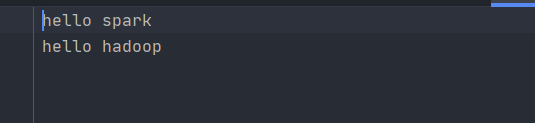
在MapReduce中,word count就是第一個入門案例,在Spark里面,WordCount也是第一個入門案例,
代碼實作
val wordCount = new SparkConf().setMaster("local").setAppName("WordCount")
val sparkContext = new SparkContext(wordCount)
val value = sparkContext.textFile("date/1.txt")
val value1 = value.flatMap(_.split(" "))
val value2 = value1.groupBy(value1 => value1)
val value3 = value2.map { case (word, list) => (word, list.size) } value3.collect().foreach(println(_)) s
parkContext.stop()上面就是用Scala代碼來實作的WordCount,
首先進行層層分析
- 創建SparkConf物件,對集群進行配置,創建SparkContext物件
val wordCount = new SparkConf().setMaster("local").setAppName("WordCount")
val sparkContext = new SparkContext(wordCount)2.通過textFile來獲取資料源
val value = sparkContext.textFile("date/1.txt")3.邏輯代碼
//flatMap函式,將資料根據空格分開
val value1 = value.flatMap(_.split(" "))
//groupBy分組,對每個單詞進行分組
val value2 = value1.groupBy(value1 => value1)
//map + match進行匹配 value2的型別是(String,Iterable)
val value3 = value2.map { case (word, list) => (word, list.size) }
//如果匹配到老了,就轉換型別
(String,Iterable) => (String,Int)RDD是什么
RDD是彈性 分布式 資料集,
在Spark中,對資料的所有操作就是創建RDD,轉化已有的RDD,呼叫RDD進行求值
如何創建RDD
兩種方法創建RDD
- 讀取一個外部資料集
- 在驅動程式里分發驅動程式中的物件集合
上面的例子中,通過讀取外部檔案來創建RDD
創建RDD過后,RDD支持兩種操作,轉換和動作,
轉錯操作就是各種算子,由一個RDD變成另外一個新的RDD,行動算子會對RDD計算出結果,并將結果回傳控制臺,
上面的例子中,flatMap,map,groupBy都是轉換算子,foreach,collect等都是動作算子
雖然一個程式會有多個算子,但是Spark是惰性運算RDD的,只有在第一次用到的時候,這個RDD算子才會運作,還有一點先說一下,RDD算子并不存盤資料,只是一個工具,資料都是在各個節點根據RDD進行運算的,
默認情況下,Spark中的RDD會在每次行動算子運算的時候會重新運算,如果想多個行動操作用一個RDD,那么可以RDD.persist()讓Spark對RDD進行快取,也就是持久化,
總結:
先寫一篇簡短的文章,明天會輸出篇幅比較大的文章,
轉載請註明出處,本文鏈接:https://www.uj5u.com/qita/423182.html
標籤:其他