目錄
1. 基本定義
2. 演算法原理
2.1 演算法優缺點
2.2 演算法引數
2.3 變種
3.演算法中的距離公式
4.案例實作
4.1 匯入相關庫
4.2 讀取資料
4.3 讀取變數名
4.4 定義X,Y資料
4.5 分離訓練集和測驗集
4.6 計算歐式距離
4.7 可視化距離矩陣
4.8 預測樣本
4.9 查看正確率
4.10 交叉驗證
5. scikit-learn的演算法實作
5.1 對上述的再次實作:
5.2 另一種實作方式
1. 基本定義
k最近鄰(k-Nearest Ne ighbor)演算法是比較簡單的機器學習演算法,它采用測量不同特征值之間的距離方法進行分類,它的思想很簡單:如果一個樣本在特征空間中的多個最近鄰(最相似〉的樣本中的大多數都屬于某一個類別,則該樣本也屬于這個類別,第一個字母k可以小寫,表示外部定義的近鄰數量,
簡而言之,就是讓機器自己按照每一個點的距離,距離近的為一類,
2. 演算法原理
knn演算法的核心思想是未標記樣本的類別,由距離其最近的k個鄰居投票來決定,
具體的,假設我們有一個已標記好的資料集,此時有一個未標記的資料樣本,我們的任務是預測出這個資料樣本所屬的類別,knn的原理是,計算待標記樣本和資料集中每個樣本的距離,取距離最近的k個樣本,待標記的樣本所屬類別就由這k個距離最近的樣本投票產生,
假設X_test為待標記的樣本,X_train為已標記的資料集,演算法原理的偽代碼如下:
- 遍歷X_train中的所有樣本,計算每個樣本與X_test的距離,并把距離保存在Distance陣列中,
- 對Distance陣列進行排序,取距離最近的k個點,記為X_knn,
- 在X_knn中統計每個類別的個數,即class0在X_knn中有幾個樣本,class1在X_knn中有幾個樣本等,
- 待標記樣本的類別,就是在X_knn中樣本個數最多的那個類別,
2.1 演算法優缺點
- 優點:準確性高,對例外值和噪聲有較高的容忍度,
- 缺點:計算量較大,對記憶體的需求也較大,
2.2 演算法引數
其演算法引數是k,引數選擇需要根據資料來決定,
- k值越大,模型的偏差越大,對噪聲資料越不敏感,當k值很大時,可能造成欠擬合;
- k值越小,模型的方差就會越大,當k值太小,就會造成過擬合,
2.3 變種
knn演算法有一些變種,其中之一是可以增加鄰居的權重,默認情況下,在計算距離時,都是使用相同權重,實際上,可以針對不同的鄰居指定不同的距離權重,如距離越近權重越高,這個可以通過指定演算法的weights引數來實作,
另一個變種是,使用一定半徑內的點取代距離最近的k個點,當資料采樣不均勻時,可以有更好的性能,在scikit-learn里,RadiusNeighborsClassifier類實作了這個演算法變種,
3.演算法中的距離公式
與我們的線性回歸不同,在這里我們并沒有什么公式可以進行推導,KNN分類演算法的核心就在于計算距離,隨后按照距離分類,
在二維笛卡爾坐標系,相信初中同學應該對這個應該不陌生,他有一個更加常見的名字,直角坐標系,其中,計算兩個點之間的距離公式,常用的有歐氏距離,點A(2,3),點B(5,6),那么AB的距離為
這,便是歐氏距離,但和我們平常經常遇到的還是有一些區別的,歐氏距離是可以計算多維資料的,也就是矩陣(Matrix),這可以幫我們解決很多問題,那么公式也就變成了
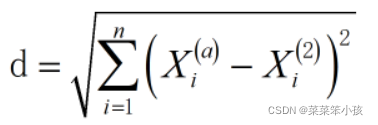
4.案例實作
我們使用knn演算法及其變種,對Pina印第安人的糖尿病進行預測,資料集可從下面下載,
鏈接:藍奏云
4.1 匯入相關庫
# 匯入相關模塊
import numpy as np
from collections import Counter
import matplotlib.pyplot as plt
from sklearn.utils import shuffle
import pandas as pd4.2 讀取資料
#讀取資料
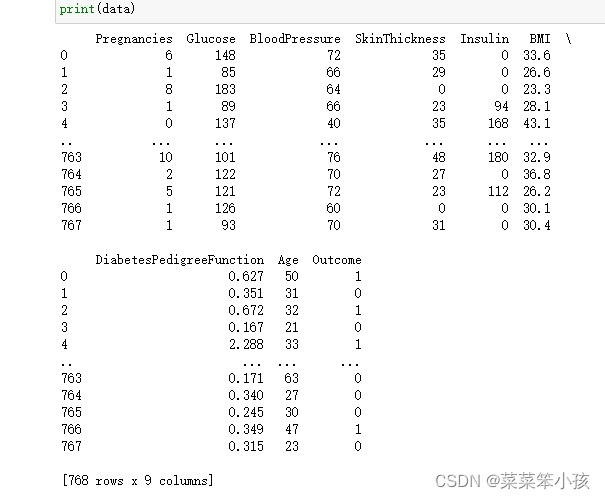
data=pd.read_excel('D:\桌面\knn.xlsx')
print(data)回傳:
4.3 讀取變數名
label_need=data.keys()
print(label_need)回傳:

4.4 定義X,Y資料
X = data[label_need].values[:,0:8]
y = data[label_need].values[:,8]
print(X)
print(y)回傳:

4.5 分離訓練集和測驗集
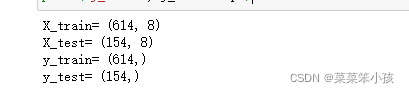
from sklearn.model_selection import train_test_split
X_train, X_test, y_train,y_test = train_test_split(X, y, test_size=0.2)
# 列印訓練集和測驗集大小
print('X_train=', X_train.shape)
print('X_test=', X_test.shape)
print('y_train=', y_train.shape)
print('y_test=', y_test.shape)回傳:
4.6 計算歐式距離
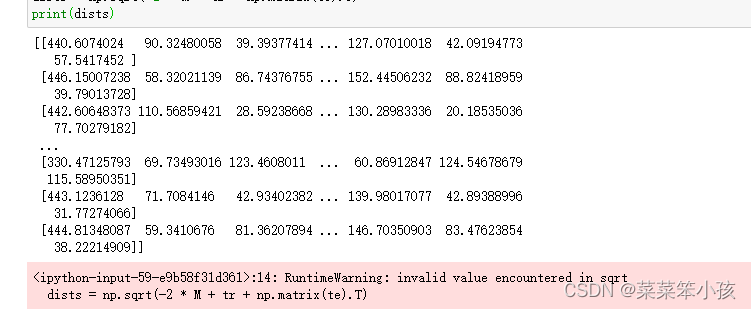
# 測驗實體樣本量
num_test = X.shape[0]
# 訓練實體樣本量
num_train = X_train.shape[0]
# 基于訓練和測驗維度的歐氏距離初始化
dists = np.zeros((num_test, num_train))
# 測驗樣本與訓練樣本的矩陣點乘
M = np.dot(X, X_train.T)
# 測驗樣本矩陣平方
te = np.square(X).sum(axis=1)
# 訓練樣本矩陣平方
tr = np.square(X_train).sum(axis=1)
# 計算歐式距離
dists = np.sqrt(-2 * M + tr + np.matrix(te).T)
print(dists)回傳:
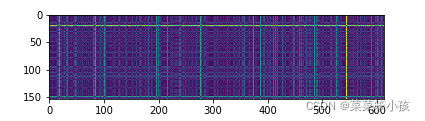
4.7 可視化距離矩陣
dists = compute_distances(X_test, X_train)
plt.imshow(dists, interpolation='none')
plt.show()回傳:
4.8 預測樣本
# 測驗樣本量
num_test = dists.shape[0]
# 初始化測驗集預測結果
y_pred = np.zeros(num_test)
# 遍歷
for i in range(num_test):
# 初始化最近鄰串列
closest_y = []
# 按歐氏距離矩陣排序后取索引,并用訓練集標簽按排序后的索引取值
# 最后拉平串列
# 注意np.argsort函式的用法
labels = y_train[np.argsort(dists[i, :])].flatten()
# 取最近的k個值
closest_y = labels[0:k]
# 對最近的k個值進行計數統計
# 這里注意collections模塊中的計數器Counter的用法
c = Counter(closest_y)
# 取計數最多的那一個類別
y_pred[i] = c.most_common(1)[0][0]
print(y_pred)回傳:

4.9 查看正確率
查看實際和預測相符的個數:
# 找出預測正確的實體
num_correct = np.sum(y_test_pred == y_test)
print(num_correct)回傳:
![]()
計算正確率:
# 計算準確率
accuracy = float(num_correct) / X_test.shape[0]
print('Got %d/%d correct=>accuracy:%f'% (num_correct, X_test.shape[0], accuracy))回傳:

4.10 交叉驗證
# 折交叉驗證
num_folds = 5
# 候選k值
k_choices = [1, 3, 5, 8, 10, 12, 15, 20, 50, 100]
X_train_folds = []
y_train_folds = []
# 訓練資料劃分
X_train_folds = np.array_split(X_train, num_folds)
# 訓練標簽劃分
y_train_folds = np.array_split(y_train, num_folds)
k_to_accuracies = {}
# 遍歷所有候選k值
for k in k_choices:
# 五折遍歷
for fold in range(num_folds):
# 對傳入的訓練集單獨劃出一個驗證集作為測驗集
validation_X_test = X_train_folds[fold]
validation_y_test = y_train_folds[fold]
temp_X_train = np.concatenate(X_train_folds[:fold] + X_train_folds[fold + 1:])
temp_y_train = np.concatenate(y_train_folds[:fold] + y_train_folds[fold + 1:])
# 計算距離
temp_dists = compute_distances(validation_X_test, temp_X_train)
temp_y_test_pred = predict_labels(temp_y_train, temp_dists, k=k)
temp_y_test_pred = temp_y_test_pred.reshape((-1, 1))
# 查看分類準確率
num_correct = np.sum(temp_y_test_pred == validation_y_test)
num_test = validation_X_test.shape[0]
accuracy = float(num_correct) / num_test
k_to_accuracies[k] = k_to_accuracies.get(k,[]) + [accuracy]
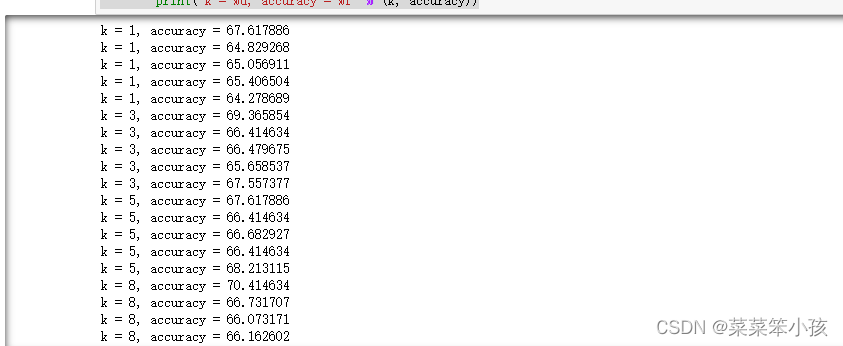
列印不同 k 值不同折數下的分類準確率:
# 列印不同 k 值不同折數下的分類準確率
for k in sorted(k_to_accuracies):
for accuracy in k_to_accuracies[k]:
print('k = %d, accuracy = %f' % (k, accuracy))回傳:
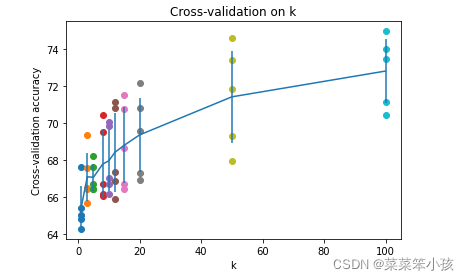
不同 k 值不同折數下的分類準確率的可視化:
for k in k_choices:
# 取出第k個k值的分類準確率
accuracies = k_to_accuracies[k]
# 繪制不同k值準確率的散點圖
plt.scatter([k] * len(accuracies), accuracies)
# 計算準確率均值并排序
accuracies_mean = np.array([np.mean(v) for k,v in sorted(k_to_accuracies.items())])
# 計算準確率標準差并排序
accuracies_std = np.array([np.std(v) for k,v in sorted(k_to_accuracies.items())])
# 繪制有置信區間的誤差棒圖
plt.errorbar(k_choices, accuracies_mean, yerr=accuracies_std)
# 繪圖示題
plt.title('Cross-validation on k')
# x軸標簽
plt.xlabel('k')
# y軸標簽
plt.ylabel('Cross-validation accuracy')
plt.show()回傳:
5. scikit-learn的演算法實作
5.1 對上述的再次實作:
# 匯入KneighborsClassifier模塊
from sklearn.neighbors import KNeighborsClassifier
# 創建k近鄰實體
neigh = KNeighborsClassifier(n_neighbors=10)
# k近鄰模型擬合
neigh.fit(X_train, y_train)
# k近鄰模型預測
y_pred = neigh.predict(X_test)
# # 預測結果陣列重塑
# y_pred = y_pred.reshape((-1, 1))
# 統計預測正確的個數
num_correct = np.sum(y_pred == y_test)
print(num_correct)
# 計算準確率
accuracy = float(num_correct) / X_test.shape[0]
print('Got %d / %d correct => accuracy: %f' % (num_correct, X_test.shape[0], accuracy))回傳:

5.2 另一種實作方式
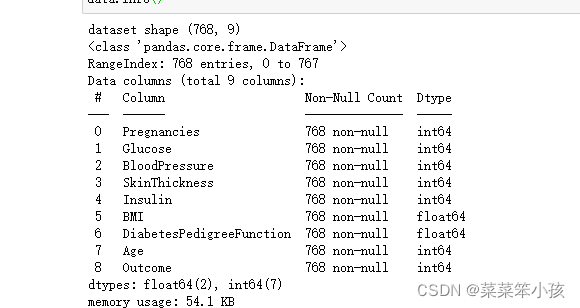
5.2.1 加載資料
import pandas as pd
data = pd.read_csv('D:\桌面\knn.csv')
print('dataset shape {}'.format(data.shape))
data.info()回傳:
5.2.2 分離訓練集和測驗集
X = data.iloc[:, 0:8]
Y = data.iloc[:, 8]
print('shape of X {}, shape of Y {}'.format(X.shape, Y.shape))
from sklearn.model_selection import train_test_split
X_train, X_test, Y_train,Y_test = train_test_split(X, Y, test_size=0.2)回傳:
![]()
5.2.3 模型比較
使用普通的knn演算法、帶權重的knn以及指定半徑的knn演算法分別對資料集進行擬合并計算評分
from sklearn.neighbors import KNeighborsClassifier, RadiusNeighborsClassifier
# 構建3個模型
models = []
models.append(('KNN', KNeighborsClassifier(n_neighbors=2)))
models.append(('KNN with weights', KNeighborsClassifier(n_neighbors=2, weights='distance')))
models.append(('Radius Neighbors', RadiusNeighborsClassifier(n_neighbors=2, radius=500.0)))
# 分別訓練3個模型,并計算得分
results = []
for name, model in models:
model.fit(X_train, Y_train)
results.append((name, model.score(X_test, Y_test)))
for i in range(len(results)):
print('name: {}; score: {}'.format(results[i][0], results[i][1]))回傳:

權重演算法,我們選擇了距離越近,權重越高,RadiusNeighborsClassifier模型的半徑選擇了500.從輸出可以看出,普通的knn演算法還是最好,
問題來了,這個判斷準確嗎? 答案是:不準確,
因為我們的訓練集和測驗集是隨機分配的,不同的訓練樣本和測驗樣本組合可能導致計算出來的演算法準確性有差異,
那么該如何解決呢?
我們可以多次隨機分配訓練集和交叉驗證集,然后求模型評分的平均值,
scikit-learn提供了KFold和cross_val_score()函式來處理這種問題,
from sklearn.model_selection import KFold
from sklearn.model_selection import cross_val_score
results = []
for name, model in models:
kfold = KFold(n_splits=10)
cv_result = cross_val_score(model, X, Y, cv=kfold)
results.append((name, cv_result))
for i in range(len(results)):
print('name: {}; cross_val_score: {}'.format(results[i][0], results[i][1].mean()))回傳:

上述代碼,我們通過KFold把資料集分成10份,其中1份會作為交叉驗證集來計算模型準確性,剩余9份作為訓練集,cross_val_score()函式總共計算出10次不同訓練集和交叉驗證集組合得到的模型評分,最后求平均值, 看起來,還是普通的knn演算法性能更優一些,
5.2.4 模型訓練及分析
據上面模型比較得到的結論,我們接下來使用普通的knn演算法模型對資料集進行訓練,并查看對訓練樣本的擬合情況以及對測驗樣本的預測準確性情況:
knn = KNeighborsClassifier(n_neighbors=2)
knn.fit(X_train, Y_train)
train_score = knn.score(X_train, Y_train)
test_score = knn.score(X_test, Y_test)
print('train score: {}; test score : {}'.format(train_score, test_score))回傳:

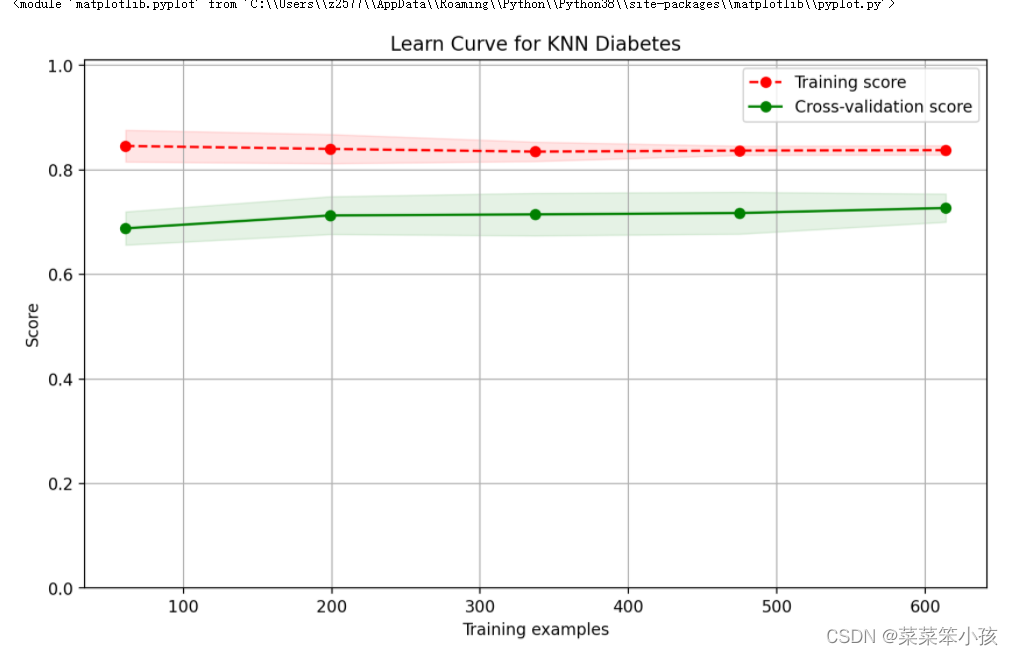
從這里可以看到兩個問題,
- 對訓練樣本的擬合情況不佳,評分才0.84多一些,說明演算法模型太簡單了,無法很好地擬合訓練樣本,
- 模型準確性不好,0.66左右的預測準確性,
我們畫出曲線,查看一下,
我們首先定義一下這個畫圖函式,代碼如下:
from sklearn.model_selection import learning_curve
import numpy as np
def plot_learning_curve(plt, estimator, title, X, y, ylim=None, cv=None,
n_jobs=1, train_sizes=np.linspace(.1, 1.0, 5)):
"""
Generate a simple plot of the test and training learning curve.
Parameters
----------
estimator : object type that implements the "fit" and "predict" methods
An object of that type which is cloned for each validation.
title : string
Title for the chart.
X : array-like, shape (n_samples, n_features)
Training vector, where n_samples is the number of samples and
n_features is the number of features.
y : array-like, shape (n_samples) or (n_samples, n_features), optional
Target relative to X for classification or regression;
None for unsupervised learning.
ylim : tuple, shape (ymin, ymax), optional
Defines minimum and maximum yvalues plotted.
cv : int, cross-validation generator or an iterable, optional
Determines the cross-validation splitting strategy.
Possible inputs for cv are:
- None, to use the default 3-fold cross-validation,
- integer, to specify the number of folds.
- An object to be used as a cross-validation generator.
- An iterable yielding train/test splits.
For integer/None inputs, if ``y`` is binary or multiclass,
:class:`StratifiedKFold` used. If the estimator is not a classifier
or if ``y`` is neither binary nor multiclass, :class:`KFold` is used.
Refer :ref:`User Guide <cross_validation>` for the various
cross-validators that can be used here.
n_jobs : integer, optional
Number of jobs to run in parallel (default 1).
"""
plt.title(title)
if ylim is not None:
plt.ylim(*ylim)
plt.xlabel("Training examples")
plt.ylabel("Score")
train_sizes, train_scores, test_scores = learning_curve(
estimator, X, y, cv=cv, n_jobs=n_jobs, train_sizes=train_sizes)
train_scores_mean = np.mean(train_scores, axis=1)
train_scores_std = np.std(train_scores, axis=1)
test_scores_mean = np.mean(test_scores, axis=1)
test_scores_std = np.std(test_scores, axis=1)
plt.grid()
plt.fill_between(train_sizes, train_scores_mean - train_scores_std,
train_scores_mean + train_scores_std, alpha=0.1,
color="r")
plt.fill_between(train_sizes, test_scores_mean - test_scores_std,
test_scores_mean + test_scores_std, alpha=0.1, color="g")
plt.plot(train_sizes, train_scores_mean, 'o--', color="r",
label="Training score")
plt.plot(train_sizes, test_scores_mean, 'o-', color="g",
label="Cross-validation score")
plt.legend(loc="best")
return plt然后我們呼叫這個函式畫一下圖看看:
from sklearn.model_selection import ShuffleSplit
knn = KNeighborsClassifier(n_neighbors=2)
cv = ShuffleSplit(n_splits=10, test_size=0.2, random_state=0)
plt.figure(figsize=(10,6), dpi=200)
plot_learning_curve(plt, knn, 'Learn Curve for KNN Diabetes', X, Y, ylim=(0.0, 1.01), cv=cv)回傳:
轉載請註明出處,本文鏈接:https://www.uj5u.com/qita/423201.html
標籤:AI
上一篇:python求解整數線性規劃
下一篇:五.OpenCv濾波器(1)