ARMA中文全稱為自回歸移動平均模型,廣泛用于時間時間序列分析中,本文以statsmodels 模塊中自帶資料集co2為例,實戰研究ARMA模型,
一、探索性資料分析,
首先匯入必要的package與資料集
from statsmodels.datasets import co2
data=co2.load(as_pandas=True).data
print(data)
得到的data為DataFrame 格式的格式,資料結構為2284行,1列,

對資料進行可視化,這里用pandas 的畫圖方法,能較好地顯示橫坐標,個人感覺比plt.plot()好用,
data.plot()
plt.show()
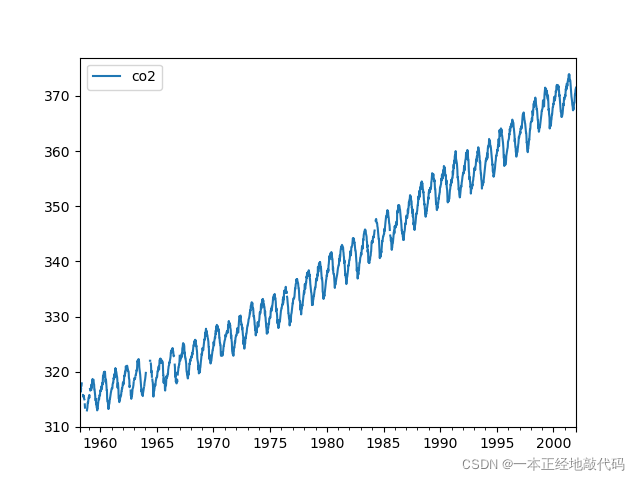
這里看到兩個資訊:1、資料并不是以天為單位,所以畫出的圖中存在間斷點,2、資料本身存在周期與趨勢,
解決辦法是先做一個資料上采樣,將資料轉變為月度平均,然后做一個12階滯后的差分,消除趨勢與周期
data=data.resample('M').mean().ffill()#均值上采樣,用強項填充填充缺失值
data_diff=data.diff(12).dropna()#12階差分,刪掉缺失值
print(data_diff.head(10))
輸出前10 條資料,1958年3月份-1959年2月份的12條資料由于缺失被洗掉了,所以差分后的資料從1959年3月份開始,

畫圖檢驗12階差分后資料的平穩性,平不平穩不敢說,至少比原始資料要好,
data_diff.plot()
plt.show()
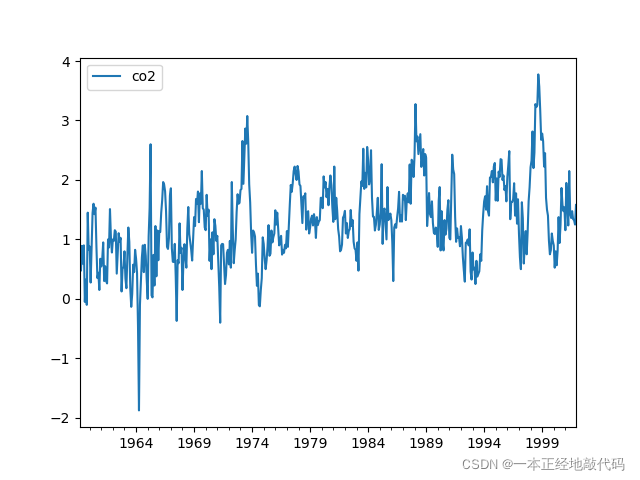
所以我們用更為嚴格的方法來說明問題,這里用單位根檢驗(ADF)把原始資料和差分后資料均檢驗了一遍,原始資料P值為0.99,大于0.05,拒絕資料平穩的假設;差分后資料通過平穩性檢驗,
from statsmodels.tsa.stattools import adfuller#匯入tsa.stattools中的ADF
print("12階差分資料單位根檢驗的P值",adfuller(data_diff)[1])
print("原始資料單位根檢驗的P值 ",adfuller(data)[1])
#12階差分資料單位根檢驗的P值 0.000778539367442881
#原始資料單位跟檢驗的P值 0.9989453312516823
凡事都有一個度,若是差分后資料“過于平穩”,便相當于白噪聲了,我們無法從中提取任何有用資訊,所以接下來進行白噪聲檢驗,各階滯后項P值均小于0.05,拒絕為白噪聲的原假設,
from statsmodels.stats.diagnostic import acorr_ljungbox
print('資料白噪聲檢驗的結果',acorr_ljungbox(data_diff,lags=[6,12,24],return_df=True))

二、定階擬合模型
對資料定階有很多方法,
1、ACF、PACF影像定階
from statsmodels.graphics.tsaplots import plot_acf,plot_pacf#匯入package
fig,axes=plt.subplots(2,1)#畫2行1列的組合圖
fig.subplots_adjust(hspace=0.5)#調整兩圖之間間隔,單純為了美觀
plot_acf(data_diff,ax=axes[0])#畫ACF圖
plot_pacf(data_diff,ax=axes[1])#畫PACF圖
plt.show()
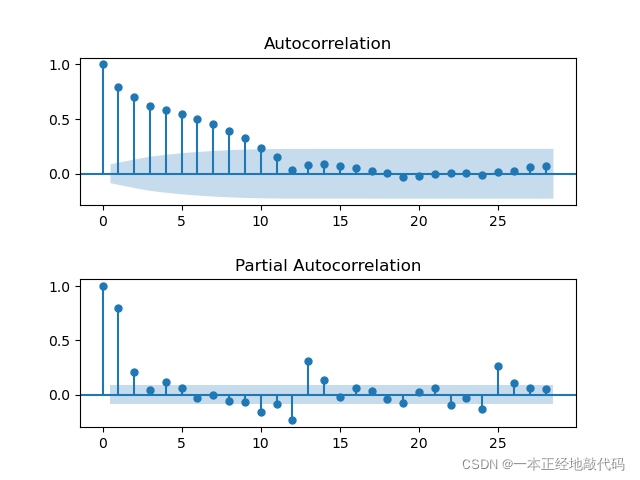
ACF超過閾值的階數作為MA的引數,PACF超過閾值threshold的階數作為AR的引數,根據上圖可將引數選為(3,11)
2、statsmodels自帶的方法定階
這種方法比看圖說話更為嚴謹,但缺點是計算量大,有時甚至跑不出結果(反正階數過高我的電腦沒跑出來#捂臉#)
from statsmodels.tsa.stattools import arma_order_select_ic
res=arma_order_select_ic(data_diff,max_ar=15,max_ma=15)
print(res[1])#res回傳兩個結果,第一個為bic值的矩陣陣列,第二個為階數
三、擬合模型
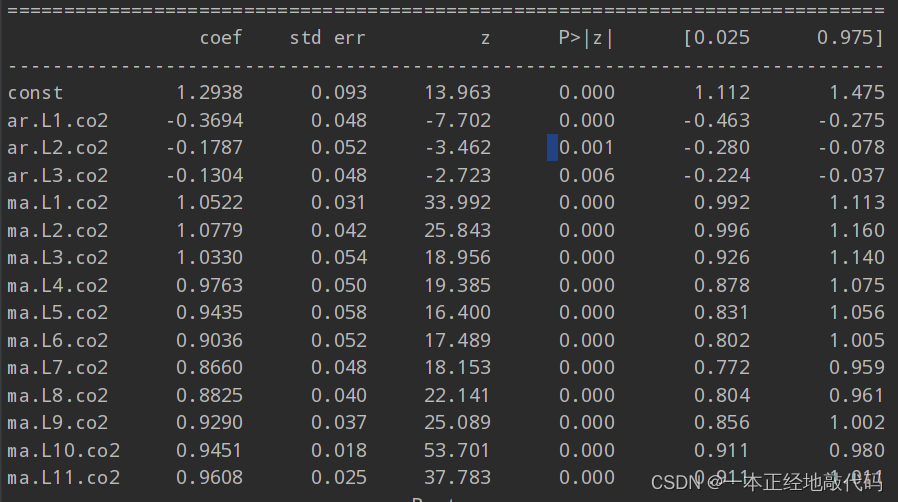
接下來用定好的階數擬合模型,注意擬合的模型一定要加fit()方法,不然無法輸出結果,這一點跟機器學習sklearn中模式是一樣的,輸出結果中P值均小于0.05,拒絕系數為0的原假設,
from statsmodels.tsa.arima_model import ARMA#匯入ARMA類
model=ARMA(data_diff,order=(3,11)).fit(disp=-1)
print(model.summary())
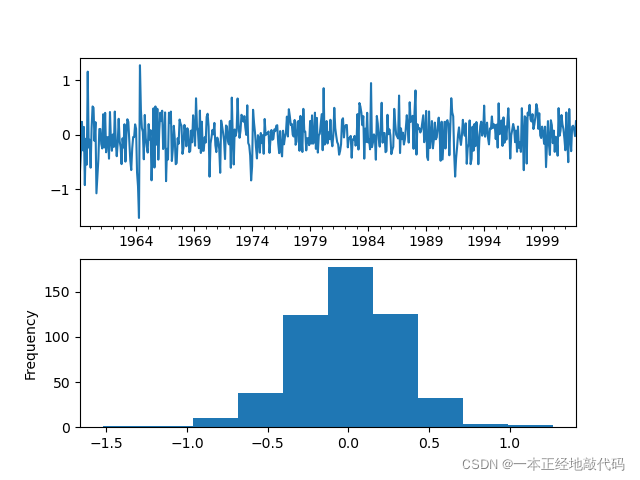
接下來評判模型是否“學習”到位?輸出模型殘差值,殘差為白噪聲,說明模型擬合得較好,
reside=model.resid#模型殘差值
fig,axes=plt.subplots(2,1)
reside.plot(ax=axes[0])
reside.plot(kind='hist',ax=axes[1])
plt.show()
print(acorr_ljungbox(reside,lags=[6,12,24],return_df=True))#殘差白噪聲檢驗
四、根據模型進行短期預測
ARMA在短期預測效果較長期好,接下來進行推后12期預測,這里一同將之前的資料預測出來了(沒搞懂+11為什么會預測出來12期)
preds=model.predict(0,len(data_diff)+11)#預測后12期
preds=pd.DataFrame(preds,columns=['predict'])#轉化為DataFrame用于合并
print(preds)
final_data=pd.merge(data,data_diff,how='outer',left_index=True,right_index=True)#將采樣后資料預差分資料合并,注意how='outer'
final_data=pd.merge(final_data,preds,how='outer',left_index=True,right_index=True)#將預測值和上行形成的資料合并,how='outer'
print(final_data)
final_data.to_csv('D:/yuce.csv')
將資料保存在本地,資料長下面這樣,最下面predict多出12個值,這里沒有展示,
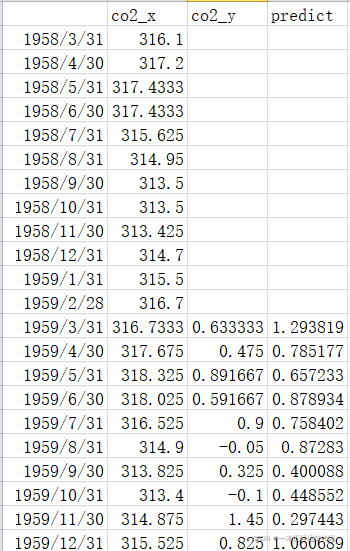
將資料都保存在本地有諸多好處,每次修改無需再跑一遍模型,直接從本地讀取資料進行分析即可,
直接讀取本地整理好的資料,第二行代碼是把預測的差分值加在原始資料上,得到預測數值,+10是為了作圖的時候好區分,沒有其他含義,
df=pd.read_excel('D:/co2預測.xlsx',index_col=0)
df['predict_value']=df['co2_x'].shift(12)+df['predict']+10
接下來進行可視化,在第一個子圖中畫出整體值的預測效果,紅色線為預測值,綠色線為實際值
fig,axes=plt.subplots(2,1)#生成2行1列組合圖
fig.subplots_adjust(hspace=0.5)#調整兩圖之間間隔
df['co2_x'].plot(color='g',ax=axes[0])
df['predict_value'].plot(color='r',ax=axes[0])
axes[1].set_title('value')
plt.legend()
在第二個子圖中繪制差分值,同樣紅色代表預測值,綠色代表實際值,
df['co2_y'].plot(color='g',ax=axes[1])#繪制真實差分值
df['predict'].plot(color='r',ax=axes[1])#繪制預測的差分值
axes[0].set_title('diff_value')
plt.legend()
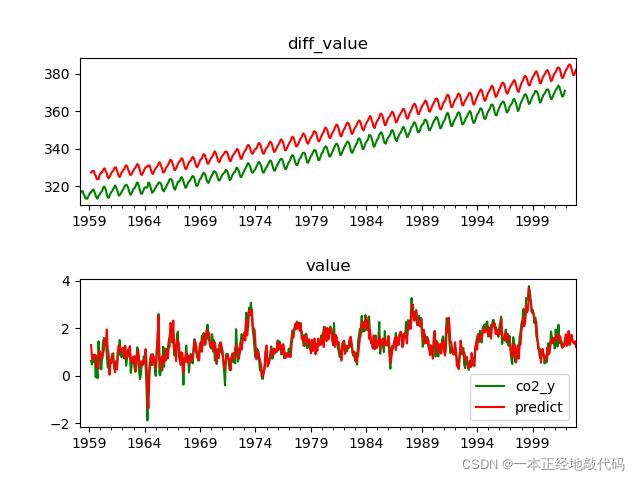
可以看出模型將大致的趨勢與周期擬合出來了,但還有很多地方值得改進,
首先就是資料集本身噪聲較少,具有明顯的周期性與趨勢性,所以擬合的模型相對表現良好,生活中大部分資料的信噪比沒有這么高,會給模型擬合帶來難度和挑戰,
其次是差分階數的選擇與模型階數的確定可以更加細致,更好的引數常常意味著更好的預測效果,能讓資料價值得到最大化挖掘,
轉載請註明出處,本文鏈接:https://www.uj5u.com/qita/423203.html
標籤:AI
上一篇:五.OpenCv濾波器(1)
下一篇:水晶藍蓮花(Matlab實作)