機器學習 Lab2 實驗報告
歡迎大家訪問我的GitHub博客
https://lunan0320.github.io/
文章目錄
- 一、實驗目的
- 二、實驗要求及環境
- 2.1 實驗要求
- 2.2實驗環境
- 三、設計思想
- 3.1 檔案描述
- 3.2 模型方法
- 3.2.1 Gaussian Distribution
- 3.2.2偏微分計算
- 3.2.3 Logistic Regression
- 3.2.4 Loss function(Cross Entropy)
- 3.2.5 Adagrad程序
- 3.3模型構想
- 3.3.1 模型一:補充代碼Generative model
- 3.3.2 模型二:自行完成Generative model
- 3.3.3 模型三:logistic regression
- 四、模型一
- 4.1資料讀取及預處理
- 4.2引數的計算
- 4.2.1 對訓練資料分類
- 4.2.2 計算均值和協方差
- 4.2.3 計算w和b
- 4.3準確率的計算
- 4.4 X_test的預測
- 4.4 模型建立并預測程序
- 五、模型二
- 5.1資料讀取及預處理
- 5.2 訓練集與驗證集分割
- 5.3 計算均值和協方差
- 5.4計算w和b
- 5.5計算驗證集的準確率
- 5.6 X_test的預測
- 5.7 模型建立并預測程序
- 六、模型三
- 6.1資料讀取及預處理
- 6.2 訓練集與驗證集分割
- 6.3 計算w和b
- 6.4計算驗證集的準確率
- 6.5 X_test的預測
- 6.6 Regularization正則化的影響
- 6.7 驗證集準確率分析比較
- 6.8 影響最大的特征
- 七、模型評價
- 7.1優點
- 7.1.1、模型特征綜合考慮
- 7.1.2、分類之間共用協方差
- 7.1.3、使用高階Gradient方法
- 7.1.4、Feature Scaling特征標準化
- 7.1.5、驗證集均勻分布
- 7.2缺點
- 7.2.1、未綜合考慮多種迭代方式
- 7.2.2、考慮了部分無用特征
- 7.2.3、生成模型假設單一
- 7.2.4、Adagrad優化瓶頸
- 八、實驗心得
- 九、參考文獻
- 十、提交檔案注解
一、實驗目的
掌握Classification中的生成模型generative model以及logistic regression model,
掌握二分類問題的機器學習方法,根據已有資料,判斷該人年收入是否大于5萬美元,
二、實驗要求及環境
2.1 實驗要求
1、不可以使用tensorflow或者pytorch庫
2、可以使用pandas庫讀取csv檔案資料資訊(其他庫亦可)
3、使用概率生成模型解決問題
4、使用logistic regression解決問題
5、概率生成模型可以完善給出代碼,也可自行完成
2.2實驗環境
?戴爾G3游匣 Intel core i7 Windows10
?Python3.8 PyCharm
三、設計思想
3.1 檔案描述
train.csv:3256115的表格,每一行有15個情況,其中最后一列是年收入的情況,
X_train:32561106的表格,是對train.csv檔案通過one-hot方法處理之后的檔案,對每一個行有106個特征,其中106是將前14種屬性值展開后的結果,代表了age, workclass, fnlwgt (總人數), education, education num, marital-status, occupation, relationship, race, sex, capital-gain, capital-loss, hours-per-week, native-country, make over 50K a year or not,
Y_train:325611的表格,是對train.csv檔案通過one-hot方法處理之后的結果,每一行只有一個特征,就是年收入,其中,年收入小于50k,則賦予label 0,否則賦予label 1,
test.csv: 1628114的表格,是需要通過訓練后的模型去計算各自對應的年收入值,
X_test:16281*106的表格,是對test.csv檔案通過one-hot方法處理之后的結果,
3.2 模型方法
3.2.1 Gaussian Distribution
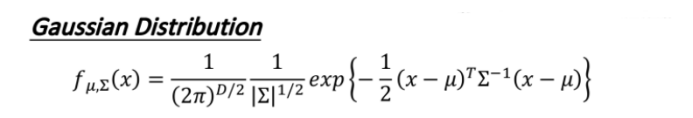
3.2.2偏微分計算
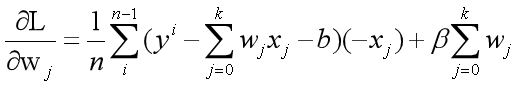
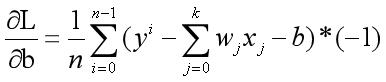
3.2.3 Logistic Regression
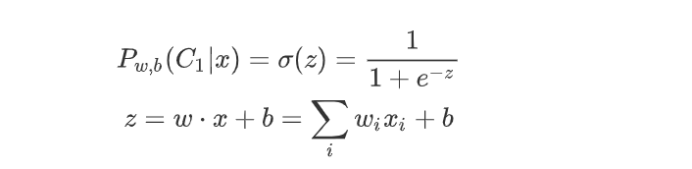
3.2.4 Loss function(Cross Entropy)
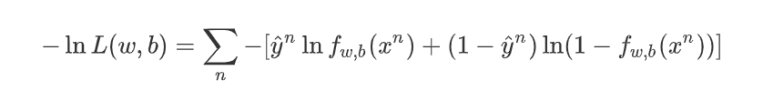
3.2.5 Adagrad程序
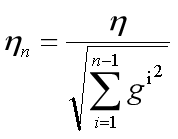
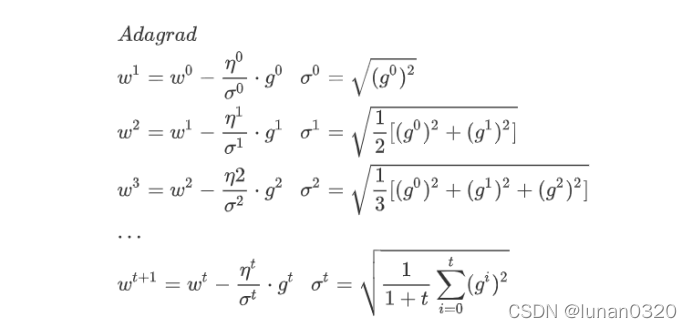
3.3模型構想
3.3.1 模型一:補充代碼Generative model
3.3.2 模型二:自行完成Generative model
3.3.3 模型三:logistic regression
四、模型一
使用生成模型,generative model來處理問題
代碼及資料見檔案:generative補充代碼.py output.csv
4.1資料讀取及預處理
觀察后發現,給出的代碼是采用了類的方式處理程序,因此直接在總類data_manager()之下完成補充函式即可,

首先需要將三個通過one-hot方法處理之后的檔案讀取出來,對X_train、Y_train、X_test分別讀取,
觀察之后發現沒有格式不正確、不合規的數字,因此直接對檔案進行讀取處理,
讀取的程序中需要對首行進行過濾,此處是使用了切片的方式將檔案的內容以浮點float的型別讀取出來,rows即是讀取到的陣列,

讀取出資料之后,由于每個特征資料的分布情況是不同的,因此需要對資料進行標準化處理,對資料標準化處理可以使得資料的結果不會受某個特征的影響太大或者太小,此處是使用了正態分布的標準化處理方式,
對于標準化,如果是X_train檔案則使用numpy的函式mean求均值,使用std函式求方差,同時將其均轉化為一行的shape,即轉化之后計算得到的mean和std均是1*106的陣列格式,
依次對rows的每一行進行標準化遍歷,對每一行執行正太分布標準化的方式進行,即可完成,
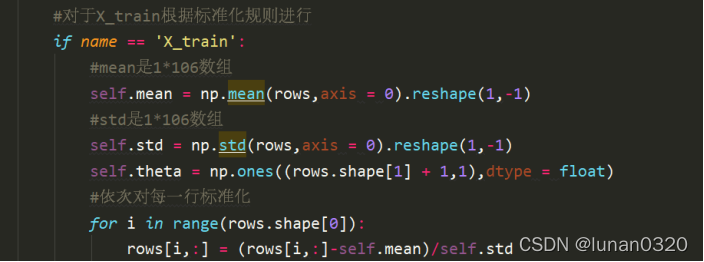
對于X_test的標準化,則是使用X_train的中得到的均值和方差,也就是類中的self.mean和self.std,直接使用標準化方法即可,
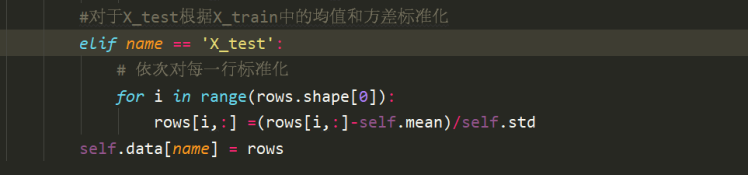
最后將結果索引到data[name]中,

4.2引數的計算
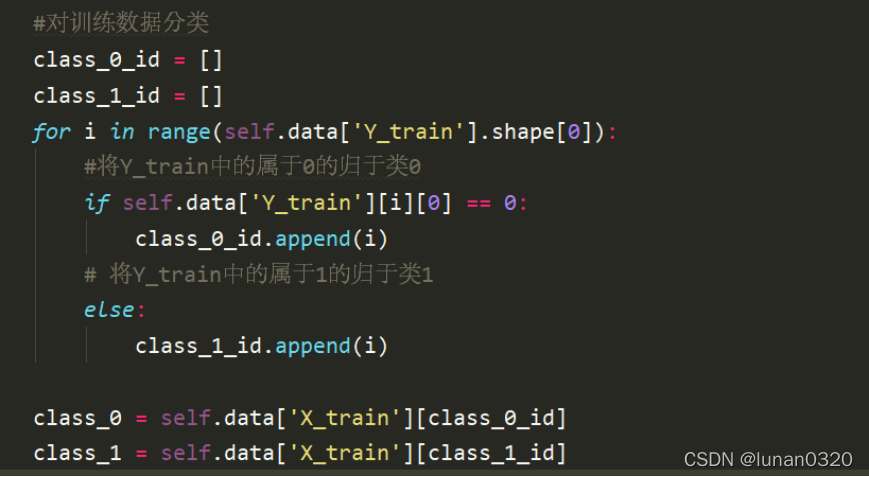
4.2.1 對訓練資料分類
將訓練資料分為兩類,class_0和class_1,分類的方法是去遍歷Y_train中的元素,如果說等于0,則將下標索引加入到class_0_id中,否則就將它加入到class_1_id中,
接著需要在X_train中找到這些下標對應的值,并將其作為對應的class,
4.2.2 計算均值和協方差
此處假設服從的是高斯分布Gaussian Distribution,推到程序使用極大似然估計法,

最優的均值和協方差的計算直接使用推導的最后的公式即可,
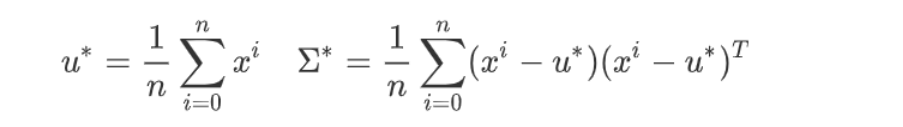
使用numpy的庫函式,mean()方法,對每一列求均值,對兩個class分別得到對應的均值mean_0和mean_1,均是1*106的陣列,

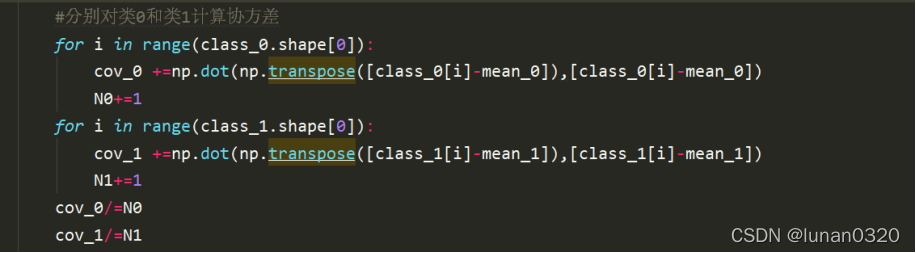
協方差的計算即是實際值與均值差的平方,此處由于是矩陣形式,需要先轉置后矩陣相乘,
首先是對兩個類的協方差的初始化,
此處的n其實就是整個的維度,也就是特征值的數量,

矩陣相乘使用了numpy中的dot()方法,對每一行依次計算,得到的分別是兩個類的106*106的協方差矩陣,
計算得到的N0和N1是兩個中元素的數量,即行數,
最后求得協方差需要除以類中的行數,
為了使得模型更加完善,此處使用了兩個類共享一個協方差的方法,
對兩個計算得到的協方差加權平均即可,

4.2.3 計算w和b
對z的推導程序如下
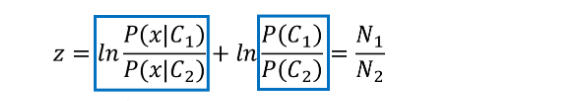
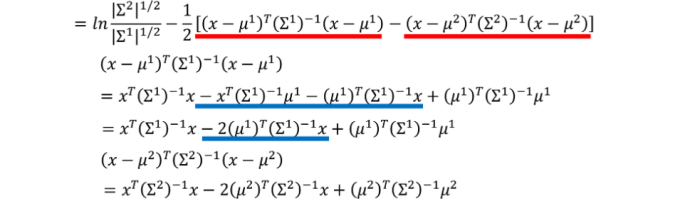
對z 的計算即可得到如下結果:
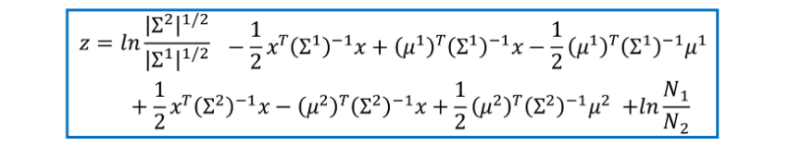
經過化簡之后,得到如下的運算式,可以看到前面是個一次項,后面是個常數項,
這就類似于線性回歸中的w*x+b的方法,因此,在求后驗概率的時候就需要先求得w和b這兩個引數,
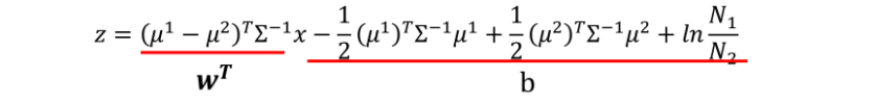
此處,對于w和b而言,所有的項都已知,只是需要先對協方差求逆運算,

因此,對于w和b的求取只需要將相應的引數代入即可,程序如下,

求得w和b之后需要計算得到z,并使得其過一次sigmoid()函式,得到結果位于0-1之間的對y的預測值,

其中sigmoid函式的定義是已經有公式給出的,
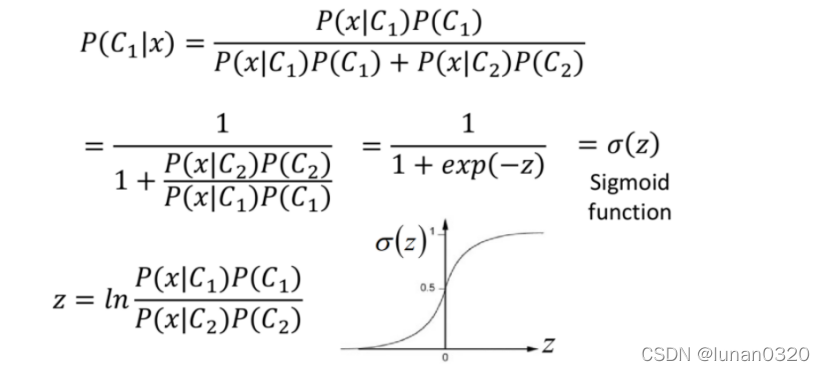
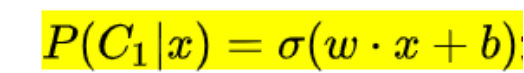
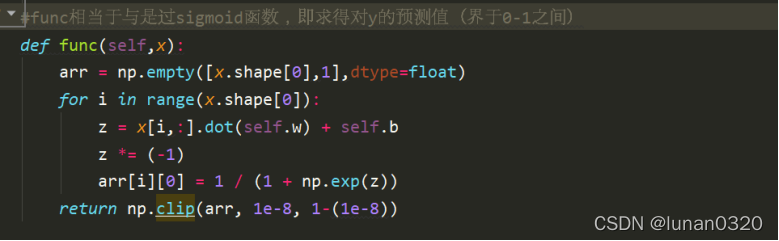
func函式的實作程序如下,對x的每一行分別計算其z的取值,根據sigmoid()函式,求得界于0-1之間的預測值,
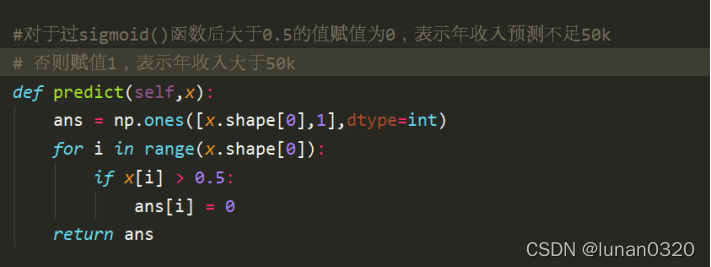
接著需要用這些得到的界于0-1之間的過sigmoid()函式的值去預測y,

預測函式即是對求得的result取整規化為0和1的程序,
4.3準確率的計算
為了考察模型的準確率,此時需要將模型計算得到的預測值與實際的Y_train檔案的值求絕對差的平均值,也就是計算了錯誤率,
準確率的計算需要在此基礎上用1減去錯誤率即可,

4.4 X_test的預測
在建立好模型,得到相關引數資料之后,需要使用該模型去預測未知量,對給定的X_test檔案預測其年收入情況,
result是對X_test的每一行過一次sigmoid()函式之后得到的界于0-1之間的資料,answer是對result的整數化的結果,也就是說answer就是最終的預測值,
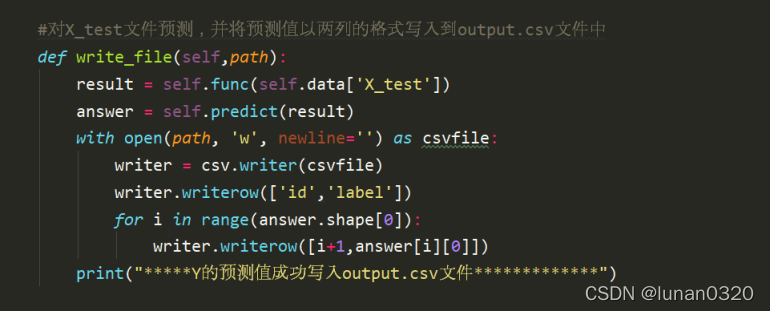
最后將預測值以特定的格式按行寫入output.csv檔案中,

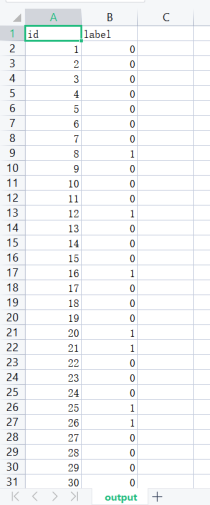
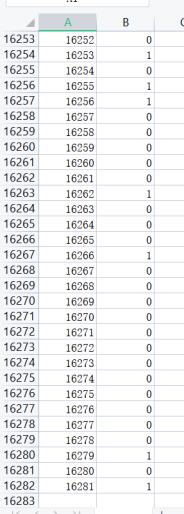
4.4 模型建立并預測程序
1、創建類

2、檔案讀取與預處理

3、引數計算

4、預測資料并寫入檔案

五、模型二
使用生成模型,generative model來處理問題(自行完成的生成模型)
代碼見檔案:generative自己完成.py
資料見檔案:Y_predict_generative.csv
5.1資料讀取及預處理
首先需要將三個通過one-hot方法處理之后的檔案讀取出來,對X_train、Y_train、X_test分別讀取,
觀察之后發現沒有格式不正確、不合規的數字,因此直接對檔案進行讀取處理,
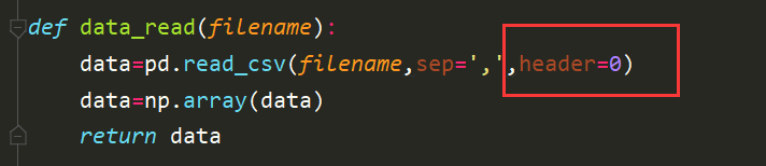
讀取時候使用的方法是使用pandas庫的方法讀取csv檔案,此處需要注意的是因為檔案的首行是特征的名稱集合,因此需要設定header=0的方式跳過首行,

將讀取到的檔案內容通過numpy庫函式轉換為陣列格式,并將該陣列data回傳,
對資料的讀取,分別呼叫data_read()函式對處理后的資料讀取,

對資料進行歸一化處理,此處需要對X_train和X_test分別歸一化,

將x_train和x_test使用numpy的concatenate()函式,將二者統一處理,求出x_all的均值和方差,對x_all實行正態分布的標準化處理方法,

此處得到的x_mean和x_std是1*106的一維陣列,為了實作更加方便的陣列之間直接進行運算,需要將x_mean和x_std陣列擴展為和x_all在第一維度同維度的陣列, 在擴展程序中,使用的是numpy的tile函式,
得到擴展后的x_mean和x_std之后就可以對資料進行標準化,
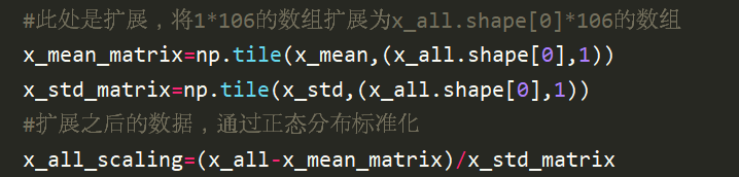
對整體進行標準化之后,再將整體資料分為x_train和x_test資料即可,此時得到的x_train和x_test即是統一標準化之后的結果,
5.2 訓練集與驗證集分割
對于X_train和Y_train資料需要進行分割,分為訓練集和驗證集兩部分,其中,訓練集用于模型的學習,驗證集用于模型準確率的驗證,

分割的時候需要提前設定分割比例,此處設定比率為0.9,即是訓練集:驗證集=9:1

為了使得驗證集和訓練集的選取更加隨機,而不是直接選擇前面的若干行為驗證集或訓練集,此處在查閱資料之后了解到numpy的shuffle生成隨機序列的函式,

此處使用該函式對X和Y進行隨機化處理,
首先是生成一個隨機序列,長度就是x的行數,
接著對該隨機序列呼叫shuffle函式,對隨機序列隨機化,
最后讓X和Y使用該隨機序列的順序,即可實作對X和Y資料的打亂,
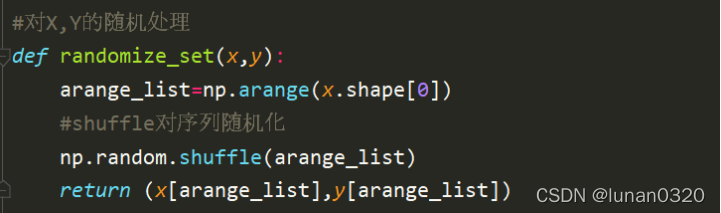
得到該隨機序列之后即可得到一個隨機化的X和Y,此時再取0.9的訓練集,0.1的驗證集就是一個很隨機的情況了,
為了使得序列直接取到前ratio的部分,設定了boundary界限,
依次對x和y取出bounary的部分,回傳值依次到x_rrain,y_train,x_valid、y_valid,即可實作對訓練集和驗證集的分隔,
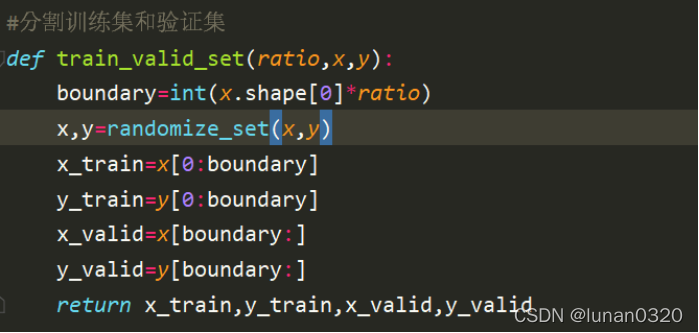
5.3 計算均值和協方差
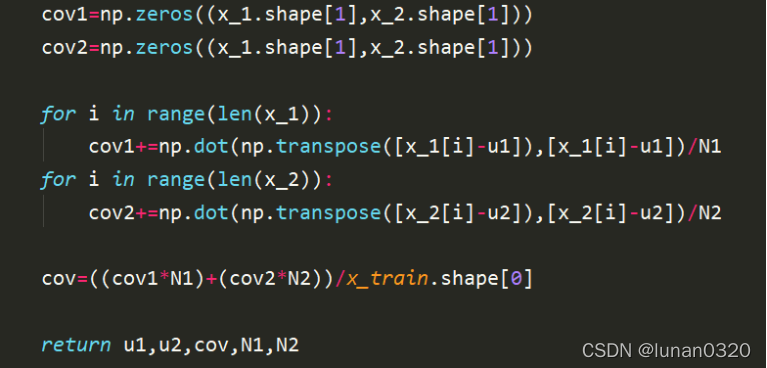
此時需要求兩個分類的均值u1、u2以及共用的cov協方差,兩個類的元素數量N1、N2.

首先需要進行分類,此處使用了比較快捷的方式,zip函式對X_train和Y_train進行打包處理,對于Y為1就歸為第一類,對于Y為0則處理為第二類,

使用numpy的求均值的mean方法,求出兩個類的u1和u2

計算N1和N2就是求出兩個類的一維長度,也就是兩個類的元素數量,

與模型一類似,代入相關資料,直接使用公式即可得到每個類的協方差,對協方差求加權平均,即可得到,
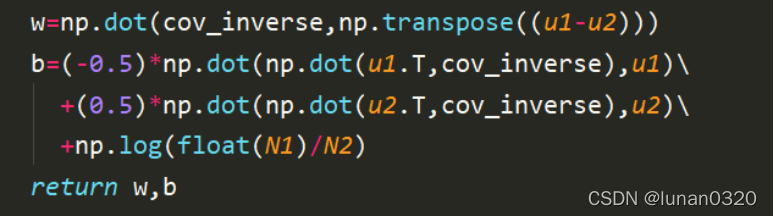
5.4計算w和b
由于在求z的程序中需要求中間變數w和b,

該程序需要用到協方差的逆,因此先對協方差求逆,

同模型一類似,也是使用公式直接即可求得w和b,
5.5計算驗證集的準確率
在求得引數訓練好模型之后,就可以使用驗證集去驗證一下準確率的大小,

對驗證集求準確率即是先找到x_valid的預測值,過一次sigmoid()函式,求出界于0-1之間的數值,通過around函式四舍五入,

此處為了避免由于數值太小,通過numpy的clip函式,將其轉換為了界于1e-8和1-(1e-8)的數字,
之后統計出現相同的頻率即可找到其準確率,

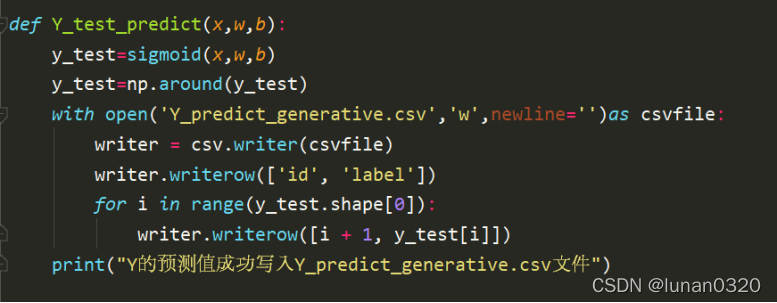
5.6 X_test的預測
在建立好模型,得到相關引數資料之后,需要使用該模型去預測未知量,對給定的X_test檔案預測其年收入情況,

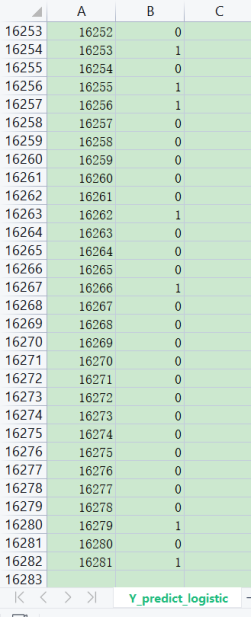
對X_test進行預測,對X_test過sigmoid函式,并四舍五入,得到y_test,將y_test寫入Y_predict_generative.csv檔案,
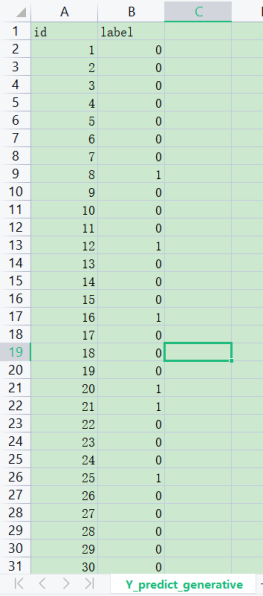
預測得到的結果如下:

5.7 模型建立并預測程序
1、首先資料處理,對x資料標準化
2、分割訓練集和驗證集
3、對訓練集分類,求出每一類的u1、u2、cov
4、利用公式用u1、u2、cov求出w和b
5、用w、b過sigmoid函式,得到分類函式f
6、對驗證集每個數過分類函式,得到驗證的準確率
7、對test資料過分類函式,將輸出以0、1格式輸出到Y_predict_generative.csv檔案中
六、模型三
使用生成模型,logistic Regression來處理問題
代碼見檔案:Logistic_Regression.py
資料見檔案:Y_predict_logistic.csv
6.1資料讀取及預處理
首先需要將三個通過one-hot方法處理之后的檔案讀取出來,對X_train、Y_train、X_test分別讀取,
觀察之后發現沒有格式不正確、不合規的數字,因此直接對檔案進行讀取處理,
將讀取到的檔案內容通過numpy庫函式轉換為陣列格式,并將該陣列data回傳,
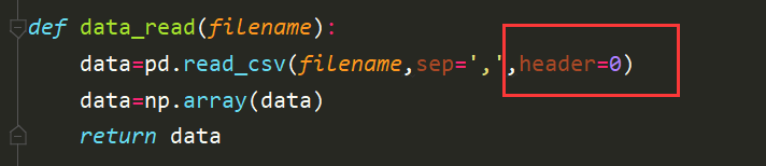
對資料的讀取,分別呼叫data_read()函式對處理后的資料讀取,

對資料進行歸一化處理,此處需要對X_train和X_test分別歸一化,
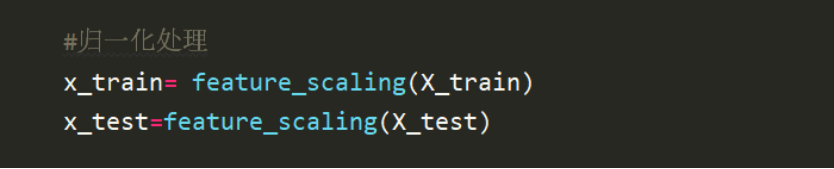
將x_train和x_test分別呼叫該函式,求出均值和方差后,是1*106的陣列,然后按列處理,對每一列依次進行標準化,此處+1e-8是因為為了避免出現例外問題,

6.2 訓練集與驗證集分割
對于X_train和Y_train資料需要進行分割,分為訓練集和驗證集兩部分,其中,訓練集用于模型的學習,驗證集用于模型準確率的驗證,

分割的時候需要提前設定分割比例,此處設定比率為0.9,即是訓練集:驗證集=9:1

為了使得驗證集和訓練集的選取更加隨機,而不是直接選擇前面的若干行為驗證集或訓練集,此處與模型二類似使用的是numpy的shuffle生成隨機序列的函式,

得到該隨機序列之后即可得到一個隨機化的X和Y,此時再取0.9的訓練集,0.1的驗證集就是一個很隨機的情況了,
為了使得序列直接取到前ratio的部分,設定了boundary界限,

依次對x和y取出bounary的部分,回傳值依次到x_rrain,y_train,x_valid、y_valid,即可實作對訓練集和驗證集的分隔,
6.3 計算w和b
Logistic_Regression使用的是直接求解w和b的方法,因此此處也直接使用的是Adagrad梯度下降的方法求解,

由于梯度下降的資料量過大,因此,此處使用的是每10行更新一次的方法,初始化設定學習率lr=0.1,相當于是每10行為一個block處理,梯度下降的函式在上一個實驗中已經完成過,
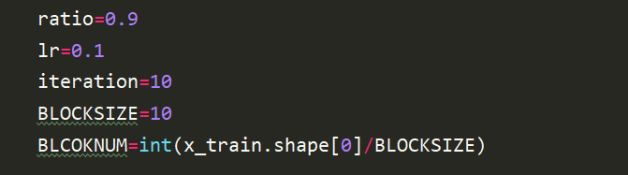

類似的可以得到本模型的梯度下降函式,
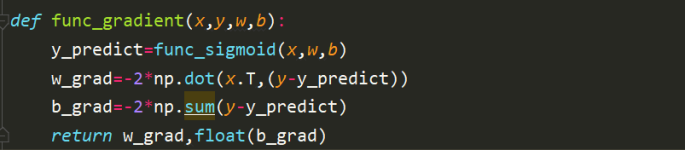
需要注意的是,此處的每次迭代是分塊進行的,每一次的更新是以塊為單位更新的,
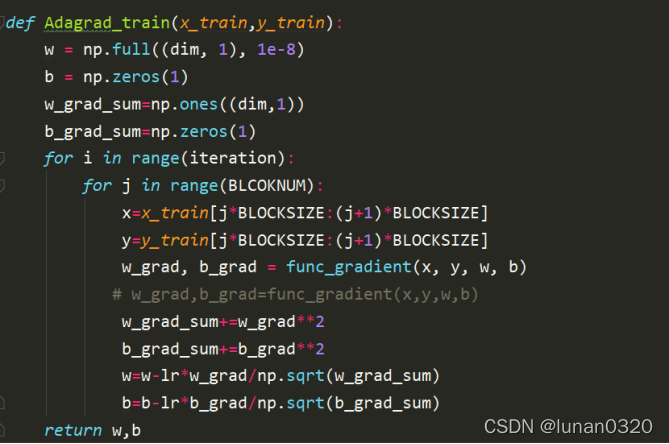
6.4計算驗證集的準確率
在求得引數訓練好模型之后,就可以使用驗證集去驗證一下準確率的大小,

對驗證集求準確率即是先找到x_valid的預測值,過一次sigmoid()函式,求出界于0-1之間的數值,然后對該值利用求交叉熵cross_entropy的方法求得loss值,然后對預測的y通過around函式四舍五入,
計算準確率的時候,需要求y和預測值之間的偏差的均值,也就是錯誤率,用1-錯誤率即可,得到驗證集的準確率和交叉熵(loss),

此處為了避免由于數值太小,通過numpy的clip函式,將其轉換為了界于1e-8和1-(1e-8)的數字,

6.5 X_test的預測
在建立好模型,得到相關引數資料之后,需要使用該模型去預測未知量,對給定的X_test檔案預測其年收入情況,

對X_test進行預測,對X_test過sigmoid函式,并四舍五入,得到y_test,將y_test寫入Y_predict_logistic.csv檔案,

6.6 Regularization正則化的影響
需要改動的地方是對w和b的求取,以及準確率和loss值的計算的地方,

此時,需要對交叉熵重新計算,加入正則項,正則項的加入如圖紅色框線,
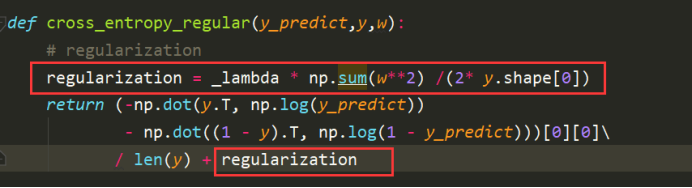
重新計算w梯度,加入正則項,對每一列一次遍歷,_lambda已在全域變數中給出,

6.7 驗證集準確率分析比較
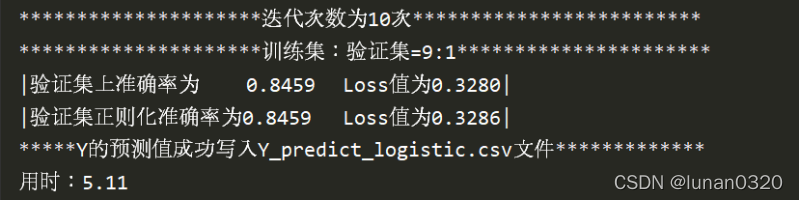
此處給出的是迭代10次之后的結果,訓練集設定的是9:1,可以看到,正則化之后并沒有對驗證集的準確率與交叉熵loss值有所改善,
分析之后,發現此模型仍然是屬于線性模型,沒有高次項,而正則化是對高次項的過擬合現象有較好的改良,對于此處的線性模型其實優化效果一般,
6.8 影響最大的特征
討論哪個特征對實驗結果的影響最大其實就是找出哪個特征對應的w的絕對值最大,
在實驗求得w和b之后,尋找w最大值所對應的特征即可,該特征即是影響因素最大的,
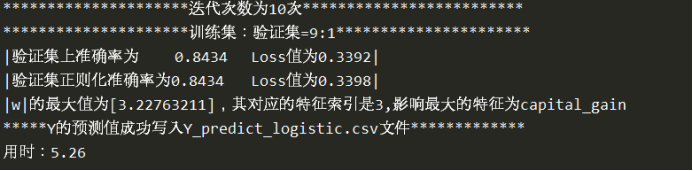
從結果種可以看出,影響最大的特征是capital_gain,也就是資本收益對于收入能否大于50k是影響最大的,
七、模型評價
7.1優點
7.1.1、模型特征綜合考慮
為了得到模型的較優解,此處是直接計算了模型的全部特征,即使某個特征沒有什么影響,也可以視為此處的w為0,這樣就不容易錯過一些有影響的特征,從而提高了模型的準確率,
7.1.2、分類之間共用協方差
為了提高模型的準確性,在生成模型Generative Model中對協方差是采取了共用的方式,
7.1.3、使用高階Gradient方法
在模型三Logistic Regression的程序中,使用了Adagrad作為主要求梯度的方法,使得學習率隨著迭代次數動態變化,
7.1.4、Feature Scaling特征標準化
使用歸一化技術,使得消除了不同特征之間的影響,更容易收斂到最佳情況,
7.1.5、驗證集均勻分布
將訓練集和驗證集分割,而驗證集又是充分隨機選取,使得模型更容易推廣,從而降低了test資料下的誤差,
7.2缺點
7.2.1、未綜合考慮多種迭代方式
對于使用Logistic_Regression時,可以考慮采用多種迭代方式,在梯度下降的程序中,除了Adagrad之外,可以考慮SGD的放大,可以對比綜合考慮,
7.2.2、考慮了部分無用特征
考慮了部分無用特征,從總特征中可以看出,顯然的是并非所有的特征都是有效的,對于沒有用的特征其實是可以不考慮的,但是從求出的w可以看出,并沒有哪一個特征對應的w為0的情況,都會或多或少的有一定的值,這就會將誤差加入進去,
7.2.3、生成模型假設單一
生成模型只考慮了假設其是服從高斯分布的情況,并沒有考慮類似樸素貝葉斯(當然不可能是這個)等其他分布情況,因此這就使得假設直接按照Gaussian Distribution的程序進行,假設的條件單一,
7.2.4、Adagrad優化瓶頸
雖然通過Adagrad方法使得不同的變數有了各自的學習率,但是初始情況的全域學習率需要自己指定,
此時,如果設定的全域學習率過大,則優化一樣是不穩定的;
如果設定的全域學習率過小,則隨著迭代程序的進行,根據Adagrad的學習特性,學習率可能會越來越小,很有可能在沒有到達極值點的時候就已經是停滯不前的狀態了,
八、實驗心得
在分類問題中可以類比回歸模型的思路,尤其是在Logistic Regression中更是體會到了與回歸的對比,
在考慮特征值的時候并不一定是所有的特征值都有用,即使選取全部特征值,對于某些特征值的w可以為0,但是在實際訓練情況中,幾乎沒有w為0的情況,或多或少均會引入誤差,
在本問題中使用生成模型求解和使用logistic regression求解的結果其實是差不多的,都是比較適合本問題的求解方法,
對同一問題的解決程序,如果使用不同的模型,結果可能也是差不多的,但是在一些條件下,結果的差距可能是很大的,
在Logistic Regression里面,是沒有做任何實質性的假設,沒有對Probability distribution有任何的描述,我們就是單純地去找b和w,
而在Generative model里面,對Probability distribution是有實質性的假設的,之前我們假設的是Gaussian(高斯分布),甚至假設在相互獨立的前提下是否可以是naive bayes(樸素貝葉斯),根據這些假設我們才找到最終的b和w,
Training Data和Validation Data要區分開,不能在訓練集中直接選取一部分用來驗證求loss值的大小,Training Data中用來訓練模型,而Validation Data用來驗證模型優劣,計算loss值,
九、參考文獻
[1] [機器學習]正規化_for justice-CSDN博客_正規化
https://blog.csdn.net/jidong2622/article/details/79354332
[2] numpy.tile()
https://blog.csdn.net/qq_18433441/article/details/54897250
[3] 陣列物件
https://www.numpy.org.cn/reference/arrays/
[4]numpy.random.shuffle打亂順序函式
https://blog.csdn.net/jasonzzj/article/details/53932645
[5] Pandas手冊
https://www.pypandas.cn/docs/getting_started/basics.html
[6] Adagrad 優化
https://www.jiqizhixin.com/graph/technologies/7eab38a3-23ec-494c-a677-415b6f85e6c5
十、提交檔案注解
訓練集:X_train Y_train
預測集:X_test
1、模型一:
代碼 generative補充代碼.py 資料 output.csv
2、模型二:
代碼 generative.py 資料 Y_predict_generative.csv
3、模型三:
代碼 Logistic_Regression.py 資料 Y_predict_logistic.csv


轉載請註明出處,本文鏈接:https://www.uj5u.com/qita/423235.html
標籤:AI