年前的最后一個天,最后一篇博文
小談
今天是除夕夜,寫完這篇博客就去下載LOL玩云頂之奕去了,今天晚上放松放松,明天是大年初一,大年初一可能會更文,
困惑
剛開始學習Spark,對于一些代碼不理解,為什么要寫SparkConf和SrakContext才能運行,當習慣敲這個之后,對于setMaster又不理解,只知道跟著人家的視頻寫上Local.
跟著視頻按部就班的學著,能聽懂一二剩下的八九分都不理解,跟著人家的視頻走,視頻里面的老師說啥自己聽啥,使得自己空知道怎么做,而不知道為什么是這樣做,
問題發生在這一次的手誤
val wordCount = new SparkConf().setMaster("local[*]").setAppName("WordCount")
val sparkContext = new SparkContext(wordCount)將上面的*刪掉了
val wordCount = new SparkConf().setMaster("local").setAppName("WordCount")
val sparkContext = new SparkContext(wordCount)就這樣,到最后輸出的時候SaveAsTextFile
按理來說,會出現12個檔案,但是只出現了1個,(關于為什么是十二,自己只知道是本地的cpu核數),為什么只出現了一個,當場就愣住了,這就是所謂的治標不治本嗎?
- 在Local[*]的時候,本地會有12個磁區
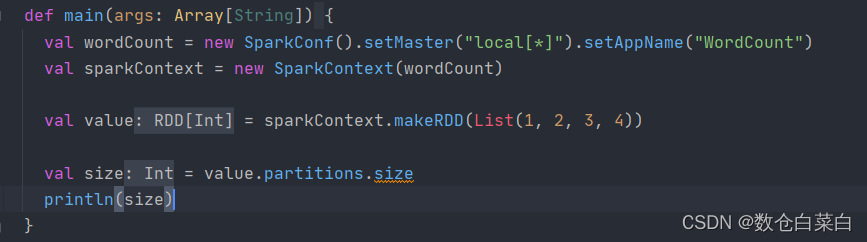
2.在Local的時候,本地只會有一個磁區
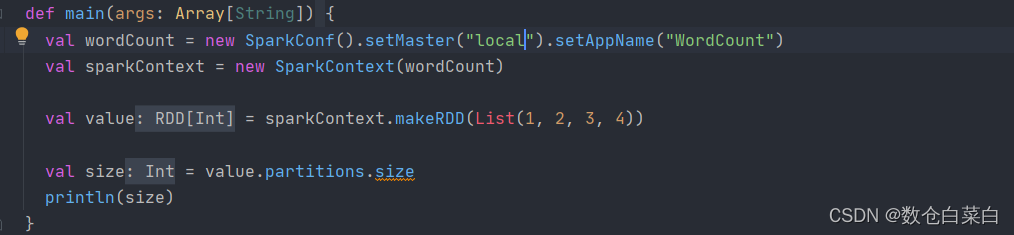
終究,還是將手伸向了原始碼
分析
問題的根源就是這三句

為什么Local 和 Local[*]的結果是不一樣的?同樣是將結果保存在檔案夾里面,最后顯示的磁區數目是不一樣的
一步一步來,看原始碼
1.進入makeRdd原始碼,發現makeRdd的底層就是parallelize方法
在創建RDD的時候可以makeRDD也可以parallelize
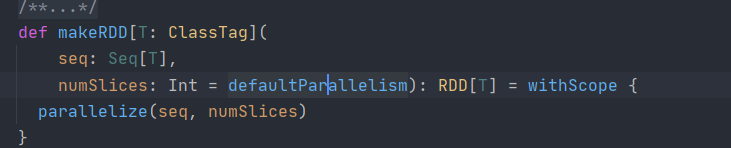
2.點擊defaultParallelism,繼續深入
3.在子類中找到defaultParallelism實作方法

4.重點來了

def getInt(key: String, defaultValue: Int): Int =
catchIllegalValue(key) {
getOption(key).map(_.toInt).getOrElse(defaultValue) }
//如果指定了并行度,那么就用指定的并行度
//如果沒有指定并行度,就用defaultValue 默認的并行度上面這段代碼就是重點了,
這段告訴我們的就是如果我們創建RDD的時候,指定了并行度,那么就采取指定的并行度,如果不指定并行度,那么就采用默認的并行度,
既然已經知道了為什么在最后輸出檔案的時候會有不同的檔案數,不妨繼續往下面走一走,看看默認的并行度是多少
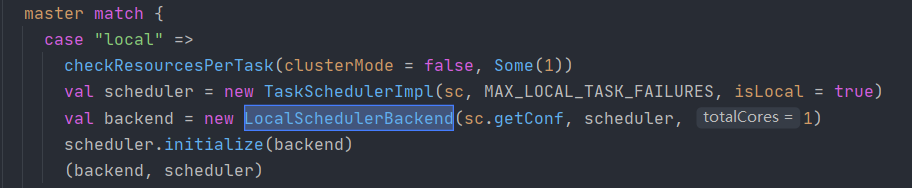
上面就是master也就是剛開始的SetMaster,
1.如果是local
val wordCount = new SparkConf().setMaster("local").setAppName("WordCount")正如上面的截圖,當使用local的時候,系統定義的本地并行度就是1
totalCores = 1 本地的磁區個數就是1
2.如果是local[*]
val wordCount = new SparkConf().setMaster("local[*]").setAppName("WordCount")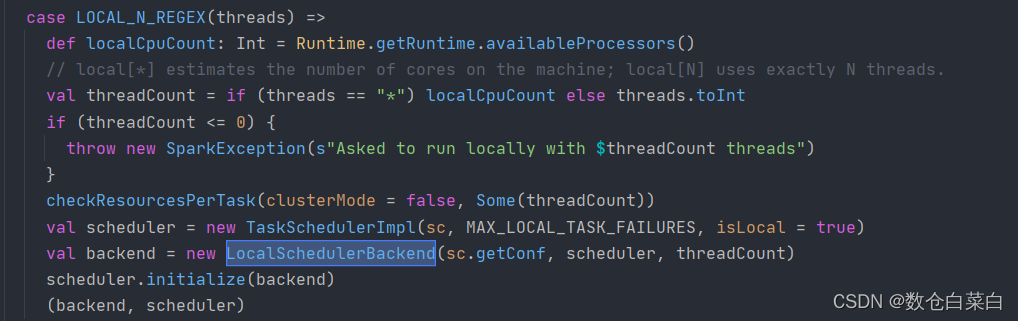
剛開始會進行正則匹配
val LOCAL_N_REGEX = """local\[([0-9]+|\*)\]""".r匹配到的就是local[*] 或者 local[0-9]
如果是local[*] 那么就用本地電腦的核數,如果不是*,那么就用自己定義的0-9的陣列作為核數,
TotalCores在這里就是本地電腦的核數,也就是
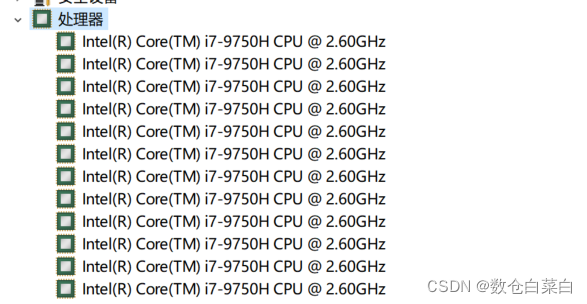
上面的圖中,也就是我的電腦核數是12,那么我最后生成檔案的個數就是12,
上面所講的就是Spark本地環境中的默認磁區規則,在默認磁區規則之外,還有資料在磁區存盤的規則沒有講,礙于時間關系,將會在年后進行講解,
總結:
臨近除夕,這篇博客簡短的寫了一個,就是講一下Local[*]和Local的區別,下次將會講資料在磁區檔案里面的存盤規則以及自定義磁區
多讀原始碼,盡管看的不是特別懂,但是慢慢來,一定可以比現在熟練
轉載請註明出處,本文鏈接:https://www.uj5u.com/qita/423241.html
標籤:其他