K-means與DBSCAN聚類演算法
前言:目前資料聚類方法大體上可以分為劃分式聚類方法(Partition-based Methods)、基于密度的聚類方法(Density-based methods)、層次化聚類方法(Hierarchical Methods)及一些聚類的新方法等四類,而在本模塊中我們學習的K-means聚類演算法屬于劃分式聚類方法、DBSCAN聚類演算法屬于基于密度的聚類方法,另一系統聚類法,也稱層次聚類法,屬于層次化聚類方法,隨著演算法領域的不斷發展,也產生了量子聚類、核聚類等新聚類方法,
一、K-means聚類演算法
1.優缺點
在講K-means聚類演算法之前,我想先交代一下它的缺點,
優點:(1)相對來說較為簡單,易實作
(2)對處理大資料集,該演算法是相對高效率的(當然這里的“大”也是有 限度的,如果資料集過大,就要使用Mini Batch K-Means演算法了)
(3)可解釋度較強(為什么這么說呢,其實主要還是從數學角度來講的,它的步驟可以說是有較強的數學支撐的)
缺點:(1)這個演算法的k值是要求提前給定的(那么我們就想了,都沒聚類去哪找k值呢?答案是經驗與個人感覺,我一般的做法是猜測+Spss跑一下測驗看看哪個k值較優)
(2)對例外點較為敏感(因為要計算距離所以不難想到)
(3)較易受初始聚類中心的影響
(4)……
當然缺點不止這些,僅列出影響較大的缺點,
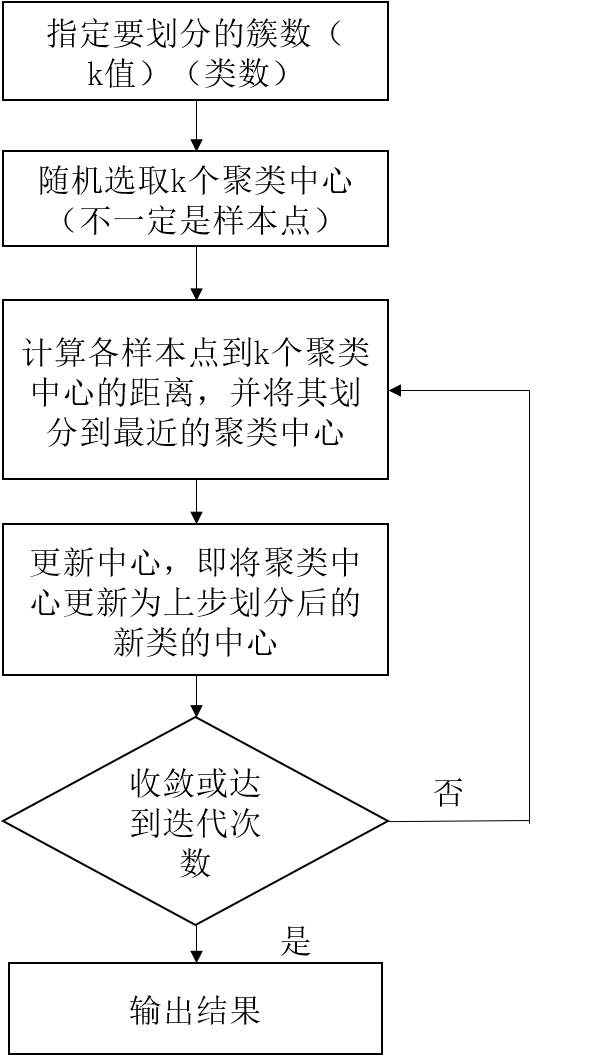
2.步驟
老規矩,我們用流程圖表示K-means的步驟,
3.Spss實作
聚類的這一部分我們統一用Spss軟體來實作,原因是內置了集成化的各種統計功能較為方便,
(1)實作步驟
資料集:【金山檔案】 測驗資料 https://kdocs.cn/l/cbfmkbJGAyYm
資料集的匯入,可查閱系統聚類法一節,
*[資料取自嵩天Python機器學習演算法]
選擇k-均值聚類
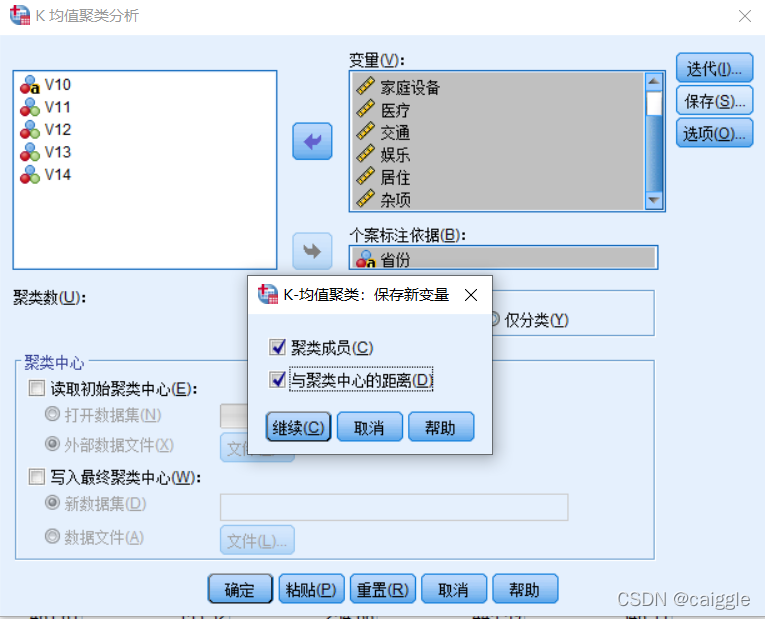
選擇“聚類成員”與“與聚類中心的距離”
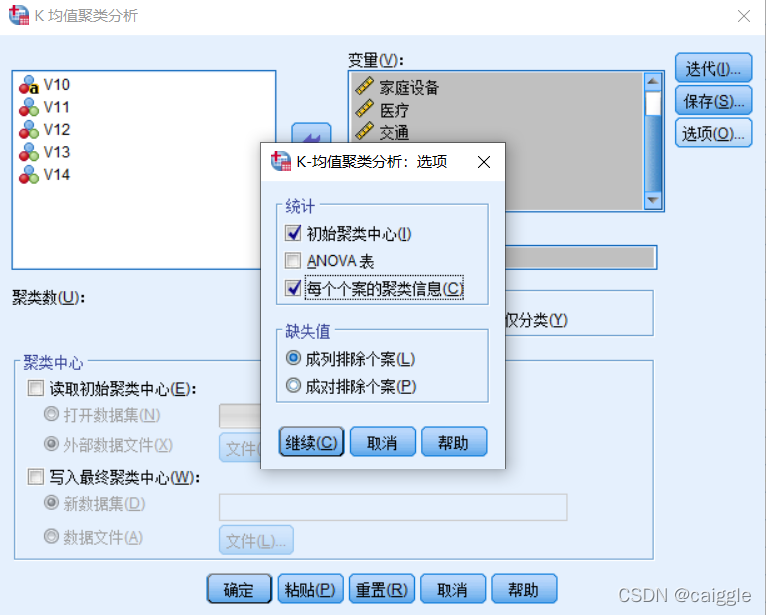
選擇“每個個案的聚類資訊”
(2)結果分析
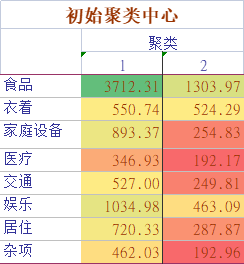
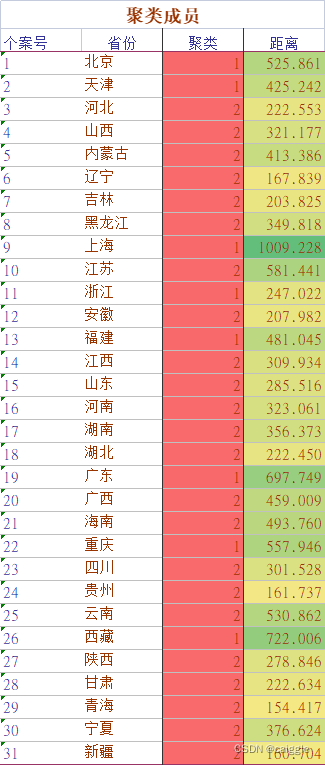
對于這次聚類,可見聚類結果為兩類,我們可解釋為:高消費省份與低消費省份,而對于聚類,難的就在于如何去解釋聚類結果,這是極為重要的,否則聚類將沒有意義,
值得注意的是,從第一個表格中可以看出,初始聚類中心選擇為上海和內蒙古,這是否真的是隨機選擇呢?可以說不是,Spss默認使用了K-means++演算法,
這里還是來介紹一下:
K-means++演算法與K-means演算法的區別在于初始k個聚類中心的選取原則不同,K-means++演算法選擇初始聚類中心的原則是:初始的聚類中心之間的相互距離要盡可能遠,
步驟:
在資料集中隨機選取一個樣本點作為第一個聚類中心
計算出樣本點與已有聚類中心的距離,距離越大,被選中作為聚類中心的概率也越大
依照概率來抽選下一個聚類中心
重復步驟二和三直至選出k個聚類中心
這個演算法也改善了K-means演算法的一些缺點,如對初值和孤立點資料值敏感,
二、DBSCAN聚類演算法
1.定義
DBSCAN(Density-Based Spatial Clustering of Applications with Noise)是一個比較有代表性的基于密度的聚類演算法,與劃分和層次聚類方法不同,它將簇定義為密度相連的點的最大集合,能夠把具有足夠高密度的區域劃分為簇,并可在噪聲的空間資料庫中發現任意形狀的聚類,
2.步驟
考慮到本演算法的流程較難理解,本處我用通俗的語言來敘述一下并推薦一個國外的可視化網站,
我先對這個演算法做一些簡單的解釋:
輸入:樣本集D,鄰域引數(epsilon,minPoints)
輸 出 :簇的劃分C
E鄰域:以樣本點為中心,epsilon為半徑的領域
minPoints:可以理解為點的一個閾值
核心點:E領域內點的個數(包括自身)大于等于minPoints的的點
邊界點:E領域內點的個數(包括自身)小于minPoints且屬于其他核心點領域內的點
噪音點:既不是核心點也不是噪音點的點
它的大概步驟是這樣的:首先我們選擇兩個引數:epsilon(通俗地理解為半徑)與minPoints;然后,我們從資料集中隨機選擇一個點,如果 E鄰域內樣本點數(包括原始點本身)大于等于minPoints ,就可以開始了;接著,我們檢查鄰域內的所有點并查看它們的型別,如果不是噪音點那么可以逐步擴展類,之后的點也是按照這個步驟進行的,讀者可以類推一下,
可視化網站:
[https://www.naftaliharris.com/blog/visualizing-dbscan-clustering/]
3.偽代碼
DBSCAN(D, Eps, MinPts)
Begin
init C=0; //初始化簇的個數為0
for each unvisited point p in D
mark p as visited; //將p標記為已訪問
N = getNeighbours (p, Eps);
if sizeOf(N) < MinPts then
mark p as Noise; //如果滿足sizeOf(N) < MinPts,則將p標記為噪聲
else
C= next cluster; //建立新簇C
ExpandCluster (p, N, C, Eps, MinPts);
end if
end for
End
其中ExpandCluster演算法偽碼如下:
ExpandCluster(p, N, C, Eps, MinPts)
add p to cluster C; //首先將核心點加入C
for each unvisited point p’ in N
mark p' as visited;
N’ = getNeighbours (p’, Eps); //對N鄰域內的所有點在進行半徑檢查
if sizeOf(N’) >= MinPts then
N = N+N’; //如果大于MinPts,就擴展N的數目
end if
if p’ is not member of any cluster
add p’ to cluster C; //將p' 加入簇C
end if
end for
End ExpandCluster
*[源自Baidu百科 ]
通俗的講,使用偽代碼的目的就是使代碼可以用任意一種編程語言輕松的實作,因為偽代碼的可讀性要求很高,
4.Matlab推薦的代碼
[https://ww2.mathworks.cn/matlabcentral/fileexchange/52905‐dbscan‐clustering‐algorithm]
注:另外需指出的是,DBSCAN演算法對于epsilon和minPoints敏感,這兩個引數也較難確定,
在進行聚類之前,還是希望有一個宏觀的把控,因此資料的預處理表現得更加重要了,可以先對資料做一個散點圖,觀察一下表現形式,
當然少不了的是新春祝福!!!
愿 律回春暉漸 萬象始更新
轉載請註明出處,本文鏈接:https://www.uj5u.com/qita/423321.html
標籤:AI
上一篇:b站的用紙筆訓練神經網路【matlab與python實作】
下一篇:pandas使用iloc函式基于dataframe資料列的索引抽取單列或者多列資料、其中多列索引需要嵌入在串列方括號[]中、或使用:符號形成起始和終止范圍索引