🐋在上一章的學習中,我們學習了docker安裝flink環境,并搭配了一系列流處理框架的組建,在這一章我們將介紹一下流式處理框架的原理,對往期其內容感興趣的同學可以參考如下內容👇:
- hadoop專題: hadoop系列文章.
- spark專題: spark系列文章.
- flink專題: Flink系列文章.
🐳本篇博客主要講解流處理框架與傳統框架的比較,以及流處理框架的組成結構,讓我們開始今日份的學習吧,
目錄
- 1. 引言
- 2. 傳統框架和流處理框架
- 3. 訊息傳輸層和流處理層
- 3.1 訊息傳輸層
- 4. 流資料在微服務架構下的應用
- 5. 案例
- 6. 參考資料
1. 引言
資料架構設計領域正在發生一場變革,其影響不僅限于實時或近實時的專案,這場變革將基于流的資料處理流程視為整個架構設計的核心,而不是只作為某些專業化作業的基礎,了解為何向流處理架構轉變,可以幫助我們理解 Flink 和它在現代資料處理中所扮演的角色,
作為新型系統,Flink 擴展了“流處理”這個概念的范圍,有了它,流處理不僅指實時、低延遲的資料分析,還指各類資料應用程式,其中,有些應用程式基于流處理器實作,有些基于批處理器實作,有些甚至基于事務型資料庫實作,
2. 傳統框架和流處理框架
對于后端資料而言,傳統架構是采用一個中心化的資料庫系統,用于存盤事務型別性資料,比如,mysql存盤的業務資料,反應當前狀況下的業務狀態,需要新鮮資料的應用程式都依靠資料庫實作,分布式檔案系統則用來存盤不需要經常更新的資料,它們也往往是大規模批量計算所依賴的資料存盤方式,但隨著時間的推移,這種傳統的方式遇見如下的問題:
- 在許多專案中,從資料到達到資料分析所需的作業流程太復雜、太緩慢,
- 傳統的資料架構太單一:資料庫是唯一正確的資料源,每一個應用程式都需要通過訪問資料庫來獲得所需的資料,
- 采用這種架構的系統擁有非常復雜的例外問題處理方法,當出現例外問題時,很難保證系統還能很好地運行,
除了這些,傳統架構的另一個問題是,需要通過在大型分布式系統中不斷地更新來維持一致的全域狀態,隨著系統規模擴大,維持實際資料與狀態資料間的一致性變得越來越困難;流處理架構則少了對這方面的要求,只需要維持本地的資料一致性即可,
作為一種新的選擇,流處理架構解決了企業在大規模系統中遇到的諸多問題,以流為基礎的架構設計讓資料記錄持續地從資料源流向應用程式,并在各個應用程式間持續流動,沒有一個資料庫來集中存盤全域狀態資料,取而代之的是共享且永不停止的流資料,它是唯一正確的資料源,記錄了業務資料的歷史, 在流處理架構中,每個應用程式都有自己的資料,這些資料采用本地資料庫或分布式檔案進行存盤,
3. 訊息傳輸層和流處理層
一個flink專案主要包含兩個部分:訊息傳輸層和流處理層
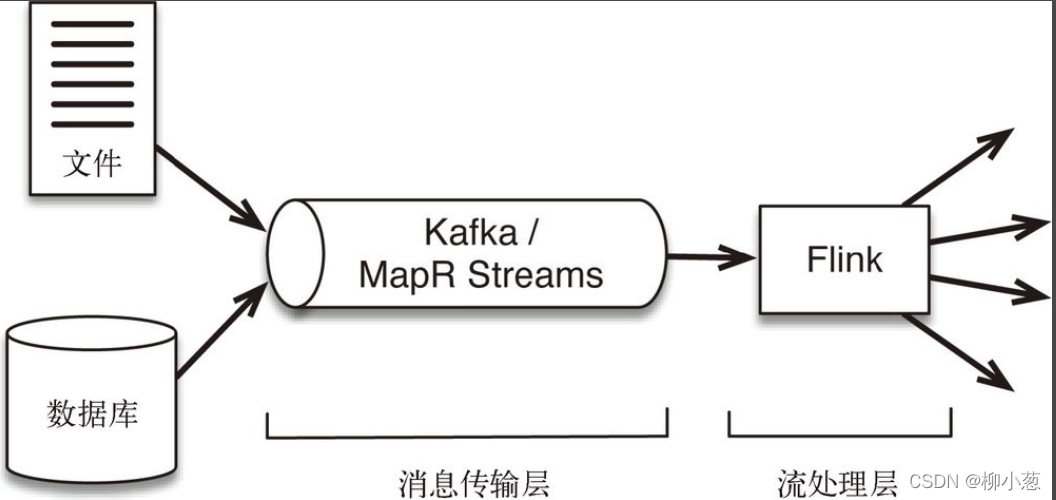
- 訊息傳輸層從各種資料源(生產者)采集連續事件產生的資料,并傳輸給訂閱了這些資料的應用和服務(消費者),
- 流處理層有 3 個用途:①持續地將資料在應用程式和系統間移動;②聚合并處理事件;③在本地維持應用程式的狀態,
在大家看來,都會把注意力放在流處理層上,這一層不止有flink還有像saprk streaming、strom等,但其實訊息傳輸層也很關鍵,沒有訊息傳遞方式的改變,流處理框架也很難作業!
3.1 訊息傳輸層
流處理框架下的訊息傳輸層需要有哪些功能呢?
- 高性能和持久性
訊息傳輸層的一個作用是作為流處理層上游的安全佇列——它相當于緩沖區,可以將事件資料作為短期資料保留起來,以防資料處理程序發生中斷,直到最近幾年,高性能和持久性不可兼得的困境才被打破,人們習慣上認為流資料從訊息傳輸層到流處理層之后就被丟棄:用了就沒了,
為了設計新一代的流處理架構,高性能和持久性不可兼得是首先要改變的一個觀念,兼具高性能和持久性對于訊息傳輸系統來說至關重要;Kafka可以滿足這個需求,
具有持久性的好處之一是訊息可以重播,這個功能使得像 Flink 這樣的處理器能對事件流中的某一部分進行重播和再計算,正是由于訊息傳輸層和流處理層相互作用,才使得像 Flink 這樣的系統有了準確處理和重新處理資料的能力,
- 生產者和消費者解耦
采用高效的訊息傳輸技術,可以從多個源(生產者)收集資料,并使這些資料可供多個服務或應用程式(消費者)使用,如圖 所示,Kafka 把從生產者獲得的資料分配給既定的主題,資料源將資料推送給訊息佇列,消費者(或消費者群組)則拉取資料,事件資料只能基于給定的偏移量從訊息佇列中按順序讀出,生產者并不向所有消費者自動廣播,這一點聽起來微不足道,但是對整個架構的作業方式有著巨大的影響,
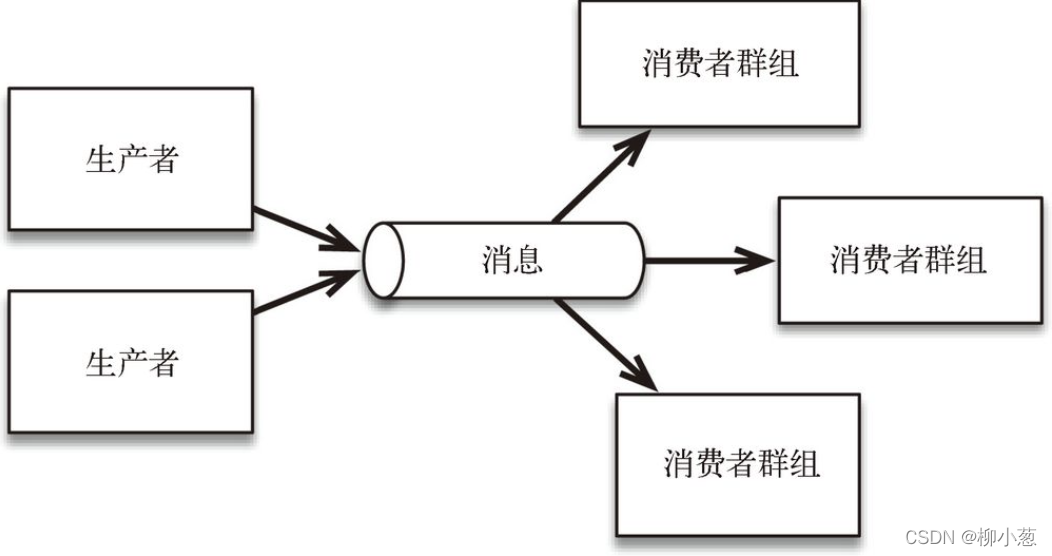
資料的生產者和消費者是解耦的,到達的訊息既可以立刻被使用,也可以稍后被使用,消費者從佇列中訂閱訊息,而不是由生產者向所有消費者廣播,在訊息到達的時候,消費者不必處于運行狀態,而是可以根據自身需求在任何時間使用資料,這樣一來,添加新的消費者和生產者也很容易,采用解耦的訊息傳輸系統很有意義,因為它能支持微服務,也支持將處理步驟中的實作程序隱藏起來,從而允許自由地修改實作程序,
4. 流資料在微服務架構下的應用
微服務是軟體設計中的概念,主要是指將一個大型的系統分解成一個一個具有單一目的子系統,比如:我們有一個單體架構的買賣東西的系統,初期用戶不是很多,我們將買商品,進貨,交易模塊等放在一起,隨著用戶越來越多,這個系統的功能模塊也在不斷增加,庫存管理、人員管理、售后服務等,這時我們可以考慮將這些服務一個一個拆解開,構建自己的系統,分別管理,這就是簡單的微服務,
流處理架構的核心是使各種應用程式互連在一起的訊息佇列,流處理器flink從訊息佇列中訂閱資料并加以處理,處理后的資料可以流向另一個訊息佇列,這樣一來,其他應用程式(包括其他 Flink 應用程式)都可以共享流資料,在一些情況下,處理后的資料會被存放在本地資料庫中,
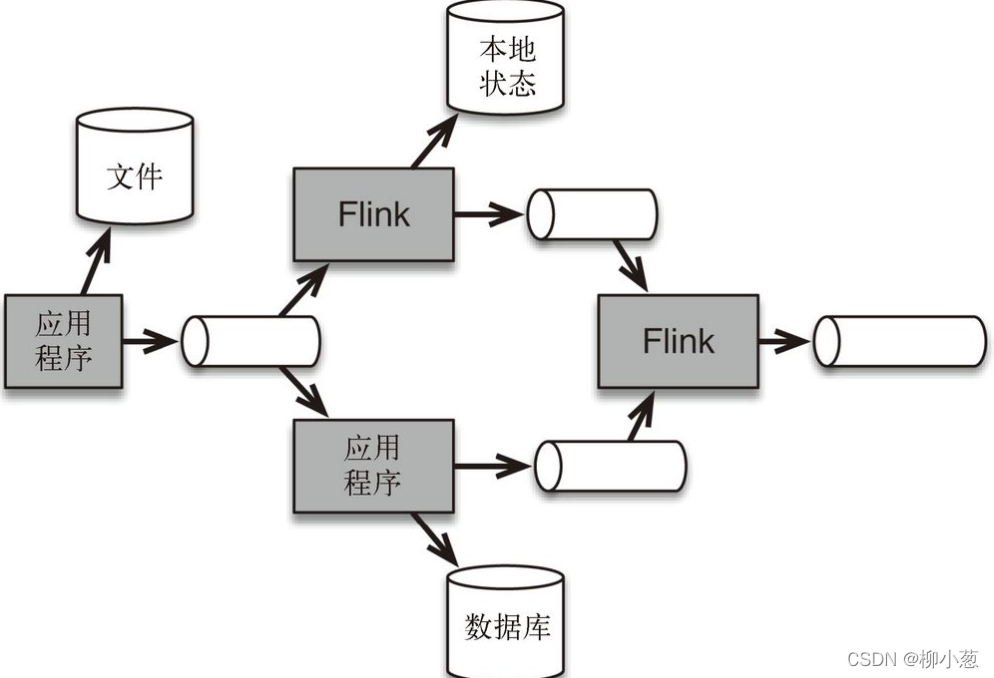
如圖:在流處理架構中,訊息佇列(圖中以水平圓柱體表示)連接應用程式,并作為新的共享資料源;它們取代了從前的大型集中式資料庫,在本例中,Flink 被多個應用程式使用,本地化的資料能夠根據微服務專案的需要被存盤在檔案或者資料庫中,這種流處理架構的另一個好處是,流處理器Flink還可以保障資料一致性,
5. 案例
我們通過一個案例來了解一下:欺詐檢測系統
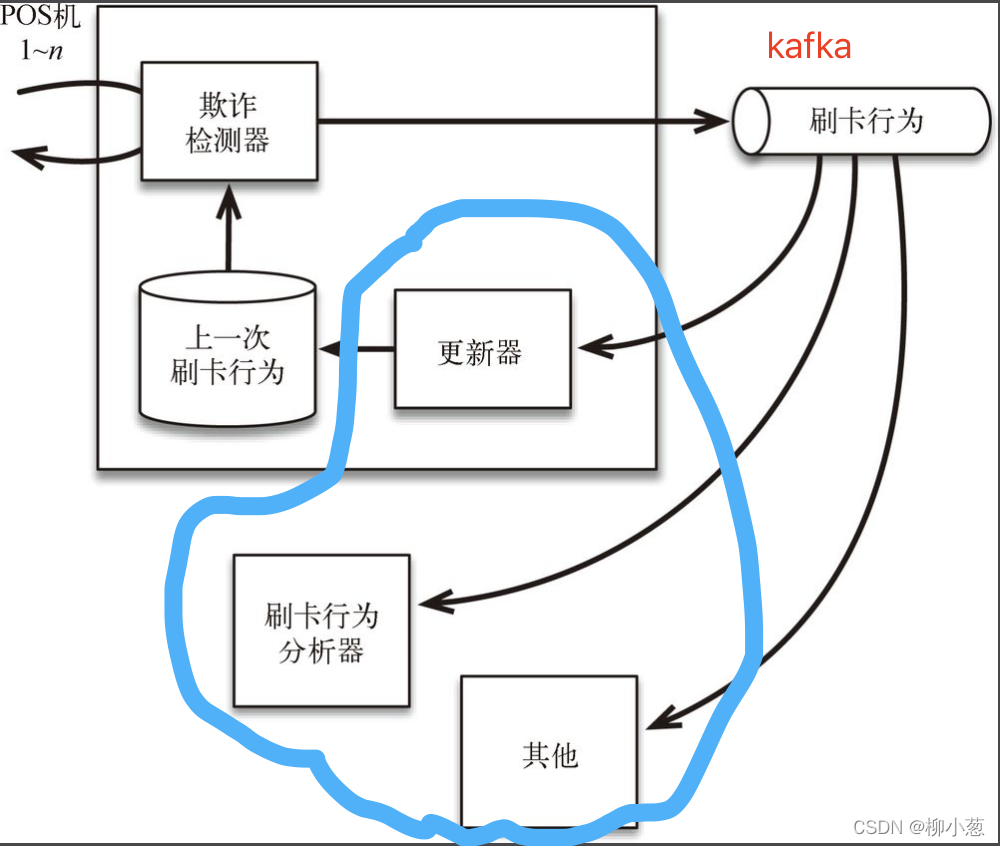
有很多POS機通過請求欺詐檢測器看看這一次刷卡是否具有欺詐行為,這些來自POS機的請求需要立即被應答,
傳統的欺詐檢測器將刷卡的最后一次資料直接存盤在資料庫中,但這樣的存盤方式讓其他需要資料的消費者不能輕易地使用刷卡資料,因為訪問資料庫可能會影響欺詐檢測系統的正常作業;在沒有經過認真仔細的審查之前,其他消費者絕不會被授權更改資料庫,這將導致整個流程變慢,因為必須仔細執行各種檢查,以避免核心的業務功能受到破壞或影響,
與傳統方法相比,如圖所示的流處理架構設計將欺詐檢測器的輸出發送給外部的訊息佇列(Kafka),再由如 Flink 這樣的流處理器更新資料庫,而不是直接將輸出發送給資料庫,這使得刷卡行為的資料可以通過訊息佇列被其他服務使用,例如刷卡行為分析器,上一次刷卡行為的資料被存盤在本地資料庫中,不會被其他服務訪問,這樣的設計避免了因為增加新的服務而帶來的過載風險,
6. 參考資料
《Flink的資料科學的實用指南》
《Kafka權威指南》
《Apache Flink 必知必會》
《docker菜鳥教程》
《Apache Flink 零基礎入門》
《Flink 基礎教程》
轉載請註明出處,本文鏈接:https://www.uj5u.com/qita/423336.html
標籤:其他
下一篇:ADP530X功能分類匯總