目錄
- 前言
- 混淆矩陣
- 查準率和查全率
- P--R曲線
- 為什么PR曲線面積越大模型就會越好呢(排除過擬合的情況)?
- IOU(交并比)
- MAP(Mean Average precision)
前言
對于我們訓練處的模型的泛化性能進行評估,不僅需要有效可行的實驗估計方法,還需要有衡量模型泛化能力的評價標準,這就是性能度量(performance measure).
性能度量反映了任務需求,在對比不同模型的能力時,使用不同的性能度量往往會導致不同的評判結果;這意味著模型的"好壞"是相對的,什么樣的模型是好的?不僅取決于演算法和資料,還決定于任務需求.
對于二分類問題,可將樣例根據其真實類別與學習器預測類別的組合劃分為真正例(true positive) 、假正例 (false positive) 、真反倒(true negative)假反例 (false negative) 四種情形,令 TP FP TN FN 分別表示其對應的樣例數,則顯然 TP+FP+TN+FN=樣例總數.分類結果的"混淆淆矩" (co usion matrix)如下 :
混淆矩陣
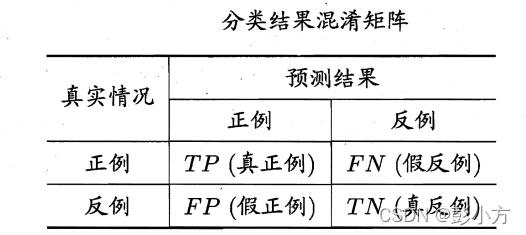
圖 1 混淆矩陣 一 (摘自西瓜書)
TP一一 將正類預測為正類數(預測對了)
FN一一 將正類預測為負類數(預測錯了)
FP一一 將負類預測為正類數(預測錯了)
TN 一一將負類預測為負類數(預測對了)
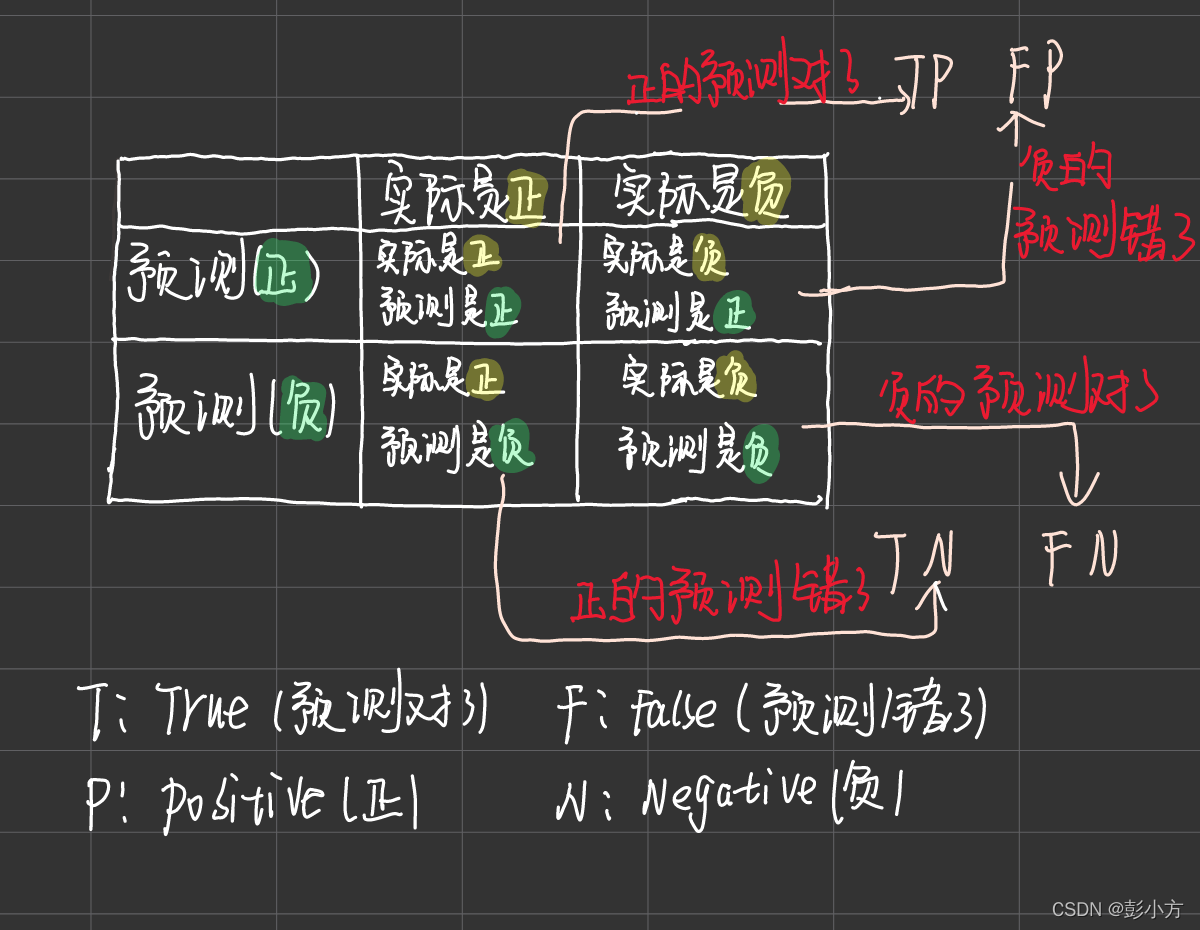
圖 2 混淆矩陣 二
查準率和查全率
查準率(precision):模型預測的所有目標中,預測正確的比例,查準率有利于突出結果的相關性

查全率(recall) :查全率又稱召回率,所有的真實(正)目標中,預測正確的目標比例,

查準率和查全率是一對矛盾的度量.一般來說,查準率高時,查全率往往偏低;而查全率高時,查準率往往偏低.
P–R曲線
以查準率為縱軸、查全率為橫軸作圖 ,就得到了查準率–查全率曲線,簡稱 P-R 線,顯示該曲線的圖稱為 “P-R圖"
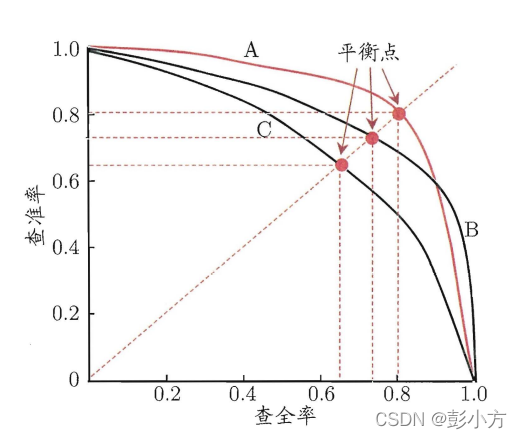
P-R圖 (取自西瓜書)
P-R圖直觀地顯示出學習器在樣本總體上的查全率、 查準率,每一個模型都有相應的P-R曲線,通過比較不同模型的P-R曲線,來評判模型的優劣,若一個模型A的 P-R 曲線被另一個模型B的曲線完全"包住 則可以說B的性能優于A,但是實際中很少出現這種情況,大部分曲線間都含有交叉, 因此我們需要一個綜合的度量"平衡點",它是"查準率= 查全率"時的取值,此時查準率等于查全率,他們的值越高,則模型的效果越好,
為什么PR曲線面積越大模型就會越好呢(排除過擬合的情況)?
我們訓練出的模型,在該模型下我們希望我們所想要預測的物件盡可能多的預測出來,而且預測的對的結果,盡可能的都是對的,查準率就是我們預測出來的正樣本,有多少實際為正,查全率就是預測為正的樣本占真實為正的樣本比例,所以PR曲線越凸越好(p:y,r:x),故面積越大,
IOU(交并比)
在目標檢測任務中,通常會使用交并比(Intersection of Union,IoU)作為衡量指標,來衡量兩個矩形框之間的關系,例如在基于錨框的目標檢測演算法中,我們知道當錨框中包含物體時,我們需要預測物體類別并微調錨框的坐標,從而獲得最終的預測框,此時,判斷錨框中是否包含物體就需要用到交并比,當錨框與真實框交并比足夠大時,我們就可以認為錨框中包含了該物體;而錨框與真實框交并比很小時,我們就可以認為錨框中不包含該物體,此外,在后面NMS的計算程序中,同樣也要使用交并比來判斷不同矩形框是否重疊,
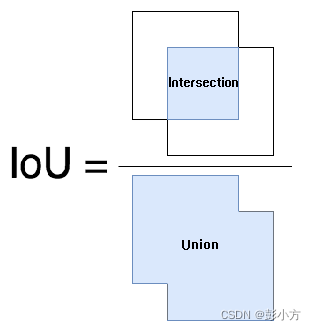
摘自百度圖庫
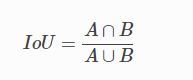
交并比公式
MAP(Mean Average precision)
即各個類別AP的平均值
AP:P-R曲線下的面積
下圖不同交并比下的map曲線,展現了目標檢測在VOCO和COCO資料集中的性能
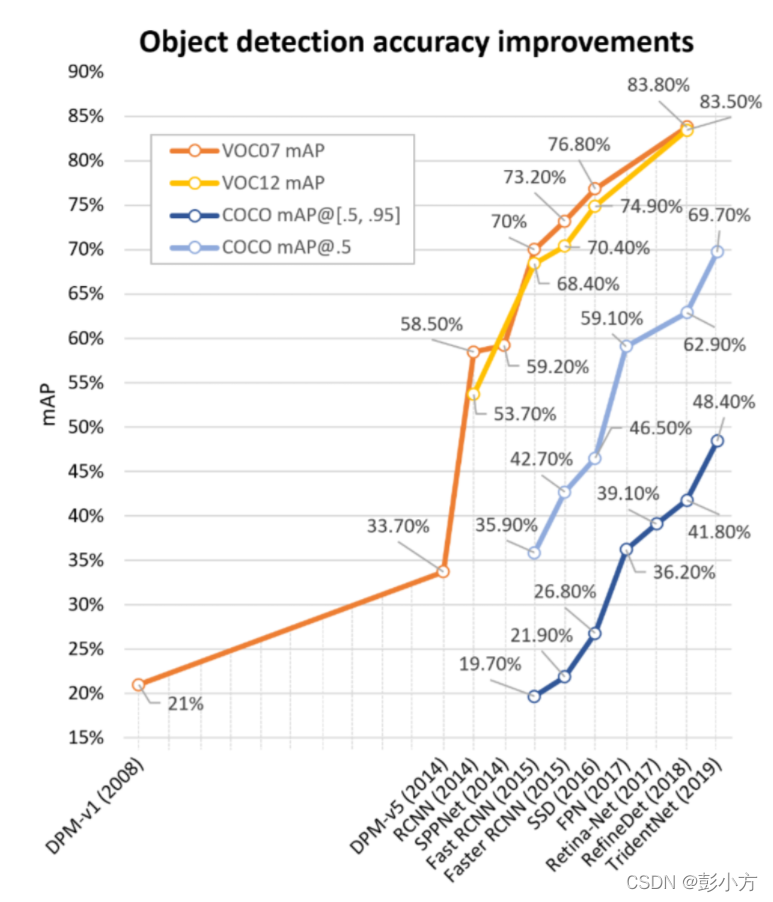
摘自 object detection in 20 years a survey
論文地址
object detection in 20 years a survey.
轉載請註明出處,本文鏈接:https://www.uj5u.com/qita/423351.html
標籤:AI
下一篇:對抗子空間維度探討