🔥 作者:FrigidWinter
🔥 簡介:主攻機器人與人工智能領域的理論研究和工程應用,業余豐富各種技術堆疊,主要涉足:【機器人(ROS)】【機器學習】【深度學習】【計算機視覺】
🔥 專欄:
- 《機器人原理與技術》
- 《計算機視覺教程》
- 《機器學習》
- 《嵌入式系統》
- …
目錄
- 1 引例
- 2 數值解法
- 3 梯度下降演算法
- 4 代碼實戰:Logistic回歸
1 引例
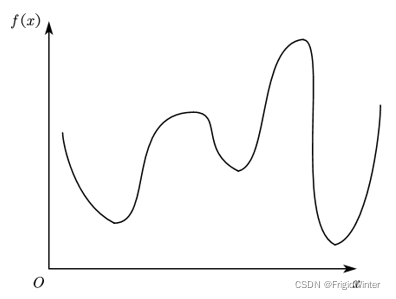
給定如圖所示的某個函式,如何通過計算機演算法編程求 f ( x ) m i n f(x)_{min} f(x)min??
2 數值解法
傳統方法是數值解法,如圖所示
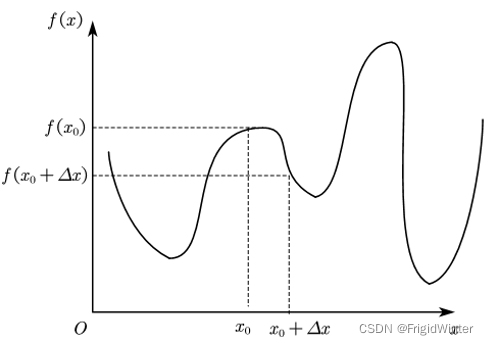
按照以下步驟迭代回圈直至最優:
① 任意給定一個初值 x 0 x_0 x0?;
② 隨機生成增量方向,結合步長生成 Δ x \varDelta x Δx;
③ 計算比較 f ( x 0 ) f\left( x_0 \right) f(x0?)與 f ( x 0 + Δ x ) f\left( x_0+\varDelta x \right) f(x0?+Δx)的大小,若 f ( x 0 + Δ x ) < f ( x 0 ) f\left( x_0+\varDelta x \right) <f\left( x_0 \right) f(x0?+Δx)<f(x0?)則更新位置,否則重新生成 Δ x \varDelta x Δx;
④ 重復②③直至收斂到最優 f ( x ) m i n f(x)_{min} f(x)min?,
數值解法最大的優點是編程簡明,但缺陷也很明顯:
① 初值的設定對結果收斂快慢影響很大;
② 增量方向隨機生成,效率較低;
③ 容易陷入區域最優解;
④ 無法處理“高原”型別函式,
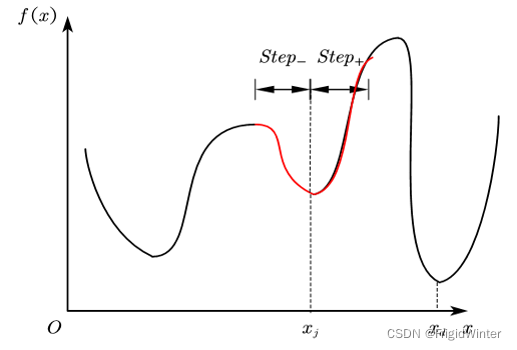
所謂陷入區域最優解是指當迭代進入到某個極小值或其鄰域時,由于步長選擇不恰當,無論正方向還是負方向,學習效果都不如當前,導致無法向全域最優迭代,就本問題而言如圖所示,當迭代陷入 x = x j x=x_j x=xj?時,由于學習步長 s t e p step step的限制,無法使 f ( x j ± S t e p ) < f ( x j ) f\left( x_j\pm Step \right) <f(x_j) f(xj?±Step)<f(xj?),因此迭代就被鎖死在了圖中的紅色區段,可以看出 x = x j x=x_j x=xj?并非期望的全域最優,
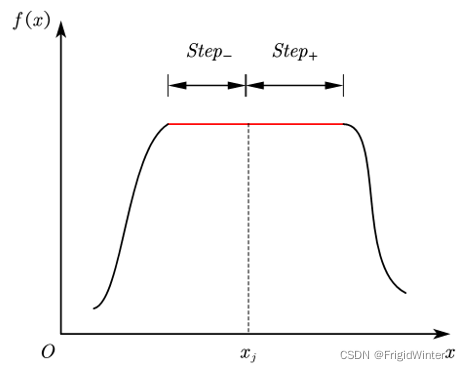
若出現下圖所示的“高原”函式,也可能使迭代得不到更新,
3 梯度下降演算法
梯度下降演算法可視為數值解法的一種改進,闡述如下:
記第 k k k輪迭代后,自變數更新為 x = x k x=x_k x=xk?,令目標函式 f ( x ) f(x) f(x)在 x = x k x=x_k x=xk?泰勒展開:
f ( x ) = f ( x k ) + f ′ ( x k ) ( x ? x k ) + o ( x ) f\left( x \right) =f\left( x_k \right) +f'\left( x_k \right) \left( x-x_k \right) +o(x) f(x)=f(xk?)+f′(xk?)(x?xk?)+o(x)
考察 f ( x ) m i n f(x)_{min} f(x)min?,則期望 f ( x k + 1 ) < f ( x k ) f\left( x_{k+1} \right) <f\left( x_k \right) f(xk+1?)<f(xk?),從而:
f ( x k + 1 ) ? f ( x k ) = f ′ ( x k ) ( x k + 1 ? x k ) < 0 f\left( x_{k+1} \right) -f\left( x_k \right) =f'\left( x_k \right) \left( x_{k+1}-x_k \right) <0 f(xk+1?)?f(xk?)=f′(xk?)(xk+1??xk?)<0
若 f ′ ( x k ) > 0 f'\left( x_k \right) >0 f′(xk?)>0則 x k + 1 < x k x_{k+1}<x_k xk+1?<xk?,即迭代方向為負;反之為正,不妨設 x k + 1 ? x k = ? f ′ ( x k ) x_{k+1}-x_k=-f'(x_k) xk+1??xk?=?f′(xk?),從而保證 f ( x k + 1 ) ? f ( x k ) < 0 f\left( x_{k+1} \right) -f\left( x_k \right) <0 f(xk+1?)?f(xk?)<0,必須指出,泰勒公式成立的條件是 x → x 0 x\rightarrow x_0 x→x0?,故 ∣ f ′ ( x k ) ∣ |f'\left( x_k \right) | ∣f′(xk?)∣不能太大,否則 x k + 1 x_{k+1} xk+1?與 x k x_{k} xk?距離太遠產生余項誤差,因此引入學習率 γ ∈ ( 0 , 1 ) \gamma \in \left( 0, 1 \right) γ∈(0,1)來減小偏移度,即 x k + 1 ? x k = ? γ f ′ ( x k ) x_{k+1}-x_k=-\gamma f'(x_k) xk+1??xk?=?γf′(xk?)
在工程上,學習率 γ \gamma γ要結合實際應用合理選擇, γ \gamma γ過大會使迭代在極小值兩側振蕩,演算法無法收斂; γ \gamma γ過小會使學習效率下降,演算法收斂慢,
對于向量 ,將上述迭代公式推廣為
x k + 1 = x k ? γ ? x k {\boldsymbol{x}_{\boldsymbol{k}+1}=\boldsymbol{x}_{\boldsymbol{k}}-\gamma \nabla _{\boldsymbol{x}_{\boldsymbol{k}}}} xk+1?=xk??γ?xk??
其中 ? x = ( ? f ( x ) ? x 1 , ? f ( x ) ? x 2 , ? ? ? , ? f ( x ) ? x n ) T \nabla _{\boldsymbol{x}}=\left( \frac{\partial f(\boldsymbol{x})}{\partial x_1},\frac{\partial f(\boldsymbol{x})}{\partial x_2},\cdots \cdots ,\frac{\partial f(\boldsymbol{x})}{\partial x_n} \right) ^T ?x?=(?x1??f(x)?,?x2??f(x)?,??,?xn??f(x)?)T為多元函式的梯度,故此迭代演算法也稱為梯度下降演算法
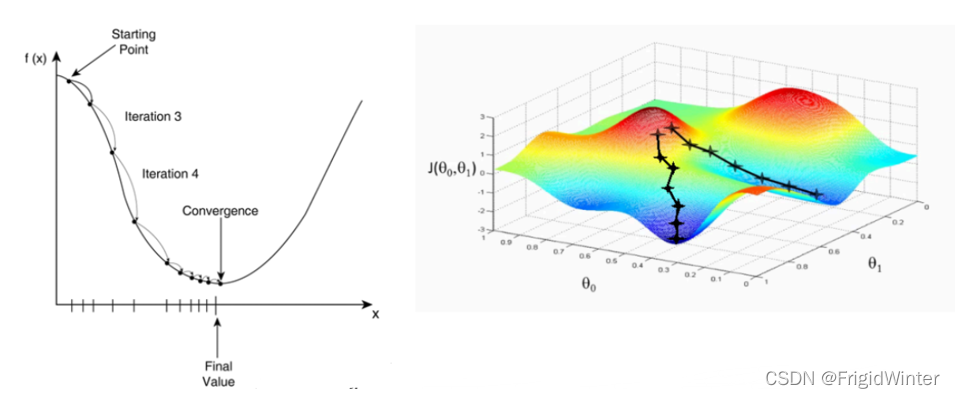
梯度下降演算法通過函式梯度確定了每一次迭代的方向和步長,提高了演算法效率,但從原理上可以知道,此演算法并不能解決數值解法中初值設定、區域最優陷落和部分函式鎖死的問題,
4 代碼實戰:Logistic回歸
import pandas as pd
import numpy as np
import os
import matplotlib.pyplot as plt
import matplotlib as mpl
from Logit import Logit
'''
* @breif: 從CSV中加載指定資料
* @param[in]: file -> 檔案名
* @param[in]: colName -> 要加載的列名
* @param[in]: mode -> 加載模式, set: 列名與該列資料組成的字典, df: df型別
* @retval: mode模式下的回傳值
'''
def loadCsvData(file, colName, mode='df'):
assert mode in ('set', 'df')
df = pd.read_csv(file, encoding='utf-8-sig', usecols=colName)
if mode == 'df':
return df
if mode == 'set':
res = {}
for col in colName:
res[col] = df[col].values
return res
if __name__ == '__main__':
# ============================
# 讀取CSV資料
# ============================
csvPath = os.path.abspath(os.path.join(__file__, "../../data/dataset3.0alpha.csv"))
dataX = loadCsvData(csvPath, ["含糖率", "密度"], 'df')
dataY = loadCsvData(csvPath, ["好瓜"], 'df')
label = np.array([
1 if i == "是" else 0
for i in list(map(lambda s: s.strip(), list(dataY['好瓜'])))
])
# ============================
# 繪制樣本點
# ============================
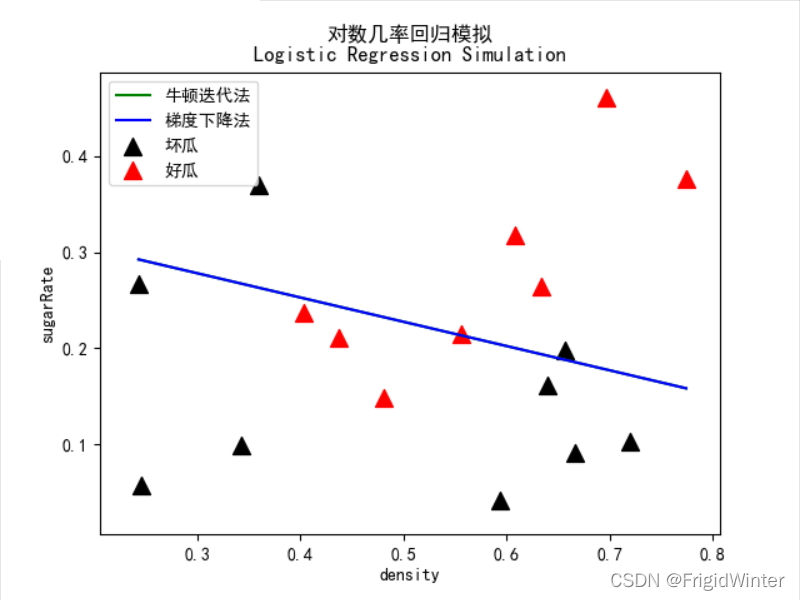
line_x = np.array([np.min(dataX['密度']), np.max(dataX['密度'])])
mpl.rcParams['font.sans-serif'] = [u'SimHei']
plt.title('對數幾率回歸模擬\nLogistic Regression Simulation')
plt.xlabel('density')
plt.ylabel('sugarRate')
plt.scatter(dataX['密度'][label==0],
dataX['含糖率'][label==0],
marker='^',
color='k',
s=100,
label='壞瓜')
plt.scatter(dataX['密度'][label==1],
dataX['含糖率'][label==1],
marker='^',
color='r',
s=100,
label='好瓜')
# ============================
# 實體化對數幾率回歸模型
# ============================
logit = Logit(dataX, label)
# 采用梯度下降法
logit.logitRegression(logit.gradientDescent)
line_y = -logit.w[0, 0] / logit.w[1, 0] * line_x - logit.w[2, 0] / logit.w[1, 0]
plt.plot(line_x, line_y, 'b-', label="梯度下降法")
# 繪圖
plt.legend(loc='upper left')
plt.show()
轉載請註明出處,本文鏈接:https://www.uj5u.com/qita/423353.html
標籤:AI
上一篇:對抗子空間維度探討
下一篇:pandas中dataframe默認不顯示所有的資料行(中間省略)、使用option_context函式自定義設定單個dataframe允許顯示的行的個數、set_option函式全域設定顯示行的個數