今天雖然有一些感冒,但是現在感覺實力爆棚,一股想要學習的沖動
小談:
昨天晚上睡覺的時候,當時的閱讀量有19300多吧,然后寫了一篇比較擺爛的博客,當時說如果閱讀量破兩萬,就一定好好寫博客,誰知道半夜醒來的時候就已經19900,早上醒來就已經突破兩萬了,這不明顯系統在安排我,讓我好好寫博客,今天就努一努,不寫好一篇博客不睡覺,
稍微有一些感冒,早上力不從心,頭暈然后就沒有學習鉆被窩里面睡了會覺,和我的那個她聊了聊天,玩了一會跳棋,
TopN案例
時間戳 省份 城市 用戶 廣告
1516609143867 6 7 64 16
1516609143869 9 4 75 18
1516609143869 1 7 87 12
1516609143869 2 8 92 9
1516609143869 6 7 84 24
1516609143869 1 8 95 5
1516609143869 8 1 90 29
求每個省份,排名前三的廣告以及點擊量,
先來看一下圖解
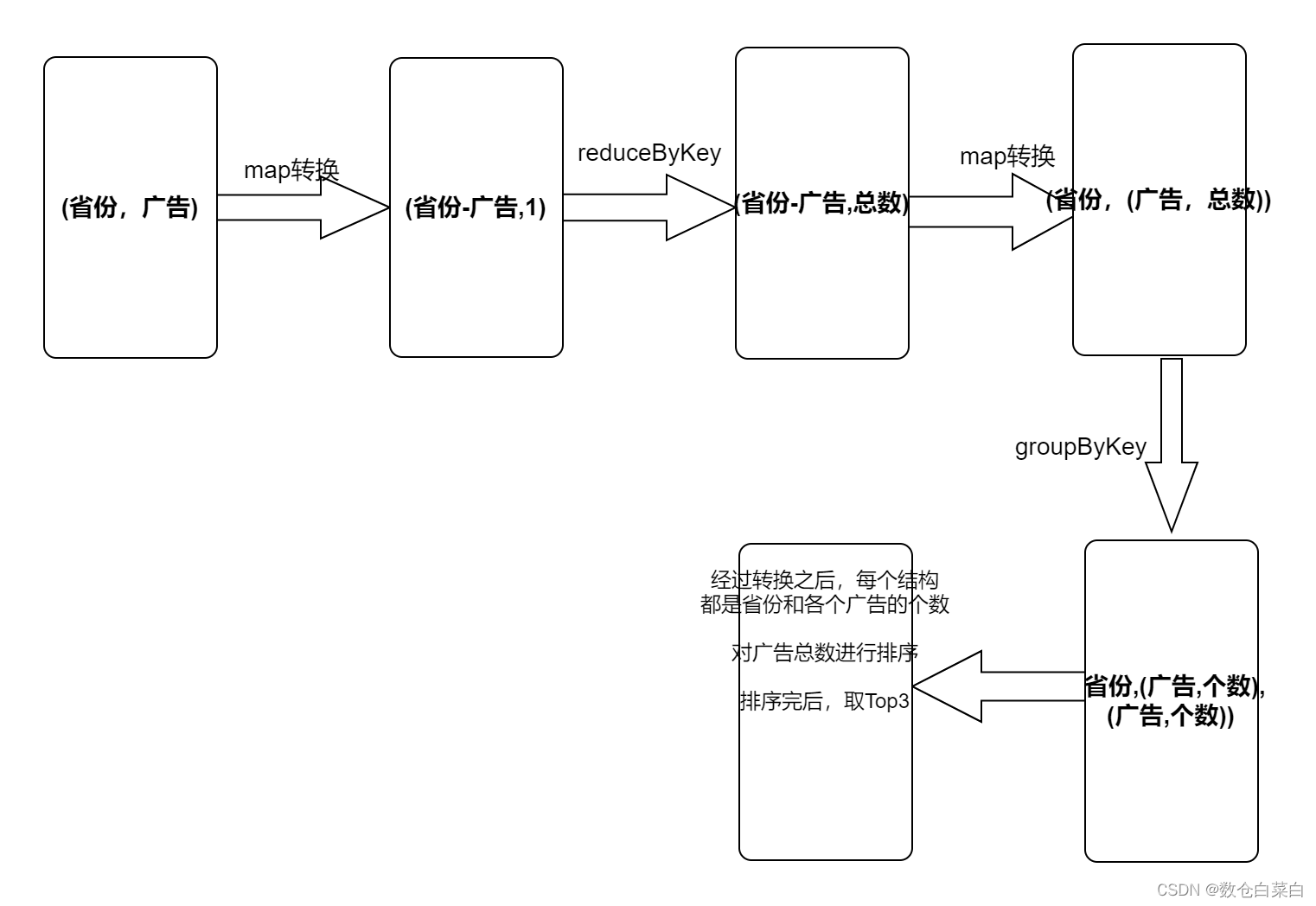
總之先取出相應的欄位,對這些欄位進行格式轉換,之后使用各個算子進行操作
下面來看代碼吧,根據代碼一一講解
val wordCount = new SparkConf().setMaster("local").setAppName("WordCount")
val sparkContext = new SparkContext(wordCount)
//時間戳 省份 城市 用戶 廣告
val value = sparkContext.textFile("date/agent.log")
//首先取出來省份和廣告 //map轉換 (省份-廣告,1)
val value1 = value.map( line => {
val strings = line.split(" ")
(strings(1) + " - " +strings(4),1 ) } )
//根據key進行累加,最后結果就是(省份-廣告,總數)
val value2 = value1.reduceByKey(_ + _)
//(省份-廣告 ,總數) =>(省份,(廣告,總數))
val value3 = value2.map {
case (province, clickCount) => {
val strings = province.split("-")
(strings(0), (strings(1), clickCount)) } }
//對省份進行分組,分組后的資料格式
//(省份,((廣告,總數),(廣告,總數),(廣告,總數)))
val value4 = value3.groupByKey()
//對后面的廣告根據總數進行排序,取降序
//mapValues 對Value進行操作 將Value根據SortWith自定義排序
value4.mapValues( itr => {
itr.toList.sortWith(
(left,right)=>{ left._2 > right._2 } ).take(3) } )
.collect().foreach(println(_))求TopN,關鍵就是在于要將格式進行轉化,其實算子的操作都很簡單,重要的點是能否轉換成自己想要的格式,如果沒有思路,可以先在紙上寫一些思路,有了思路就可以很好的進行編碼了,Reduce
聚合RDD中的所有元素,先聚合磁區內的元素,再聚合磁區間的元素
val value = sparkContext.makeRDD(List(1, 2, 3, 4),2)
兩個磁區,磁區0: 1 2 磁區1:3 4
聚合的時候,先將磁區內的元素聚合
磁區0: 1 +2 =3 磁區1: 3 + 4 = 7
來看一下代碼
val wordCount = new SparkConf().setMaster("local").setAppName("WordCount")
val sparkContext = new SparkContext(wordCount)
val value = sparkContext.makeRDD(List(1, 2, 3, 4))
val i = value.reduce(_ + _) println(i)可以看到的是,在轉換算子的時候,都會有RDD顯示出來,但是動作算子并沒有顯示RDD,

可以看到,轉換算子并不存盤資料,在Spark初了解博客里面就說過,轉換算子并不存盤資料,只是存盤操作,當資料到節點之后,資料就會根據記錄的操作對資料進行轉換,
行動算子之后,就可以從節點將資料回傳到Driver端,
Collect
在驅動程式中,以陣列Array形式回傳資料集的所有元素,
來看一下Collect動作算子
def collect(): Array[T] = withScope {
val results = sc.runJob(this, (iter: Iterator[T]) =>
iter.toArray) Array.concat(results: _*) }可以看到 iter.toArray,將元素轉換成陣列的形式
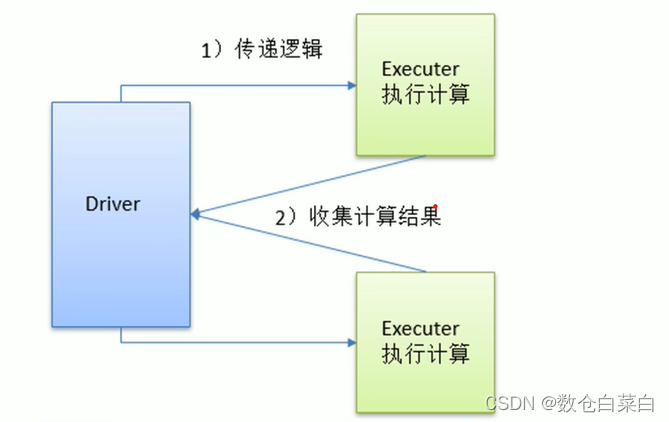
foreach
遍歷RDD中的每一個元素,并依次呼叫里面的函式
舉一個例子
val wordCount = new SparkConf().setMaster("local").setAppName("WordCount")
val sparkContext = new SparkContext(wordCount)
val value = sparkContext.makeRDD(List(1, 2, 3, 4))
val i = value.foreach(println(_)) println(i)上面這個例子中,就會遍歷RDD中的每一個元素,因為設定的f函式就是列印操作
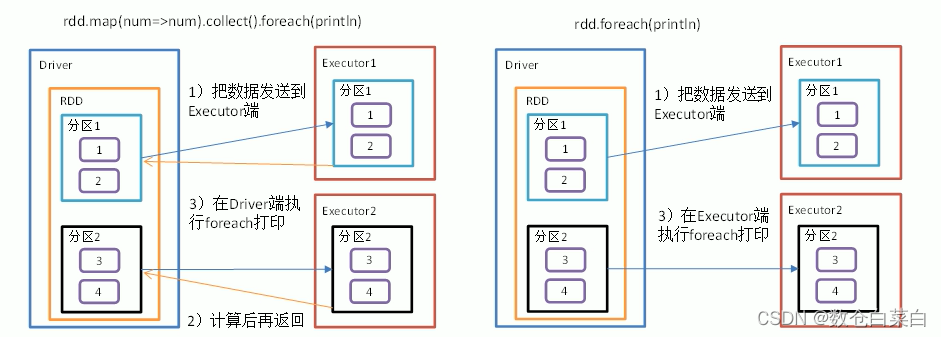
Count
回傳RDD中元素個數
val wordCount = new SparkConf().setMaster("local").setAppName("WordCount")
val sparkContext = new SparkContext(wordCount)
val value = sparkContext.makeRDD(List(1, 2, 3, 4))
val i = value.count() println(i)看一下圖解

first
回傳RDD中的第一個元素
val wordCount = new SparkConf().setMaster("local").setAppName("WordCount")
val sparkContext = new SparkContext(wordCount)
val value = sparkContext.makeRDD(List(1, 2, 3, 4))
val i = value.first() println(i)回傳第一個元素,就是1
take
回傳一個由RDD的前n個元素組成的陣列
val wordCount = new SparkConf().setMaster("local").setAppName("WordCount")
val sparkContext = new SparkContext(wordCount)
val value = sparkContext.makeRDD(List(1, 2, 3, 4))
val i = value.take(2) println(i)回傳的是陣列型別,單獨列印的話,列印的就是陣列的地址,
takeOrdered
回傳該RDD排序后的前n個元素組成的陣列
val wordCount = new SparkConf().setMaster("local").setAppName("WordCount")
val sparkContext = new SparkContext(wordCount)
val value = sparkContext.makeRDD(List(1, 2, 3, 4))
val i = value.takeOrdered(2) println(i)怎么知道回傳的是排序后的陣列呢,看一下原始碼
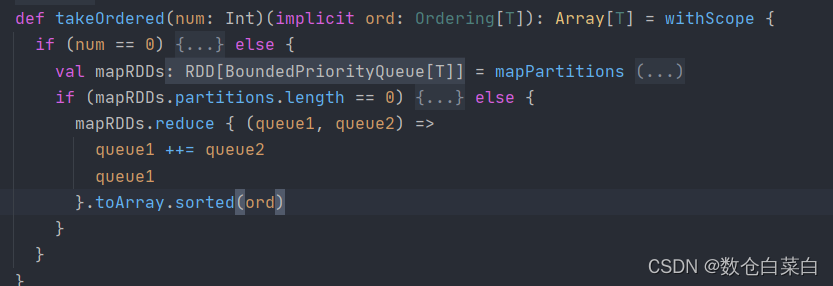
.toArray.sorted(ord),像轉換成陣列,然后排序,排完序后取前n個值
aggregate
將每個磁區內的元素通過磁區內邏輯和初始值進行聚合,然后用磁區間邏輯和初始值進行操作,
先看圖解,根據圖解來講
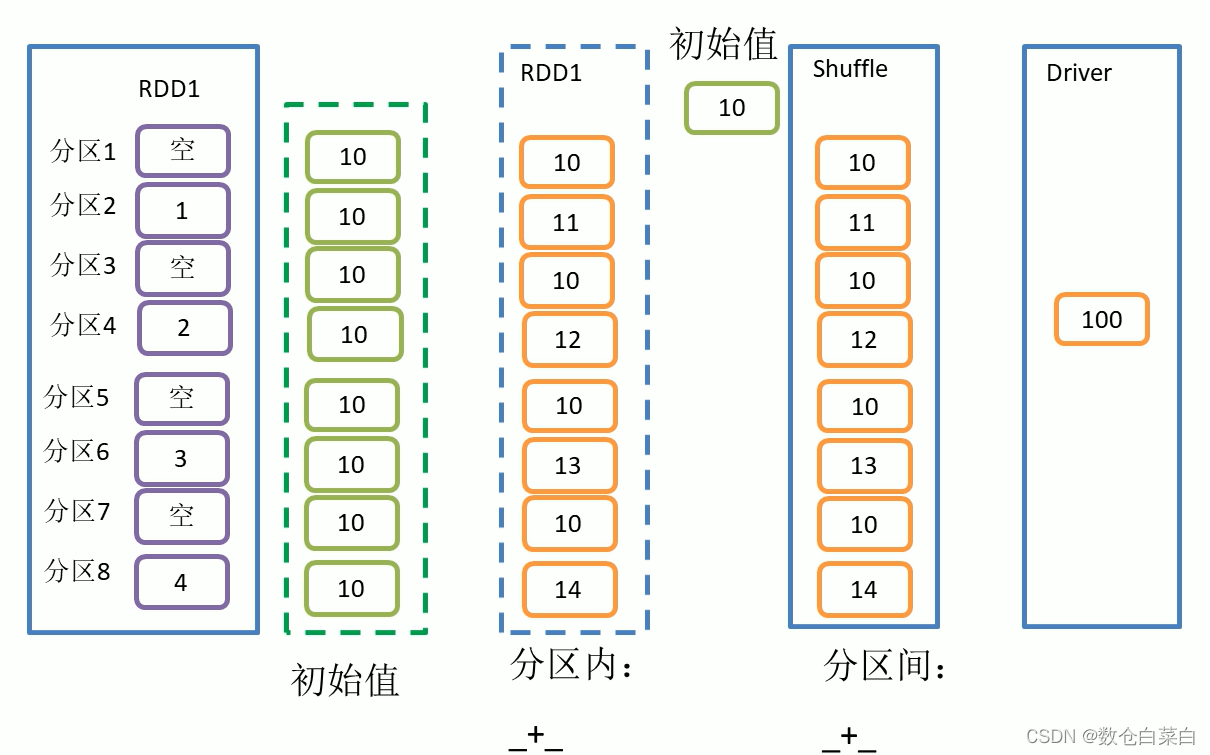
4個資料分了8個區
val value = sparkContext.makeRDD(List(1, 2, 3, 4),8)
val i1 = value.aggregate(10)(_+ _, _ + _)在磁區內:對每一個值都和設定的初始值10,進行相加,
磁區間:在磁區間計算的時候,將每個磁區間的值進行相加,之后再與初始值進行相加,
countByKey
統計每種key的個數
看一下圖解
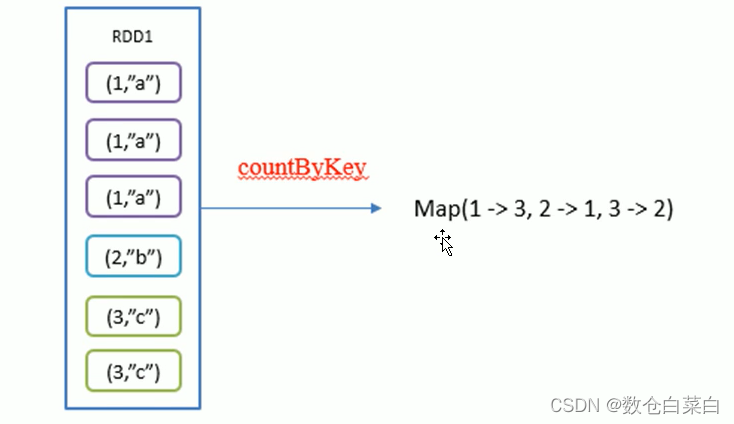
回傳的是Map[K,Long]型別
key key的總數
總結:
更新到這里就不寫了,要去歇息一會,
如果我是一個打工仔,那么明天就要上班拉,雖然現在還不是打工仔,已經快是了,
這兩天更新的內容,干貨不是特別多,到明天會更新磁區器的相關內容,
明天就要開始卷啦,顫抖吧,學生仔!!!
轉載請註明出處,本文鏈接:https://www.uj5u.com/qita/423409.html
標籤:其他
上一篇:一天學完spark的Scala基礎語法教程十三、檔案IO操作(idea版本)
下一篇:電商大促作戰指南