一.模板匹配
定義:讓模板影像在輸入影像中滑動逐像素遍歷整個影像進行比較,查找出與模板影像最匹配的部分,
單目標匹配
定義:輸入影像中只存在一個可能匹配結果
基本格式如下:
result = cv2.matchTemplate(image,templ,method)
- image為輸入影像
- templ為模板影像,要小于image
- method為匹配方法,如下:
- cv2.TM_SQDIFF:以方差結果為依據進行匹配,完全匹配時結果為零,否則為很大的值
- cv2.TM_SQDIFF_NORMED:標準(歸一化)方差匹配
- cv2.TM_CCORR:相關匹配,將輸入影像與模板影像相乘,乘積越大匹配程度越高,乘積為0匹配程度最低
- cv2.TM_CCORR_NORMED:標準(歸一化)相關匹配
- cv2.TM_CCOEFF:相關系數匹配,將輸入影像于其均值的相關性和模板影像與其均值的相關值進行匹配,1為完美匹配,-1并表示糟糕匹配,0表示沒有任何相關性,
- cv2.TM_CCOEFF_NORMED:標準(歸一化)相關系數匹配
- result為回傳結果,當匹配方法為前兩個時,匹配結果值越小匹配度越高,越大匹配度越低,當為后四個時值越小說明匹配度越低,反之則說明匹配度越高,
opencv中的cv2.minMaxLoc()函式用于處理匹配結果
minVal,maxVal,minLocmmaxLoc=cv2.minMaxLoc(src)
- src是上面的matchTemplate()函式的回傳結果
- minVal(maxVal)為src中的最小值(最大值),不存在時可以為NULL(空值)
- minLoc(MaxLoc)為src中最小值(最大值)的位置,不存在時可以為NULL
實體代碼如下
import cv2
import numpy as np
import matplotlib. pyplot as plt
img1=cv2. imread( 'img/a.jpg')
cv2. imshow( ' original', img1)
temp=cv2. imread( 'img/b.jpg' )
cv2. imshow('template',temp)
img1gray=cv2. cvtColor(img1, cv2.COLOR_BGR2GRAY,dstCn=1)
tempgray=cv2. cvtColor(temp, cv2.COLOR_BGR2GRAY,dstCn=1)
h, w=tempgray.shape
res=cv2. matchTemplate(img1gray, tempgray,cv2.TM_SQDIFF)
plt.imshow(res,cmap = 'gray')
plt.title( 'Matching Result')
plt.axis('off')
plt. show()
min_val,max_val,min_loc,max_loc=cv2 .minMaxLoc(res)
top_left = min_loc
bottom_right = (top_left[0] + w, top_left[1] + h)
cv2.rectangle(img1,top_left, bottom_right,(255,0,0),2)
cv2. imshow(' Detected Range ',img1)
cv2. waitKey(0)
原影像:

模板影像:

匹配結果:
本次用了cv2.TM_SQDIFF作為匹配方法,所以值越小匹配度就越高,用灰度影像格式顯示匹配結果,所以圖中顏色越深的位置匹配度越高
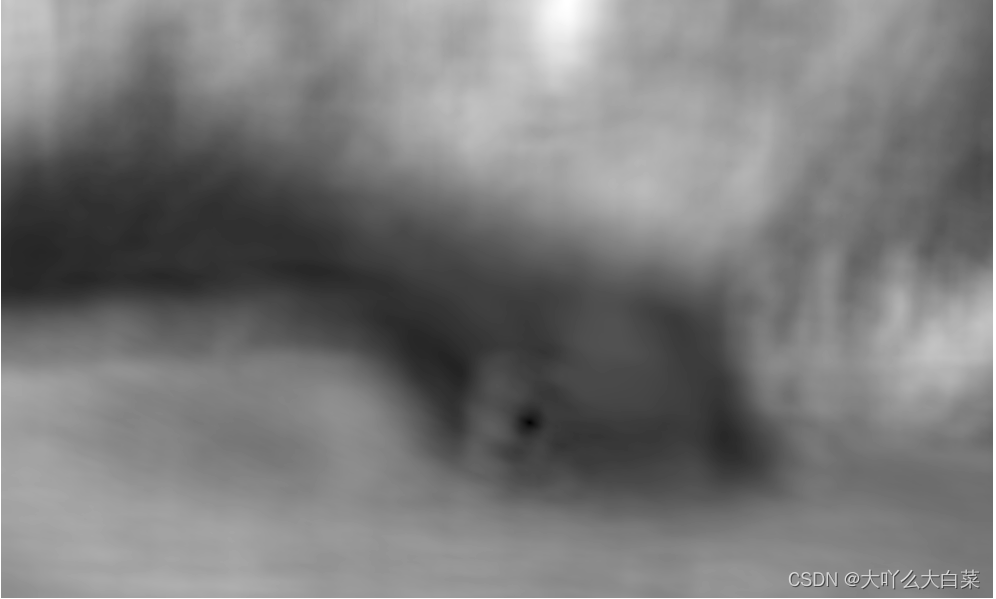
模板影像在原圖當中的位置:

多目標匹配
定義:輸入影像中存在多個可能的匹配
以查找象棋為例,查找“卒象棋”:
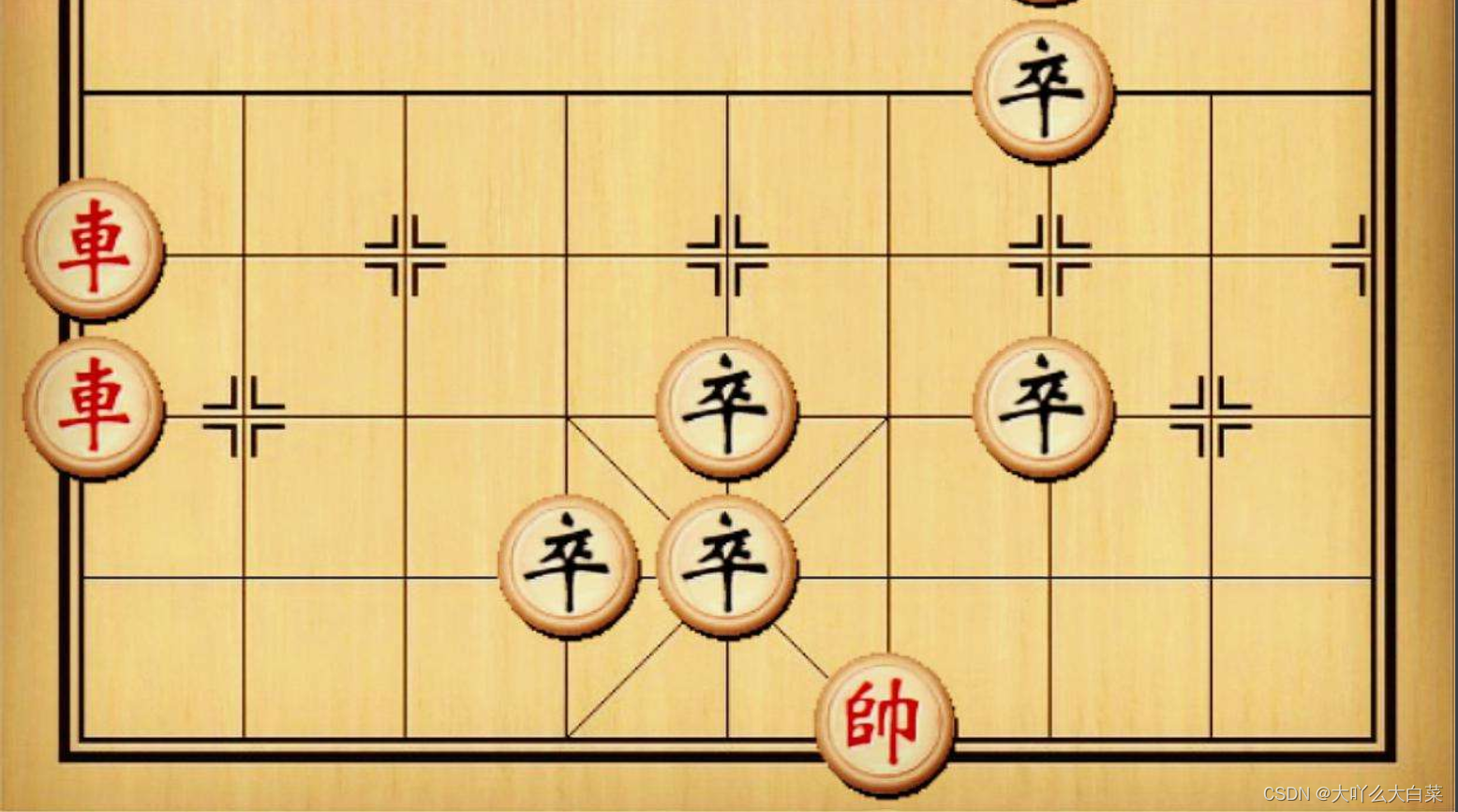
模板影像:

代碼如下:
import cv2
import numpy as np
import matplotlib.pyplot as plt
img1=cv2. imread('img/d.jpg') #打開輸入影像,默認為BGR格式
temp=cv2. imread('img/e.jpg') #打開模板影像
img1gray=cv2. cvtColor(img1, cv2. COLOR_BGR2GRAY, dstCn=1) #轉換為單通道灰度影像
tempgray=cv2. cvtColor(temp,cv2. COLOR_BGR2GRAY , dstCn=1) #轉換為單通道灰度影像
th, tw=tempgray.shape #獲得模板影像的高度和寬度
img1h, img1w= img1gray. shape
res = cv2.matchTemplate(img1gray, tempgray, cv2.TM_SQDIFF_NORMED) #執行匹配操作
mloc=[] #用于保存符合條件的匹配位置
threshold = 0.02 #設定匹配度閾值
for i in range(img1h-th): #查找符合條件的匹配結果位置
for j in range(img1w-tw):
if res[i][j]<=threshold: #保存小于閾值的匹配位置
mloc.append((j,i))
for pt in mloc:
cv2.rectangle(img1,pt, (pt[0]+tw,pt[1]+th),(255,0,0),2) #標注匹配位置,藍色
cv2. imshow( ' result' ,img1) #顯示結果
cv2.waitKey(0)
這種多目標匹配相較于上面的單目標的區別主要在于通過threshold,設定匹配度的閾值來篩選匹配位置,因為上面代碼采用的模板匹配方法是cv2.TM_SQDIFF_NORMED,匹配結果越小匹配度越高,所以小于匹配度閾值的會被篩選出來,結果如下:
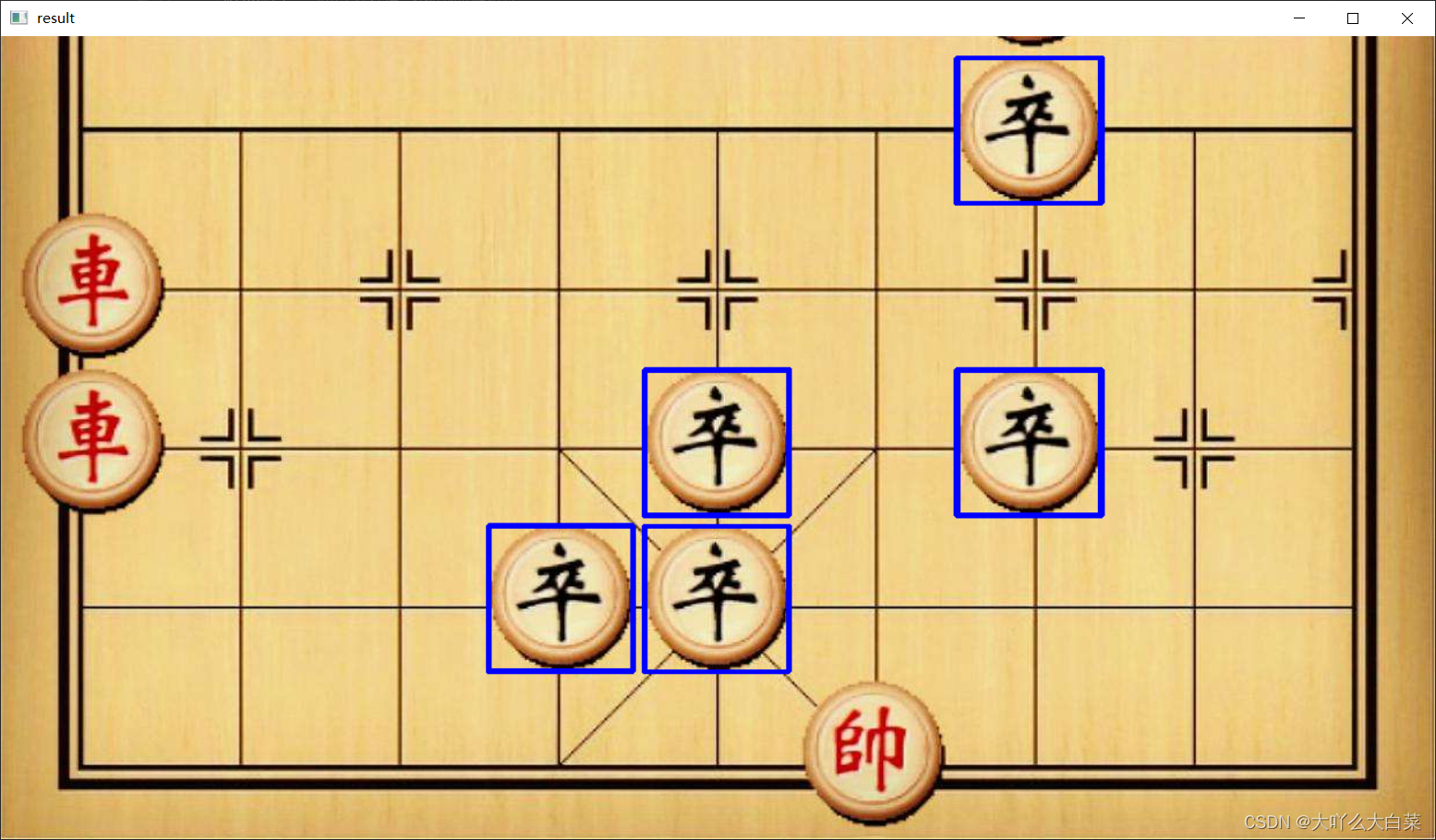
二.影像分割
本節采用分水嶺演算法和影像金字塔對影像進行分割的方法
使用分水嶺演算法分割影像
基本原理:將任意的灰度影像視為地形圖表面,其中灰度值高的部分表示山峰和丘陵,灰度值低的部分表示山谷,用不同的顏色的水(標簽)填充每個獨立的山谷(區域最小值);隨著水平面的上升,來自不同山谷(具有不同顏色)的水將開始合并,為了避免出現這種現象,需要在水的匯合位置建造水壩;持續填充水和建造水壩,直至所有的山峰和丘陵都在水下,整個程序中建造的水壩將作為影像分割的依據,
分水嶺演算法分割影像步驟:
- 將源影像轉換為灰度影像
- 運用開運算(先腐蝕后膨脹,去除影像中的細小白色噪點)和膨脹操作(膨脹運算使得一部分背景成為了物體的邊界,因為先進行了二值化處理得到的影像中的黑色區域肯定是真實背景)
- 進行距離轉換(用下面函式,其中每個像素的值為其到最近的背景像素(灰度值為0)的距離,而中心像素值最大(中心離背景像素最遠),對其進行二值處理就得到了分離的前景圖),再進行閾值處理,確定影像前景
- 確定影像的未知區域(用影像的背景減去前景的剩余部分,可能是邊界的部分)
- 標記背景影像
- 執行分水嶺演算法分割影像
此處有演算法詳細的解釋
我們需要給不同區域貼上不同的標簽,用大于1的整數表示我們確定為前景或物件的區域,用1表示我們確定為背景或非物件的區域,最后用0表示我們無法確定的區域,然后應用分水嶺演算法,我們的標記影像將被更新,更新后的標記影像的邊界像素值為-1,
cv2.distanceTransform()函式用來計算非0值像素點到0值(背景)像素點的距離
dst=cv2.distanceTransform(src,distanceType,maskSize[,dstType])
- dst為回傳的距離轉換結果影像
- src為原影像
- distanceType為距離型別
- maskSize為掩模的大小,可設定為0、3、5.
- dstType為回傳的影像型別,默認為CV_32F(32位浮點數)
import cv2
import numpy as np
img=cv2. imread( 'img/aa.jpg' )
cv2. imshow('original',img) #顯示原圖
gray=cv2. cvtColor( img, cv2. COLOR_BGR2GRAY) #轉換為灰度圖
ret, imgthresh=cv2. threshold(gray,0,255,cv2. THRESH_BINARY_INV+cv2.THRESH_OTSU) #Otsu演算法閾值處理
kernel=np.ones((3,3),np.uint8) #定義形態變換卷積核
imgopen=cv2 . morphologyEx(imgthresh,cv2.MORPH_OPEN,kernel, iterations=2) #形態變換:開運算
imgdist=cv2. distanceTransform( imgopen,cv2.DIST_L2,3) #距離轉換
cv2. imshow('distance',imgdist) #顯示距離轉換結果
cv2. waitKey(0)
原圖:注意最上面的圓中的十字星中的里面也是十字星

距離轉換結果圖:十字星變成了橢圓形,因為星星的角上進行距離轉換后的圖形顏色會比較淺,在進行閾值處理就會被處理成白色
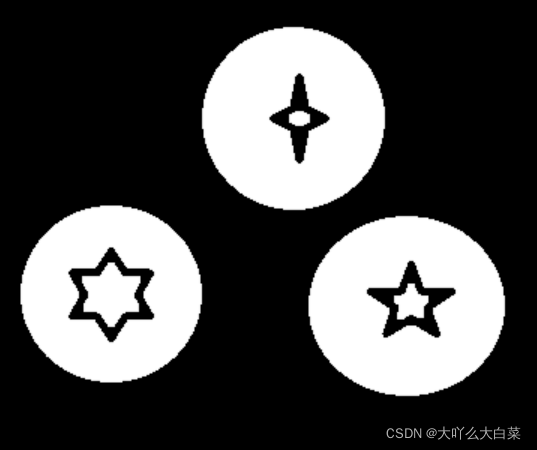
cv2.connectedComponents()函式用于將影像中的背景標記為0,將其他影像標記為1開始的整數
格式如下:
ret,labels=cv2.connectedComponents(image[,connectivity[,ltype]])
引數說明如下:
- labels為回傳的標記結果影像,和image大小相同
- image為要標記的8位單通道影像
- connectivity為4或8(默認值)
- ltype為回傳的標記結果影像的型別
ret, imgfg=cv2.threshold(imgdist,0.7*imgdist.max(),255,2) #對距離轉換結果進行閾值處理
imgfg=np.uint8(imgfg) #轉換為整數
ret,markers=cv2.connectedComponents(imgfg) #標記閾值處理結果
cv2.watershed()函式用于執行分水嶺演算法分割影像,基本格式如下
ret=cv2.watershed(image,markers)
- ret為回傳的8位或32位單通道影像
- image為輸入的8位3通道影像
- markers為輸入的32位單通道影像
import cv2
import numpy as np
import matplotlib.pyplot as plt
img=cv2. imread('img/ccc.jpg')
gray=cv2. cvtColor(img, cv2.COLOR_BGR2GRAY) #轉換為灰度圖
ret, imgthresh=cv2. threshold(gray, 0,255,cv2.THRESH_BINARY_INV+cv2.THRESH_OTSU) #Otsu演算法閾值處理
kernel=np . ones((5,5), np.uint8) #定義形態變換卷積核
imgopen=cv2. morphologyEx(imgthresh, cv2.MORPH_OPEN,kernel, iterations=2) #形態變換:開運算
imgbg=cv2. dilate( imgopen, kernel, iterations=3) #膨脹操作,確定背景
imgdist=cv2. distanceTransform( imgopen, cv2.DIST_L2,0) #距離轉換
ret, imgfg=cv2. threshold(imgdist,0.7*imgdist .max(),255,2) #對距離轉換結果進行閾值處理
imgfg=np.uint8( imgfg) #轉換為整數,獲得前景影像
ret,markers=cv2. connectedComponents(imgfg) #標記閾值處理結果
unknown= cv2. subtract(imgbg, imgfg) #確定位置未知區域
markers=markers+1 #加1使背景不為0
markers[unknown==255]=0 #將未知區域設定為0
imgwater=cv2. watershed(img, markers) #執行分水嶺演算法分割影像
plt. imshow( imgwater) #以灰度影像格式顯示匹配結果
plt. title( 'watershed')
plt.axis('off')
plt. show()
img[ imgwater==-1]=[0,255,0] #將原圖中的被標記點設定為綠色
cv2. imshow('watershed',img) #顯示分割結果
cv2.waitKey(0)
分水嶺演算法回傳的結果影像
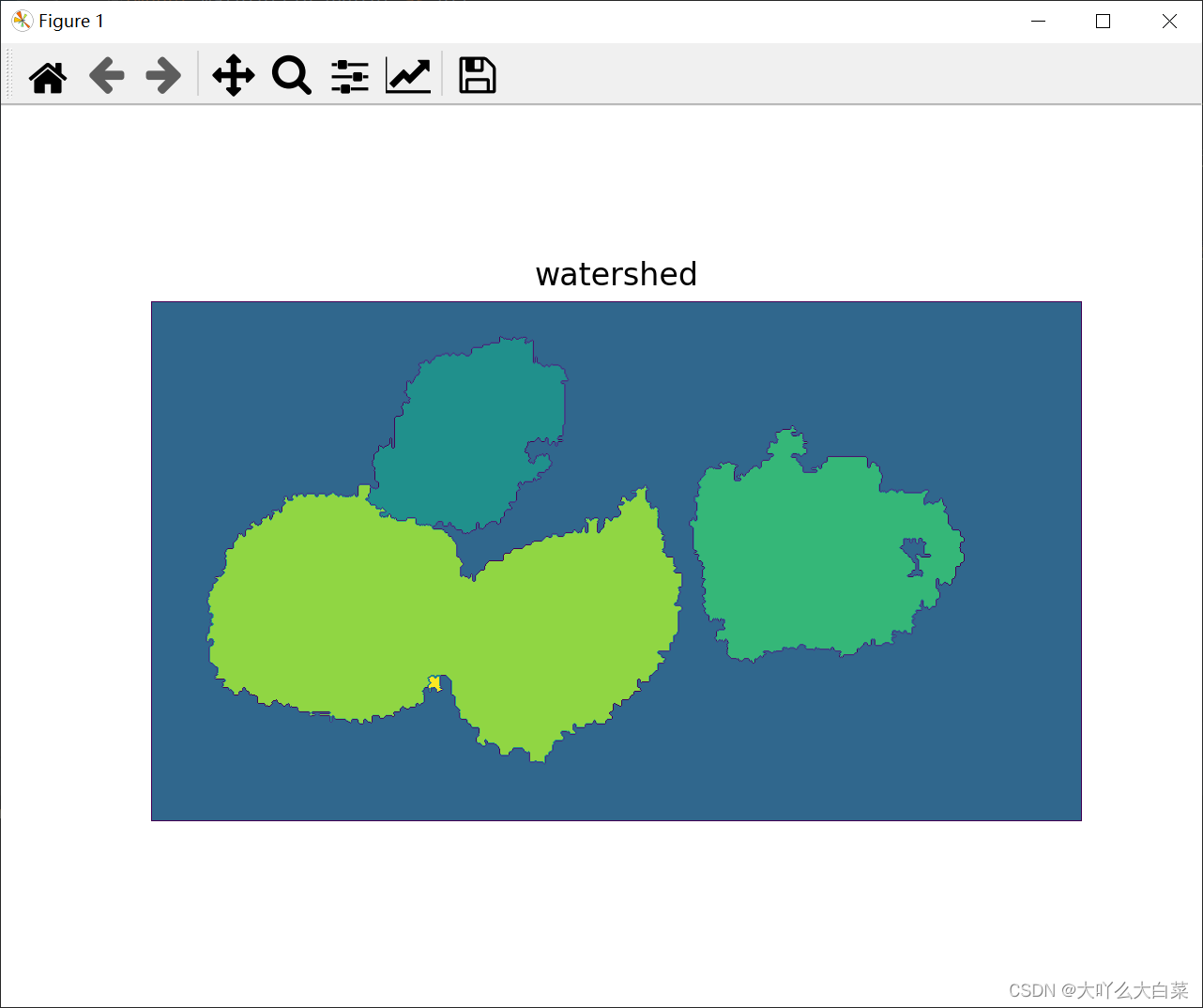
原圖中標記的分割結果(綠色為分割線):

影像金字塔
影像金字塔從解析度的角度分析處理影像,影像金字塔的底部為原始影像,對原始影像進行梯次向下采樣,得到金字塔的其他各層影像,層次越高,解析度越低,影像越小,通常,每向上一層,影像的寬度和高度就為下一層的一半,常見的影像金字塔可分為高斯金字塔和拉普拉斯金字塔,
高斯金字塔有向下和向上兩種采樣方式,向下采樣時,原始影像為第0層,第1次向下采樣的結果為第1層,第2次向下采樣的結果為第2層,依此類推, 每次采樣影像的高度和寬度都減小為原來的一 半,所有的圖層構成高斯金字塔, 向上采樣的程序和向下采樣相反 ,每次采樣影像的高度和寬度 都擴大為原來的二倍,
高斯金字塔向下采樣
cv2.pyrDown() 函式基本格式如下:
ret=cv2.pyrDown(image[,dstsize[,borderType]])
- ret為回傳的結果影像,型別和輸入影像相同
- image為輸入影像
- dstsize為結果影像大小
- borderType為邊界值型別
import cv2
img0=cv2. imread('img/dd.jpg')
img1=cv2. pyrDown( img0) #第1次采樣
img2=cv2. pyrDown(img1) #第2次采樣
cv2. imshow( ' img0', img0) #顯示第0層
cv2. imshow( ' img1',img1) #顯示第1層
cv2. imshow( ' img2',img2) #顯示第2層
print('0層形狀: ', img0.shape) #輸出影像形狀
print('1層形狀: ',img1.shape) #輸出影像形狀
print('2層形狀:', img2. shape) #輸出影像形狀
cv2. waitKey(0)
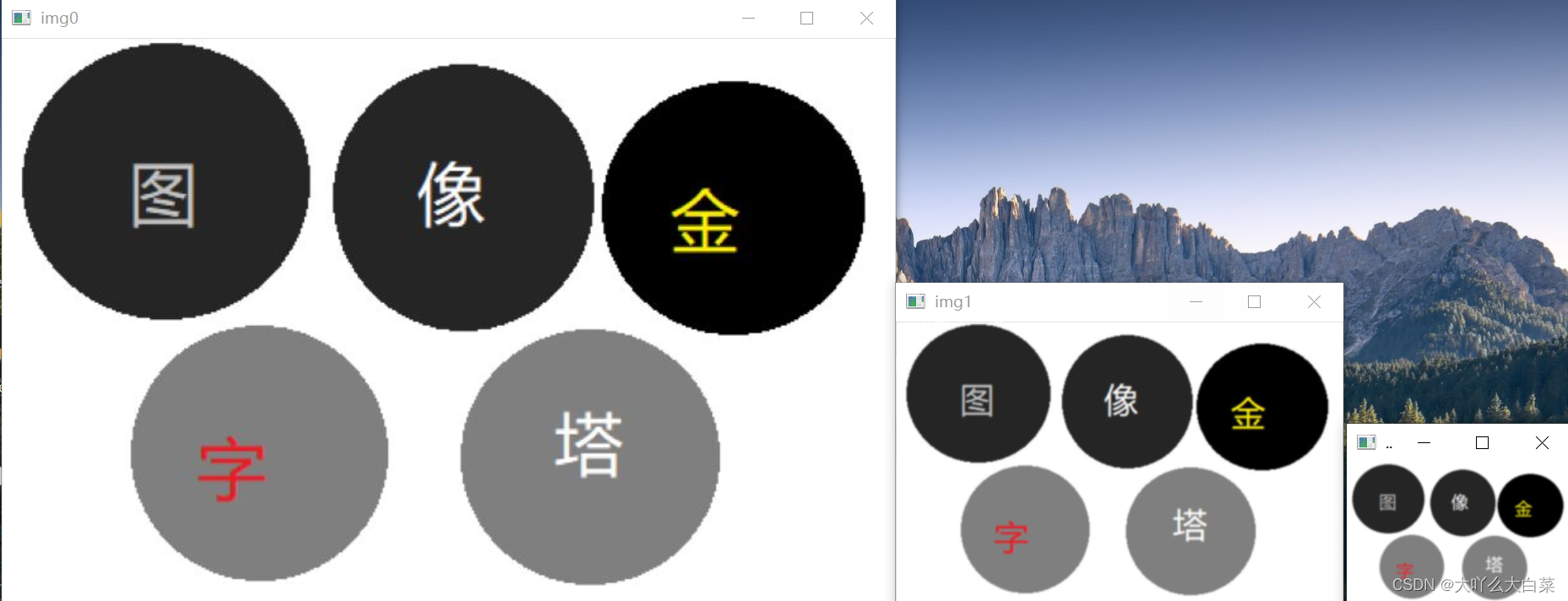
結果: 可見高和寬依次減為原來一半
0層形狀: (447, 706, 3)
1層形狀: (224, 353, 3)
2層形狀: (112, 177, 3)
三個圖片分別為原圖,第一次采樣,第二次采樣
高斯金字塔向上采樣
cv2.pyrUp() 函式基本格式如下
ret=cv2.pyrUp(image[,dstsize[,borderType]])
- ret 為回傳的結果影像,型別和輸入影像相同
- image為輸入影像
- dstsize為結果影像大小
- borderType為邊界值型別
import cv2
img0=cv2. imread('img/ee.jpg')
img1=cv2. pyrUp( img0) #第1次采樣
img2=cv2. pyrUp(img1) #第2次采樣
cv2. imshow( ' img0', img0) #顯示第0層
cv2. imshow( ' img1',img1) #顯示第1層
cv2. imshow( ' img2',img2) #顯示第2層
cv2. waitKey(0)
拉普拉斯金字塔
拉普拉斯金字塔的第n層是該層高斯金字塔影像減去第n+1層向上采樣結果獲得的影像
注意:N層的拉普拉斯金字塔,影像的寬度和高度就應該是2的N次方的整倍數
示例代碼:
import cv2
img0=cv2. imread('img/ff.jpg' )
img1=cv2. pyrDown(img0) #第1次采樣
img2=cv2. pyrDown(img1) #第2次采樣
img3=cv2. pyrDown(img2) #第3次采樣
imgL0= cv2. subtract(img0,cv2.pyrUp(img1)) #拉普拉斯金字塔第0層
imgL1= cv2. subtract(img1,cv2.pyrUp(img2)) #拉普拉斯金字塔第1層
imgL2= cv2. subtract(img2,cv2.pyrUp(img3)) #拉普拉斯金字塔第2層
cv2. imshow( ' imgL0',img0) #顯示第0層
cv2. imshow( ' imgL1',img1) #顯示第1層
cv2. imshow( ' imgL2',img2) #顯示第2層
cv2. waitKey(0)
互動式前景提取
互動式前景提取的基本原理如下,
首先,用一個矩形指定要提取的前景所在的大致范圍,然后執行前景提取演算法,得到初步結果,初步結果中包含的前景可能并不理想,存在前景未提取完整或者背景被處理為前景等問題,此時需要人工干預(體現互動),甩戶需要復制原影像作為掩模影像,在其中用白色標注要提取的前景區域,用黑色標注背景區域,標注并不需要很精確,然后,使用掩模影像執行前景提取演算法從而獲得理想的提取結果,
cv2.grabCut() 函式用于實作前景提取,基本格式如下:
mask2,bgdModel,fgdModel = cv2.frabCut(img,mask1,reck,bgdModel,fgdModel,iterCount[,mode])
引數說明如下
- mask1為輸入的8位單通道掩模影像,用于指定影像的哪些區域可能是背景或前景,
- mask2為輸出的掩模影像,其中的0表示確定的背景,1 表示確定的前景,2表示可能的背景,3表示可能的前景,
- bgdModel和fgdModel為用于內部計算的臨時陣列, 需定義為大小是1 x 65的np.float64型別的陣列,陣列元素值均為0,
- img為輸入的8位3通道影像,
- rect為矩形坐標,格式為“(左上角的橫坐標x,左上角的縱坐標y,寬度,高度)”,要提取的前景影像在矩形內部,將矩形的外部視為背景,mode引數設定為使用矩形模板時,rect 引數才有效,
- iterCount為迭代次數,
- mode為前景提取模式,可設定為下列值,
- cv2.GC_ INIT_ WITH_ RECT:使用矩形模板,
- cv2.GC_ INIT_ WITH_ MASK: 使用自定義模板,
- cv2.GC_ EVAL:使用修復模式,
- cv2.GC_ EVAL_ FREEZE_ _MODEL:使用固定模式,
import cv2
import numpy as np
img = cv2. imread( 'img/qwe.jpg' )
cv2. imshow( ' original',img)
mask = np. zeros(img. shape[:2],np.uint8)
#定義與原圖大小相同的掩模影像
bg = np.zeros((1, 65) ,np. float64)
fg = np.zeros((1,65),np. float64)
rect = (150,0,360,330)
#根據原圖設定包含前景的矩形大小
cv2. grabCut(img,mask, rect, bg, fg,5,cv2.GC_INIT_WITH_RECT) #提取前景
#將回傳的掩模影像中像素值為0或2的像素設定為0 (確認為背景)
#將所有像素值為1或3的像素設定為1 (確認為前景)
mask2 = np.where((mask==2)|(mask==0),0,1).astype( 'uint8')
img=img*mask2[:, :, np. newaxis] #將掩模影像與原影像相乘,獲得分割出來的前景影像
cv2. imshow( ' grabCut ',img) #顯示獲得的前景
cv2.waitKey(0)
原圖:

提取前景圖片:

此時圖片提取的前景并不完整,用黑色和白色的線標注背景和前景,代碼為:
import cv2
import numpy as np
img = cv2.imread('img/qwe.jpg')
mask = np.zeros(img. shape[:2],np.uint8) #定義原始掩模影像
bg = np.zeros((1,65),np. float64)
fg = np.zeros((1,65),np. float64)
rect = (130,0,360,330)
cv2. grabCut(img,mask,rect, bg,fg,5,cv2.GC_INIT_WITH_RECT) #第1次提取前景,矩形模式
imgmask = cv2. imread('img/qwee.jpg') #讀取已標注的掩模影像
cv2. imshow( ' mask image ',imgmask)
mask2 = cv2. cvtColor( imgmask, cv2. COLOR_BGR2GRAY, dstCn=1) #轉換為單通道灰度影像
mask[mask2==0]=0 #將掩模影像中黑色像素對應的原始掩模像素設定為0
mask[mask2==255]=1 #將掩模影像中白色像素對應的原始掩模像素設定為1
cv2. grabCut( img , mask, None,bg,fg,5,cv2.GC_INIT_WITH_MASK) #第2次提取前景,掩模模式
#將回傳的掩模影像中像素值為0或2的像素設定為0 (確認為背景)
#將所有像素值為1或3的像素設定為1 (確認為前景)
mask2 =np.where( (mask==2)|(mask==0),0,1).astype('uint8')
img =img*mask2[:,:,np.newaxis] #將掩模影像與原影像相乘獲得分割出來的前景影像
cv2. imshow( 'grabCut',img) #顯示獲得的前景
cv2. waitKey(0)
標注了背景和前景的掩膜影像:

干預后提取的前景圖片:·

轉載請註明出處,本文鏈接:https://www.uj5u.com/qita/423422.html
標籤:AI
上一篇:Jensen不等式