pandas.DataFrame.plot繪圖詳解
- 一、介紹
- 1.1 引數介紹
- 1.2 其他常用說明
- 二、舉例說明
- 2.1 折線圖 line
- 2.2 條型圖 bar
- 2.3 直方圖 hist
- 2.4 箱型圖 box
- 2.5 區域圖 area
- 2.6 散點圖 scatter
- 2.7 蜂巢圖 hexbin
- 2.8 餅型圖 pie
- 三、其他格式
- 3.1 設定顯示中文標題
- 3.2 設定坐標軸顯示負號
- 3.3 使用誤差線 yerr 進行繪圖
- 3.4 使用 layout 將目標分成多個子圖
- 3.5 使用 table 繪制表,上圖下表
- 3.6 使用 colormap 設定圖的區域顏色
一、介紹
使用pandas.DataFrame的plot方法繪制影像會按照資料的每一列繪制一條曲線,默認按照列columns的名稱在適當的位置展示圖例,比matplotlib繪制節省時間,且DataFrame格式的資料更規范,方便向量化及計算,
DataFrame.plot( )函式:
DataFrame.plot(x=None, y=None, kind='line', ax=None, subplots=False,
sharex=None, sharey=False, layout=None, figsize=None,
use_index=True, title=None, grid=None, legend=True,
style=None, logx=False, logy=False, loglog=False,
xticks=None, yticks=None, xlim=None, ylim=None, rot=None,
fontsize=None, colormap=None, position=0.5, table=False, yerr=None,
xerr=None, stacked=True/False, sort_columns=False,
secondary_y=False, mark_right=True, **kwds)
1.1 引數介紹
- x和y:表示標簽或者位置,用來指定顯示的索引,默認為None
- kind:表示繪圖的型別,默認為line,折線圖
- line:折線圖
- bar/barh:柱狀圖(條形圖),縱向/橫向
- pie:餅狀圖
- hist:直方圖(數值頻率分布)
- box:箱型圖
- kde:密度圖,主要對柱狀圖添加Kernel 概率密度線
- area:區域圖(面積圖)
- scatter:散點圖
- hexbin:蜂巢圖
- ax:子圖,可以理解成第二坐標軸,默認None
- subplots:是否對列分別作子圖,默認False
- sharex:共享x軸刻度、標簽,如果ax為None,則默認為True,如果傳入ax,則默認為False
- sharey:共享y軸刻度、標簽
- layout:子圖的行列布局,(rows, columns)
- figsize:圖形尺寸大小,(width, height)
- use_index:用索引做x軸,默認True
- title:圖形的標題
- grid:圖形是否有網格,默認None
- legend:子圖的圖例
- style:對每列折線圖設定線的型別,list or dict
- logx:設定x軸刻度是否取對數,默認False
- logy
- loglog:同時設定x,y軸刻度是否取對數,默認False
- xticks:設定x軸刻度值,序列形式(比如串列)
- yticks
- xlim:設定坐標軸的范圍,數值,串列或元組(區間范圍)
- ylim
- rot:軸標簽(軸刻度)的顯示旋轉度數,默認None
- fontsize : int, default None#設定軸刻度的字體大小
- colormap:設定圖的區域顏色
- colorbar:柱子顏色
- position:柱形圖的對齊方式,取值范圍[0,1],默認0.5(中間對齊)
- table:圖下添加表,默認False,若為True,則使用DataFrame中的資料繪制表格
- yerr:誤差線
- xerr
- stacked:是否堆積,在折線圖和柱狀圖中默認為False,在區域圖中默認為True
- sort_columns:對列名稱進行排序,默認為False
- secondary_y:設定第二個y軸(右輔助y軸),默認為False
- mark_right : 當使用secondary_y軸時,在圖例中自動用“(right)”標記列標簽 ,默認True
- x_compat:適配x軸刻度顯示,默認為False,設定True可優化時間刻度的顯示
1.2 其他常用說明
- color:顏色
- s:散點圖大小,int型別
- 設定x,y軸名稱
- ax.set_ylabel(‘yyy’)
- ax.set_xlabel(‘xxx’)
二、舉例說明
2.1 折線圖 line
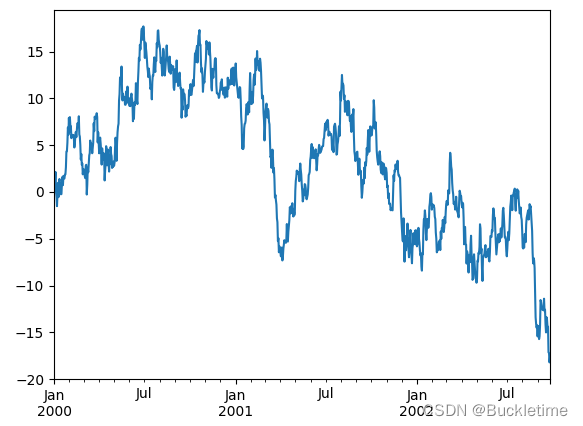
1. 基本用法
ts = pd.Series(np.random.randn(1000), index=pd.date_range("1/1/2000", periods=1000))
ts = ts.cumsum()
ts.plot();
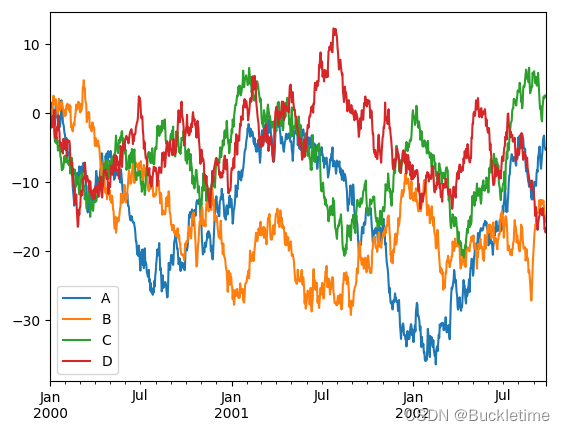
2. 展示多列資料
df = pd.DataFrame(np.random.randn(1000, 4), index=pd.date_range("1/1/2000", periods=1000), columns=list("ABCD"))
df = df.cumsum()
df.plot()
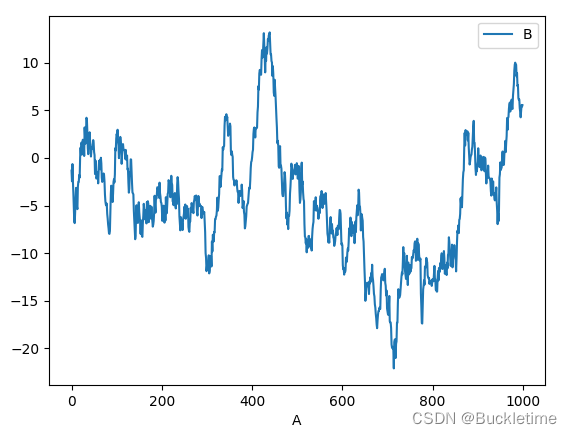
3. 使用x和y引數,繪制一列與另一列的對比
df3 = pd.DataFrame(np.random.randn(1000, 2), columns=["B", "C"]).cumsum()
df3["A"] = pd.Series(list(range(1000)))
df3.plot(x="A", y="B")
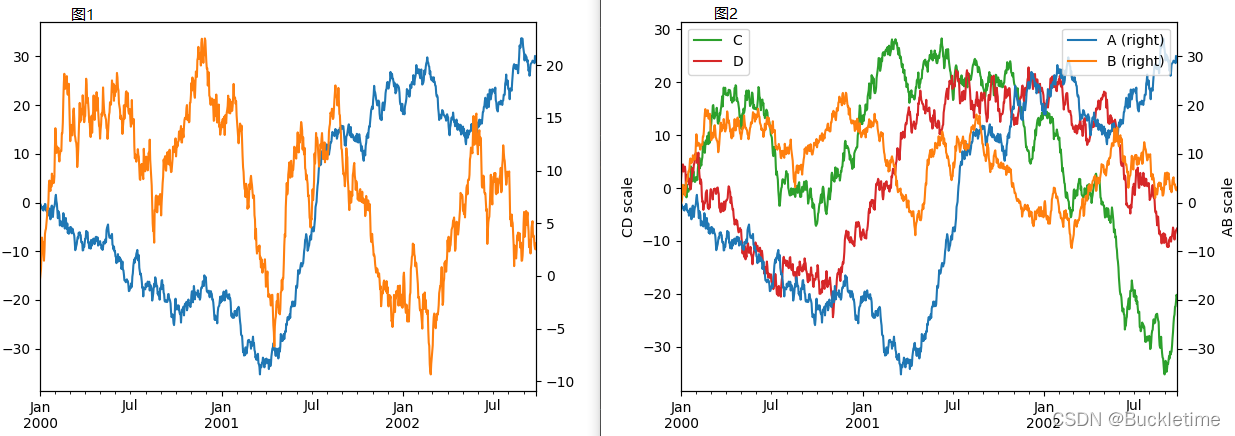
4. secondary_y引數,設定第二Y軸及圖例位置
ts = pd.Series(np.random.randn(1000), index=pd.date_range('1/1/2000', periods=1000))
df = pd.DataFrame(np.random.randn(1000, 4), index=ts.index, columns=list('ABCD'))
df = df.cumsum()
print(df)
# 圖1:其中A列用左Y軸標注,B列用右Y軸標注,二者共用一個X軸
df.A.plot() # 對A列作圖,同理可對行做圖
df.B.plot(secondary_y=True) # 設定第二個y軸(右y軸)
# 圖2
ax = df.plot(secondary_y=['A', 'B']) # 定義column A B使用右Y軸,
# ax(axes)可以理解為子圖,也可以理解成對黑板進行切分,每一個板塊就是一個axes
ax.set_ylabel('CD scale') # 主y軸標簽
ax.right_ax.set_ylabel('AB scale') # 第二y軸標簽
ax.legend(loc='upper left') # 設定圖例的位置
ax.right_ax.legend(loc='upper right') # 設定第二圖例的位置
5. x_compat引數,X軸為時間刻度的良好展示
ts = pd.Series(np.random.randn(1000), index=pd.date_range("1/1/2000", periods=1000))
ts = ts.cumsum()
ts.plot(x_compat=True)
6. color引數,設定多組圖形的顏色
df = pd.DataFrame(np.random.randn(1000, 4), index=pd.date_range('1/1/2000', periods=1000),
columns=list('ABCD')).cumsum()
df.A.plot(color='red')
df.B.plot(color='blue')
df.C.plot(color='yellow')
2.2 條型圖 bar
DataFrame.plot.bar() 或者 DataFrame.plot(kind=‘bar’)
1. 基本用法
df2 = pd.DataFrame(np.random.rand(10, 4), columns=["a", "b", "c", "d"])
df2.plot.bar()
2. 引數stacked=True,生成堆積條形圖
df2.plot.bar(stacked=True)
3. 使用barh,生成水平條形圖
df2.plot.barh()
4. 使用rot引數,設定軸刻度的顯示旋轉度數
df2.plot.bar(rot=0) # 0表示水平顯示
2.3 直方圖 hist
1. 基本使用
df3 = pd.DataFrame(
{
"a": np.random.randn(1000) + 1,
"b": np.random.randn(1000),
"c": np.random.randn(1000) - 1,
},
columns=["a", "b", "c"],
)
# alpha設定透明度
df3.plot.hist(alpha=0.5)
# 設定坐標軸顯示負號
plt.rcParams['axes.unicode_minus']=False
2. 直方圖可以使用堆疊,stacked=True,可以使用引數 bins 更改素材箱大小
df3.plot.hist(alpha=0.5,stacked=True, bins=20)
3. 可以使用引數 by 指定關鍵字來繪制分組直方圖
data = pd.Series(np.random.randn(1000))
data.hist(by=np.random.randint(0, 4, 1000), figsize=(6, 4))
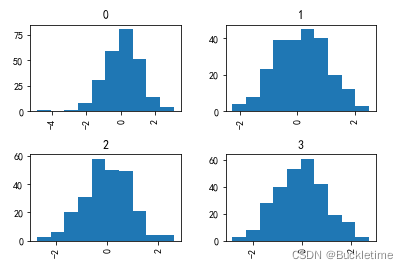
2.4 箱型圖 box
箱型圖,用來可視化每列中值的分布
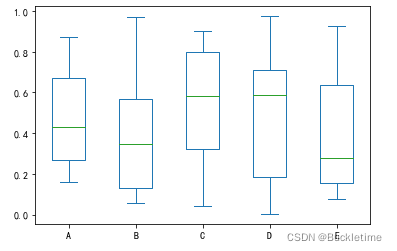
.1. 基本使用
示例:這里有一個箱形圖,代表對[0,1]上的均勻隨機變數的10個觀察結果進行的五次試驗,
df = pd.DataFrame(np.random.rand(10, 5), columns=["A", "B", "C", "D", "E"])
df.plot.box();
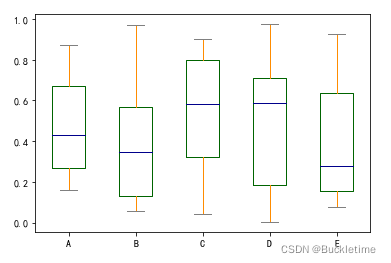
2. 箱型圖可以通過引數 color 進行著色
color是dict型別,包含的鍵分別是 boxes, whiskers, medians and caps
color = {
"boxes": "DarkGreen",
"whiskers": "DarkOrange",
"medians": "DarkBlue",
"caps": "Gray",
}
df.plot.box(color=color, sym="r+")
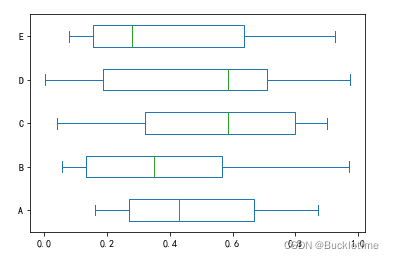
3. 可以使用引數 vert=False,指定水平方向顯示,默認為True表示垂直顯示
df.plot.box(vert=False)
4. 可以使用boxplot()方法,繪制帶有網格的箱型圖
df = pd.DataFrame(np.random.rand(10, 5))
bp = df.boxplot()
5. 可以使用引數 by 指定關鍵字來繪制分組箱型圖
df = pd.DataFrame(np.random.rand(10, 2), columns=["Col1", "Col2"])
df["X"] = pd.Series(["A", "A", "A", "A", "A", "B", "B", "B", "B", "B"])
bp = df.boxplot(by="X")
6. 可以使用多個列進行分組
df = pd.DataFrame(np.random.rand(10, 3), columns=["Col1", "Col2", "Col3"])
df["X"] = pd.Series(["A", "A", "A", "A", "A", "B", "B", "B", "B", "B"])
df["Y"] = pd.Series(["A", "B", "A", "B", "A", "B", "A", "B", "A", "B"])
bp = df.boxplot(column=["Col1", "Col2"], by=["X", "Y"])
2.5 區域圖 area
默認情況下,區域圖為堆疊,要生成區域圖,每列必須全部為正值或全部為負值,
1. 基本使用
df = pd.DataFrame(np.random.rand(10, 4), columns=["a", "b", "c", "d"])
df.plot.area()
2.6 散點圖 scatter
散點圖需要x和y軸的數字列, 這些可以由x和y關鍵字指定,
1. 基本使用
df = pd.DataFrame(np.random.rand(50, 4), columns=["a", "b", "c", "d"])
df["species"] = pd.Categorical(
["setosa"] * 20 + ["versicolor"] * 20 + ["virginica"] * 10
)
df.plot.scatter(x="a", y="b")
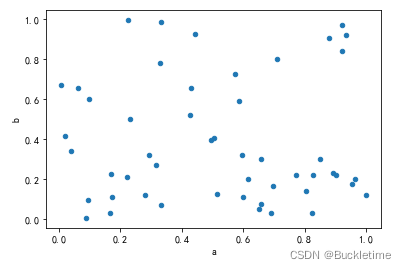
2. 可以使用 引數 ax 和 label 設定多組資料
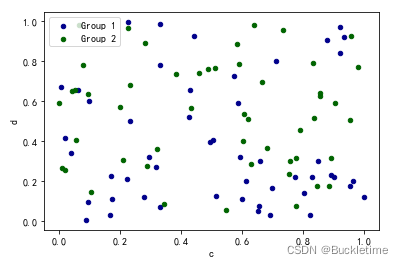
ax = df.plot.scatter(x="a", y="b", color="DarkBlue", label="Group 1")
df.plot.scatter(x="c", y="d", color="DarkGreen", label="Group 2", ax=ax)
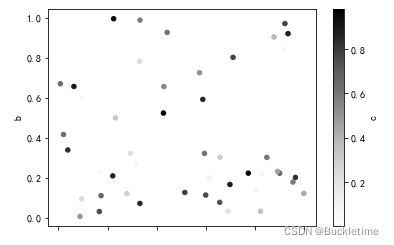
3. 使用引數 c 可以作為列的名稱來為每個點提供顏色,引數s可以指定散點大小
df.plot.scatter(x="a", y="b", c="c", s=50)
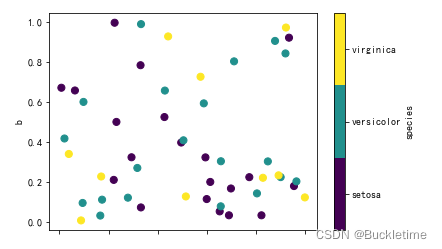
4. 如果將一個分類列傳遞給c,那么將產生一個離散的顏色條
df.plot.scatter(x="a", y="b", c="species", cmap="viridis", s=50)
5. 可以使用DataFrame的一列值作為散點的大小
df.plot.scatter(x="a", y="b", s=df["c"] * 200)
2.7 蜂巢圖 hexbin
如果資料過于密集而無法單獨繪制每個點,則 蜂巢圖可能是散點圖的有用替代方法,
df = pd.DataFrame(np.random.randn(1000, 2), columns=["a", "b"])
df["b"] = df["b"] + np.arange(1000)
df.plot.hexbin(x="a", y="b", gridsize=25)
2.8 餅型圖 pie
如果您的資料包含任何NaN,則它們將自動填充為0, 如果資料中有任何負數,則會引發ValueError
1. 基本使用
series = pd.Series(3 * np.random.rand(4), index=["a", "b", "c", "d"], name="series")
series.plot.pie(figsize=(6, 6))
2. 如果指定subplot =True,則將每個列的餅圖繪制為子圖, 默認情況下,每個餅圖中都會繪制一個圖例; 指定legend=False隱藏它,
df = pd.DataFrame(
3 * np.random.rand(4, 2), index=["a", "b", "c", "d"], columns=["x", "y"]
)
df.plot.pie(subplots=True, figsize=(8, 4))
3. autopct 顯示所占總數的百分比
series.plot.pie(
labels=["AA", "BB", "CC", "DD"],
colors=["r", "g", "b", "c"],
autopct="%.2f",
fontsize=20,
figsize=(6, 6),
)

三、其他格式
3.1 設定顯示中文標題
df = pd.DataFrame(np.random.rand(5, 3), columns=["a", "b", "c"])
df.plot.bar(title='中文標題測驗',rot=0)
# 默認不支持中文 ---修改RC引數,指定字體
plt.rcParams['font.sans-serif'] = 'SimHei'
3.2 設定坐標軸顯示負號
df3 = pd.DataFrame(
{
"a": np.random.randn(1000) + 1,
"b": np.random.randn(1000),
"c": np.random.randn(1000) - 1,
},
columns=["a", "b", "c"],
)
df3.plot.hist(alpha=0.5)
# 設定坐標軸顯示負號
plt.rcParams['axes.unicode_minus']=False
3.3 使用誤差線 yerr 進行繪圖
示例1:使用與原始資料的標準偏繪制組均值
ix3 = pd.MultiIndex.from_arrays([['a', 'a', 'a', 'a', 'b', 'b', 'b', 'b'], ['foo', 'foo', 'bar', 'bar', 'foo', 'foo', 'bar', 'bar']], names=['letter', 'word'])
df3 = pd.DataFrame({'data1': [3, 2, 4, 3, 2, 4, 3, 2], 'data2': [6, 5, 7, 5, 4, 5, 6, 5]}, index=ix3)
# 分組
gp3 = df3.groupby(level=('letter', 'word'))
means = gp3.mean()
errors = gp3.std()
means.plot.bar(yerr=errors,rot=0)
示例2:使用非對稱誤差線繪制最小/最大范圍
mins = gp3.min()
maxs = gp3.max()
errors = [[means[c] - mins[c], maxs[c] - means[c]] for c in df3.columns]
means.plot.bar(yerr=errors,capsize=4, rot=0)
3.4 使用 layout 將目標分成多個子圖
df = pd.DataFrame(np.random.randn(1000, 4), index=pd.date_range("1/1/2000", periods=1000), columns=list("ABCD"))
df = df.cumsum()
df.plot(subplots=True, layout=(2, 3), figsize=(6, 6), sharex=False)
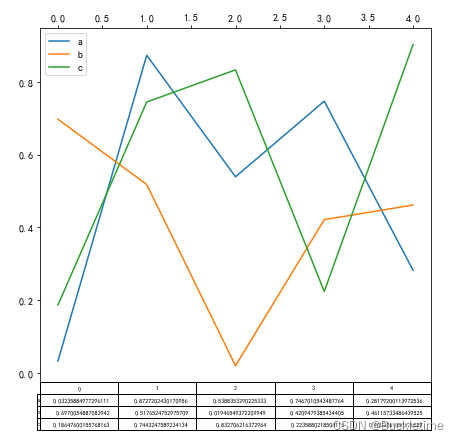
3.5 使用 table 繪制表,上圖下表
使用 table=True,繪制表格,圖下添加表
fig, ax = plt.subplots(1, 1, figsize=(7, 6.5))
df = pd.DataFrame(np.random.rand(5, 3), columns=["a", "b", "c"])
ax.xaxis.tick_top() # 在上方展示x軸
df.plot(table=True, ax=ax)
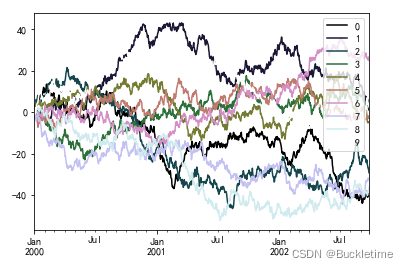
3.6 使用 colormap 設定圖的區域顏色
在繪制大量列時,一個潛在的問題是,由于默認顏色的重復,很難區分某些序列, 為了解決這個問題,DataFrame繪圖支持使用colormap引數,該引數接受Matplotlib的colormap或一個字串,該字串是在Matplotlib中注冊的一個colormap的名稱, 在這里可以看到默認matplotlib顏色映射的可視化,
df = pd.DataFrame(np.random.randn(1000, 10), index=pd.date_range("1/1/2000", periods=1000))
df = df.cumsum()
df.plot(colormap="cubehelix")
參考文章:https://blog.csdn.net/h_hxx/article/details/90635650
轉載請註明出處,本文鏈接:https://www.uj5u.com/qita/423426.html
標籤:AI
上一篇:《全網最強》詳解機器學習分類演算法之決策樹(附可視化和代碼)
下一篇:python使用OpenCV加載影像為RGB圖并可視化加載的影像(Convert to RGB and show image)