PyTorch多卡分布式訓練DistributedDataParallel 使用方法
目錄
PyTorch多卡分布式訓練DistributedDataParallel 使用方法
1.DP模式和DP模式
(1)單行程多GPU訓練模式:DP模式
(2)多行程多GPU訓練模式:DDP模式
2.Pytorch分布式訓練方法
3.Pytorch-Base-Trainer(PBT)分布式訓練工具
(1) 工具介紹
(2) 安裝
(3)使用方法
4.Example: 構建自己的分類Pipeline
5.可視化
【尊重原則,轉載請注明出處】:https://panjinquan.blog.csdn.net/article/details/122702287
1.DP模式和DP模式
Pytorch多卡訓練有兩種方式,一種是單行程多GPU訓練模式(single process multi-gpus),另一種的多行程多卡模式(multi-processes multi-gpus)
(1)單行程多GPU訓練模式:DP模式
Pytorch通過nn.DataParallel可實作多卡訓練模型(簡稱DP模式),這是single process multi-gpus 的多卡并行機制,這種并行模式下并行的多卡都是由一個行程進行控制,其缺點有:
- 盡管 DataLoader 可以指定 num_worker,增加負責加載資料的執行緒數量,但是執行緒的資源受限于父行程,且由于python的GIL機制,不能利用好多核的并行優勢
- 模型在 gpu 群組中進行初始化與廣播程序依賴單一行程的串行操作
- DP模式相當于將多個GPU卡合并為一個卡進行訓練
盡管DataParallel更易于使用(只需簡單包裝單GPU模型),但由于使用一個行程來計算模型權重,然后在每個批處理期間將分發到每個GPU,因此通信很快成為一個瓶頸,GPU利用率通常很低,而且,nn.DataParallel要求所有的GPU都在同一個節點上(不支持分布式),
(2)多行程多GPU訓練模式:DDP模式
Pytorch通過nn.parallel.DistributedDataParallel可實作多行程多卡訓練模型(也稱DDP模式),這種多卡并行機制的特點/優勢有:
- 一個行程一個GPU(當然可以讓每個行程控制多個GPU,但這顯然比每個行程有一個GPU要慢)
- 充分利用多核并行的優勢加載資料
- 模型在 gpu 群組中進行初始化的程序由各自的行程負責調度
- 代碼可以無縫切換單機多卡與多機多卡訓練,因為此時單機單卡成為了單機多卡/多機多卡并行下的一個特例
- GPU可以都在同一個節點上,也可以分布在多個節點上,每個行程都執行相同的任務,并且每個行程都與所有其他行程通信,行程或者說GPU之間只傳遞梯度,這樣網路通信就不再是瓶頸,
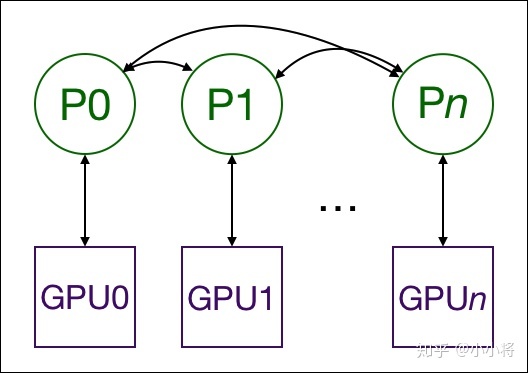
在訓練程序中,每個行程從磁盤加載batch資料,并將它們傳遞到其GPU,每一個GPU都有自己的前向程序,然后梯度在各個GPUs間進行All-Reduce,每一層的梯度不依賴于前一層,所以梯度的All-Reduce和后向程序同時計算,以進一步緩解網路瓶頸,在后向程序的最后,每個節點都得到了平均梯度,這樣模型引數保持同步,
這就要求多個行程,甚至多個節點上的多個行程實作同步并通信,Pytorch通過distributed.init_process_group函式來實作這一點,他需要知道行程0位置以便所有行程都可以同步,以及預期的行程總數,每個行程都需要知道行程總數及其在行程中的順序,以及使用哪個GPU,通常將行程總數稱為world_size,
Pytorch提供了nn.utils.data.DistributedSampler來為各個行程切分資料,以保證訓練資料不重疊,
nn.DataParallel和nn.distributedataparallel的主要差異可以總結為以下幾點:
DistributedDataParallel支持模型并行,而DataParallel并不支持,這意味如果模型太大單卡顯存不足時只能使用前者;DataParallel是單行程多執行緒的,只用于單機情況,而DistributedDataParallel是多行程的,適用于單機和多機情況,真正實作分布式訓練;DistributedDataParallel的訓練更高效,因為每個行程都是獨立的Python解釋器,避免GIL問題,而且通信成本低其訓練速度更快,基本上DataParallel已經被棄用;- 必須要說明的是
DistributedDataParallel中每個行程都有獨立的優化器,執行自己的更新程序,但是梯度通過通信傳遞到每個行程,所有執行的內容是相同的;
除了PyTorch官方實作的分布式訓練方案,還有horovod分布式訓練工具,不僅支持PyTorch還支持TensorFlow和MXNet框架,實作起來也是比較容易的,速度方面應該不相上下,
參考資料:PyTorch分布式訓練簡明教程 - 知乎
2.Pytorch分布式訓練方法
分布式訓練一般分為資料并行和模型并行兩種,Pytorch分布式訓練的實作步驟可簡述如下:
- 首先在nn.DataParallel(即DP模式下)實作多卡加載資料,訓練模型并除錯成功;這一步是為了保證你的訓練流程正常無BUG,然后就可以開始魔改了
- 資料并行(分布式):
DataLoader的樣本采樣器(sampler)修改為分布式采樣器torch_utils.distributed.DistributedSampler - 模型并行(分布式):將torch.nn.parallel.DistributedDataParallel 代替torch.nn.DataParallel
- 為了能夠使用 DistributedDataParallel 需要先進行行程間通訊環境的初始化,torch.distributed.init_process_group()
- 為了解決并行訓練中加載到各個 worker/gpu 中的 sub-mini-batch 之間出現 example overlap 問題,還可以配合 torch.utils.data.distributed.DistributedSampler 進行使用
- 為了讓行程與 gpu 進行一一匹配,在程式的開頭通過 torch.cuda.set_device 設定目標設備
- (可選)為了讓各個 worker/gpu 能有一致的初始值,在程式開頭通過 torch.manual_seed 與 torch.cuda.manual_seed 來初始化亂數種子
所以代碼結構如下:
# filename: distributed_example.py
# import some module
...
...
parser = argparse.Argument()
parser.add_argument('--init_method', defalut='env://', type=str)
parser.add_argument('--local_rank', type=int, default=0)
args = parser.parse()
import os
# Set master information and NIC
# NIC for communication
os.environ['NCCL_SOCKET_IFNAME'] = 'xxxx'
# set master node address
# recommend setting to ib NIC to gain bigger communication bandwidth
os.environ['MASTER_ADDR'] = '192.168.xx.xx'
# set master node port
# **caution**: avoid port conflict
os.environ['MASTER_PORT'] = '1234'
def main():
# step 1
# set random seed
torch.manual_seed(seed)
torch.cuda.manual_seed(seed)
# step 2
# set target device
torch.cuda.set_device(args.local_rank)
# step 3
# initialize process group
# use nccl backend to speedup gpu communication
torch.distributed.init_process_group(backend='nccl', init_method=args.init_method)
...
...
# step 4
# set distributed sampler
# the same, you can set distributed sampler for validation set
train_sampler = torch.utils.data.distributed.DistributedSampler(
dataset_train)
train_loader = torch.utils.data.DataLoader(
dataset_train, batch_size=BATCH_SIZE, sampler=train_sampler, pin_memory=PIN_MEMORY,
num_workers=NUM_WORKERS
)
...
...
# step 5
# initialize model
model = resnet50()
model.cuda()
# step 6
# wrap model with distributeddataparallel
# map device with model process, and we bind process n with gpu n(n=0,1,2,3...) by default.
model = torch.nn.parallel.DistributedDataParallel(model, device_ids=[args.local_rank], output_device=args.local_rank)
...
...
for epoch in range(epochs):
# step 7
# update sampler with epoch
train_sampler.set_epoch(epoch)
# then do whatever you want to do, just like a single device/gpu training program
...
...注意:
由于程式開頭采用了 torch.cuda.set_device() 指定了目標的設備,所以后續的操作中如果有涉及要將資料、模型移動到 gpu 中的操作需要改為 model.cuda()、inputs.cuda(),該指令會將物件正確地復制到對應的 cuda 設備中,
如果你執意使用 to 操作,那么注意確保 xx.to('cuda:n') 中的 cuda:n 與目標設備是匹配的,
以多行程方式啟動訓練腳本
你當然可以以 python distributed_example.py 這樣的形式啟動訓練腳本,不過這樣無法觸發多行程,pytorch 為多行程啟動腳本提供了 launch 工具,所以正確的啟動方式是:
python -m torch.distributed.launch --nnodes=<nodes> --nproc_per_node=<process per node> --node_rank=<rank of current node>\
distributed_example.py --arg1 --arg2 and all other arguments of your trainning script引數說明:
- nnodes:指定參與計算的節點數量,默認值為1,單機多卡的訓練中可以不用指定
- nproc_per_node:指定每個節點中的所要啟動的行程數量,由于行程與 gpu 一一對應,所以這里的數值不能大于系統中所能使用的 gpu 數量
- node_rank: 指定當前節點在整個系統中的序號,從 0 開始遞增,需要注意的是,在多機多卡訓練中 node_rank == 0 的節點表示 master,所以 node_rank == 0 的節點必須是 MASTER_ADDR 所在的節點,否則多卡間的通信無法正確建立連接,
老實說,【從DP模式升級到DDP的方法】看起來簡單,步驟也不多,但真正要跑起來還是很多地方需要優化的;
這種多行程訓練的方法,每個行程需要分配一個卡進行訓練,這就導致你保存模型,列印Log,測驗資料都變成復雜了,比如會出現多個行程都會列印相同的Log的問題;一般建議你,定義一個主行程,且在主行程中列印Log,保存模型,測驗資料等操作,這樣可以避免上述問題了,
那有沒有一個簡單方法,可以快速實作Pytorch的分布式訓練
有的,我今天就介紹一個我自己整合的Pytorch的分布式訓練工具:Pytorch-Base-Trainer,基于這套工具,你可以簡單配置,即可實作DP或者DDP模式的訓練,而無需關注各種行程間通訊,埠設定等這些復雜的程序,
3.Pytorch-Base-Trainer(PBT)分布式訓練工具
(1) 工具介紹
考慮到深度學習訓練程序都有一套約定成俗的流程,鄙人借鑒Keras開發了一套基礎訓練庫: Pytorch-Base-Trainer(PBT); 這是一個基于Pytorch開發的基礎訓練庫,支持以下特征:
- 支持多卡訓練訓練(DP模式)和分布式多卡訓練(DDP模式),參考build_model_parallel
- 支持argparse命令列指定引數,也支持config.yaml組態檔
- 支持最優模型保存ModelCheckpoint
- 支持自定義回呼函式Callback
- 支持NNI模型剪枝(L1/L2-Pruner,FPGM-Pruner Slim-Pruner)nni_pruning
- 非常輕便,安裝簡單
博客介紹:
Pytorch基礎訓練庫Pytorch-Base-Trainer(支持模型剪枝 分布式訓練)_pan_jinquan的博客-CSDN博客考慮到深度學習訓練程序都有一套約定成俗的流程,鄙人借鑒Keras開發了一套基礎訓練庫: Pytorch-Base-Trainer(PBT); 這是一個基于Pytorch開發的基礎訓練庫,支持以下特征:https://panjinquan.blog.csdn.net/article/details/122662902GitHub地址:
GitHub - PanJinquan/Pytorch-Base-Trainer: Pytorch分布式訓練框架![]() https://github.com/PanJinquan/Pytorch-Base-Trainer
https://github.com/PanJinquan/Pytorch-Base-Trainer
(2) 安裝
- 原始碼安裝
git clone https://github.com/PanJinquan/Pytorch-Base-Trainer
cd Pytorch-Base-Trainer
bash setup.sh #pip install dist/basetrainer-*.*.*.tar.gz- pip安裝
pip install basetrainer- 使用NNI 模型剪枝工具,需要安裝NNI
# Linux or macOS
python3 -m pip install --upgrade nni
# Windows
python -m pip install --upgrade nni(3)使用方法
basetrainer使用方法可以參考example.py,構建自己的訓練器,可通過如下步驟實作:
- step1: 新建一個類
ClassificationTrainer,繼承trainer.EngineTrainer - step2: 實作介面
def build_train_loader(self, cfg, **kwargs):
"""定義訓練資料"""
raise NotImplementedError("build_train_loader not implemented!")
def build_test_loader(self, cfg, **kwargs):
"""定義測驗資料"""
raise NotImplementedError("build_test_loader not implemented!")
def build_model(self, cfg, **kwargs):
"""定于訓練模型"""
raise NotImplementedError("build_model not implemented!")
def build_optimizer(self, cfg, **kwargs):
"""定義優化器"""
raise NotImplementedError("build_optimizer not implemented!")
def build_criterion(self, cfg, **kwargs):
"""定義損失函式"""
raise NotImplementedError("build_criterion not implemented!")
def build_callbacks(self, cfg, **kwargs):
"""定義回呼函式"""
raise NotImplementedError("build_callbacks not implemented!")
step3: 在初始化中呼叫build
def __init__(self, cfg):
super(ClassificationTrainer, self).__init__(cfg)
...
self.build(cfg)
...
step4: 實體化ClassificationTrainer,并使用launch啟動分布式訓練
def main(cfg):
t = ClassificationTrainer(cfg)
return t.run()
if __name__ == "__main__":
parser = get_parser()
args = parser.parse_args()
cfg = setup_config.parser_config(args)
launch(main,
num_gpus_per_machine=len(cfg.gpu_id),
dist_url="tcp://127.0.0.1:28661",
num_machines=1,
machine_rank=0,
distributed=cfg.distributed,
args=(cfg,))4.Example: 構建自己的分類Pipeline
basetrainer使用方法可以參考example.py
# 單行程多卡訓練
python example.py --gpu_id 0 1 # 使用命令列引數
python example.py --config_file configs/config.yaml # 使用yaml組態檔
# 多行程多卡訓練(分布式訓練)
python example.py --config_file configs/config.yaml --distributed # 使用yaml組態檔
- 目標支持的backbone有:resnet[18,34,50,101], ,mobilenet_v2等,詳見backbone等 ,其他backbone可以自定義添加
- 訓練引數可以通過兩種方法指定: (1) 通過argparse命令列指定 (2)通過config.yaml組態檔,當存在同名引數時,以組態檔為默認值
| 引數 | 型別 | 參考值 | 說明 |
|---|---|---|---|
| train_data | str, list | - | 訓練資料檔案,可支持多個檔案 |
| test_data | str, list | - | 測驗資料檔案,可支持多個檔案 |
| work_dir | str | work_space | 訓練輸出作業空間 |
| net_type | str | resnet18 | backbone型別,{resnet,resnest,mobilenet_v2,...} |
| input_size | list | [128,128] | 模型輸入大小[W,H] |
| batch_size | int | 32 | batch size |
| lr | float | 0.1 | 初始學習率大小 |
| optim_type | str | SGD | 優化器,{SGD,Adam} |
| loss_type | str | CELoss | 損失函式 |
| scheduler | str | multi-step | 學習率調整策略,{multi-step,cosine} |
| milestones | list | [30,80,100] | 降低學習率的節點,僅僅scheduler=multi-step有效 |
| momentum | float | 0.9 | SGD動量因子 |
| num_epochs | int | 120 | 回圈訓練的次數 |
| num_warn_up | int | 3 | warn_up的次數 |
| num_workers | int | 12 | DataLoader開啟執行緒數 |
| weight_decay | float | 5e-4 | 權重衰減系數 |
| gpu_id | list | [ 0 ] | 指定訓練的GPU卡號,可指定多個 |
| log_freq | in | 20 | 顯示LOG資訊的頻率 |
| finetune | str | model.pth | finetune的模型 |
| use_prune | bool | True | 是否進行模型剪枝 |
| progress | bool | True | 是否顯示進度條 |
| distributed | bool | False | 是否使用分布式訓練 |
一個簡單分類例子如下:
# -*-coding: utf-8 -*-
"""
@Author : panjq
@E-mail : pan_jinquan@163.com
@Date : 2021-07-28 22:09:32
"""
import os
import sys
sys.path.append(os.getcwd())
import argparse
import basetrainer
from torchvision import transforms
from torchvision.datasets import ImageFolder
from basetrainer.engine import trainer
from basetrainer.engine.launch import launch
from basetrainer.criterion.criterion import get_criterion
from basetrainer.metric import accuracy_recorder
from basetrainer.callbacks import log_history, model_checkpoint, losses_recorder, multi_losses_recorder
from basetrainer.scheduler import build_scheduler
from basetrainer.optimizer.build_optimizer import get_optimizer
from basetrainer.utils import log, file_utils, setup_config, torch_tools
from basetrainer.models import build_models
print(basetrainer.__version__)
class ClassificationTrainer(trainer.EngineTrainer):
""" Training Pipeline """
def __init__(self, cfg):
super(ClassificationTrainer, self).__init__(cfg)
torch_tools.set_env_random_seed()
cfg.model_root = os.path.join(cfg.work_dir, "model")
cfg.log_root = os.path.join(cfg.work_dir, "log")
if self.is_main_process:
file_utils.create_dir(cfg.work_dir)
file_utils.create_dir(cfg.model_root)
file_utils.create_dir(cfg.log_root)
file_utils.copy_file_to_dir(cfg.config_file, cfg.work_dir)
setup_config.save_config(cfg, os.path.join(cfg.work_dir, "setup_config.yaml"))
self.logger = log.set_logger(level="debug",
logfile=os.path.join(cfg.log_root, "train.log"),
is_main_process=self.is_main_process)
# build project
self.build(cfg)
self.logger.info("=" * 60)
self.logger.info("work_dir :{}".format(cfg.work_dir))
self.logger.info("config_file :{}".format(cfg.config_file))
self.logger.info("gpu_id :{}".format(cfg.gpu_id))
self.logger.info("main device :{}".format(self.device))
self.logger.info("num_samples(train):{}".format(self.num_samples))
self.logger.info("num_classes :{}".format(cfg.num_classes))
self.logger.info("mean_num :{}".format(self.num_samples / cfg.num_classes))
self.logger.info("=" * 60)
def build_optimizer(self, cfg, **kwargs):
"""build_optimizer"""
self.logger.info("build_optimizer")
self.logger.info("optim_type:{},init_lr:{},weight_decay:{}".format(cfg.optim_type, cfg.lr, cfg.weight_decay))
optimizer = get_optimizer(self.model,
optim_type=cfg.optim_type,
lr=cfg.lr,
momentum=cfg.momentum,
weight_decay=cfg.weight_decay)
return optimizer
def build_criterion(self, cfg, **kwargs):
"""build_criterion"""
self.logger.info("build_criterion,loss_type:{},num_classes:{}".format(cfg.loss_type, cfg.num_classes))
criterion = get_criterion(cfg.loss_type, cfg.num_classes, device=self.device)
return criterion
def build_train_loader(self, cfg, **kwargs):
"""build_train_loader"""
self.logger.info("build_train_loader,input_size:{}".format(cfg.input_size))
transform = transforms.Compose([
transforms.Resize([int(128 * cfg.input_size[1] / 112), int(128 * cfg.input_size[0] / 112)]),
transforms.RandomHorizontalFlip(),
transforms.RandomCrop([cfg.input_size[1], cfg.input_size[0]]),
transforms.ToTensor(),
transforms.Normalize(mean=[0.5, 0.5, 0.5], std=[0.5, 0.5, 0.5]),
])
dataset = ImageFolder(root=cfg.train_data, transform=transform)
cfg.num_classes = len(dataset.classes)
cfg.classes = dataset.classes
loader = self.build_dataloader(dataset, cfg.batch_size, cfg.num_workers, phase="train",
shuffle=True, pin_memory=False, drop_last=True, distributed=cfg.distributed)
return loader
def build_test_loader(self, cfg, **kwargs):
"""build_test_loader"""
self.logger.info("build_test_loader,input_size:{}".format(cfg.input_size))
transform = transforms.Compose([
transforms.Resize([int(128 * cfg.input_size[1] / 112), int(128 * cfg.input_size[0] / 112)]),
transforms.CenterCrop([cfg.input_size[1], cfg.input_size[0]]),
transforms.ToTensor(),
transforms.Normalize(mean=[0.5, 0.5, 0.5], std=[0.5, 0.5, 0.5]),
])
dataset = ImageFolder(root=cfg.train_data, transform=transform)
loader = self.build_dataloader(dataset, cfg.batch_size, cfg.num_workers, phase="test",
shuffle=False, pin_memory=False, drop_last=False, distributed=False)
return loader
def build_model(self, cfg, **kwargs):
"""build_model"""
self.logger.info("build_model,net_type:{}".format(cfg.net_type))
model = build_models.get_models(net_type=cfg.net_type, input_size=cfg.input_size,
num_classes=cfg.num_classes, pretrained=True)
if cfg.finetune:
self.logger.info("finetune:{}".format(cfg.finetune))
state_dict = torch_tools.load_state_dict(cfg.finetune)
model.load_state_dict(state_dict)
if cfg.use_prune:
from basetrainer.pruning import nni_pruning
sparsity = 0.2
self.logger.info("use_prune:{},sparsity:{}".format(cfg.use_prune, sparsity))
model = nni_pruning.model_pruning(model,
input_size=[1, 3, cfg.input_size[1], cfg.input_size[0]],
sparsity=sparsity,
reuse=False,
output_prune=os.path.join(cfg.work_dir, "prune"))
model = self.build_model_parallel(model, cfg.gpu_id, distributed=cfg.distributed)
return model
def build_callbacks(self, cfg, **kwargs):
"""定義回呼函式"""
self.logger.info("build_callbacks")
# 準確率記錄回呼函式
acc_record = accuracy_recorder.AccuracyRecorder(target_names=cfg.classes,
indicator="Accuracy")
# loss記錄回呼函式
loss_record = losses_recorder.LossesRecorder(indicator="loss")
# Tensorboard Log等歷史記錄回呼函式
history = log_history.LogHistory(log_dir=cfg.log_root,
log_freq=cfg.log_freq,
logger=self.logger,
indicators=["loss", "Accuracy"],
is_main_process=self.is_main_process)
# 模型保存回呼函式
checkpointer = model_checkpoint.ModelCheckpoint(model=self.model,
optimizer=self.optimizer,
moder_dir=cfg.model_root,
epochs=cfg.num_epochs,
start_save=-1,
indicator="Accuracy",
logger=self.logger)
# 學習率調整策略回呼函式
lr_scheduler = build_scheduler.get_scheduler(cfg.scheduler,
optimizer=self.optimizer,
lr_init=cfg.lr,
num_epochs=cfg.num_epochs,
num_steps=self.num_steps,
milestones=cfg.milestones,
num_warn_up=cfg.num_warn_up)
callbacks = [acc_record,
loss_record,
lr_scheduler,
history,
checkpointer]
return callbacks
def run(self, logs: dict = {}):
self.logger.info("start train")
super().run(logs)
def main(cfg):
t = ClassificationTrainer(cfg)
return t.run()
def get_parser():
parser = argparse.ArgumentParser(description="Training Pipeline")
parser.add_argument("-c", "--config_file", help="configs file", default="configs/config.yaml", type=str)
# parser.add_argument("-c", "--config_file", help="configs file", default=None, type=str)
parser.add_argument("--train_data", help="train data", default="./data/dataset/train", type=str)
parser.add_argument("--test_data", help="test data", default="./data/dataset/val", type=str)
parser.add_argument("--work_dir", help="work_dir", default="output", type=str)
parser.add_argument("--input_size", help="input size", nargs="+", default=[224, 224], type=int)
parser.add_argument("--batch_size", help="batch_size", default=32, type=int)
parser.add_argument("--gpu_id", help="specify your GPU ids", nargs="+", default=[0], type=int)
parser.add_argument("--num_workers", help="num_workers", default=0, type=int)
parser.add_argument("--num_epochs", help="total epoch number", default=50, type=int)
parser.add_argument("--scheduler", help=" learning scheduler: multi-step,cosine", default="multi-step", type=str)
parser.add_argument("--milestones", help="epoch stages to decay learning rate", nargs="+",
default=[10, 20, 40], type=int)
parser.add_argument("--num_warn_up", help="num_warn_up", default=3, type=int)
parser.add_argument("--net_type", help="net_type", default="mobilenet_v2", type=str)
parser.add_argument("--finetune", help="finetune model file", default=None, type=str)
parser.add_argument("--loss_type", help="loss_type", default="CELoss", type=str)
parser.add_argument("--optim_type", help="optim_type", default="SGD", type=str)
parser.add_argument("--lr", help="learning rate", default=0.1, type=float)
parser.add_argument("--weight_decay", help="weight_decay", default=0.0005, type=float)
parser.add_argument("--momentum", help="momentum", default=0.9, type=float)
parser.add_argument("--log_freq", help="log_freq", default=10, type=int)
parser.add_argument('--use_prune', action='store_true', help='use prune', default=False)
parser.add_argument('--progress', action='store_true', help='display progress bar', default=True)
parser.add_argument('--distributed', action='store_true', help='use distributed training', default=False)
parser.add_argument('--polyaxon', action='store_true', help='polyaxon', default=False)
return parser
if __name__ == "__main__":
parser = get_parser()
cfg = setup_config.parser_config(parser.parse_args(), cfg_updata=True)
launch(main,
num_gpus_per_machine=len(cfg.gpu_id),
dist_url="tcp://127.0.0.1:28661",
num_machines=1,
machine_rank=0,
distributed=cfg.distributed,
args=(cfg,))
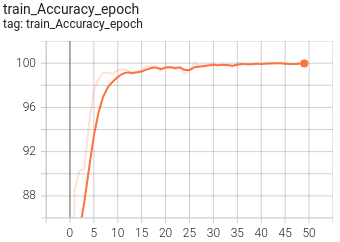
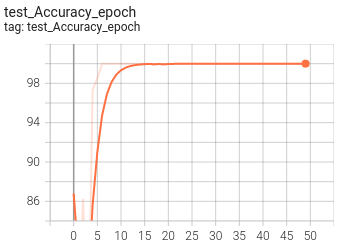
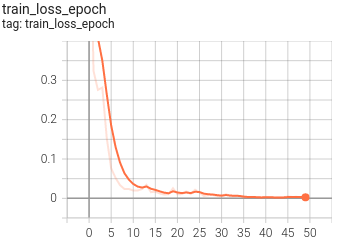
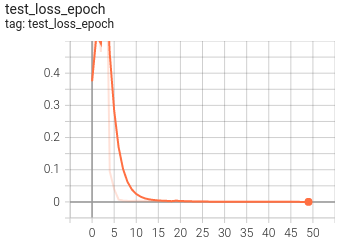
5.可視化
目前訓練程序可視化工具是使用Tensorboard,使用方法:
tensorboard --logdir=path/to/log/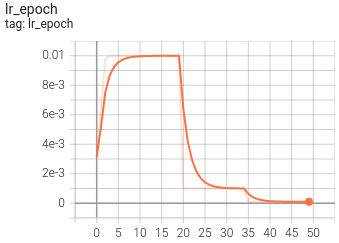 ? ? | 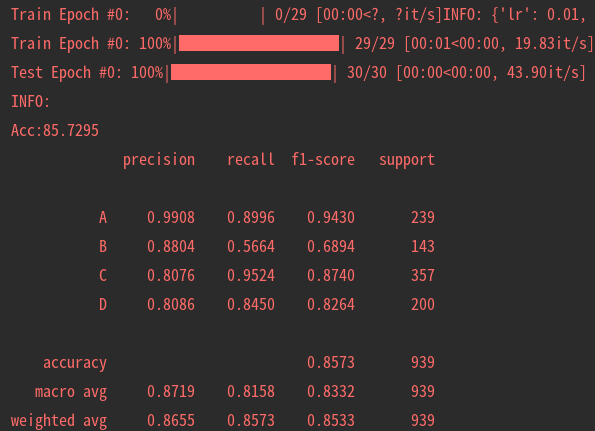 ? ? |
|---|---|
 ? ? |  ? ? |
 ? ? |  ? ? |
轉載請註明出處,本文鏈接:https://www.uj5u.com/qita/423486.html
標籤:AI
下一篇:智能車淺談——抗干擾技術軟體篇