前向傳播
首先我們需要先確定一個公式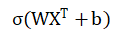
其中W是我們的權重,X是我們的輸入,b是偏置, σ是激活函式
就拿最簡單的兩層神經網路來舉例子,也就是由一個輸入層,一個隱藏層,和一個輸出層所組成的神經網路,在這個神經網路里,W也就是我們的隱藏層,X也就是輸入層
假設現在我們的輸入X是一個1xN的一維矩陣
假如我們需要實作0-9的手寫數字識別功能,那么我們最后的輸出就是0-9這十個數字的概率矩陣,也就是1x10的一個一維矩陣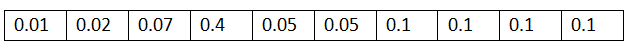
那么應該如何將一個1xN的矩陣變成1x10的矩陣呢,
我們可以用一個10xN的矩陣,也就是隱藏層的W與X的轉置矩陣做矩陣乘法,這樣得出來的就是一個10x1的矩陣了,把結果再轉置一下,就是我們所需要的最后結果了(實際情況中其實不需要再轉置一下),最后再加上一個10x1維的偏置矩陣,這個線性變化就完成了,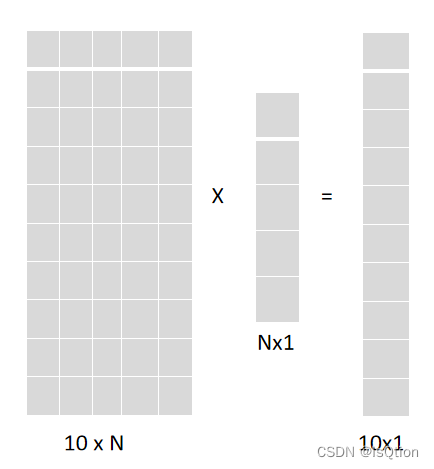
通常在線性變化之后,還會對輸出的結果進行一次激活函式的運算,常用的激活函式有很多,比如:Sigmoid,Tanh,Relu,LeakRelu 等等,
線性變化+激活函式就完成了隱藏層的輸出,最后,隱藏層的輸出結果再與輸出層的權重矩陣進行相同的操作,一個簡單的2層神經網路的前向傳播也就完成了
反向傳播
將網路最后的輸出結果,與我們的真值做運算就可以得到我們的這次訓練的損失是多少了,常用的損失計算的方法也有很多,比如:平方損失,絕對值損失,交叉熵損失等等,
得到了損失值,我們就知道了這次網路的輸出跟真實情況的差距有多大了,損失值越小代表我們的網路輸出的結果越準確,為了能夠實作這一目標,我們就需要根據損失,去更新每個隱藏層的權重矩陣和偏置矩陣,因為最后的輸出結果就是輸入的資料跟一層一層的隱藏層中的權重矩陣相運算所得到的,因此,隱藏層中的矩陣與最后輸出結果的準確性有直接關系
這里假設我們的整個網路中所用到的激活函式是sigmoid,損失函式使用的是平方損失,那么現在我們來梳理一下這整個2層神經網路前向傳播的程序,
首先,我們定義我們最開始的輸入是X,隱藏層的權重矩陣是W,偏置是A,輸出層的權重矩陣是V,偏置是B
那么整體的前向傳播的數學運算式就應該是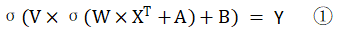
損失函式的運算式則是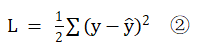
其中y代表真值,也就是真值矩陣T中的每一項;y尖代表網路的輸出,也就是①式Y矩陣中的每一項
而對于權重矩陣的更新用的則是梯度下降法,也就是利用鏈式求導法則,分別求出,L對W,V,A,B的導數,乘上學習率再加回原來的就完成了這次的更新,
首先讓我們畫張圖來梳理一下,也方便后面的求導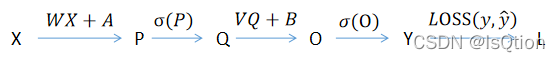
我們可一先不把這些X,W,P,Q什么的當成矩陣,因為如果是矩陣的話,在運算程序中還要把這些矩陣轉置過來轉置過去的,可以把他們當成一個實數,這樣對反向求導會更好理解一些,
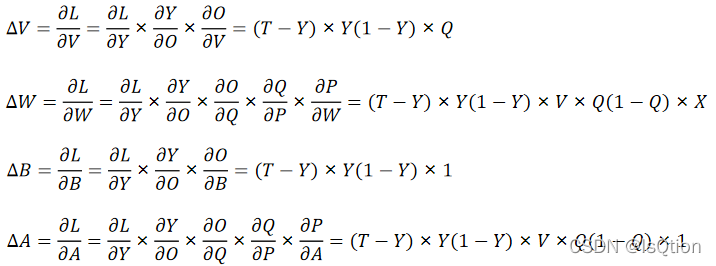
其中σ(x)是sigmoid函式,σ(x)的導數 = σ(x)·[1-σ(x)]
代碼實作
import numpy as np
class net:
def __init__(self,input_nodes,hidden_nodes,output_nodes,learning_rate):
self.input_nodes = input_nodes #輸入的節點數
self.hidden_nodes = hidden_nodes #隱藏層的節點數
self.output_nodes = output_nodes #輸出的節點數
self.learning_rate = learning_rate #學習率
self.activation_function = lambda x:1/(1+np.exp(-x)) #sigmoid激活函式
self.w = np.random.randn(hidden_nodes,input_nodes)*0.01 #隱藏層的權重矩陣
self.v = np.random.randn(output_nodes,hidden_nodes)*0.01 #輸出層的權重矩陣
self.b1 = np.array(np.zeros(hidden_nodes),ndmin=2).T #隱藏層的偏置
self.b2 = np.array(np.zeros(output_nodes),ndmin=2).T #輸出層的偏置
def train(self,inputs,targets):
inputs = np.asfarray(np.array(inputs,ndmin=2).T) #將輸入和真值矩陣轉置一下
targets = np.asfarray(np.array(targets,ndmin=2).T)
hidden_level_input = np.dot(self.w,inputs)+self.b1 #WX+A = P
hidden_level_output = self.activation_function(hidden_level_input) #σ(P) = Q
output_level_input = np.dot(self.v,hidden_level_output)+self.b2 #VQ+B = O
output_level_output = self.activation_function(output_level_input) #σ(O) = Y
loss = 1/2*(np.sum(np.square(targets-output_level_output))) #平方損失
# 計算梯度
G = (targets-output_level_output)*output_level_output*(1-output_level_output) #(T-Y)xY(1-Y) = G
E = hidden_level_output*(1-hidden_level_output)*np.dot(self.v.T,G) #GxVxQ(1-Q)
self.v+=self.learning_rate*np.dot(G,hidden_level_output.T)
self.w+=self.learning_rate*np.dot(E,inputs.T)
self.b1+=self.learning_rate*E
self.b2+=self.learning_rate*G
轉載請註明出處,本文鏈接:https://www.uj5u.com/qita/423490.html
標籤:AI
上一篇:智慧停車場-車牌識別自動計費系統