目錄
支持向量機演算法背景介紹
什么是線性可分?
什么又是超平面?
支持向量機的三種情況
近線性可分
線性不可分
不用核函式的傳統方法
核函式Kernel是什么?
核函式SVM求解程序
核函式的本質
代碼實體
模型調參
gamma調參
C值調參
使用Polynomial kernel進行預測
使用RBF kernel進行預測
總結
每文一語
支持向量機演算法背景介紹
1995年Cortes和Vapnik首先提出了支持向量機(Support Vector Machine),由于其能夠適應小樣本的分類,分類速度快等特點,性能不差于人工神經網路,所以在這之后,人們將SVM應用于各個領域,
大量使用SVM模型的論文不斷涌現,包括國內和國外支持向量機建立在堅實的統計學理論基礎上,是在所有知名的資料挖掘演算法中最健壯、最準確的方法之一,具有很好的學習能力和泛化能力,
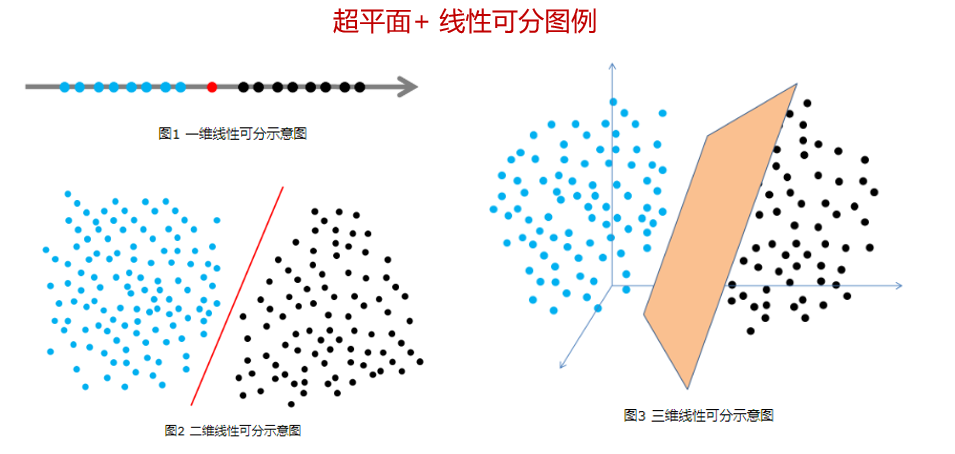
什么是線性可分?
簡單說,線性可分就是在多維空間中存在一個超平面(Hyper Plane),可以把樣例資料清楚地分成不同類別,二分類就是最典型的線性可分問題,
什么又是超平面?
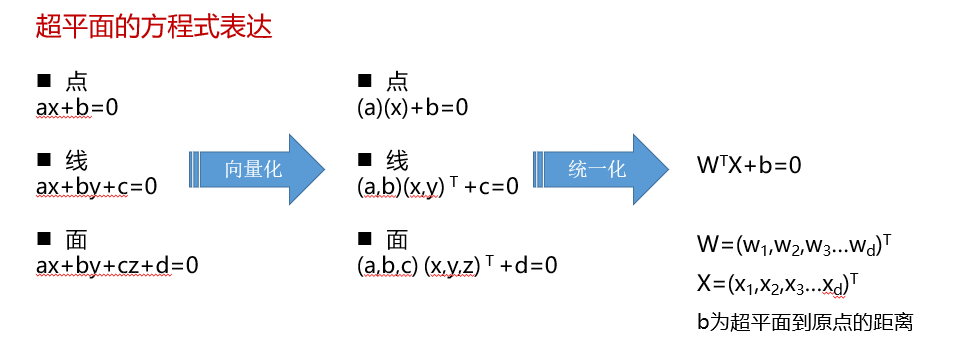
超平面H是從n維空間到n-1維空間的一個映射子空間,它有一個n維向量和一個實數定義,因為是子空間,所以超平面一定過原點,
利用這種方式,我們可以看到即使再多維的情況下,也可以生成一種超平面用來進行分類
怎么正確理解超平面?
超平面是個純數學概念,不是物理概念,它是直線中的點、平面中的直線、空間中的平面的推廣,只有當維度大于3,才能稱為“超”平面,
超平面的本質是自由度比空間維度小1,也即最后一個維度可以因其他維度確定而確定,
超平面的兩個性質:
1)方程是線性的: 是空間點的各分量的線性組合
2)方程數量為1
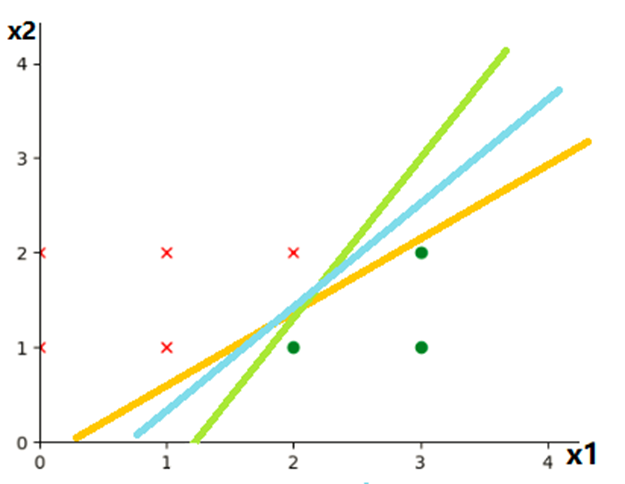
說到這里,可能還是比較的懵逼,到底什么是超平面,超平面又該如何選擇呢?我們可以看看下面的這個例子!
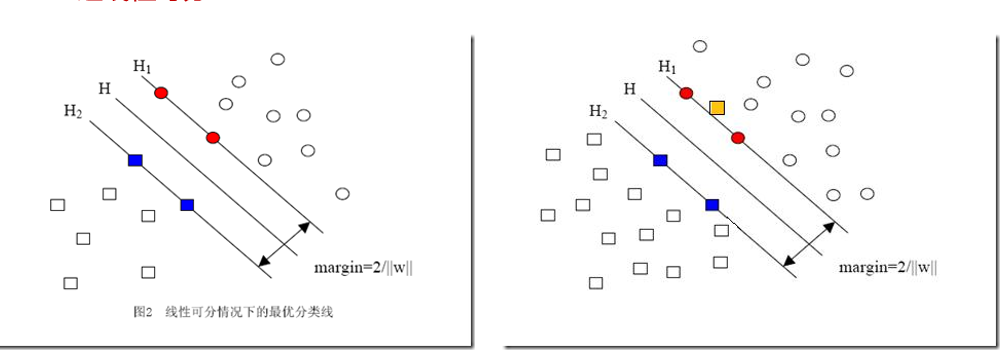
下面是一個二分類的問題,對于藍點和黑點資料,事實上存在很多條直線可以把他們正確地劃分開,那么究竟選擇哪一條直線最佳呢?
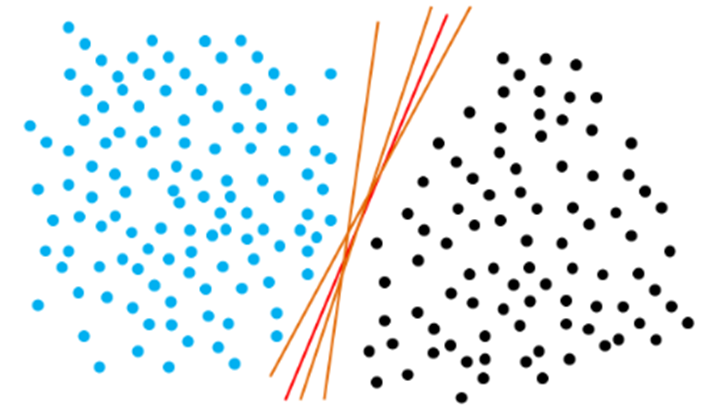
我們發現存在三條特別的超平面(直線),兩條紫色的線分別距離藍點和黑點最近,而紅色的線則和兩條紫線的距離相等,我們把兩條紫線的距離稱作間隔Margin

假如我們設定 g(X)=WTX+b為線性判別函式,對g(X)進行歸一化,即令g1(X)=g(X)/c,也即W1=WT /c,b1=b/c,我們可以得到新的左圖,
這也是,為什么支持向量機需要使用歸一化,可以大幅度的提高模型的效果的原因
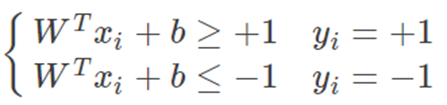

約束條件合并
對于上圖而言:
1)藍色樣本點(y=+1)必定在直線W1TX+b1=+1上方,也即對所有藍色樣本點資料必定滿足: W1TX+b1≥+1
2)黑色樣本點(y=-1)必定在直線W1TX+b1=-1下面,也即對所有黑色樣本點資料必定滿足: W1TX+b1≤-1
我們把以上兩個不等式合成一個,即:
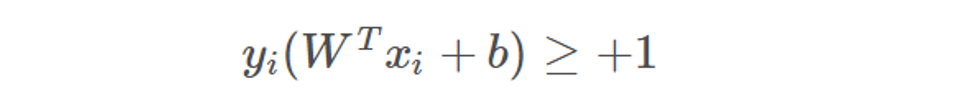
距離超平面最近的這幾個樣本點滿足yi(WTxi+b)=1,它們被稱為“支持向量”,虛線稱為邊界,兩條虛線間的距離稱為間隔(margin),而間隔(margin)其實就是兩個異類支持向量的差在法向量W方向的投影,故有:
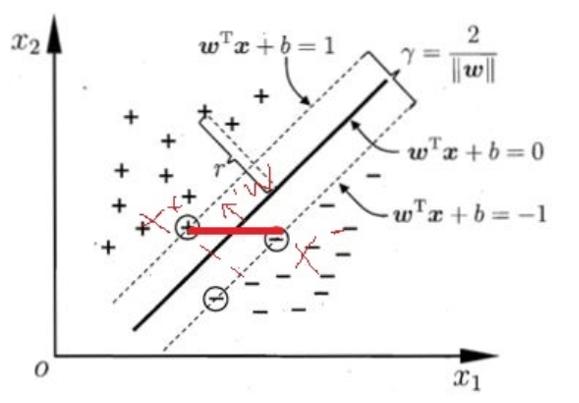
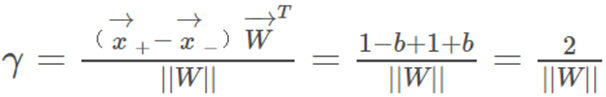
經過了大量的鋪墊作業之后,現在我們對支持向量機進行一個定義
支持向量機(support vector machines)是一種二分類模型,它的目的是尋找一個超平面來對樣本進行分割,分割的原則是間隔最大化,最終轉化為一個凸二次規劃問題來求解:

支持向量機的三種情況
線性可分
線性可分指樣本資料集可以找到一個線性函式或者超平面一分為二,這樣的支持向量機又叫硬間隔(Hard Margin)支持向量機,求解程序如下:
1)使用拉格朗日乘子法得到其對偶問題:
2)分別對W和b求偏導,并令其等于0:
3)將(9)和(10)代回公式(8),消去之前W和b,原問題就轉換成了關于α的問題
4)新的目標函式變成如下:
5)這樣解出α之后,就可以根據公式(9)求W,進而求偏移量b
6)該程序的KKT條件為:
對于任意的訓練樣本 (xi,yi):
若 αi=0,則其不會在公式(13)中的求和項中出現,也就是說,它不影響模型的訓練;
若 αi>0,則yif(xi)?1=0,也就是 yif(xi)=1,即該樣本一定在邊界上,是一個支持向量,這里顯示出了支持向量機的重要特征:當訓練完成后,大部分樣本都不需要保留,最終模型只與支持向量有關,
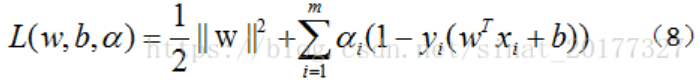
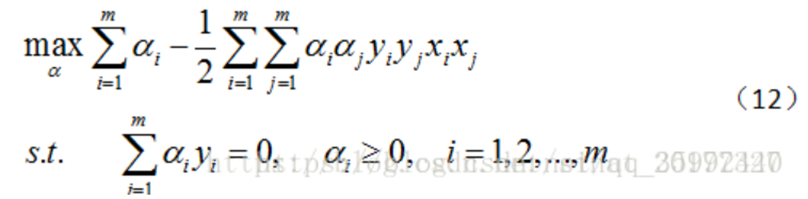
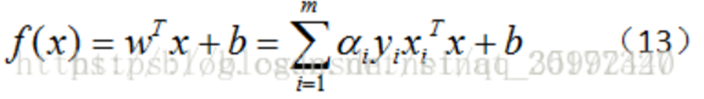
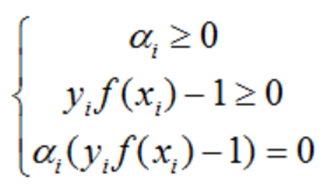
近線性可分
假如資料本身并非線性不可分的,只是因為噪聲資料的存在,一些偏離正常位置很遠的離群點資料(Outlier),使得資料線性不可分,
為解決這一問題,可以對每個樣本點引入一個松弛變數 ξi≥0,使得間隔加上松弛變數大于等于1,這樣處理后資料仍然可以實作線性可分,我們稱之為近線性可分,這樣的支持向量機也叫軟間隔(Soft Margin)支持向量機,
這個時候,原問題的約束條件變成了:
同時,對于每一個松弛變數ξi≥0,支付一個代價 ξi≥0,目標函式變為:
其中 C>0為懲罰引數,C值大時對誤分類的懲罰增大, C值小時對誤分類的懲罰減小,公式(21)包含兩層含義:使 ||W||2/2盡量小即間隔盡量大,同時使誤分類點的個數盡量小,C是調和兩者的系數,
有了公式(21),可以和線性可分支持向量機一樣考慮線性支持向量機的學習程序
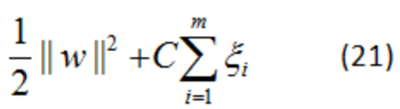
近線性可分求解程序
1)近線性支持向量機的學習問題變成如下凸二次規劃問題的求解(原始問題):
2)對其使用拉格朗日函式,利用對偶問題求解,公式(22)的拉格朗日函式為:
其中 αi≥0,μi≥0是拉格朗日乘子,
3)令L(w,b,α,ξ,μ)對w,b,ξ的偏導數為0可得如下:
4)將公式(24)(25)(26)代入公式(23)得對偶問題:
5)上述程序的KKT條件為:
對于任意的訓練樣本 (xi,yi) ,總有 αi=0 或者yif(xi)?1+ξi=0:
1)若 αi=0,則其不會在公式(13)中的求和項中出現,也就是說,它不影響模型的訓練;2)若 αi>0,則yif(xi)?1+ξi=0,也就是 yif(xi)=1- ξi ,即該樣本一定在邊界上,是一個支持向量,結果跟線性可分SVM差不多,這個也是SVM演算法的一大特色
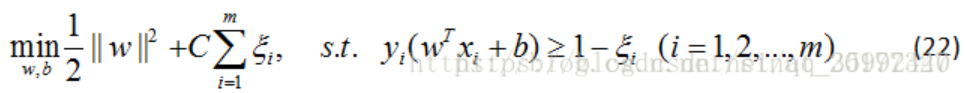
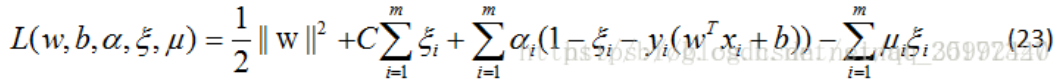
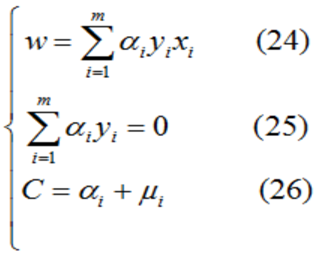
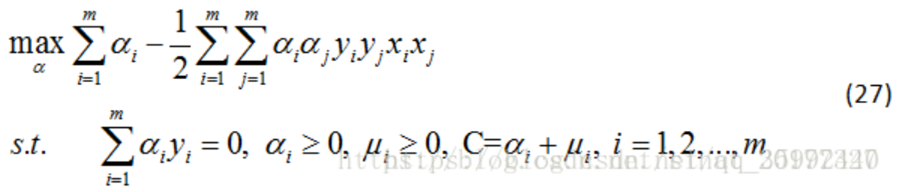
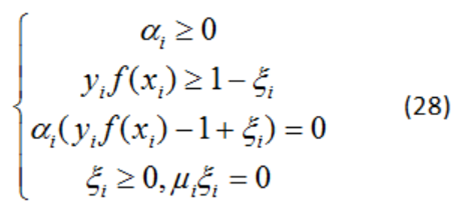
線性不可分
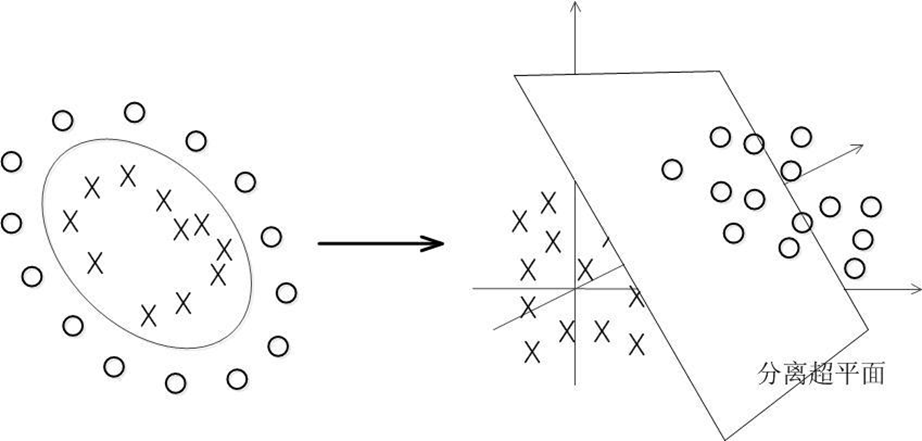
如果資料確實線性不可分,這個時候可以考慮把資料映射到更高維的空間,然后使得轉換后的資料變得線性可分,
這個程序中,會引入一個核函式的概念,具體來說,在線性不可分的情況下,支持向量機首先在低維空間中完成計算,然后通過核函式將輸入空間映射到高維特征空間,最終在高維特征空間中構造出最優分離超平面,從而把平面上本身不好分的非線性資料分開,
通俗易懂的來講就是在多維空間里面利用多維曲面進行分類
不用核函式的傳統方法
如果用原始的方法,那么在用線性學習器學習一個非線性關系,需要選擇一個非線性特征集,并且將資料寫成新的表達形式,這等價于應用一個固定的非線性映射,將資料映射到特征空間,在特征空間中使用線性學習器,因此,考慮的假設集是這種型別的函式:
這里?:X->F是從輸入空間到某個特征空間的映射,這意味著建立非線性學習器分為兩步:
1)首先使用一個非線性映射將資料變換到一個特征空間F,
2)然后在特征空間使用線性學習器分類,
但這種方法隨著維度的增長,存在很大的問題:
1)我們對一個二維空間構造一個非線性的曲面做映射,選擇的新空間是原始空間的所有一階和二階的組合,那么會得到五個維度;
2)如果原始空間是三維(一階、二階和三階的組合),那么我們會得到:3(一次)+3(二次交叉)+3(平方)+3(立方)+1(x1*x2*x3)+2*3(交叉,一個一次一個二次,類似x1*x2^2) = 19維的新空間,這個數目是呈指數級爆炸性增長的從而勢必這給的計算帶來非常大的困難,
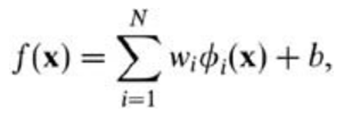
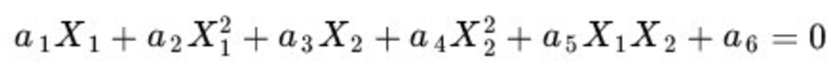
如果遇到無窮維的情況,就更加無從計算了,這個時候我們就必須引入Kernel核函式
核函式Kernel是什么?
核是一個特征空間的隱式映射,比如假定函式K,對所有x,z(-X,滿足
核函式與傳統的計算方式不同之處:
1、(傳統)一個是映射到高維空間中,然后再根據內積的公式進行計算;
2、(核函式) 則直接在原來的低維空間中進行計算,而不需要顯式地寫出映射后的結果,
核函式SVM求解程序
1)令?(x)\phi (x)?(x)表示將 x 映射后的特征向量,于是劃分超平面所對應的的模型:
2)于是有最小化函式:
3)利用拉格朗日乘子法,求對偶問題:
4)若要對公式(16)求解,會涉及到計算 ?(xi)T?(xj) 之后的內積,由于特征空間的維數可能很高,甚至是無窮維,因此直接計算 ?(xi)T?(xj)通常是困難的,于是想到這樣一個函式:
即 xi和xj在特征空間中的內積等于他們在原始樣本空間中通過函式 κ(xi,xj) 計算的函式值,于是公式(16)寫成如下:
最后得到
其中k(xi,xj)就是核函式,可以根據情況有多種選擇

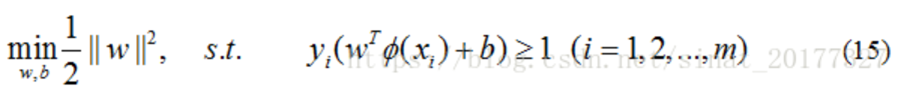
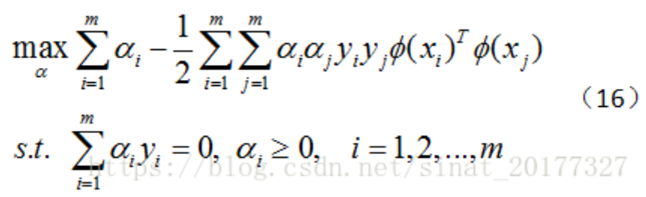
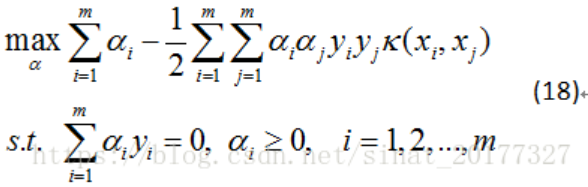
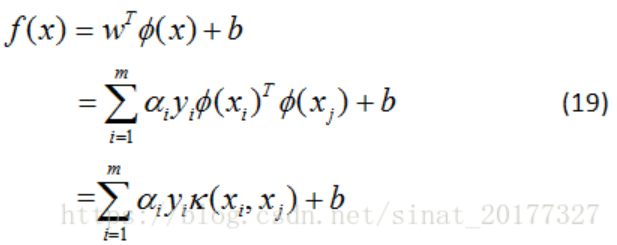

核函式的本質
1、實際中,我們會經常遇到線性不可分的樣例,此時,我們的常用做法是把樣例特征映射到高維空間中去(如之前那幅圖線性不可分圖所示,映射到高維空間后,相關特征便被分開了,也就達到了分類的目的);
2、但進一步,如果凡是遇到線性不可分的樣例,一律映射到高維空間,那么這個維度大小是會高到可怕的(如上文中19維乃至無窮維的例子),那咋辦呢?
3、此時,核函式就隆重登場了,核函式的價值在于它雖然也是將特征進行從低維到高維的轉換,但核函式絕就絕在它事先在低維上進行計算,而將實質上的分類效果表現在了高維上,也就如上文所說的避免了直接在高維空間中的復雜計算,
說到這里,相信差不多應該可以理解了吧,下面再去舉一個例子
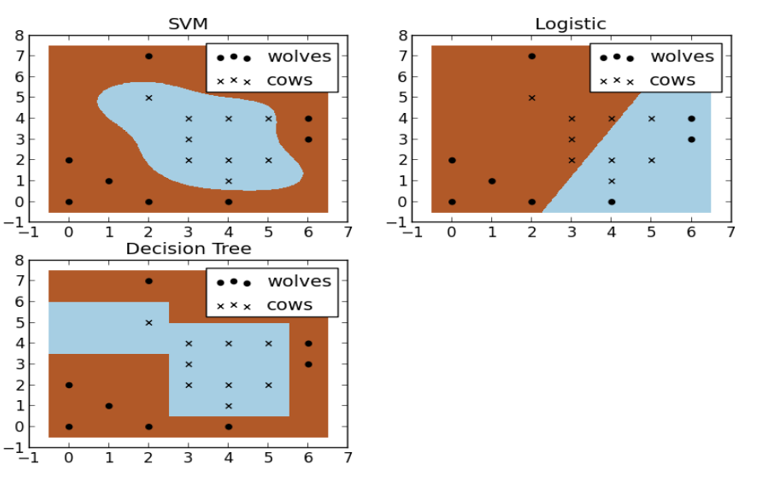
假設現在你是一個農場主,圈養了一批羊群,但為預防狼群襲擊羊群,你需要搭建一個籬笆來把羊群圍起來,但是籬笆應該建在哪里呢?你很可能需要依據牛群和狼群的位置建立一個“分類器”,比較下圖這幾種不同的分類器,我們可以看到SVM完成了一個很完美的解決方案,
顯然,我們的SVM勝利了!
講了這么多,其實就是在介紹支持向量機的本質,如果你認真的看完之后,你會發現,在支持向量機里面,最重要的兩個引數就是C和核函式
支持向量機的優勢在于:
( 1) 在高維空間中非常高效,
( 2) 即使在資料維度比樣本數量大的情況下仍然有效,
( 3) 在決策函式(稱為支持向量)中使用訓練集的子集,因此它也是高效利用記憶體的,
支持向量機的缺點包括:
( 1) 如果特征數量比樣本數量大得多, 在選擇核函式核函式時要避免過擬合,
( 2) 而且正則化項是非常重要的,
( 3) 支持向量機不直接提供概率估計, 這些都是使用昂貴的五次交叉驗算計算的,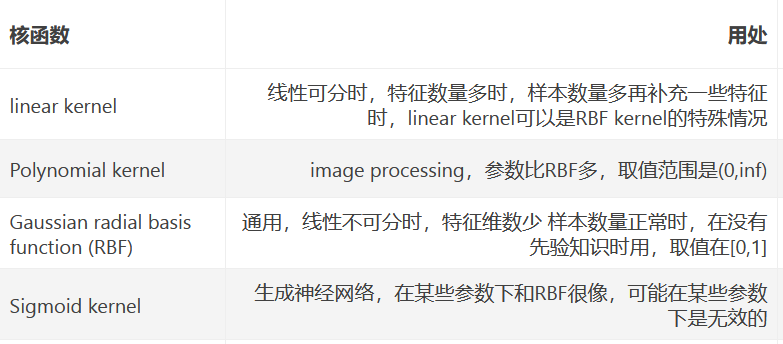
注意,這里很重要的,根據你選擇的核函式,最終對資料是否需要預處理,下面我們就看看一個實體:
代碼實體
匯入第三方庫
#匯入所需要的包
from sklearn.metrics import precision_score
from sklearn.model_selection import train_test_split
from sklearn.svm import SVC
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
from matplotlib.colors import ListedColormap
from sklearn.preprocessing import LabelEncoder
from sklearn.metrics import classification_report
from sklearn.model_selection import GridSearchCV #網格搜索
import matplotlib.pyplot as plt#可視化
import seaborn as sns#繪圖包
from sklearn.preprocessing import StandardScaler,MinMaxScaler,MaxAbsScaler初次加載模型
# 加載模型
model = SVC()
# 訓練模型
model.fit(X_train,y_train)
# 預測值
y_pred = model.predict(X_test)
'''
評估指標
'''
# 求出預測和真實一樣的數目
true = np.sum(y_pred == y_test )
print('預測對的結果數目為:', true)
print('預測錯的的結果數目為:', y_test.shape[0]-true)
# 評估指標
from sklearn.metrics import accuracy_score,precision_score,recall_score,f1_score,cohen_kappa_score
print('預測資料的準確率為: {:.4}%'.format(accuracy_score(y_test,y_pred)*100))
print('預測資料的精確率為:{:.4}%'.format(
precision_score(y_test,y_pred)*100))
print('預測資料的召回率為:{:.4}%'.format(
recall_score(y_test,y_pred)*100))
# print("訓練資料的F1值為:", f1score_train)
print('預測資料的F1值為:',
f1_score(y_test,y_pred))
print('預測資料的Cohen’s Kappa系數為:',
cohen_kappa_score(y_test,y_pred))
# 列印分類報告
print('預測資料的分類報告為:','\n',
classification_report(y_test,y_pred))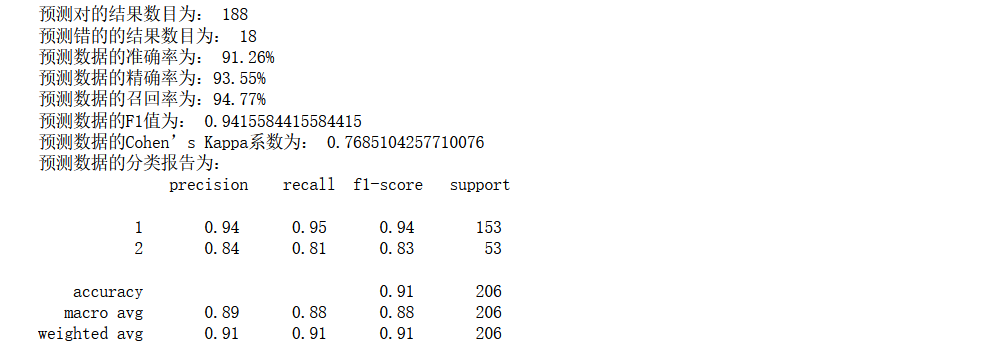
這里默認使用的是高斯核,但是我們的資料集范圍并沒有規約到[0,1]之間,由于資料集最先最好了離散化,所以造成的影響也不是很大,因為這里是初次加載
標準化
# 沒有作用
# sc = StandardScaler()
# 標準化【0,1】
# 效果不行
sc=MinMaxScaler()
# sc=MaxAbsScaler()
X_train1 = sc.fit_transform(X_train)
X_test1 = sc.transform(X_test)
X_test1
使用標準化后的資料集進行預測
# 加載模型
model = SVC()
# 訓練模型
model.fit(X_train1,y_train)
# 預測值
y_pred = model.predict(X_test1)
'''
評估指標
'''
# 求出預測和真實一樣的數目
true = np.sum(y_pred == y_test )
print('預測對的結果數目為:', true)
print('預測錯的的結果數目為:', y_test.shape[0]-true)
# 評估指標
from sklearn.metrics import accuracy_score,precision_score,recall_score,f1_score,cohen_kappa_score
print('預測資料的準確率為: {:.4}%'.format(accuracy_score(y_test,y_pred)*100))
print('預測資料的精確率為:{:.4}%'.format(
precision_score(y_test,y_pred)*100))
print('預測資料的召回率為:{:.4}%'.format(
recall_score(y_test,y_pred)*100))
# print("訓練資料的F1值為:", f1score_train)
print('預測資料的F1值為:',
f1_score(y_test,y_pred))
print('預測資料的Cohen’s Kappa系數為:',
cohen_kappa_score(y_test,y_pred))
# 列印分類報告
print('預測資料的分類報告為:','\n',
classification_report(y_test,y_pred))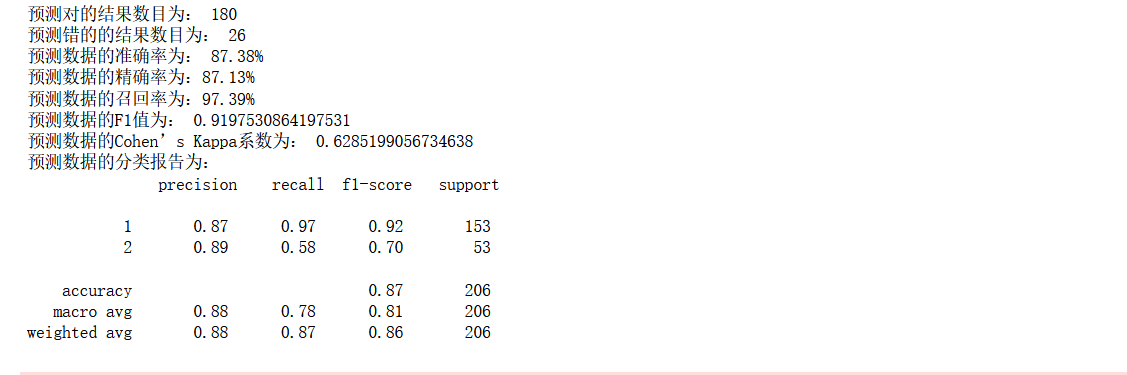
并不樂觀,繼續探索
模型調參
from datetime import time
import datetime
# ploy在該例中跑不出來
Kernel = ["linear", "rbf", "sigmoid","poly"]
for kernel in Kernel:
time0 = time()
clf = SVC(kernel=kernel,
gamma="auto",
cache_size=5000, # 允許使用的記憶體,單位為MB,默認是200M
).fit(X_train, y_train)
print("The accuracy under kernel %s is %f" % (kernel, clf.score(X_test, y_test)))
# print(datetime.datetime.fromtimestamp(time() - time0).strftime("%M:%S:%f"))
優先考慮多項式和高斯核
gamma調參
RBF調參
# 使用rbf,必須要對其進行資料縮放
# 畫學習曲線
score = []
gamma_range = np.logspace(-10, 1, 50) # 回傳在對數刻度上均勻間隔的數字
for i in gamma_range:
clf = SVC(kernel="rbf", gamma=i, cache_size=5000).fit(X_train, y_train)
score.append(clf.score(X_test, y_test))
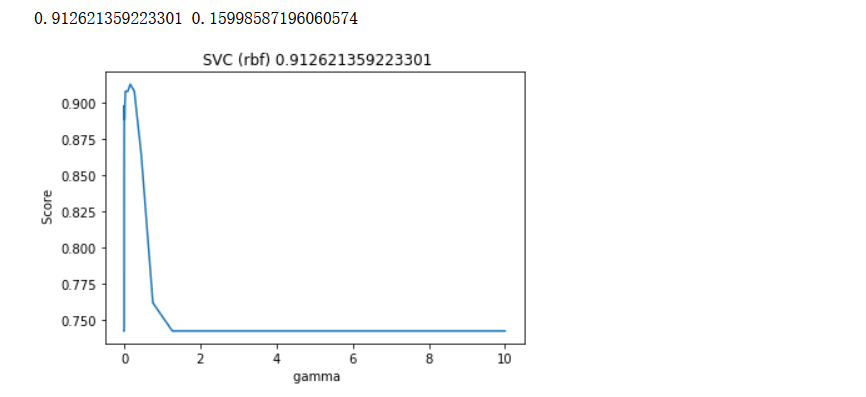
print(max(score), gamma_range[score.index(max(score))])
best_gamma_rbf=gamma_range[score.index(max(score))]
#設定標題
plt. title(f' SVC (rbf) {max(score)}')
#設定x軸標簽
plt. xlabel(' gamma')
#設定y軸標簽
plt. ylabel(' Score')
#添加圖例
# plt. legend()
plt.plot(gamma_range, score)
plt.show()
rbf核下的最佳gamma是0.1599......
poly調參
# 畫學習曲線,資料不需要處理
score = []
gamma_range = np.logspace(-10, 1, 50) # 回傳在對數刻度上均勻間隔的數字
for i in gamma_range:
clf = SVC(kernel="poly", gamma=i, cache_size=5000).fit(X_train, y_train)
score.append(clf.score(X_test, y_test))
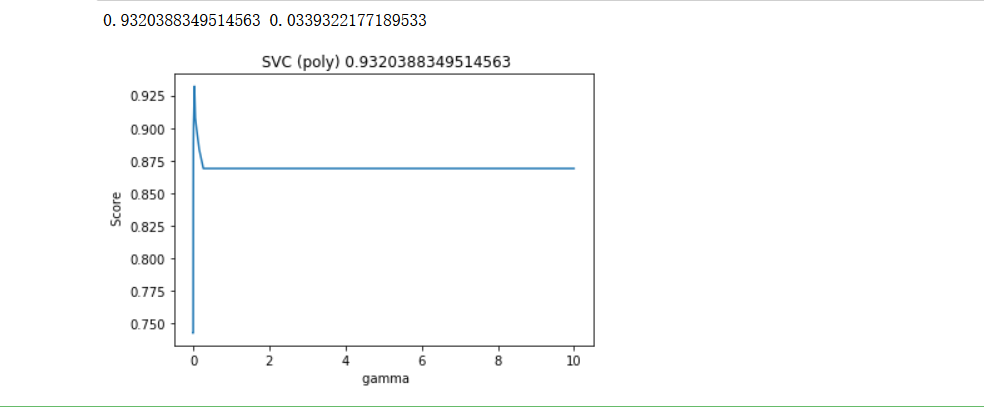
print(max(score), gamma_range[score.index(max(score))])
best_gamma_poly=gamma_range[score.index(max(score))]
#設定標題
plt. title(f' SVC (poly) {max(score)}')
#設定x軸標簽
plt. xlabel(' gamma')
#設定y軸標簽
plt. ylabel(' Score')
#添加圖例
# plt. legend()
plt.plot(gamma_range, score)
plt.show()
效果上升了,感覺多項式核函式也還不錯的
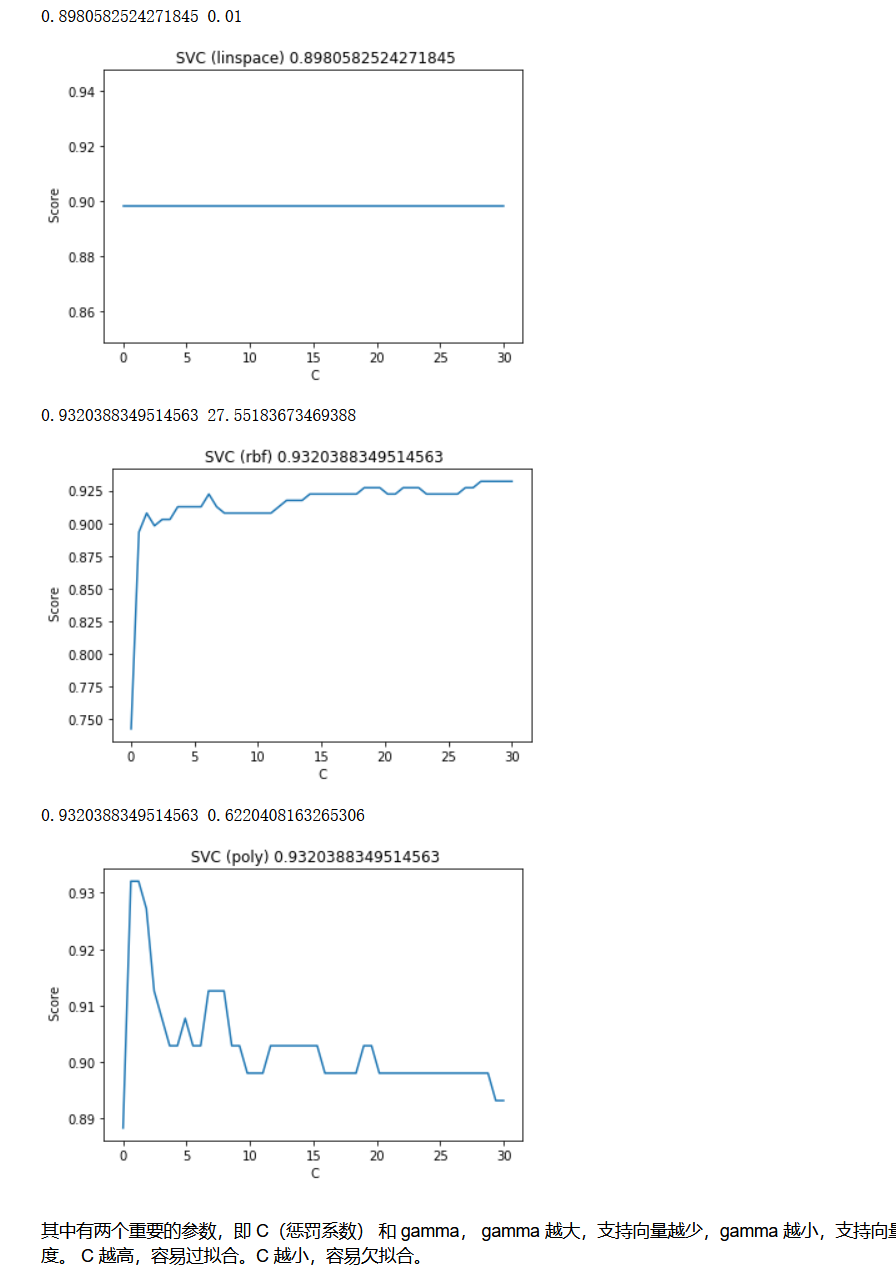
C值調參
# 調線性核函式
score = []
C_range = np.linspace(0.01, 30, 50)
for i in C_range:
clf = SVC(kernel="linear",C=i,cache_size=5000).fit(X_train,y_train)
score.append(clf.score(X_test, y_test))
print(max(score), C_range[score.index(max(score))])
best_C_linear=C_range[score.index(max(score))]
#設定標題
plt. title(f' SVC (linspace) {max(score)}')
#設定x軸標簽
plt. xlabel(' C')
#設定y軸標簽
plt. ylabel(' Score')
#添加圖例
# plt. legend()
plt.plot(C_range, score)
plt.show()
# 換rbf,并且這里對資料進行了標準化,縮放到0和1之間的
score = []
C_range = np.linspace(0.01, 30, 50)
for i in C_range:
clf = SVC(kernel="rbf", C=i, gamma=0.15998587196060574, cache_size=5000).fit(X_train, y_train)
score.append(clf.score(X_test, y_test))
print(max(score), C_range[score.index(max(score))])
best_C_rbf=C_range[score.index(max(score))]
#設定標題
plt. title(f' SVC (rbf) {max(score)}')
#設定x軸標簽
plt. xlabel(' C')
#設定y軸標簽
plt. ylabel(' Score')
#添加圖例
# plt. legend()
plt.plot(C_range, score)
plt.show()
# 換ploy
score = []
C_range = np.linspace(0.01, 30, 50)
for i in C_range:
clf = SVC(kernel="poly", C=i, gamma=0.0339322177189533, cache_size=5000).fit(X_train, y_train)
score.append(clf.score(X_test, y_test))
print(max(score), C_range[score.index(max(score))])
best_C_poly=C_range[score.index(max(score))]
#設定標題
plt. title(f' SVC (poly) {max(score)}')
#設定x軸標簽
plt. xlabel(' C')
#設定y軸標簽
plt. ylabel(' Score')
#添加圖例
# plt. legend()
plt.plot(C_range, score)
plt.show()
看起來他們的分數不相上下(RBF和poly),根據他們的學習曲線,還是可以看出不一樣的
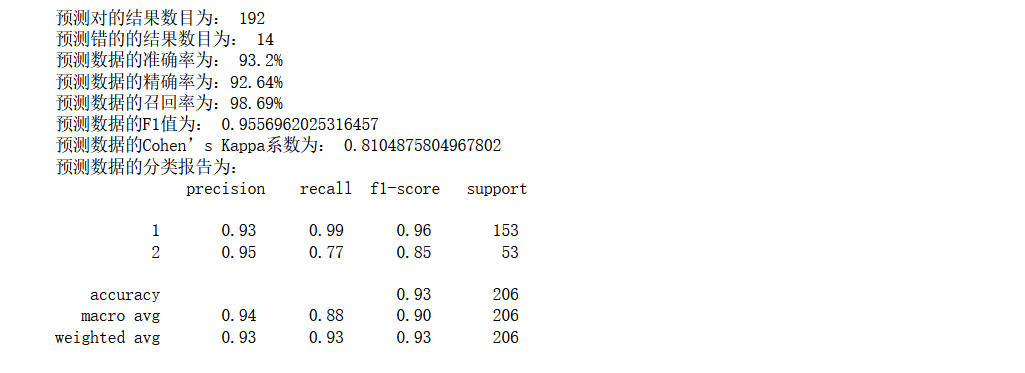
使用Polynomial kernel進行預測
# 加載模型
model_1 = SVC(C=best_C_poly,gamma=best_gamma_poly,kernel='poly',cache_size=5000,degree=3,probability=True)
# 訓練模型
model_1.fit(X_train,y_train)
# 預測值
y_pred = model_1.predict(X_test)
'''
評估指標
'''
# 求出預測和真實一樣的數目
true = np.sum(y_pred == y_test )
print('預測對的結果數目為:', true)
print('預測錯的的結果數目為:', y_test.shape[0]-true)
# 評估指標
from sklearn.metrics import accuracy_score,precision_score,recall_score,f1_score,cohen_kappa_score
print('預測資料的準確率為: {:.4}%'.format(accuracy_score(y_test,y_pred)*100))
print('預測資料的精確率為:{:.4}%'.format(
precision_score(y_test,y_pred)*100))
print('預測資料的召回率為:{:.4}%'.format(
recall_score(y_test,y_pred)*100))
# print("訓練資料的F1值為:", f1score_train)
print('預測資料的F1值為:',
f1_score(y_test,y_pred))
print('預測資料的Cohen’s Kappa系數為:',
cohen_kappa_score(y_test,y_pred))
# 列印分類報告
print('預測資料的分類報告為:','\n',
classification_report(y_test,y_pred))from sklearn.metrics import precision_recall_curve
from sklearn import metrics
# 預測正例的概率
y_pred_prob=model_1.predict_proba(X_test)[:,1]
# y_pred_prob ,回傳兩列,第一列代表類別0,第二列代表類別1的概率
#https://blog.csdn.net/dream6104/article/details/89218239
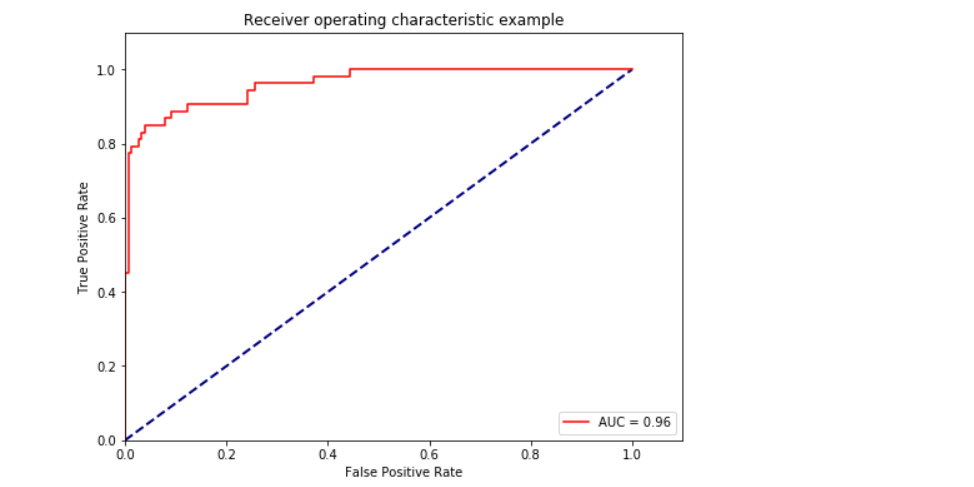
fpr, tpr, thresholds = metrics.roc_curve(y_test,y_pred_prob, pos_label=2)
#pos_label,代表真陽性標簽,就是說是分類里面的好的標簽,這個要看你的特征目標標簽是0,1,還是1,2
roc_auc = metrics.auc(fpr, tpr) #auc為Roc曲線下的面積
# print(roc_auc)
plt.figure(figsize=(8,6))
plt.plot([0, 1], [0, 1], color='navy', lw=2, linestyle='--')
plt.plot(fpr, tpr, 'r',label='AUC = %0.2f'% roc_auc)
plt.legend(loc='lower right')
# plt.plot([0, 1], [0, 1], 'r--')
plt.xlim([0, 1.1])
plt.ylim([0, 1.1])
plt.xlabel('False Positive Rate') #橫坐標是fpr
plt.ylabel('True Positive Rate') #縱坐標是tpr
plt.title('Receiver operating characteristic example')
plt.show()評估指標
ROC曲線AUC面積
模型效果還是不錯,可以達到93%的準確率
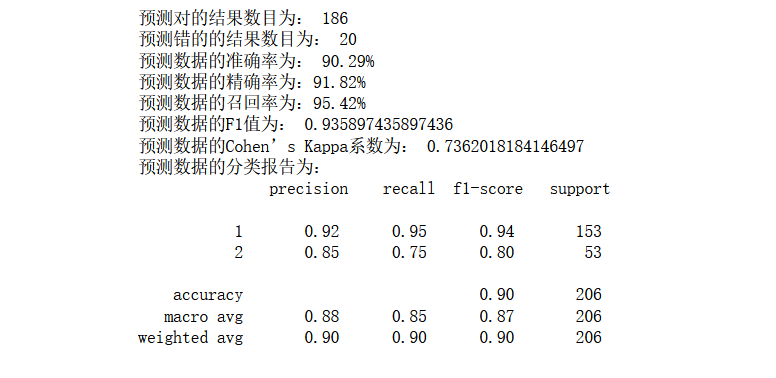
使用RBF kernel進行預測
# 加載模型
model_2 = SVC(C=best_C_rbf,kernel='rbf',cache_size=5000,probability=True)
# 訓練模型
model_2.fit(X_train1,y_train)
# 預測值
y_pred = model_2.predict(X_test1)
'''
評估指標
'''
# 求出預測和真實一樣的數目
true = np.sum(y_pred == y_test )
print('預測對的結果數目為:', true)
print('預測錯的的結果數目為:', y_test.shape[0]-true)
# 評估指標
from sklearn.metrics import accuracy_score,precision_score,recall_score,f1_score,cohen_kappa_score
print('預測資料的準確率為: {:.4}%'.format(accuracy_score(y_test,y_pred)*100))
print('預測資料的精確率為:{:.4}%'.format(
precision_score(y_test,y_pred)*100))
print('預測資料的召回率為:{:.4}%'.format(
recall_score(y_test,y_pred)*100))
# print("訓練資料的F1值為:", f1score_train)
print('預測資料的F1值為:',
f1_score(y_test,y_pred))
print('預測資料的Cohen’s Kappa系數為:',
cohen_kappa_score(y_test,y_pred))
# 列印分類報告
print('預測資料的分類報告為:','\n',
classification_report(y_test,y_pred))from sklearn.metrics import precision_recall_curve
from sklearn import metrics
# 預測正例的概率
y_pred_prob=model_2.predict_proba(X_test1)[:,1]
# y_pred_prob ,回傳兩列,第一列代表類別0,第二列代表類別1的概率
#https://blog.csdn.net/dream6104/article/details/89218239
fpr, tpr, thresholds = metrics.roc_curve(y_test,y_pred_prob, pos_label=2)
#pos_label,代表真陽性標簽,就是說是分類里面的好的標簽,這個要看你的特征目標標簽是0,1,還是1,2
roc_auc = metrics.auc(fpr, tpr) #auc為Roc曲線下的面積
# print(roc_auc)
plt.figure(figsize=(8,6))
plt.plot([0, 1], [0, 1], color='navy', lw=2, linestyle='--')
plt.plot(fpr, tpr, 'r',label='AUC = %0.2f'% roc_auc)
plt.legend(loc='lower right')
# plt.plot([0, 1], [0, 1], 'r--')
plt.xlim([0, 1.1])
plt.ylim([0, 1.1])
plt.xlabel('False Positive Rate') #橫坐標是fpr
plt.ylabel('True Positive Rate') #縱坐標是tpr
plt.title('Receiver operating characteristic example')
plt.show()
效果也還是不錯,雖然比poly稍微低一點,但是總體來說還是不錯的
總結
本次使用支持向量機進行模型分類預測,并沒有對其進行特征篩選,效果也是不錯的,因為支持向量機的本質也會根據根據特征進行劃分,這里經過測驗之后也確實如此,
核支持向量機是非常強大的模型,在各種資料集上的表現都很好, SVM 允許決策邊界很
復雜,即使資料只有幾個特征,它在低維資料和高維資料(即很少特征和很多特征)上的
表現都很好,但對樣本個數的縮放表現不好,在有多達 10 000 個樣本的資料上運行 SVM
可能表現良好,但如果資料量達到 100 000 甚至更大,在運行時間和記憶體使用方面可能會
面臨挑戰,
SVM 的另一個缺點是,預處理資料和調參都需要非常小心,這也是為什么如今很多應用
中用的都是基于樹的模型,比如隨機森林或梯度提升(需要很少的預處理,甚至不需要預
處理),此外, SVM 模型很難檢查,可能很難理解為什么會這么預測,而且也難以將模型
向非專家進行解釋,
不過 SVM 仍然是值得嘗試的,特別是所有特征的測量單位相似(比如都是像素密度)而
且范圍也差不多時,
核 SVM 的重要引數是正則化引數 C、核的選擇以及與核相關的引數,雖然我們主要講的是
RBF 核,但 scikit-learn 中還有其他選擇, RBF 核只有一個引數 gamma,它是高斯核寬度
的倒數,
gamma 和 C 控制的都是模型復雜度,較大的值都對應更為復雜的模型,因此,這
兩個引數的設定通常是強烈相關的,應該同時調節,
每文一語
走好當下的每一步便是努力
轉載請註明出處,本文鏈接:https://www.uj5u.com/qita/423565.html
標籤:AI
上一篇:R語言rename重命名dataframe的列名實戰:rename重命名dataframe的列名(寫錯的列名不會被重命名)