ClickHouse UBA 版本是位元組跳動內部在開源版本基礎上為火山引擎增長分析專門深度定制優化的版本,本文介紹在字典編碼方向上的優化實踐,作者系位元組跳動資料平臺研發工程師 Jet He,長期致力于 OLAP 引擎開發優化,在 OLAP 領域、用戶行為在線分析等有豐富的經驗,
背景
雖然 ClickHouse 列存已經有比較好的存盤壓縮率,但面對海量資料時,磁盤空間的占用跟常用的 Parquet 格式相比仍然有不少差距,特別是對于低基數列時,Parquet 的存盤空間會更加有優勢,
同時,大多這類資料的事件屬性都有低基數的特征,例如事件屬性中的城市、性別、品牌等等,Parquet 會自動對低基數列做字典編碼,因此會獲得更高的存盤效率,
同時 ClickHouse 官方也提供了一種字典編碼的解決方案即 LowCardinality 型別,網上也有一些測驗 Benchmark 資料,效果不錯,可以進一步降低存盤空間和提升查詢、IO 性能,
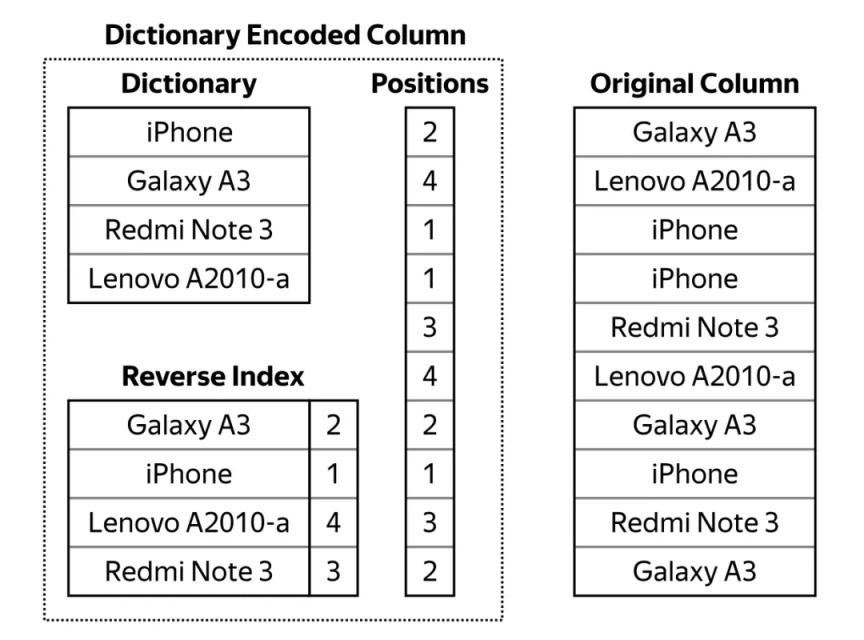
上圖是內部 LowCardinality 的存盤結構,寫入程序中,會構建一個字典,列資料通過 Positions 表示,數值是字典中每個 Unique 值的 Index,其他更加詳細的介紹可以參考官方檔案,
但在內部環境中通過驗證測驗發現,原始的 LowCardinality 列存在以下兩個致命問題:
- 在 LowCardinality 列比較多的情況下(平均 300+),Part Merge 耗時嚴重,在大量實時寫入的場景下,Merge 速度跟不上寫入速度,最侄訓導致集群不可用;
- 用戶資料中事件屬性多種多樣,UBA 版本通過動態 Map 列實作用戶屬性的自由上報,也會導致某些屬性基數非常大,不再適合做字典編碼,否則會同時導致存盤、計算性能下降,
如果以上兩個問題得不到解決,那么字典編碼功能就無法上線使用,需要一種解決方案,能夠做到支持大量的列做字典編碼的同時需要保證內部 Part 的 Merge 速度,另外就是面對高基數列時需要一個 Fall back 方案,讓高基數列時不再做字典編碼,改用原始列存盤,原作者在做字典編碼技術分享時也提到了針對高基數列時 Fall back 到原始列的構想,但社區版本中目前沒有付諸實作,
解決方案
首先來看針對 LowCardinality 列 Part Merge 的優化方案,
這里先介紹下 ClickHouse 的 Part Merge 程序,ClickHouse 的資料組織是以 Part 形式存在的,每個 Part 對應磁盤的一個資料目錄,每次寫入都會生成一個 Part,Part 目錄下包含各個列的資料檔案,因此每次寫入的時候最好是大批量的寫入,才能有較好的寫入吞吐,
ClickHouse 有常駐 Worker 執行緒不斷的做 Part 的 Merge,將小 Part 不斷地 Merge 成大 Part,從而提升查詢性能,如果 Part 不能及時 Merge 會造成嚴重的性能問題,更有甚者還會造成 Inodes 耗盡,
當統一把事件屬性列(Map 列)改為 LowCardinality 列時,發現 Part Merge 耗時嚴重,Part 數會不斷增長,最侄訓導致集群不可用,通過 Profile 發現,在 LowCardinality 列 Part Merge 時,耗時主要發生在字典構造上,具體如下圖灰色部分所示:
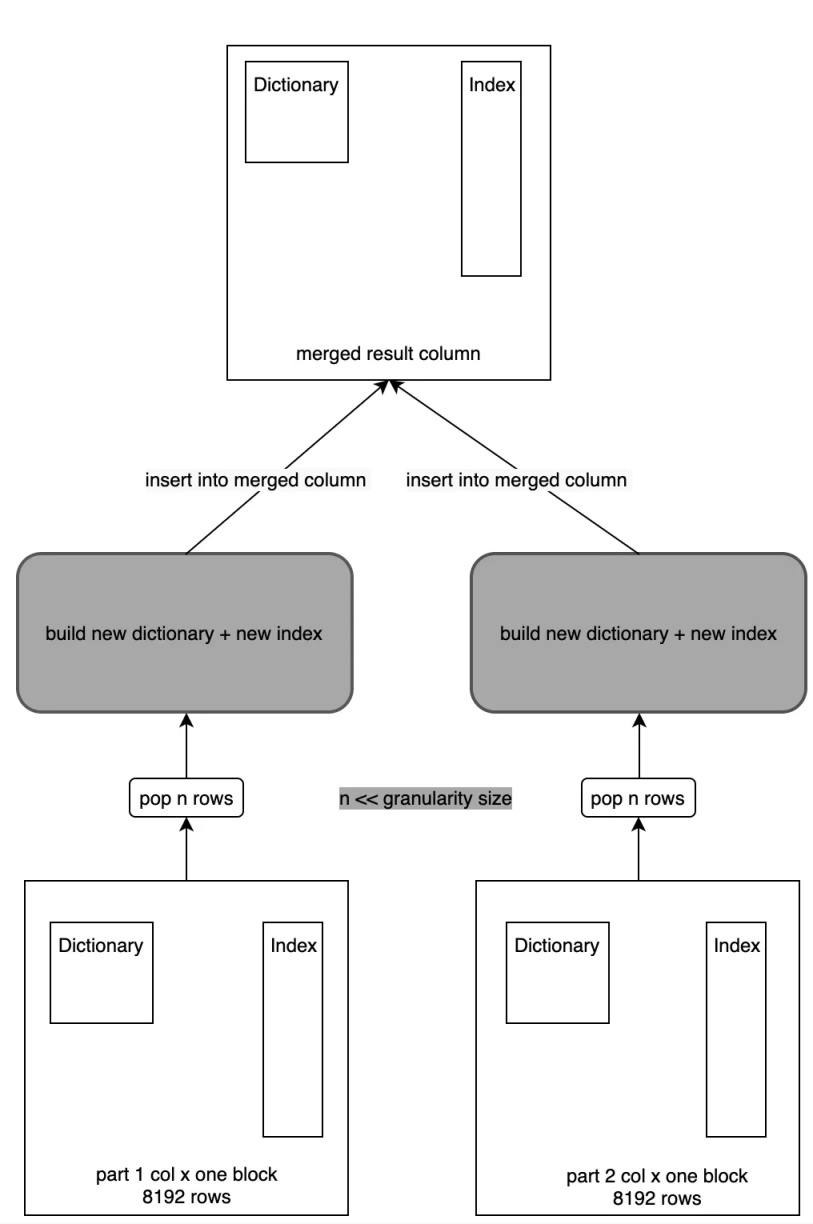
即在做 Part Merge 程序中,首先會通過 Primary Key 列做排序,然后從每個 Part 中獲取對應的 Row 寫入到一個新的 Part 中,例如一次從 Part1 中取 3 行寫入到新 Part 中,下一次從 Part2 中取 5 行寫入到新 Part 中,寫入到新 Part 時,LowCardinality 首先做構建新的字典,并生成好倒排索引,形成一個新的 LowCardinality 列,然后通過 Column 的 Insert 介面完成寫入,另外在構建字典的程序中,是通過一個 HashTable 實作,這樣在做 Merge 時這塊的性能損耗較大,所以優化的關鍵點就是在于字典的構建程序,
這里實作了一種先構建字典后做具體 Merge 的思路,即多個 Part 的 Merge 程序中,詞典只需要構建一次,然后接下來的 Merge 只需要將 Index 直接 Append 寫入到新 Part 即可,
整個程序可以分為兩個程序:
01 -Dictionary Merge
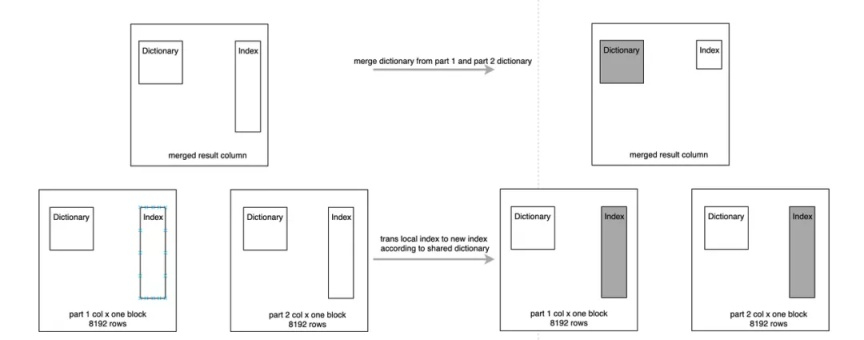
首先進行字典的 Merge,在 Merge 的程序中,先將待 Merge 的幾個 Part 中的字典部分做 Merge,生成一個字典,同時記錄下每個 Part 這個列中 Index 的變化,這個變化類似一個轉換矩陣;
Index Merge 程序中將這個轉換矩陣逐個 Apply 到 Part 中的 Index,有時這個轉換矩陣為空,例如 Unique 值很少的列,基本可以保證每個 Part 的字典基本一樣,如果轉換矩陣為空這步操作會直接跳過,
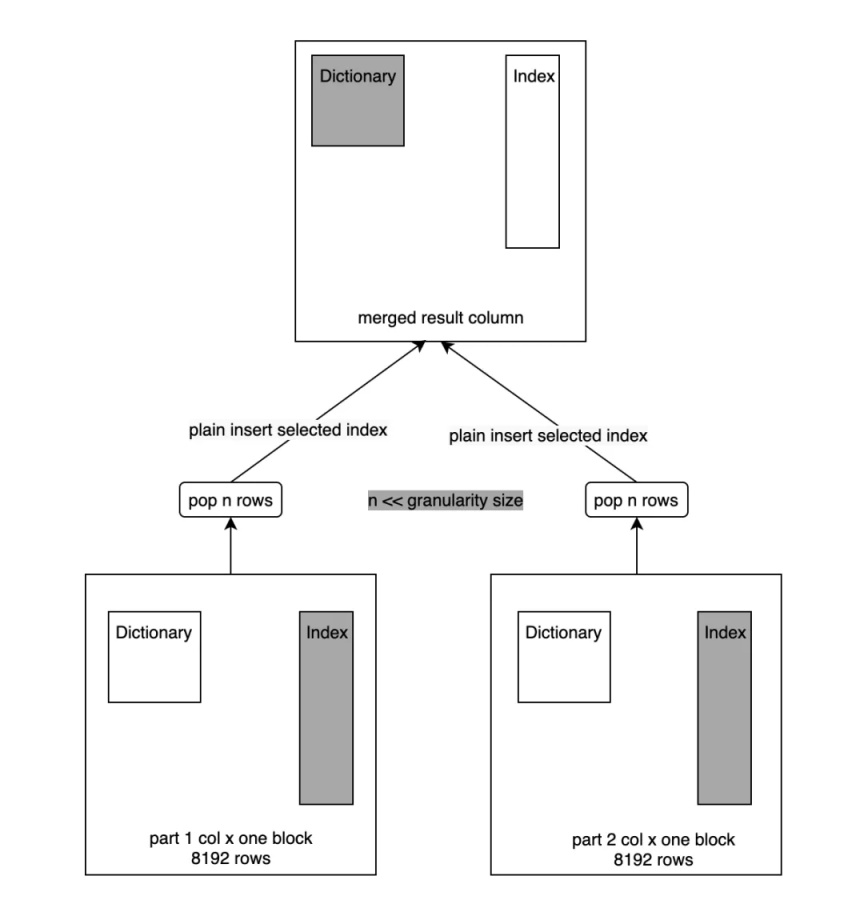
02 -Index Merge
Index Merge 程序跟之前的 Merge 程序一致,只不過這里不再做字典構建了,會直接將列中的 Index Append 到新列的 Index 中,如下圖所示:
經過這個 Merge 優化后,LowCardinality 的 Merge 性能有明顯提升,在大量寫入的場景也能應付自如,寫入的 Part 可以得到及時 Merge,
具體的性能優化測驗資料如下表所示,Merge 速度的是在表寫入程序中統計得出,寫入大量大概 10 億左右:

可以看出在基數 10 萬以內時性能提升非常明顯,當基數 100 萬+時,性能提升不明顯,并且在 1000 萬時還會導致性能回退,這里也不難理解,因為當基數變大時,Merge 程序中轉換矩陣會變得很大,轉換矩陣的 Apply 的程序就會變成一個新的瓶頸點,解決這一問題的只有 Fall back 方案,即將高基數列自動不做字典編碼,
Fall back 方案在內部做了很多討論,也跟原作者討論了可能的實作方案,
最終通過 LowCardinality 內部封裝的方式實作,如下圖所示:
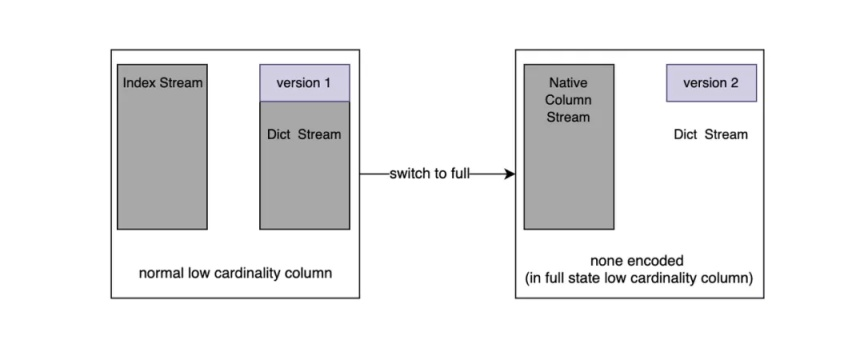
Stream 可以理解為檔案流,通過 Version 值標識該列是否是已經是 Fall back 的列,
內部復用了 Index Stream,如果發生了 Fall back 那么這個 Stream 里面的值便是原始列的值,Fall back 可以發生在實時寫入程序中和 Part Merge 程序中,如果此列發生了 Fall back 后續的所有 Part 都將是 Fall back 的,
Fall back 后,一個高基數列的 Merge 速度和存盤性能對比,連續寫入 1 億條記錄的統計:

從表中可以看出,Fall back 后的列基本跟原始列性能接近,至少保證 Merge 和存盤性能沒有退化,如果不做 Fall back,存盤空間占用會比原始列還要多,Merge 性能無法支撐實時寫入,
通過 Merge 優化和自動 Fall back 解決了 LowCardinality 列的兩大絆腳石,接下來看下我們在內部一些大應用上的測驗驗證效果,
性能驗證
下面是在內部某些大 APP 上的驗證結果,
1、磁盤占用
資料表是內部某些 APP 某個時間段的資料,
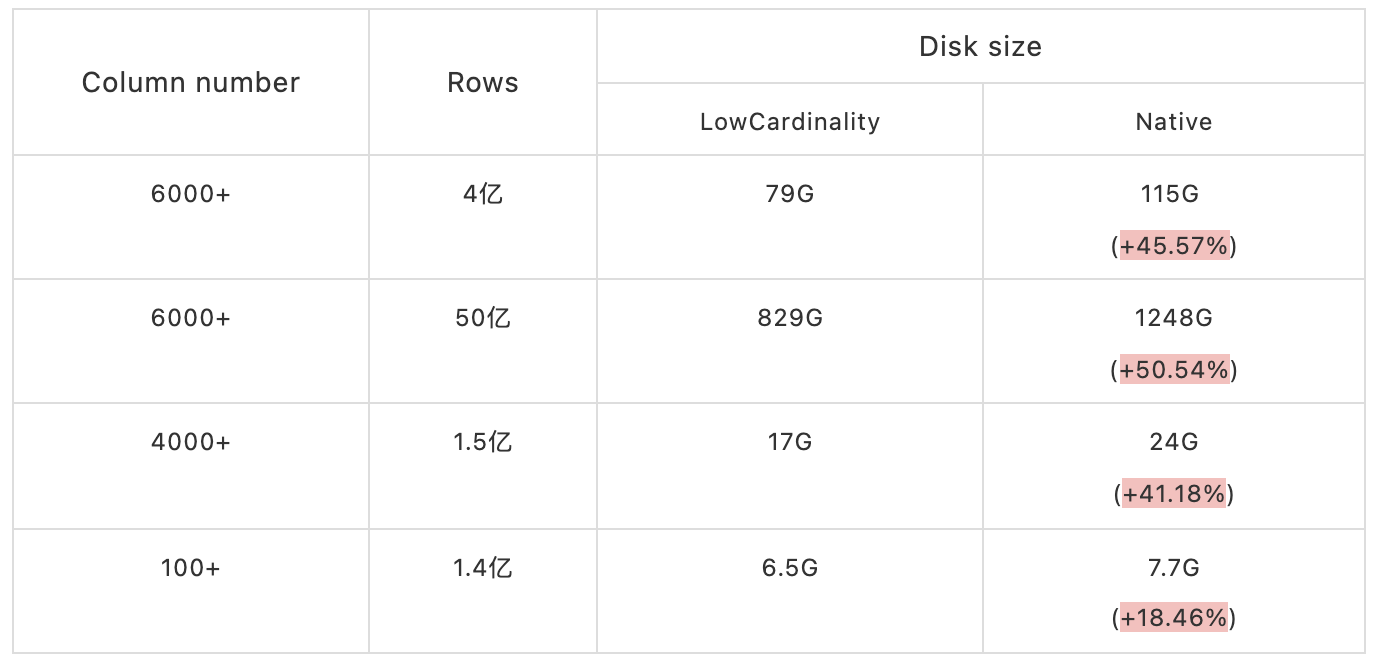
從上表中可以看出,列越多,資料量越大,存盤空間下降就會越明顯,最高可以節省一半的資料存盤空間,在資料量非常的大 APP 場景下,上線 LowCardinality 后可以節省大量的存盤資源,
2、針對某個 APP,獲取其典型的 10 個業務 SQL,做查詢性能測驗,
下面是兩個資料表分別查詢的對比測驗結果:
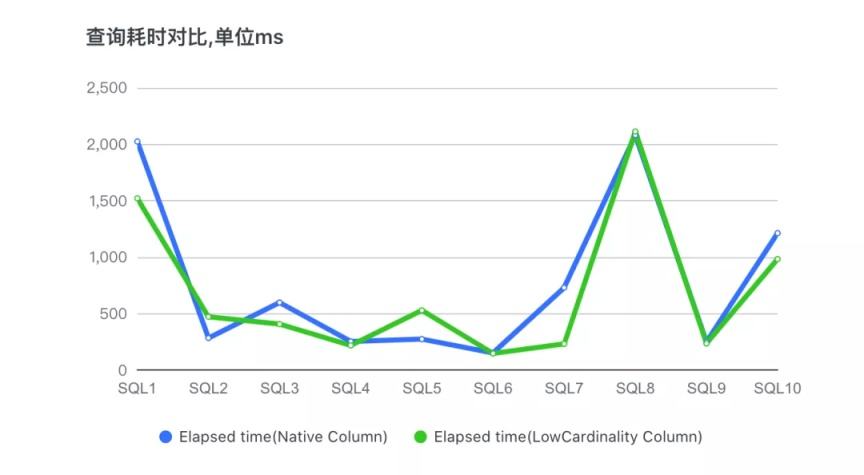
從上圖可以看出,有兩個 SQL 導致查詢性能有回退現象,其余 SQL 都是 LowCardinality 的表查詢性能更優,耗時更短,
3、10 個查詢對應的磁盤資料讀取量:
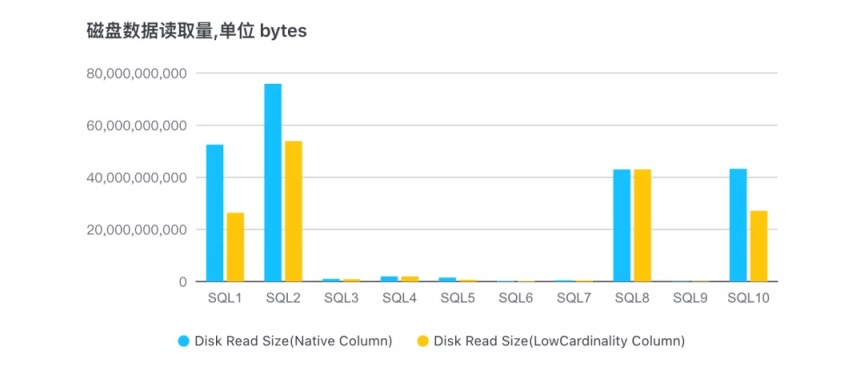
可以看出,基本上所有 SQL 讀取的資料量都有明顯的減少,對磁盤 IO 的壓力會降低很多,SQL8 對應的查詢列已經做了 Fall back,所以跟原始列讀取資料量持平,
下圖是查詢時對應的記憶體使用量:
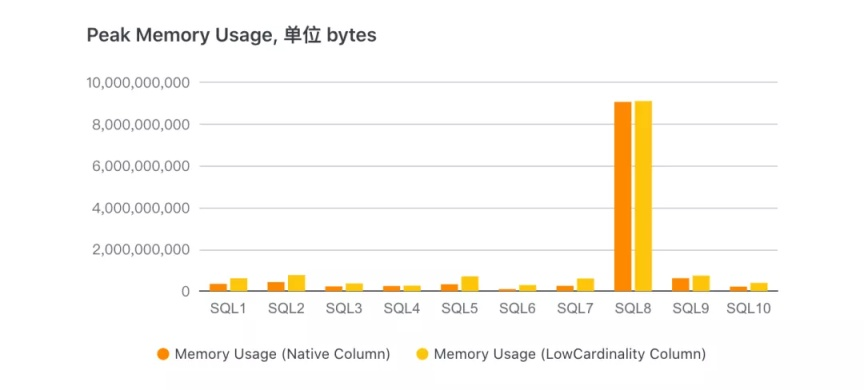
其中除了 SQL8 發生了 Fall back 外,其他查詢均是 LowCardinlity 表記憶體使用量較大,由于 LowCardinality 列計算程序中,如 filter,需要讀取的 Part 字典并將列反解出來,每個 Part 的字典是獨立存在的,這樣在計算程序中會多占用些記憶體,這塊也是后續優化的重點,
小結
目前 ClickHouse UBA 版已經全面啟用了字典編碼列,并且在火山引擎增長分析(DataFinder)服務的多個客戶環境中已經上線,
從實踐反饋看,我們為客戶節省了大量存盤資源,同時在大多數場景下查詢性能也有提升明顯,總體上由于字典位于每個 Part 中獨立存盤,查詢程序中無法做到在壓縮域直接計算,因而會造成個別場景下查詢性能不佳,并且記憶體使用量上會增加,
下一步作業的重點將是優化 LowCardinality 的計算程序,例如把字典做成 Part 間共享的,可以減少計算程序中記憶體占用,進一步擴展復雜場景在可以直接在壓縮域做計算,
參考文獻
https://github.com/yandex/clickhouse-presentations/raw/master/meetup19/string_optimization.pdf
https://clickhouse.com/docs/en/sql-reference/data-types/lowcardinality/
火山引擎增長分析
一站式用戶分析與運營平臺,為企業提供數字化消費者行為分析洞見,優化數字化觸點、用戶體驗,支撐精細化用戶運營,發現業務的關鍵增長點,提升企業效益,
歡迎關注同名公眾號「位元組跳動資料平臺」
轉載請註明出處,本文鏈接:https://www.uj5u.com/qita/423588.html
標籤:其他
上一篇:虎年開工大吉
下一篇:資料結構 - 陣列