目錄
- 前言
- 1.基本概念
- 1.1 連續值
- 1.2 離散值
- 1.3 簡單線性回歸
- 1.4 基本名詞的定義
- 1.5 多元線性回歸
- 2.正規方程
- 2.1 最小二乘法的矩陣表示
- 2.2 多元一次方程舉例
- 2.2.1 二元一次方程
- 2.2.2 三元一次方程
- 2.2.3 八元一次方程
- 2.2.4 s k l e a r n sklearn sklearn 演算法使用
- 2.2.5 帶截距的線性方程
- 2.2.5.1 增加截距 12 12 12
- 2.2.5.2 修改資料 X X X
- 2.3 矩陣轉置公式與求導公式
- 2.4 推導正規方程 θ \theta θ 的解
- 2.5 凸函式判定
前言
本文屬于 線性回歸演算法【AIoT階段三】(尚未更新),這里截取自其中一段內容,方便讀者理解和根據需求快速閱讀,
線性回歸是機器學習中有監督機器學習下的一種演算法, 回歸問題主要關注的是因變數(需要預測的值,可以是一個也可以是多個)和一個或多個數值型的自變數(預測變數)之間的關系,
需要預測的值:即目標變數,target,y,連續值預測變數,
影響目標變數的因素: X 1 X_1 X1?… X n X_n Xn?,可以是連續值也可以是離散值,
因變數和自變數之間的關系:即模型,model,是我們要求解的,
1.基本概念
1.1 連續值
🚩連續值就是連續的一連串數字,是可以無限細分下去的一段,比如我們的身高,你可以說你身高在
175
175
175至
185
185
185,繼續細分下去也是可以的,你甚至可以說你的身高在
175.003
175.003
175.003 至
182.231
182.231
182.231 甚至繼續下分下去也沒可以的,這就被稱為是連續值,

1.2 離散值
🚩離散值就是單個孤立的點,比如我國共計34個省級行政區,我們絕不可以說成我國共計34.3個省級行政區,或者是33.6個省級行政區,必須是 34 整個,這就是離散值,
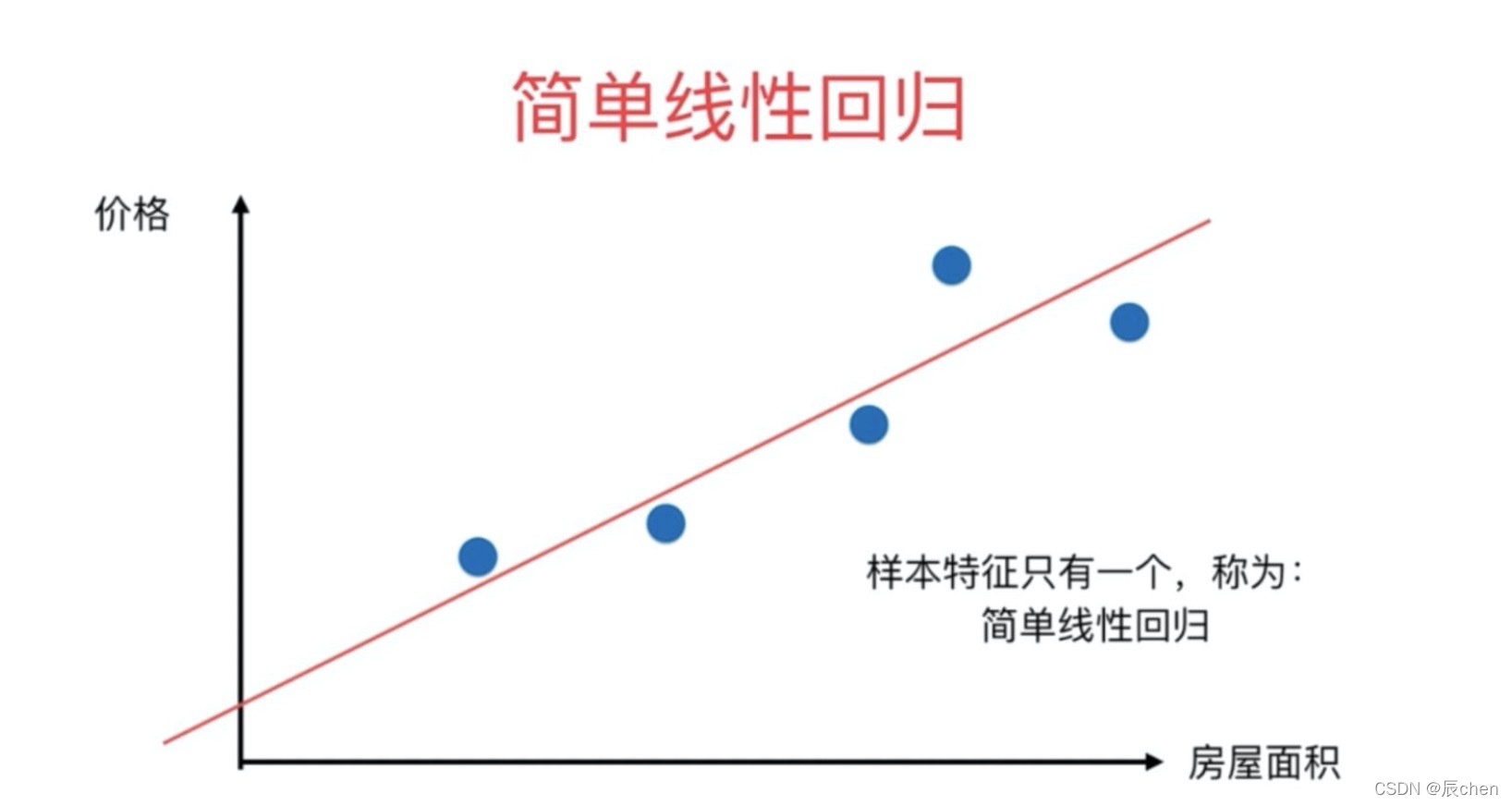
1.3 簡單線性回歸
🚩什么是演算法?研究演算法說白了還是在研究公式,簡單線性回歸屬于一個演算法,它所對應的公式: y = w x + b y = wx + b y=wx+b,這個公式中, y y y 是目標變數即未來要預測的值, x x x 是影響 y y y 的因素, w , b w,b w,b 是公式上的引數即要求的模型,其實 b b b 就是咱們的截距, w w w 就是斜率嘛! 所以很明顯如果模型求出來了,未來影響 y y y 值的未知數就是一個 x x x 值,也可以說影響 y y y 值 的因素只有一個,所以這是就叫簡單線性回歸的原因,如下圖所表示的直線,就是一個簡單線性回歸的意思:
1.4 基本名詞的定義
A c t u a l v a l u e Actual value Actualvalue:真實值,一般使用 y y y 表示,
P r e d i c t e d v a l u e Predicted value Predictedvalue:預測值,是把已知的 x x x 帶入到公式里面和猜出來的引數 w , b w,b w,b 計算得到的,一般使用 y ^ \hat{y} y^? 表示,
E r r o r Error Error:誤差,預測值和真實值的差距,一般使用 ε \varepsilon ε 表示
最優解:盡可能的找到一個模型使得整體的誤差最小,整體的誤差通常叫做損失 L o s s Loss Loss
L o s s Loss Loss:整體的誤差, L o s s Loss Loss 通過損失函式 L o s s Loss Loss f u n c t i o n function function 計算得到,
1.5 多元線性回歸
🚩多元線性回歸無非就是比簡單線性回歸變得: 多元,所謂多元,就是在某些情況下,影響結果
y
y
y 的因素不止有一個,比如我們在預測股票的時候,國家的政策起到影響作用,國民的經濟也是影響因素,甚至他國的經濟政策也會影響到我們,等等等等有諸多原因,為此,僅僅一個變數
x
x
x 就顯得不夠用了,這時,我們的
x
x
x 就從
1
1
1 個變成了
n
n
n 個:
X
1
X_1
X1?…
X
n
X_n
Xn?, 同時簡單線性回歸的公式也就不在適用了,多元線性回歸公式如下:
y
^
=
w
1
X
1
+
w
2
X
2
+
…
…
+
w
n
X
n
+
b
\hat{y} = w_1X_1 + w_2X_2 + …… + w_nX_n + b
y^?=w1?X1?+w2?X2?+……+wn?Xn?+b
b是截距,也可以使用 w 0 w_0 w0?來表示
y ^ = w 1 X 1 + w 2 X 2 + … … + w n X n + w 0 \hat{y} = w_1X_1 + w_2X_2 + …… + w_nX_n + w_0 y^?=w1?X1?+w2?X2?+……+wn?Xn?+w0?
y ^ = w 1 X 1 + w 2 X 2 + … … + w n X n + w 0 ? 1 \hat{y} = w_1X_1 + w_2X_2 + …… + w_nX_n + w_0 * 1 y^?=w1?X1?+w2?X2?+……+wn?Xn?+w0??1
使用向量來表示, X X X表示所有的變數,是一維向量; w w w 表示所有的系數(包含 w 0 w_0 w0?),是一維向量,根據向量乘法規律,可以這么寫: y ^ = W T X \hat{y} = W^TX y^?=WTX
y ^ = ∣ w 1 w 2 . . . w n w 0 ∣ ? ∣ X 1 X 2 . . . X n 1 ∣ \hat{y} =\left|\begin{matrix}w_1 \\ w_2 \\ ... \\ w_n \\ w_0 \end{matrix}\right| *\left|\begin{matrix}X_1 & X_2 & ... & X_n & 1 \end{matrix}\right| y^?=∣∣∣∣∣∣∣∣∣∣?w1?w2?...wn?w0??∣∣∣∣∣∣∣∣∣∣??∣∣?X1??X2??...?Xn??1?∣∣?
2.正規方程
2.1 最小二乘法的矩陣表示
🚩最小二乘法可以將誤差方程轉化為有確定解的代數方程組(其方程式數目正好等于未知數的個數),從而可求解出這些未知引數,這個有確定解的代數方程組稱為最小二乘法估計的正規方程,公式如下:
θ
=
(
X
T
X
)
?
1
X
T
y
\theta = (X^TX)^{-1}X^Ty
θ=(XTX)?1XTy 或者
W
=
(
X
T
X
)
?
1
X
T
y
W = (X^TX)^{-1}X^Ty
W=(XTX)?1XTy ,其中的
W
、
θ
W、\theta
W、θ 即使方程的解!
公式是如何推導的在 2.4 推導正規方程
θ
\theta
θ 的解 中進行詳細講解,
最小二乘法公式如下:
J
(
θ
)
=
1
2
∑
i
=
0
n
(
h
θ
(
x
i
)
?
y
i
)
2
J(\theta) = \frac{1}{2}\sum\limits_{i = 0}^n(h_{\theta}(x_i) - y_i)^2
J(θ)=21?i=0∑n?(hθ?(xi?)?yi?)2
使用矩陣表示:
J ( θ ) = 1 2 ∑ i = 0 n ( h θ ( x i ) ? y ) ( h θ ( x i ) ? y ) J(\theta) = \frac{1}{2}\sum\limits_{i = 0}^n(h_{\theta}(x_i) - y)(h_{\theta}(x_i) - y) J(θ)=21?i=0∑n?(hθ?(xi?)?y)(hθ?(xi?)?y)
J ( θ ) = 1 2 ( X θ ? y ) T ( X θ ? y ) J(\theta) = \frac{1}{2}(X\theta - y)^T(X\theta - y) J(θ)=21?(Xθ?y)T(Xθ?y)
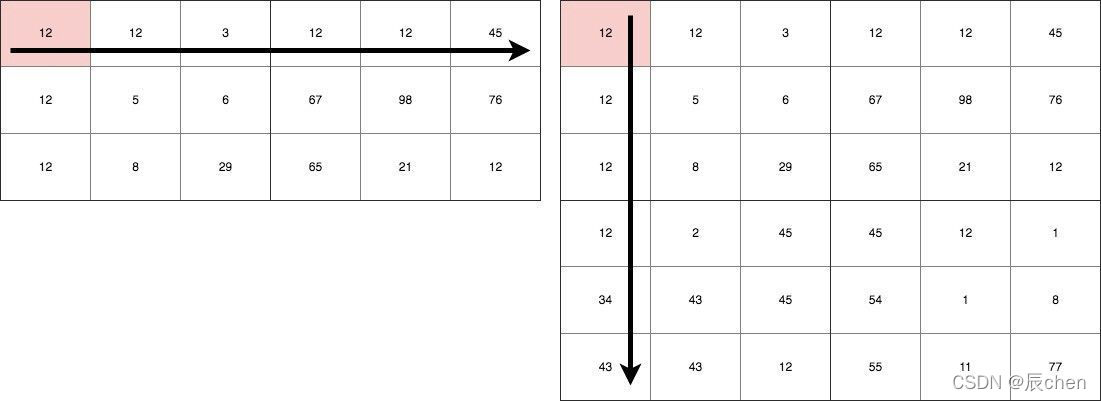
之所以要使用轉置 T T T,是因為,矩陣運算規律是:矩陣 A A A 的一行乘以矩陣 B B B 的一列!
2.2 多元一次方程舉例
2.2.1 二元一次方程
{ x + y = 14 2 x ? y = 10 \begin{cases} x + y=14\\ 2x - y = 10\\ \end{cases} {x+y=142x?y=10?
import numpy as np
import matplotlib.pyplot as plt
X = np.array([[1, 1],
[2, -1]])
y = np.array([14, 10])
# linalg 線性代數,solve計算線性回歸問題
np.linalg.solve(X, y)

我們來根據上述中的正規方程來計算一下: W = ( X T X ) ? 1 X T y W = (X^TX)^{-1}X^Ty W=(XTX)?1XTy:
A = X.T.dot(X)
B = np.linalg.inv(A) ## 求逆矩陣
C = B.dot(X.T)
C.dot(Y)
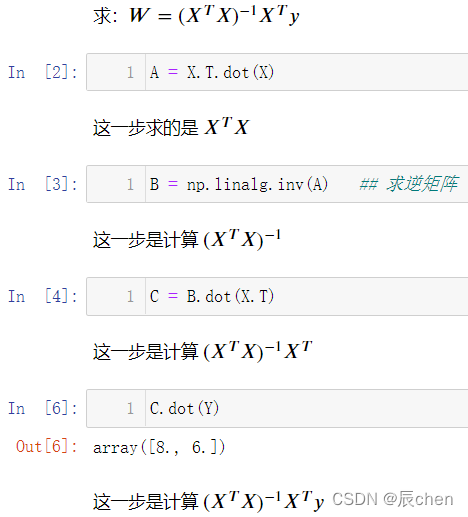
可以發現,我們使用正規方程可以同樣有效的進行計算,我們再來舉幾個例子
2.2.2 三元一次方程
{ x ? y + z = 100 2 x + y ? z = 80 3 x ? 2 y + 6 z = 256 \begin{cases} x - y + z = 100\\ 2x + y -z = 80\\ 3x - 2y + 6z = 256\\ \end{cases} ??????x?y+z=1002x+y?z=803x?2y+6z=256?
import numpy as np
import matplotlib.pyplot as plt
X = np.array([[1, -1, 1],
[2, 1, -1],
[3, -2, 6]])
y = np.array([100, 80, 256])
# 根據正規方程進行計算:
W = np.linalg.inv(X.T.dot(X)).dot(X.T).dot(y)
W

2.2.3 八元一次方程
{ 14 x 2 + 8 x 3 + 5 x 5 + ? 2 x 6 + 9 x 7 + ? 3 x 8 = 339 ? 4 x 1 + 10 x 2 + 6 x 3 + 4 x 4 + ? 14 x 5 + ? 2 x 6 + ? 14 x 7 + 8 x 8 = ? 114 ? 1 x 1 + ? 6 x 2 + 5 x 3 + ? 12 x 4 + 3 x 5 + ? 3 x 6 + 2 x 7 + ? 2 x 8 = 30 5 x 1 + ? 2 x 2 + 3 x 3 + 10 x 4 + 5 x 5 + 11 x 6 + 4 x 7 + ? 8 x 8 = 126 ? 15 x 1 + ? 15 x 2 + ? 8 x 3 + ? 15 x 4 + 7 x 5 + ? 4 x 6 + ? 12 x 7 + 2 x 8 = ? 395 11 x 1 + ? 10 x 2 + ? 2 x 3 + 4 x 4 + 3 x 5 + ? 9 x 6 + ? 6 x 7 + 7 x 8 = ? 87 ? 14 x 1 + 4 x 3 + ? 3 x 4 + 5 x 5 + 10 x 6 + 13 x 7 + 7 x 8 = 422 ? 3 x 1 + ? 7 x 2 + ? 2 x 3 + ? 8 x 4 + ? 6 x 6 + ? 5 x 7 + ? 9 x 8 = ? 309 \begin{cases}&14x_2 + 8x_3 + 5x_5 + -2x_6 + 9x_7 + -3x_8 = 339\\&-4x_1 + 10x_2 + 6x_3 + 4x_4 + -14x_5 + -2x_6 + -14x_7 + 8x_8 = -114\\&-1x_1 + -6x_2 + 5x_3 + -12x_4 + 3x_5 + -3x_6 + 2x_7 + -2x_8 = 30\\&5x_1 + -2x_2 + 3x_3 + 10x_4 + 5x_5 + 11x_6 + 4x_7 + -8x_8 = 126\\&-15x_1 + -15x_2 + -8x_3 + -15x_4 + 7x_5 + -4x_6 + -12x_7 + 2x_8 = -395\\&11x_1 + -10x_2 + -2x_3 + 4x_4 + 3x_5 + -9x_6 + -6x_7 + 7x_8 = -87\\&-14x_1 + 4x_3 + -3x_4 + 5x_5 + 10x_6 + 13x_7 + 7x_8 = 422\\&-3x_1 + -7x_2 + -2x_3 + -8x_4 + -6x_6 + -5x_7 + -9x_8 = -309\end{cases} ???????????????????????????????14x2?+8x3?+5x5?+?2x6?+9x7?+?3x8?=339?4x1?+10x2?+6x3?+4x4?+?14x5?+?2x6?+?14x7?+8x8?=?114?1x1?+?6x2?+5x3?+?12x4?+3x5?+?3x6?+2x7?+?2x8?=305x1?+?2x2?+3x3?+10x4?+5x5?+11x6?+4x7?+?8x8?=126?15x1?+?15x2?+?8x3?+?15x4?+7x5?+?4x6?+?12x7?+2x8?=?39511x1?+?10x2?+?2x3?+4x4?+3x5?+?9x6?+?6x7?+7x8?=?87?14x1?+4x3?+?3x4?+5x5?+10x6?+13x7?+7x8?=422?3x1?+?7x2?+?2x3?+?8x4?+?6x6?+?5x7?+?9x8?=?309?
import numpy as np
import matplotlib.pyplot as plt
X = np.array([[0, 14, 8, 0, 5, -2, 9, -3],
[-4, 10, 6, 4, -14, -2, -14, 8],
[-1, -6, 5, -12, 3, -3, 2, -2],
[5, -2, 3, 10, 5, 11, 4, -8],
[-15, -15, -8, -15, 7, -4, -12, 2],
[11, -10, -2, 4, 3, -9, -6, 7],
[-14, 0, 4, -3, 5, 10, 13, 7],
[-3, -7, -2, -8, 0, -6, -5, -9]])
y = np.array([339, -114, 30, 126, -395, -87, 422, -309])
# 根據正規方程進行計算:
W = np.linalg.inv(X.T.dot(X)).dot(X.T).dot(y)
W

2.2.4 s k l e a r n sklearn sklearn 演算法使用
🚩沒有安裝這個包的同學在命令列中輸入:pip install sklearn 即可,如果你看過博文:最詳細的Anaconda Installers 的安裝【numpy,jupyter】(圖+文) 或者 資料分析三劍客【AIoT階段一(下)】(十萬字博文 保姆級講解),那么這一步可省略:在安裝
j
u
p
y
t
e
r
jupyter
jupyter 的時候已經安裝完成,如果你沒有設定以 清華源 為地址進行下載會很慢,配置默認下載從 清華源 下載可見博文:matplotlib的安裝教程以及簡單呼叫
下面還是來計算我們上述的八元一次方程組:
# linear:線性 model:模型、演算法
# LinearRegression: 線性回歸
from sklearn.linear_model import LinearRegression
import numpy as np
import matplotlib.pyplot as plt
model = LinearRegression()
X = np.array([[0, 14, 8, 0, 5, -2, 9, -3],
[-4, 10, 6, 4, -14, -2, -14, 8],
[-1, -6, 5, -12, 3, -3, 2, -2],
[5, -2, 3, 10, 5, 11, 4, -8],
[-15, -15, -8, -15, 7, -4, -12, 2],
[11, -10, -2, 4, 3, -9, -6, 7],
[-14, 0, 4, -3, 5, 10, 13, 7],
[-3, -7, -2, -8, 0, -6, -5, -9]])
y = np.array([339, -114, 30, 126, -395, -87, 422, -309])
# X:資料 y:目標值
model.fit(X, y)
# coef_ : 結果、回傳值
# 就是指方程的解、W、系數、斜率
model.coef_
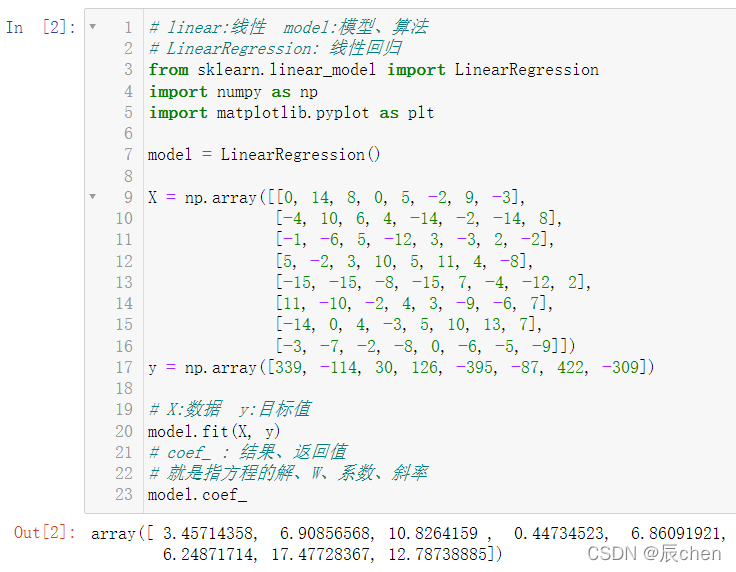
我們發現,運行結果和我們用正規方程計算出來的不一樣,這是因為在代碼:
model = LinearRegression()
有一個引數叫做:intercept_,意為截距,即我們呼叫
s
k
l
e
a
r
n
sklearn
sklearn 自動計算了截距:
# 默認計算截距
model.intercept_

但其實我們的八元一次方程是沒有截距的,故我們在代碼改為如下即可:
model = LinearRegression(fit_intercept = False)
完整代碼:
# linear:線性 model:模型、演算法
# LinearRegression: 線性回歸
from sklearn.linear_model import LinearRegression
import numpy as np
import matplotlib.pyplot as plt
model = LinearRegression(fit_intercept = False)
X = np.array([[0, 14, 8, 0, 5, -2, 9, -3],
[-4, 10, 6, 4, -14, -2, -14, 8],
[-1, -6, 5, -12, 3, -3, 2, -2],
[5, -2, 3, 10, 5, 11, 4, -8],
[-15, -15, -8, -15, 7, -4, -12, 2],
[11, -10, -2, 4, 3, -9, -6, 7],
[-14, 0, 4, -3, 5, 10, 13, 7],
[-3, -7, -2, -8, 0, -6, -5, -9]])
y = np.array([339, -114, 30, 126, -395, -87, 422, -309])
# X:資料 y:目標值
model.fit(X, y)
# coef_ : 結果、回傳值
# 就是指方程的解、W、系數、斜率
model.coef_
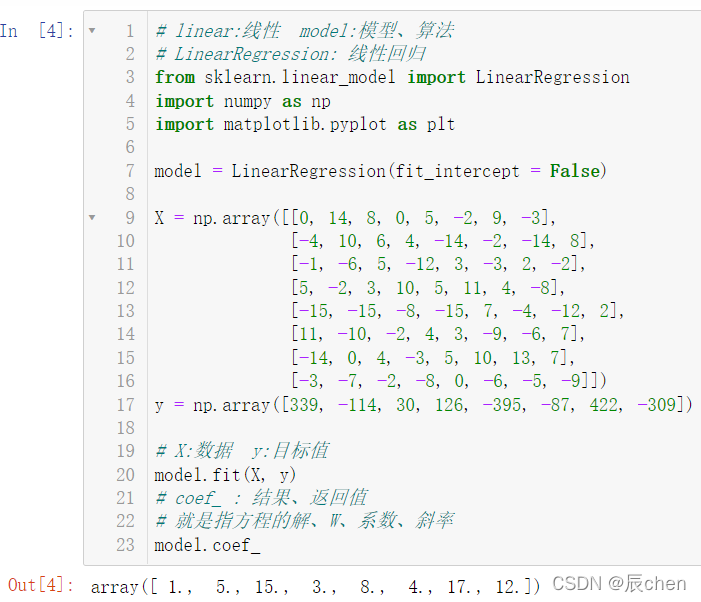
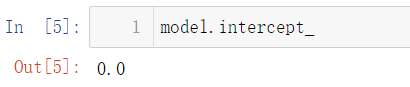
此時我們再來計算一下截距:
model.intercept_
2.2.5 帶截距的線性方程
2.2.5.1 增加截距 12 12 12
🚩上述八元一次方程的解其實就是:
f
(
x
)
=
x
1
+
5
x
2
+
15
x
3
+
3
x
4
+
8
x
5
+
4
x
6
+
17
x
7
+
12
x
8
{f(x)=x_1+5x_2+15x_3+3x_4+8x_5+4x_6+17x_7+12x_8}
f(x)=x1?+5x2?+15x3?+3x4?+8x5?+4x6?+17x7?+12x8?
現在我們不妨讓上式加上一個任意常數,比如
12
12
12,
那么方程的解就變成了:
f
(
x
)
=
x
1
+
5
x
2
+
15
x
3
+
3
x
4
+
8
x
5
+
4
x
6
+
17
x
7
+
12
x
8
+
12
{f(x)=x_1+5x_2+15x_3+3x_4+8x_5+4x_6+17x_7+12x_8+12}
f(x)=x1?+5x2?+15x3?+3x4?+8x5?+4x6?+17x7?+12x8?+12
那么顯然我們的
y
y
y 要發生改變,即對于
y
y
y 中的每一個元素都要加上
12
12
12:這時,因為有了截距,我們就需要讓 intercept 置為 True:
y = y + 12
display(y)
model = LinearRegression(fit_intercept = True)
# fit:健身,訓練;特質演算法、模型訓練,擬合
# 資料 X 和 y 之間存在規律,擬合出來,找到規律
model.fit(X, y)
b_ = model.intercept_
print('截距是:', b_)
w_ = model.coef_
print('斜率是:', w_)
print('方程的解為:', X.dot(w_) + b_)
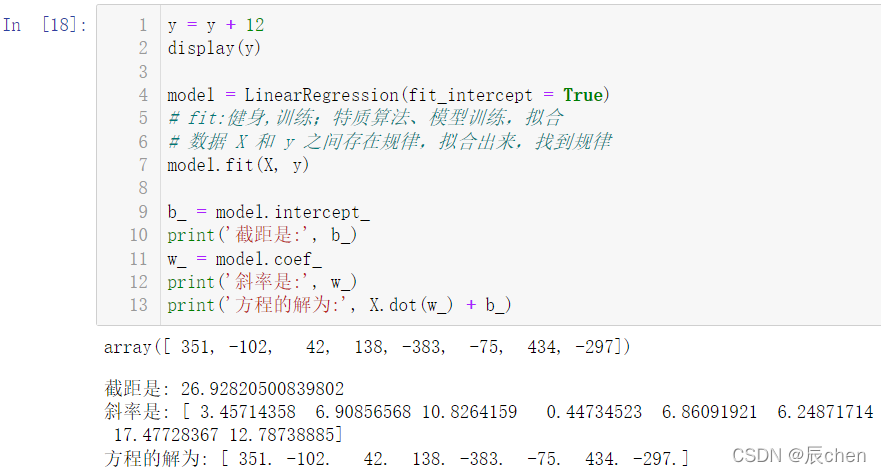
我們可以看出,求出來的截距雖然不是我們加上的
12
12
12,斜率也不是我們之前求過的解,但是這兩個結合起來確確實實是方程的解,

求出的不是我們期望的結果,但是是符合題意的結果,這是因為,一旦我們規定了 fit_intercept = True,那么在計算機進行解方程的時候,就不會使用正規方程去進行運算
2.2.5.2 修改資料 X X X
🚩我們根據 1.5 多元線性回歸 所講過的對 X X X 進行修改:即給 X X X 所代表的矩陣中在最后一列的位置增加一個 1 1 1:
X = np.concatenate([X, np.full(shape = (8, 1), fill_value = 1)], axis = 1)
display(X, y)

那么這個資料,相比較與最開始的八元一次方程,我們讓 X X X 增加了一列, y y y 增加了 12 12 12,那么接下來進行正規方程的計算:
model = LinearRegression(fit_intercept = False)
model.fit(X, y)
display(model.coef_, model.intercept_)

我們發現和我們的預期還是相差甚遠,我們期望的是計算截距為 12 12 12,斜率為: a r r a y ( [ 1. , 5. , 15. , 3. , 8. , 4. , 17. , 12. ] ) array([ 1., 5., 15., 3., 8., 4., 17., 12.]) array([1.,5.,15.,3.,8.,4.,17.,12.]),但是為什么出現了這么大的誤差呢?我們再來用 W = ( X T X ) ? 1 X T y W = (X^TX)^{-1}X^Ty W=(XTX)?1XTy 計算一下正規方程:
W = np.linalg.inv(X.T.dot(X)).dot(X.T).dot(y)
W

可以看出即使是使用我們推匯出的正規方程也和我們期待的相差甚遠,我們來查看一下此時的 X X X
X.shape
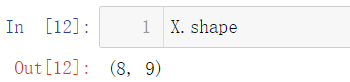
這意味著,我們有八個方程,但是我們有九個未知數,顯然,對于這樣的一個方程組,我們并非只有一組解,而是有無窮多組解,這也是我們產生偏差的原因,
你或許有疑問,既然有無窮多組解,那么每次運行的結果應該是不同的,為什么對于正規方程每次運行的結果確實相同的:這是因為演算法會默認給我們算出一個 最優解,所以我們要有唯一解,就需要我們人為的添加一個方程:
# w就是標準的解
w = np.array([ 1., 5., 15., 3., 8., 4., 17., 12.])
# 造一個方程出來
X9 = np.random.randint(-15, 15, size = 8)
display(X9)

接下來對于這個方程我們按照增加 12 12 12 截距和修改資料的方法來改變這個方程:
# 上面的8個方程,都有截距12,第九個方程也是如此
X9.dot(w) + 12
y = np.concatenate([y, [X9.dot(w) + 12]])
y
X9 = np.concatenate([X9, [1]])
X9
X = np.concatenate([X, [X9]])
X
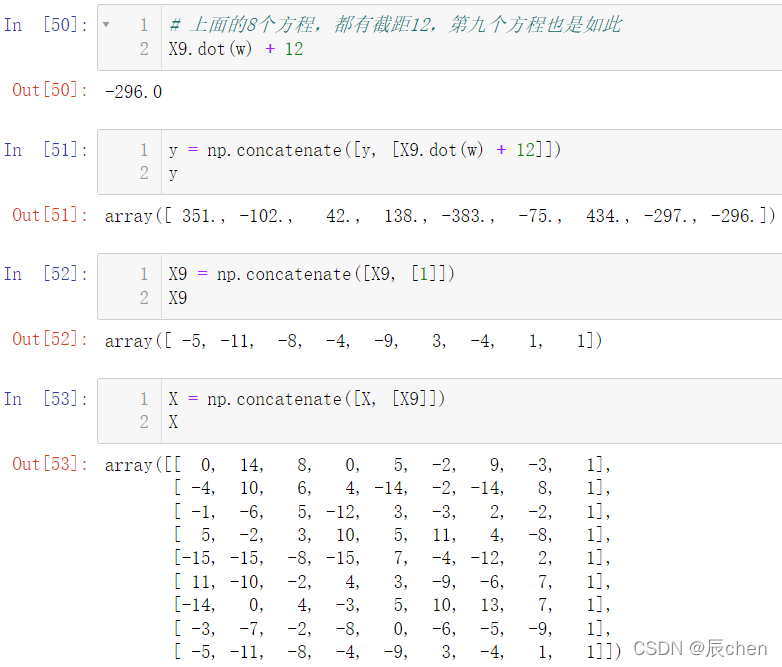
以上操作后我們就處理好了 X X X 和 y y y,那么接下來,就是見證奇跡的時刻:
# 計算正規方程
np.linalg.inv(X.T.dot(X)).dot(X.T).dot(y)

使用線性回歸:
model = LinearRegression(fit_intercept = False)
model.fit(X, y)
display(model.coef_)

那么這還是有些區別,因為我們想要的是截距以及斜率,但是此時我們只有斜率,故我們可以把 fit_intercept 設定為 True:
model = LinearRegression(fit_intercept = True)
model.fit(X, y)
display(model.coef_, model.intercept_)

截距是不是離我們的真實值特別靠近啦,此時我們只需要進行四舍五入即可,對于值為
0
0
0 的解,即我們自定義出來的
X
9
X_9
X9?,
0
0
0 代表其沒有權重,故我們可以舍去它
model = LinearRegression(fit_intercept = True)
model.fit(X[:,:-1], y)
display(model.coef_, model.intercept_.round())

蕪湖!大功告成!!!
2.3 矩陣轉置公式與求導公式
轉置公式如下:
-
( m A ) T = m A T (mA)^T = mA^T (mA)T=mAT,其中m是常數
-
( A + B ) T = A T + B T (A + B)^T = A^T + B^T (A+B)T=AT+BT
-
( A B ) T = B T A T (AB)^T = B^TA^T (AB)T=BTAT
-
( A T ) T = A (A^T)^T = A (AT)T=A
求導公式如下:
- ? X T ? X = I \frac{\partial X^T}{\partial X} = I ?X?XT?=I 求解出來是單位矩陣
- ? X T A ? X = A \frac{\partial X^TA}{\partial X} = A ?X?XTA?=A
- ? A X T ? X = A \frac{\partial AX^T}{\partial X} = A ?X?AXT?=A
- ? A X ? X = A T \frac{\partial AX}{\partial X} = A^T ?X?AX?=AT
- ? X A ? X = A T \frac{\partial XA}{\partial X} = A^T ?X?XA?=AT
- ? X T A X ? X = ( A + A T ) X ; \frac{\partial X^TAX}{\partial X} = (A + A^T)X; ?X?XTAX?=(A+AT)X; A不是對稱矩陣
- ? X T A X ? X = 2 A X ; \frac{\partial X^TAX}{\partial X} = 2AX; ?X?XTAX?=2AX; A是對稱矩陣
2.4 推導正規方程 θ \theta θ 的解
- 矩陣乘法公式展開
-
J ( θ ) = 1 2 ( X θ ? y ) T ( X θ ? y ) J(\theta) = \frac{1}{2}(X\theta - y)^T(X\theta - y) J(θ)=21?(Xθ?y)T(Xθ?y)
-
J ( θ ) = 1 2 ( θ T X T ? y T ) ( X θ ? y ) J(\theta) = \frac{1}{2}(\theta^TX^T - y^T)(X\theta - y) J(θ)=21?(θTXT?yT)(Xθ?y)
-
J ( θ ) = 1 2 ( θ T X T X θ ? θ T X T y ? y T X θ + y T y ) J(\theta) = \frac{1}{2}(\theta^TX^TX\theta - \theta^TX^Ty -y^TX\theta + y^Ty) J(θ)=21?(θTXTXθ?θTXTy?yTXθ+yTy)
- 進行求導(注意X、y是已知量, θ \theta θ 是未知數):
- J ′ ( θ ) = 1 2 ( θ T X T X θ ? θ T X T y ? y T X θ + y T y ) ′ J'(\theta) = \frac{1}{2}(\theta^TX^TX\theta - \theta^TX^Ty -y^TX\theta + y^Ty)' J′(θ)=21?(θTXTXθ?θTXTy?yTXθ+yTy)′
- 根據上面求導公式進行運算:
- J ′ ( θ ) = 1 2 ( X T X θ + ( θ T X T X ) T ? X T y ? ( y T X ) T ) J'(\theta) = \frac{1}{2}(X^TX\theta + (\theta^TX^TX)^T-X^Ty - (y^TX)^T) J′(θ)=21?(XTXθ+(θTXTX)T?XTy?(yTX)T)
- J ′ ( θ ) = 1 2 ( X T X θ + X T X θ ? X T y ? X T y ) J'(\theta) = \frac{1}{2}(X^TX\theta + X^TX\theta -X^Ty - X^Ty) J′(θ)=21?(XTXθ+XTXθ?XTy?XTy)
- J ′ ( θ ) = 1 2 ( 2 X T X θ ? 2 X T y ) J'(\theta) = \frac{1}{2}(2X^TX\theta -2X^Ty) J′(θ)=21?(2XTXθ?2XTy)
- J ′ ( θ ) = X T X θ ? X T y J'(\theta) =X^TX\theta -X^Ty J′(θ)=XTXθ?XTy
- J ′ ( θ ) = X T ( X θ ? y ) J'(\theta) =X^T(X\theta -y) J′(θ)=XT(Xθ?y) 矩陣運算分配律
- 令導數 J ′ ( θ ) = 0 : J'(\theta) = 0: J′(θ)=0:
-
0 = X T X θ ? X T y 0 =X^TX\theta -X^Ty 0=XTXθ?XTy
-
X T X θ = X T y X^TX\theta = X^Ty XTXθ=XTy
- 矩陣沒有除法,使用逆矩陣進行轉化:
- ( X T X ) ? 1 X T X θ = ( X T X ) ? 1 X T y (X^TX)^{-1}X^TX\theta = (X^TX)^{-1}X^Ty (XTX)?1XTXθ=(XTX)?1XTy
- I θ = ( X T X ) ? 1 X T y I\theta = (X^TX)^{-1}X^Ty Iθ=(XTX)?1XTy
- θ = ( X T X ) ? 1 X T y \theta = (X^TX)^{-1}X^Ty θ=(XTX)?1XTy
到此為止,公式推匯出來了~

2.5 凸函式判定
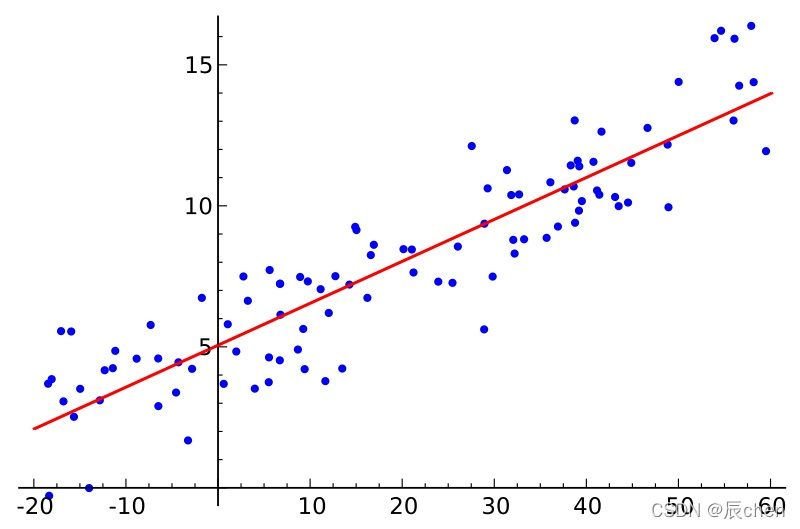
🚩判定損失函式是凸函式的好處在于我們可能很肯定的知道我們求得的極值即最優解,一定是全域最優解,
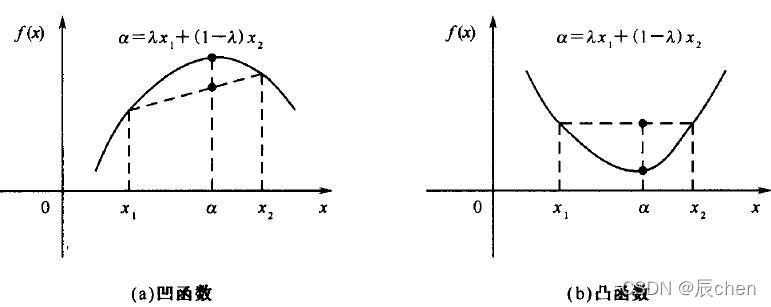
如果是非凸函式,那就不一定可以獲取全域最優解,如下圖:
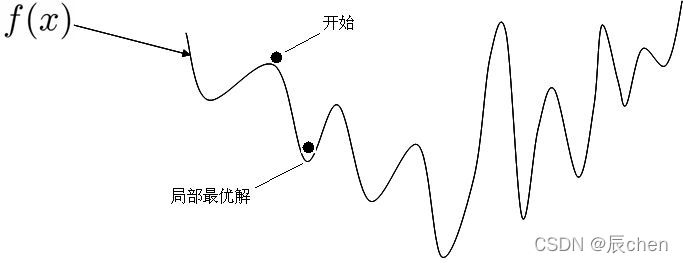
來一個更加立體的效果圖:
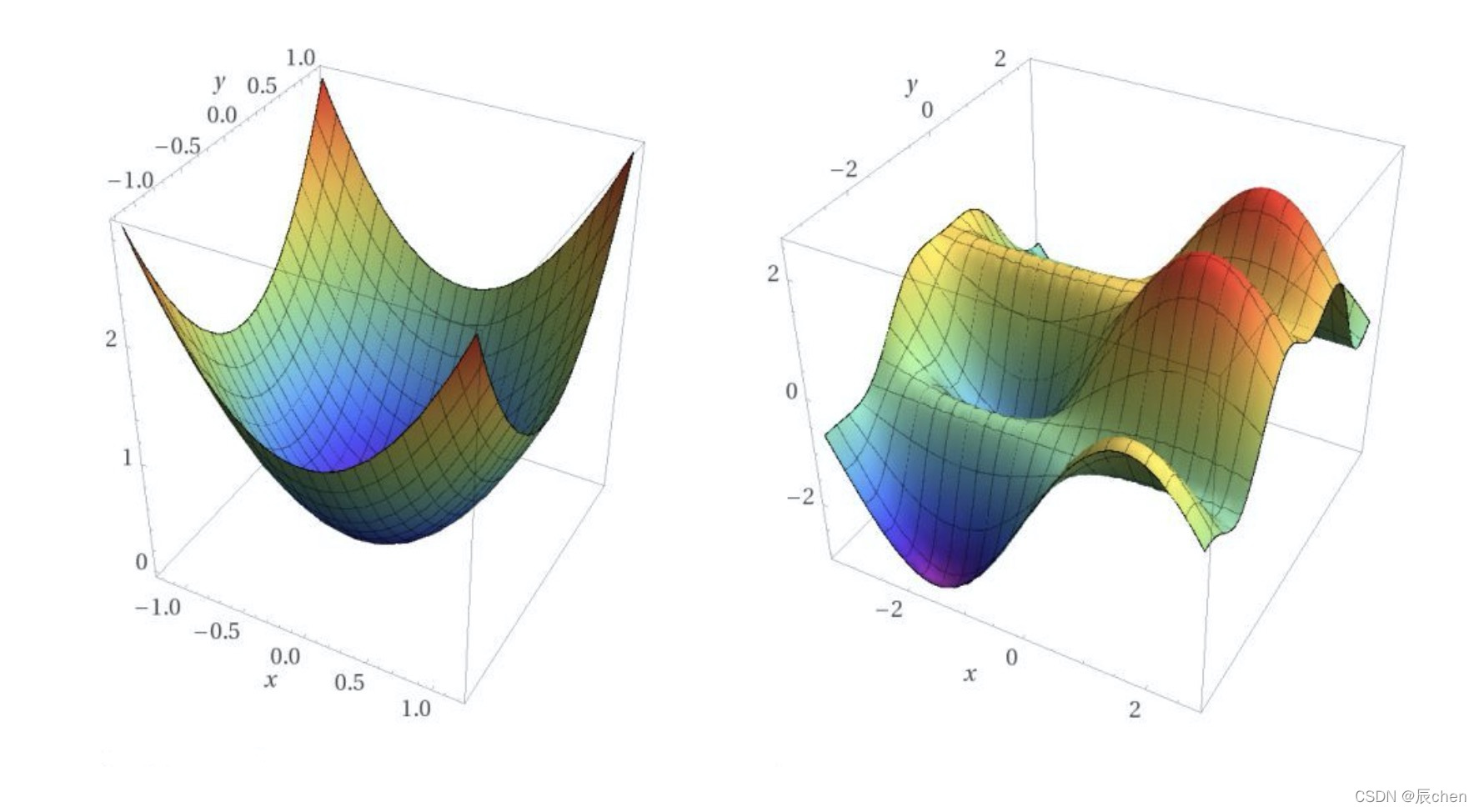
判定凸函式的方式: 判定凸函式的方式非常多,其中一個方法是看 黑塞矩陣 是否是 半正定 的,
黑塞矩陣 ( h e s s i a n (hessian (hessian m a t r i x ) matrix) matrix)是由目標函式在點 X X X 處的二階偏導陣列成的對稱矩陣,
對于我們的式子來說就是在導函式的基礎上再次對 θ \theta θ 來求偏導,結果就是 X T X X^TX XTX,所謂正定就是 X T X X^TX XTX 的特征值全為正數,半正定就是 X T X X^TX XTX 的特征值大于等于 0 0 0, 就是半正定,
J
′
(
θ
)
=
X
T
X
θ
?
X
T
y
J'(\theta) =X^TX\theta -X^Ty
J′(θ)=XTXθ?XTy
J
′
′
(
θ
)
=
X
T
X
J''(\theta) =X^TX
J′′(θ)=XTX
這里我們對 J ( θ ) J(\theta) J(θ) 損失函式求二階導數的黑塞矩陣是 X T X X^TX XTX ,得到的一定是半正定的,自己和自己做點乘嘛!
這里不用數學推導證明這一點,在機器學習中往往損失函式都是凸函式,到深度學習中損失函式往往是非凸函式,即找到的解未必是全域最優,只要模型堪用就好!機器學習特點是:不強調模型 100 % 100\% 100% 正確,只要是有價值的,堪用的,就 O k a y ! Okay! Okay!
轉載請註明出處,本文鏈接:https://www.uj5u.com/qita/423604.html
標籤:AI
上一篇:影像特征—FAST關鍵點
下一篇:python使用matplotlib可視化歸一化的直方圖(histogram)、Y軸坐標為比例、而非頻率、自定義直方圖箱圖不填充(normalizing a histogram)