背景
存盤是大資料的基石,存盤系統的元資料又是它的核心大腦,元資料的性能對整個大資料平臺的性能和擴展能力非常關鍵,本文選取了大資料平臺中 3 個典型的存盤方案來壓測元資料的性能,來個大比拼,
其中 HDFS 是被廣為使用的大資料存盤方案,已經經過十幾年的沉淀和積累,是最合適的參考標桿,
以 Amazon S3 和 Aliyun OSS 為代表的物件存盤也是云上大資料平臺的候選方案,但它只有 HDFS 的部分功能和語意,性能也差不少,實際使用并不廣泛,在這個測驗中物件存盤以 Aliyun OSS 為代表,其他物件存盤類似,
JuiceFS 是大資料圈的新秀,專為云上大資料打造,是符合云原生特征的大資料存盤方案,JuiceFS 使用云上物件存盤保存客戶資料內容,通過 JuiceFS 元資料服務和 Java SDK 來實作 HDFS 的完整兼容,不需要對資料分析組件做任何修改就可以得到跟 HDFS 一樣的體驗,
測驗方法
Hadoop 中有一個專門壓測檔案系統元資料性能的組件叫 NNBench,本文就是使用它來做壓測的,
原版的 NNBench 有一些局限性,我們做了調整:
- 原版 NNBench 的單個測驗任務是單執行緒的,資源利用率低,我們將它改成多執行緒,便于增加并發壓力,
- 原版 NNBench 使用 hostname 作為路徑名的一部分,沒有考慮同一個主機里多個并發任務的沖突問題,會導致多個測驗任務重復創建和洗掉檔案,不太符合大資料作業負載的實際情況,我們改成使用 Map 的順序號來生成路徑名,避免的一個主機上多個測驗任務的產生沖突,
我們使用了 3 臺阿里云 4核 16G 的虛擬機來做壓力測驗,CDH 5 是目前被廣泛使用的發行版,我們選用 CDH 5 作為測驗環境,其中的 HDFS 是 2.6 版本, HDFS 是使用 3 個 JournalNode 的高可用配置,JuiceFS 是 3 個節點的 Raft 組,HDFS 使用內網 IP,JuiceFS 使用的是彈性 IP,HDFS 的網路性能會好一些,OSS 是使用內網介面訪問,
資料分析
先來看看大家都熟悉的 HDFS 的性能表現:
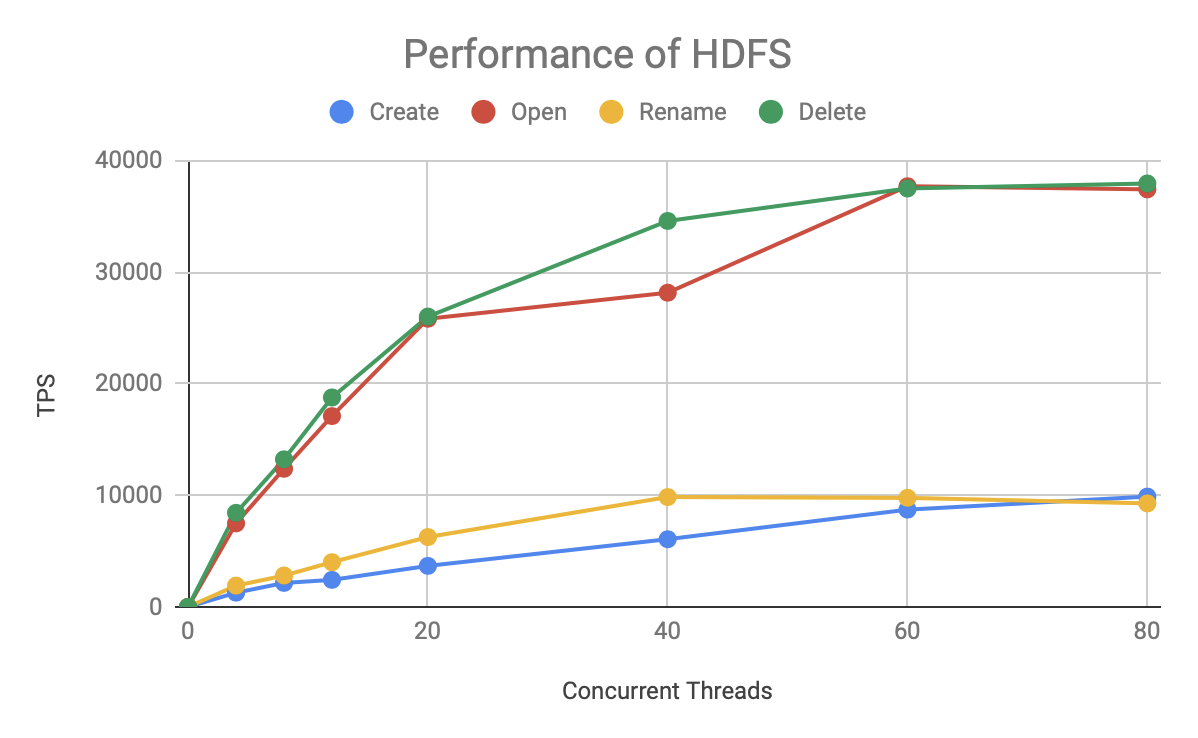
此圖描述的是 HDFS 每秒處理的請求數(TPS)隨著并發數增長的曲線,有兩個發現:
- 其中 Open/Read 和 Delete 操作的性能要遠高于 Create 和 Rename,
- 在 20 個并發前,TPS 隨著并發數線性增長,之后就增長緩慢了,到 60 個并發已經能壓到 TPS 的極限(滿負載),
再來看看 OSS 的性能情況:
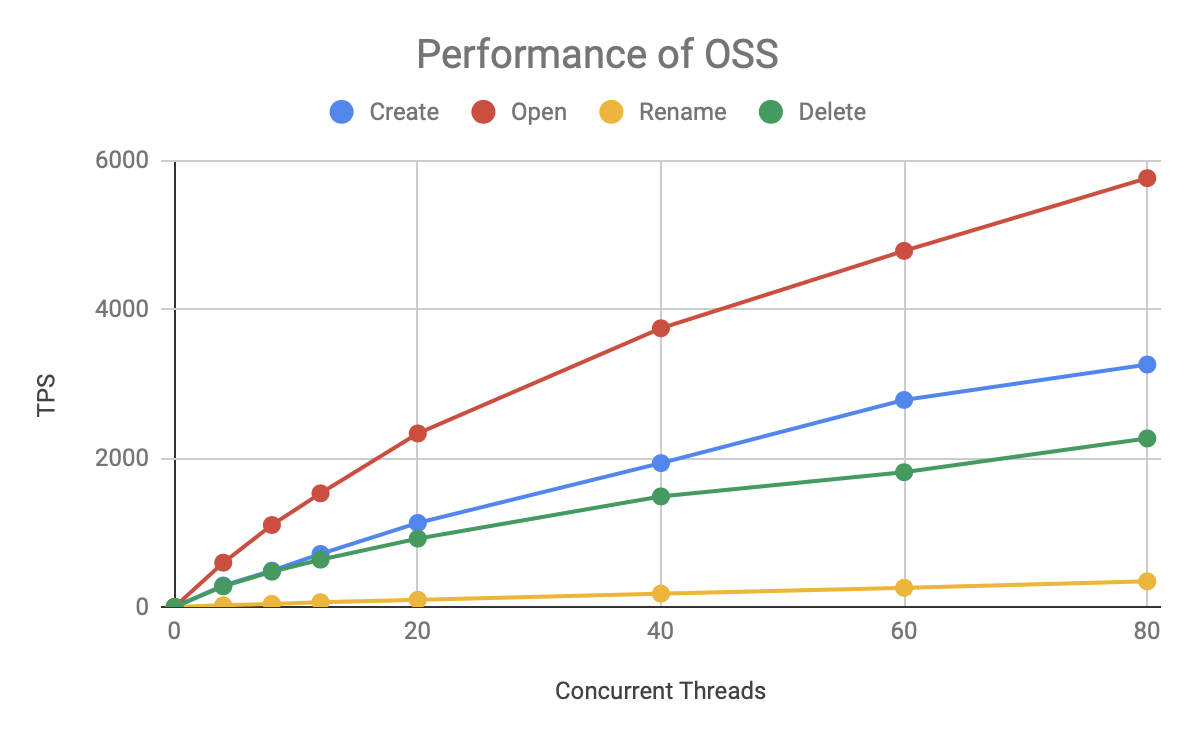
OSS 速度比 HDFS 慢了一個數量級,但它的各種操作的速度基本保持穩定,總的 TPS 隨著并發數的增長而增長,在 80 個并發下還沒遇到瓶頸,受測驗資源所限,未能進一步加大壓測知道它的上限,
最后看下 JuiceFS 的表現:
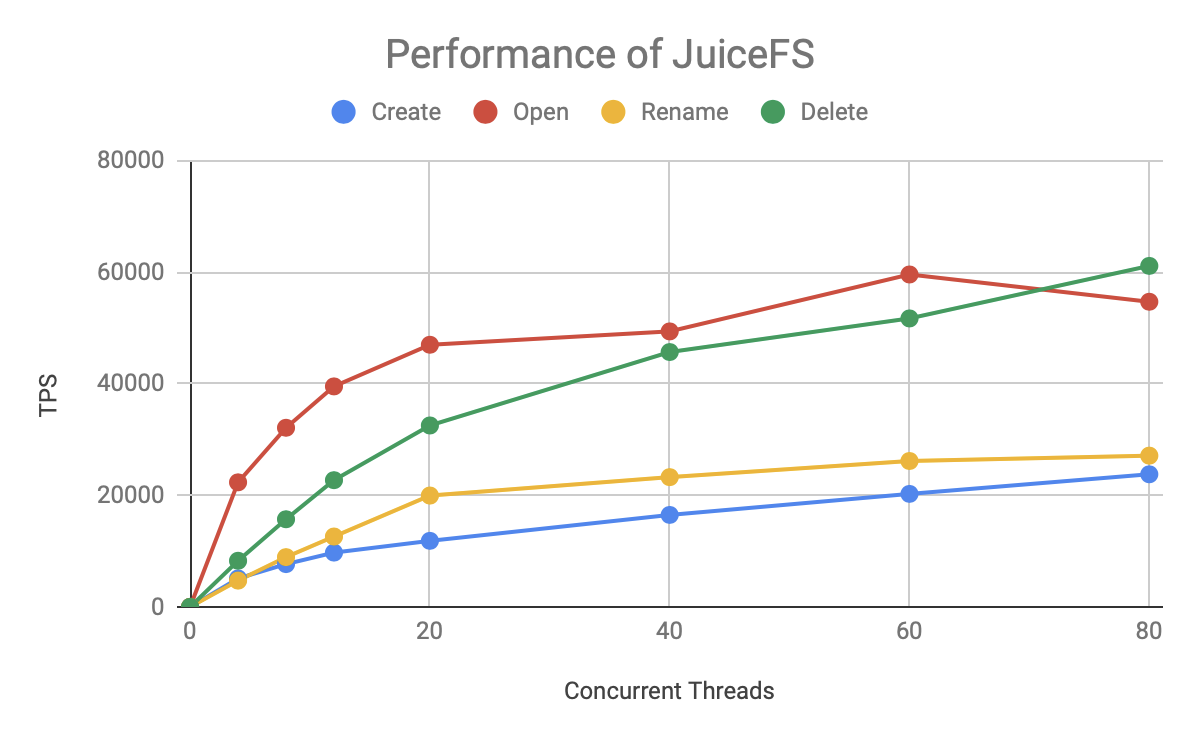
從圖中可以看出,整體趨勢和 HDFS 類似,Open/Read 和 Delete 操作明顯比 Create/Rename 快很多,JuiceFS 的 TPS 也是在 20 個并發以內基本保持執行緒增長,之后增長放緩,在 60 個并發左右達到上線,但 JuiceFS 增幅更快,上限更高,
詳細性能對比
為了更直觀的看出這三者的性能差異,我們直接把 HDFS、Aliyun OSS 和 JuiceFS 放在一起比較:
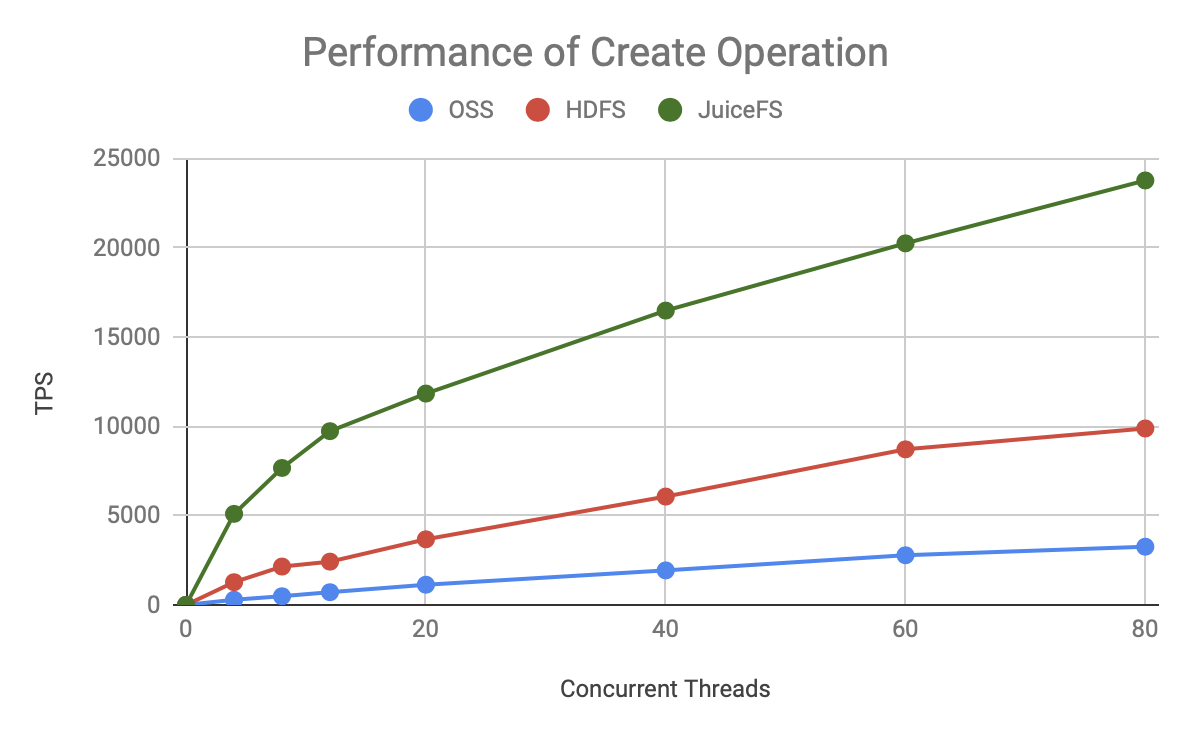
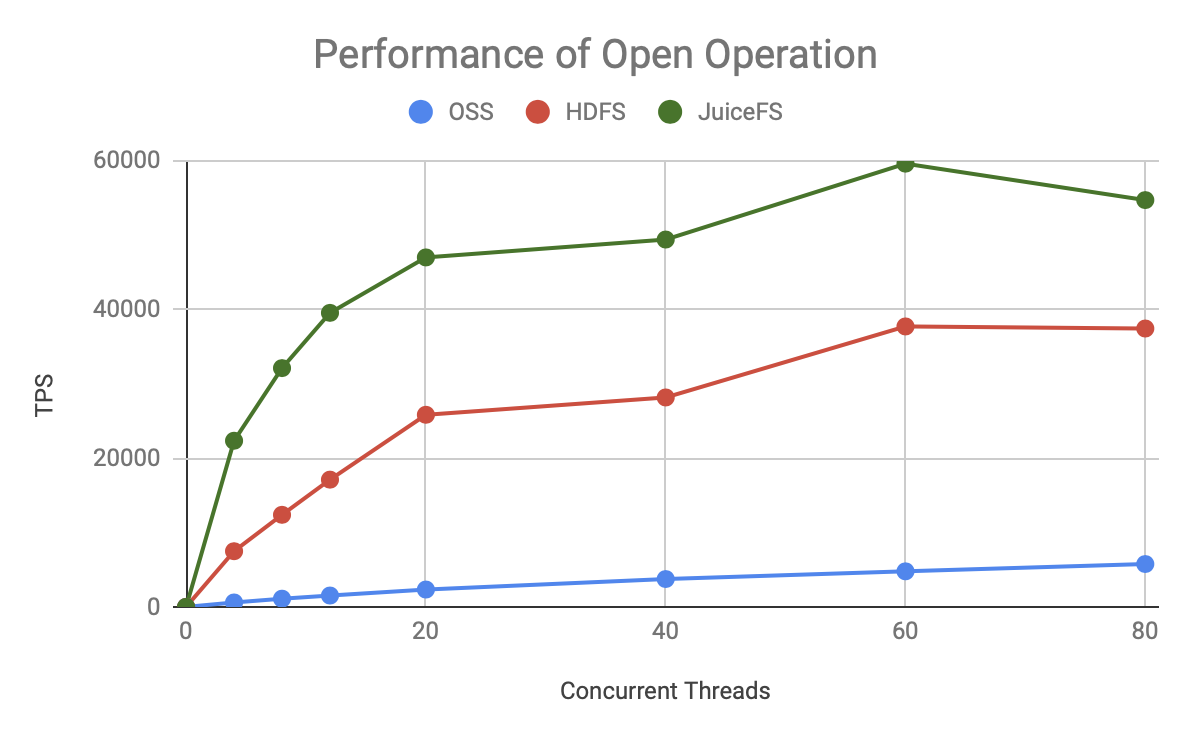
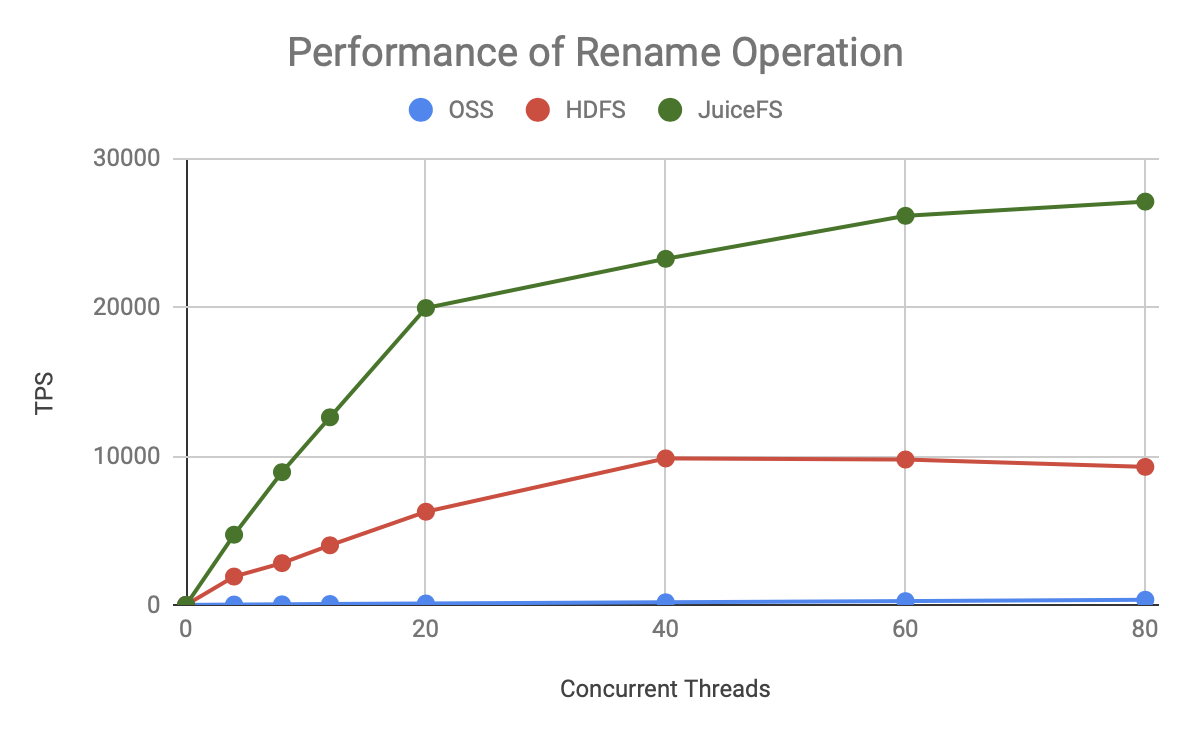
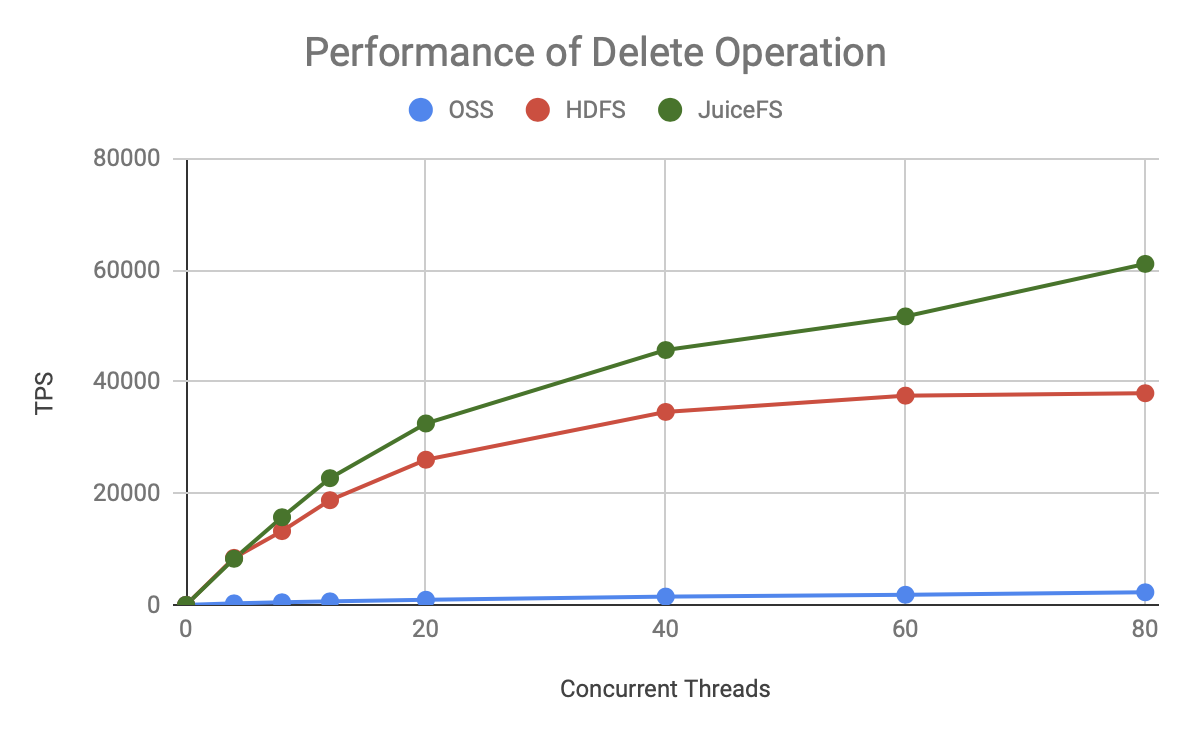
可見無論是哪種元資料操作,JuiceFS 的 TPS 增長更快,上限也更高,明顯優于 HDFS 和 OSS,
總結
一般我們在看一個系統的性能時,主要關注它的操作時延(單個操作所消耗的時間)和吞吐量(滿負載下的處理能力),我們把這兩個指標再匯總一下:
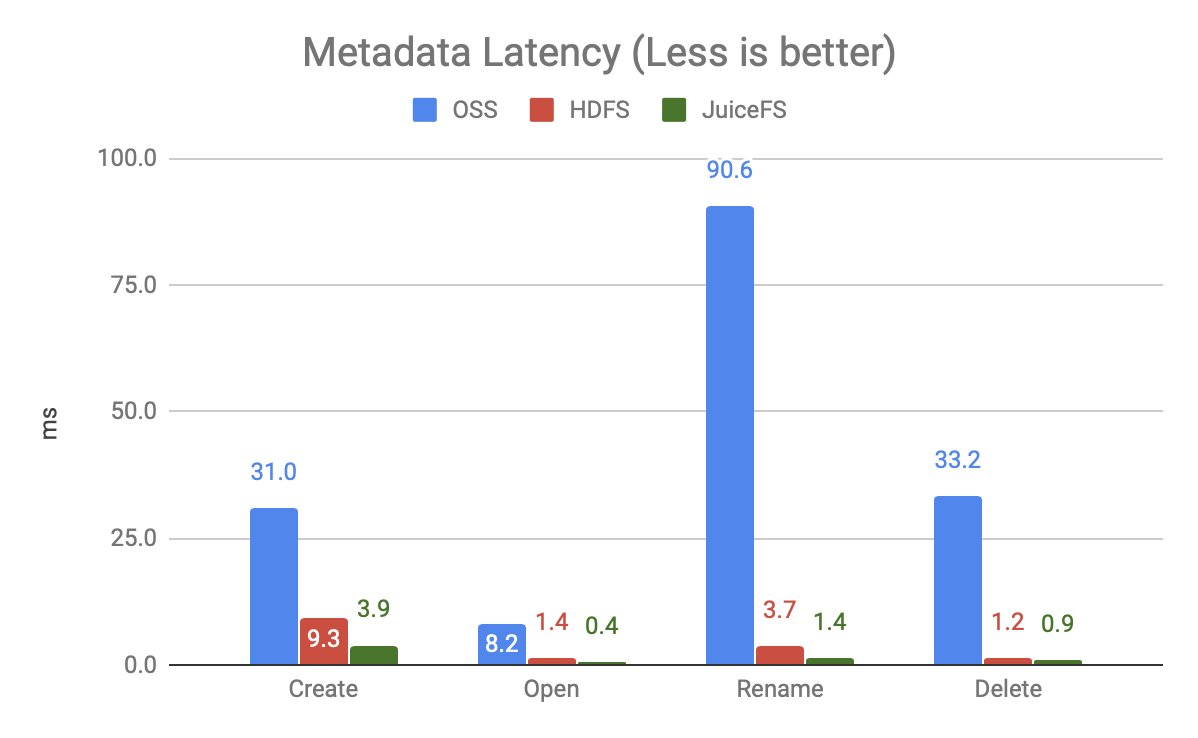
上圖是 20 個并發下的各操作的時延(未跑滿負載),可以發現:
- OSS 非常慢,尤其是 Rename 操作,因為它是通過 Copy + Delete 實作的,本文測驗的還只是單個檔案的 Rename,而大資料場景常用的是對整個目錄的 Rename,差距會更大,
- JuiceFS 的速度比 HDFS 更快,快一倍多,
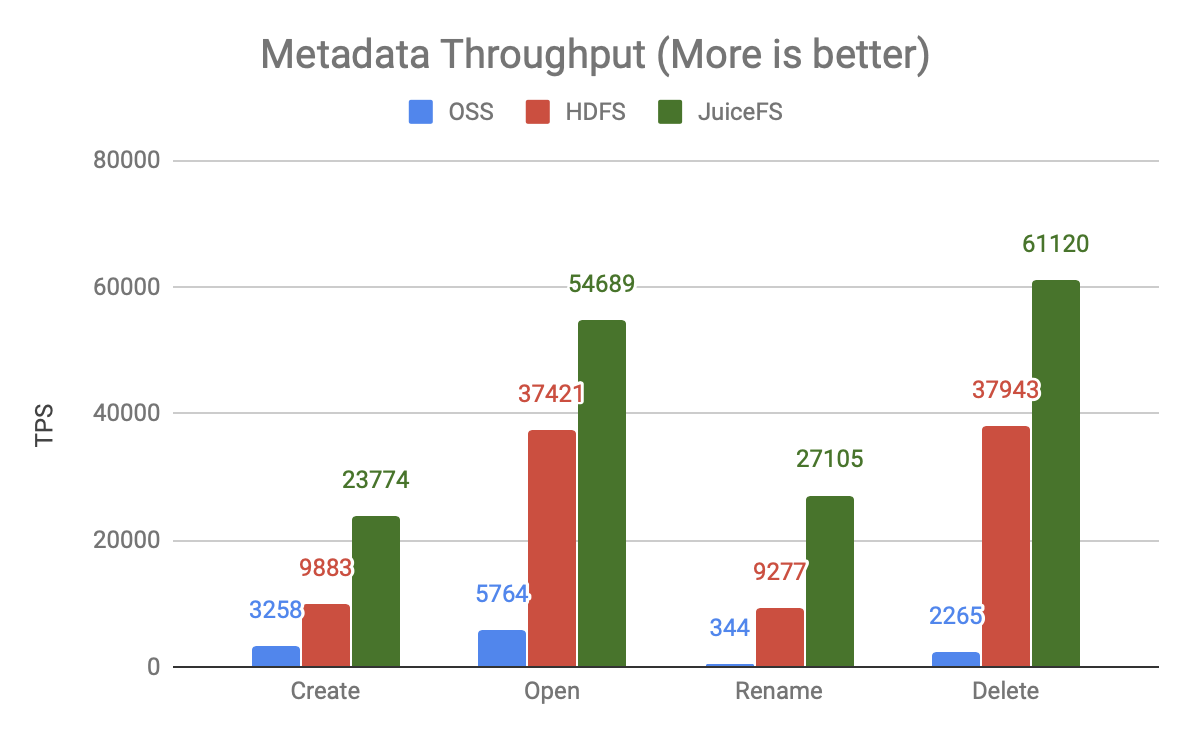
上圖是 80 個并發時的吞吐量對比,可以發現:
- OSS 的吞吐量非常低,和其它兩個產品有一到兩個數量級的差距,意味著它需要使用更多的計算資源,產生更高的并發,才能獲得同等的處理能力,
- JuiceFS 比 HDFS 的處理能力高 50-200%,同樣的資源能夠支撐更大規模的計算,
從以上兩個核心性能指標來看,物件存盤不適合要求性能的大資料分析場景,
如有幫助的話歡迎關注我們專案 Juicedata/JuiceFS 喲! (0?0?)
轉載請註明出處,本文鏈接:https://www.uj5u.com/qita/423620.html
標籤:其他
上一篇:Flink四大基石