1.理論分析
1.SMA
- 優點:較強的全域探索能力
- 缺點:后期迭代震蕩作用較弱,易陷入區域最優;收碩訓制不強,收斂速度較慢;初始種群質量低,探索和開發程序難以平衡,
2.混沌精英演算法CESMA
1.混沌初始化
-
SMA :采用亂數法初始化種群,在解決復雜優化問題時,存在后期種群多樣性降低,易于陷入區域最優等缺陷,
-
Tent混沌映射:目前文獻中大多運用 Logistic 混沌映射優化智能演算法產生混沌序列,豐富種群多樣性,但相較于 Logistic 混沌映射,Tent 混沌映射更加結構簡單,收斂速度快,具有更好的遍歷均勻性,
-
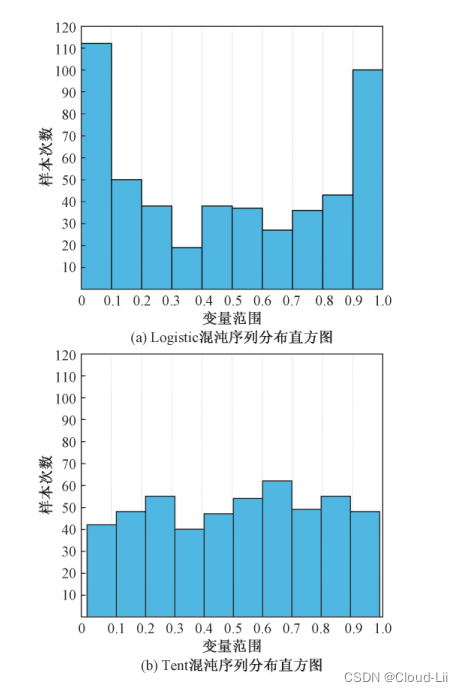
Logistic與Tent混沌映射分布對比:
-
設定種群規模為 500,分別采用兩種方法在區間[0,1]范圍內產生混沌序列,其空間分布直方圖如下圖所示:
-
-
由圖可以看出,Logistic混沌映射生成的序列在區間[0,0. 1]和[0. 9, 1]范圍內的概率要高于其他各段,而 Tent 混沌序列在可行域內分布相對均勻,因此選用Tent混沌映射再sMA演算法迭代初期進行種群初始化,使得個體位置均勻分布在搜索空間內,有助于提高演算法求解效率,
-
-
Tent混沌映射的數學運算式:
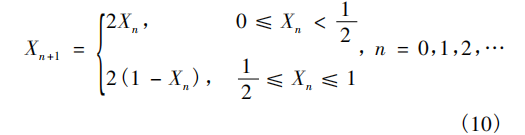
其中:n 表示映射次數; Xn 表示第 n 次映射函式值, -
采用Tent映射生成初始種群的步驟:
-
S:表示種群的適應度值陣列
-
個人認為:步驟3“若生成的X落入最小周期點,則轉到步驟3”中的“步驟3”應改為“步驟4”,
-

- 效果:提高初始化種群的多樣性
2.精英反向學習機制
-
精英反向學習EOBL:
- 其他演算法對于EOBL機制的應用:何慶等人采用 EBOL 方法初始化種群,增加了蜻蜓演算法的種群多樣性;方旭陽等人引入 EBOL 優化正余弦演算法,避免個體盲目地向當前學習,
- EBOL 機制利用精英個體相對普通個體而言攜帶更多有效資訊的優勢,首先通過種群中精英個體形成反向種群,再從反向種群和當前種群中選取優秀個體構成新的種群,
-
精英反向解公式:
X e i j = δ × ( l b j + u b j ) - X E i j Xe ij = δ × ( lbj + ubj) - XEij Xeij=δ×(lbj+ubj)-XEij-
引數說明:Xe 為精英反向解,XE為精英解,δ 是[0,1]上的隨機值,XEij ∈[lbj,ubj],
-
lbj = min( Xij ) ,ubj = max( Xij) ,lbj 和 ubj 分別為動態邊界的下界和上界,min( Xij) 、max( Xij) 分別為第 j 維個體的最小值和最大值,動態邊界解決了固定邊界難以保存搜索經驗的問題,有利于減少演算法的尋優時間,
-
如果精英反向解 Xeij 超過邊界,利用隨機生成的方式將其重置,重置方程如下:
X e i j = r a n d ( l b j , u b j ) Xeij = rand(lbj , ubj) Xeij=rand(lbj,ubj)
-
-
效果:有利于提高黏菌種群多樣性和種群質量,提升演算法全域尋優性能與收斂精度,
2.CESMA偽代碼

3.實驗仿真
-
為了更好的驗證 CESMA 演算法性能,選取了 5 種演算法進行對比:SMA、PSO、WOA、ISMA_EQ、HSMAAOA(論文中包括MBO演算法,但由于筆者還沒有學習MBO演算法,故暫不加入實驗,加入另外幾種SMA的改進演算法HSMAAOA、ISMA_EQ),這些演算法被證實具有良好的尋優性能,為了更準確的驗證所提演算法與對比演算法的優劣性,設定種群規模 N=30,維度 D=30,最大迭代次數 500 次,各演算法獨立運行 30 次,
-
選取最優值、最差值、平均值與標準差作為評價指標,其中,平均值與標準差越小,則證明演算法的性能越佳,
-
例舉部分標準測驗函式的適應度曲線:F1、F2(單峰函式)、F6、F7(多峰函式),F21、F23(固定維多峰函式)結果顯示如下:
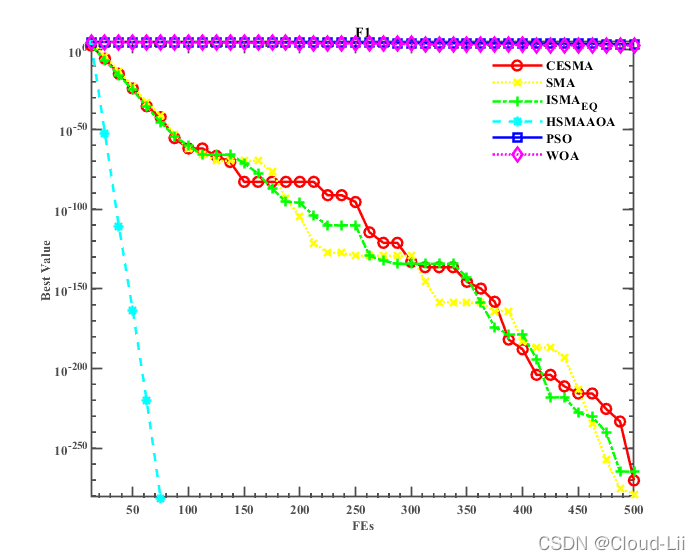
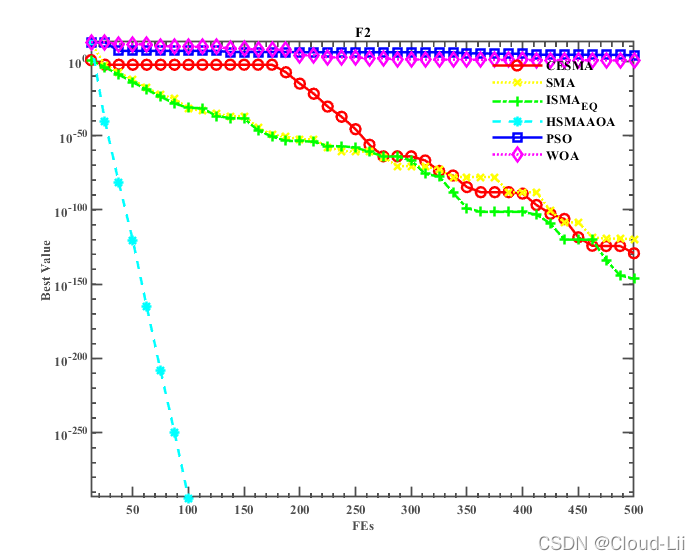
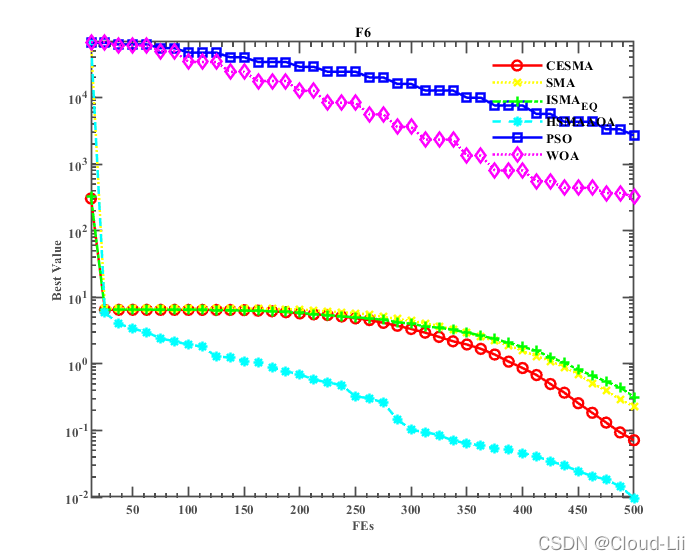
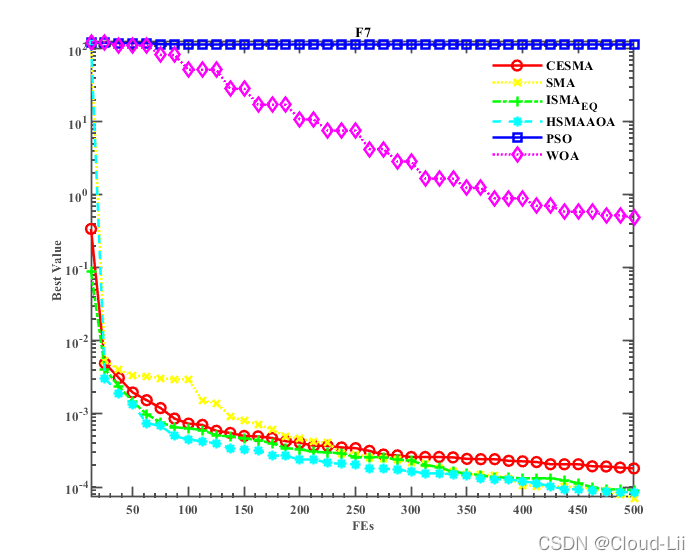
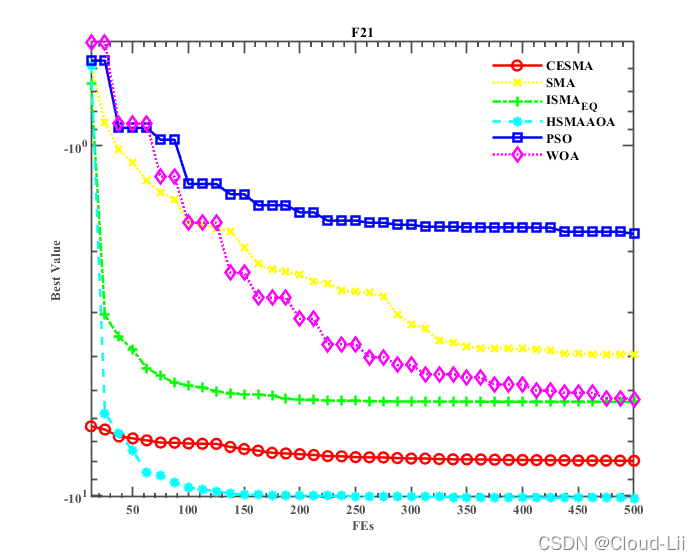
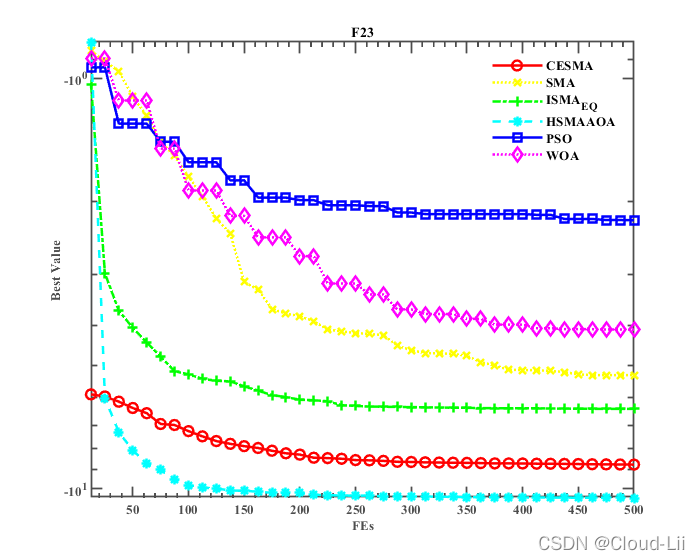
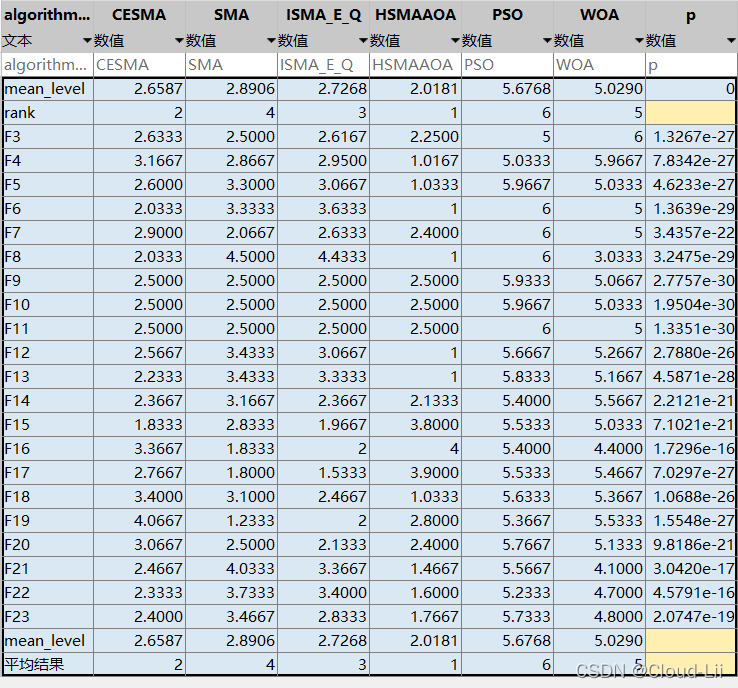 實驗結果表明:CESMA較好地提升了黏菌演算法的全域尋優性能、精度、速度以及魯棒性,其對于收斂速度的改善效果優良,但其整體優化效果較HSMAAOA演算法較弱,
實驗結果表明:CESMA較好地提升了黏菌演算法的全域尋優性能、精度、速度以及魯棒性,其對于收斂速度的改善效果優良,但其整體優化效果較HSMAAOA演算法較弱,
4.參考文獻
[1]肖亞寧,孫雪,李三平,姚金言.基于混沌精英黏菌演算法的無刷直流電機轉速控制[J].科學技術與工程,2021,21(28):12130-12138.
轉載請註明出處,本文鏈接:https://www.uj5u.com/qita/423687.html
標籤:AI
上一篇:黃金之殼