《繁凡的深度學習筆記》第 3 章分類問題與資訊論基礎 (中)(邏輯回歸、資訊論基礎、Softmax回歸)(DL筆記整理系列)
3043331995@qq.com
https://fanfansann.blog.csdn.net/
https://github.com/fanfansann/fanfan-deep-learning-note
作者:繁凡
version 1.0 2022-1-20
宣告:
1)《繁凡的深度學習筆記》是我自學完成深度學習相關的教材、課程、論文、專案實戰等內容之后,自我總結整理創作的學習筆記,寫文章就圖一樂,大家能看得開心,能學到些許知識,對我而言就已經足夠了 ^q^ ,
2)因個人時間、能力和水平有限,本文并非由我個人完全原創,文章部分內容整理自互聯網上的各種資源,參考內容標注在每章末的參考資料之中,
3)本文僅供學術交流,非商用,所以每一部分具體的參考資料并沒有詳細對應,如果某部分不小心侵犯了大家的利益,還望海涵,并聯系博主洗掉,非常感謝各位為知識傳播做出的貢獻!
4)本人才疏學淺,整理總結的時候難免出錯,還望各位前輩不吝指正,謝謝,
5)本文由我個人( CSDN 博主 「繁凡さん」(博客) , 知乎答主 「繁凡」(專欄), Github 「fanfansann」(全部原始碼) , 微信公眾號 「繁凡的小島來信」(文章 P D F 下載))整理創作而成,且僅發布于這四個平臺,僅做交流學習使用,無任何商業用途,
6)「我希望能夠創作出一本清晰易懂、可愛有趣、內容詳實的深度學習筆記,而不僅僅只是知識的簡單堆砌,」
7)本文《繁凡的深度學習筆記》全匯總鏈接:《繁凡的深度學習筆記》前言、目錄大綱
8)本文的Github 地址:https://github.com/fanfansann/fanfan-deep-learning-note/ 孩子的第一個 『Github』!給我個 ? ??? Starred \boxed{? \,\,\,\text{Starred}} ?Starred? 嘛!謝謝!!o(〃^▽^〃)o
9)此屬 version 1.0 ,若有錯誤,還需繼續修正與增刪,還望大家多多指點,本文會隨著我的深入學習不斷地進行完善更新,Github 中的 P D F 版也會盡量每月進行一次更新,所以建議點贊收藏分享加關注,以便經常過來回看!
如果覺得還不錯或者能對你有一點點幫助的話,請幫我給本篇文章點個贊,你的支持是我創作的最大動力!^0^
要是沒人點贊的話自然就更新慢咯 >_<
《繁凡的深度學習筆記》第 3 章 分類問題與資訊論基礎(上)目錄
第 3 章 分類問題 (邏輯回歸、Softmax 回歸、資訊論基礎)
??? 3.1 手寫數字分類問題
????? 3.1.1 手寫數字圖片資料集
????? 3.1.2 構建模型
????? 3.1.3 誤差計算
????? 3.1.4 非線性模型
????? 3.1.4 手寫數字圖片識別實戰
???????? 3.1.4.1 TensorFlow2.0 實作
???????? 3.1.4.2 PyTorch 實作
??? 3.2 邏輯回歸(Logistic Regression, LR)
????? 3.2.1 決策邊界
????? 3.2.2 邏輯回歸模型
????? 3.2.3 代價函式
????? 3.2.4 優化方法
《繁凡的深度學習筆記》第 3 章分類問題與資訊論基礎(中)目錄
- 《繁凡的深度學習筆記》第 3 章(中)分類問題與資訊論基礎
- 3.3 資訊論基礎
- 3.3.1 資訊論
- 3.3.1.1 自資訊與資訊量
- 3.3.2 香農熵
- 3.3.2.1 熵
- 3.3.2.2 聯合熵
- 3.3.2.3 互資訊
- 3.3.2.4 條件熵
- 3.3.2.5 資訊熵的鏈式法則
- 3.3.3 相對熵(KL 散度)
- 3.3.4 交叉熵
- 3.3.5 JS 散度
- 3.3.6 Wasserstein 距離
《繁凡的深度學習筆記》第 3 章 分類問題與資訊論基礎(下)目錄
??? 3.4 Softmax 回歸
????? 3.4.1 Softmax 回歸模型
????? 3.4.2 優化方法
????? 3.4.3 權重衰減
????? 3.4.4 Fashion-MNIST 資料集圖片分類實戰
??? 3.5 Softmax 回歸與邏輯回歸的關系
????? 3.5.1 Softmax 回歸與邏輯回歸的關系
????? 3.5.2 多分類問題的 Softmax 回歸與 k 個二元分類器
??? 3.6 面試問題集錦
??? 3.7 參考資料
《繁凡的深度學習筆記》第 3 章(中)分類問題與資訊論基礎
3.3 資訊論基礎
資訊論是一個非常龐大的學科,這里僅對機器學習中常用的簡單資訊論基礎進行清晰易懂的簡要講解,如果對資訊論感興趣想要深入學習,請繼續閱讀Thomas M. Cover 的 《Elements of Information Theory》 (資訊論經典之作)以及其中譯本《資訊論基礎》,詳見 我的Github 專案《繁凡的深度學習筆記》免.費深度學習書籍 ,
3.3.1 資訊論
??資訊論是運用概率論與數理統計的方法研究資訊熵、通信系統、資料傳輸、資料壓縮等問題的應用數學學科,主要研究的是對一個信號能夠提供的資訊多少進行量化,資訊論涉及編碼、解碼、發送以及盡可能簡潔地處理資訊或資料,主要的研究物件是關于隨機變數的資訊熵和信道,
3.3.1.1 自資訊與資訊量
??資訊量(amount of information),指資訊多少的量度,我們需要知道,資訊是用來減少隨機不確定性的東西,也即不確定性的減少,
??自資訊(self-information),又譯為資訊本體,由克勞德 · 香農(Claude Shannon)提出,用來衡量單一事件發生時所包含的資訊量多寡,任何事件都會承載著一定的資訊量,包括已經發生的事件和未發生的事件,只是它們承載的資訊量會有所不同,
??例如對于昨天下雨這個已知事件,因為是已經發生的事件,是既定事實,那么它的資訊量就為 0 0 0 ,對于明天會下雨這個事件,因為未有發生,那么這個事件的資訊量就大,我們可以發現資訊量是一個與事件發生概率相關的概念,對于一個事件來說,它發生的概率越大,確定性越強,顯然它所含有的資訊量就越低,一件事情發生的概率越低,不確定性越強,它包含的資訊量就越大,
??至此,資訊論假設資訊量它只與隨機變數的概率分布有關,滿足可加性等性質,
定義事件
X
=
x
i
X=x_i
X=xi? 的自資訊為
I
(
x
i
)
=
log
?
b
1
P
(
x
i
)
=
?
log
?
b
P
(
x
i
)
=
?
log
?
P
(
x
i
)
(3.32)
I\left(x_i\right)=\log_b\dfrac 1{P(x_i)}=-\log_b P\left(x_i\right)=-\log P\left(x_i\right)\tag{3.32}
I(xi?)=logb?P(xi?)1?=?logb?P(xi?)=?logP(xi?)(3.32)
其中, X X X 為隨機變數, x i x_i xi? 為隨機變數的某個取值, P P P 為 X X X 的概率分布: X ~ P ( X ) X\sim P(X) X~P(X) , n n n 表示事件的個數,引數 b b b 不同時對應的結果單位不同,在公式中可忽略,在機器學習中,用自然對數 e e e 為底,單位為 奈特( n i t \mathrm{nit} nit),用 2 2 2 為底,單位為位元( b i t \mathrm{bit} bit),至于我們為什么會這樣定義自資訊,我們將在下一節 《繁凡的深度學習筆記》3.3.2 香農熵 中進行詳細探討,
我們同樣可以定義事件 X = x i , Y = y i X=x_i,Y=y_i X=xi?,Y=yi? 的聯合自資訊:
I
(
x
i
,
y
j
)
=
log
?
1
P
(
x
i
,
y
j
)
(3.33)
I\left(x_{i}, y_{j}\right)=\log \frac{1}{P\left(x_{i}, y_{j}\right)}\tag{3.33}
I(xi?,yj?)=logP(xi?,yj?)1?(3.33)
如果
X
X
X 與
Y
Y
Y 相互獨立,則:
I
(
x
i
,
y
j
)
=
log
?
1
P
(
x
i
)
+
log
?
1
P
(
y
i
)
=
I
(
x
i
)
+
I
(
y
j
)
(3.34)
\begin{aligned}I\left(x_{i}, y_{j}\right) &=\log \frac{1}{P\left(x_{i}\right)}+\log \frac{1}{P\left(y_{i}\right)} \\&=I\left(x_{i}\right)+I\left(y_{j}\right)\end{aligned}\tag{3.34}
I(xi?,yj?)?=logP(xi?)1?+logP(yi?)1?=I(xi?)+I(yj?)?(3.34)
直觀上我們要求需要自資訊滿足如下的性質:
- 連續性,即事件的自資訊 I I I 隨著 P P P 的變化連續變化,
- 單調遞減性,即發生的概率越小,確定它發生所需要的資訊量越大,
- 當 P → 0 P\rightarrow 0 P→0 時, I → ∞ I\rightarrow \infin I→∞ ,即確定不可能事件發生需要的資訊量為無窮大,
- 當 P → 1 P\rightarrow 1 P→1 時, I → 0 I\rightarrow 0 I→0,即對確定一定會發生事件發生需要的資訊量為0,
- 獨立隨機變數的自資訊等于各自自資訊的代數和,
由此可見,資訊的本質是對不確定性的消除,
3.3.2 香農熵
3.3.2.1 熵
??我們首先來介紹資訊學中熵的概念,
??熵 (Entropy),本是熱力學中的概念,1948 年,克勞德 · 香農(Claude Shannon)將熱力學中的熵的概念引入到資訊論中,因此也被稱為 資訊熵 或香農熵 (Shannon Entropy),用來衡量資訊的不確定度,不準確點說,熵是用來衡量混亂程度的,越混亂,熵越大,代表不確定性越大,要弄清楚情況所需要的資訊量越多,
??舉個栗子,一個袋子有 10 10 10 個球,如果其中有 5 5 5 個紅球 5 5 5 個白球,這就是混亂的,如果有 9 9 9 個紅球和 1 1 1 個白球,這就不混亂,可以理解為如果各種物品的比例相同,不同物品的概率都很大,那么我想要判斷袋子里面有什么東西就比較困難,整體的資訊量就很大,就會非常混亂,如果袋子僅有一種物品,那么我判斷袋子里的物品就非常容易,這便是不混亂,也即一個集合里面各部分比例越均衡越混亂,各部分越兩極分化越不混亂,
??那么如何使用數學來衡量混亂程度呢? 我們顯然發現當物品的總數不變的情況下,兩種物品數目的乘積越大越混亂,越小越不混亂,那么我們顯然就可以用這個相乘的結果來衡量資料混亂程度,既然如此,如果袋子中有多種球,我們可以將他們的概率連乘即可,
??但是我們發現連乘起來以后求導比較困難,例如對 f ( P ( x ) ) × g ( P ( x ) ) f(P(x))\times g(P(x)) f(P(x))×g(P(x)) 進行求導我們就需要將其展開,一個顯而易見的思路就是對乘積取對數將乘法變成加法,這樣不僅求導更加方便,原先的單調性也沒有改變,
??但是我們發現取對數以后雖然 log ? P ( x ) \log P(x) logP(x) 是單調遞增的,但是概率 P ( x ) P(x) P(x) 不能取 0 0 0,我們知道概率的取值范圍為 [ 0 , 1 ] [0,1] [0,1],而當 P ( x ) = 0 P(x)=0 P(x)=0 時,此時極限是負無窮的 log ? ( P ( x ) ) \log(P(x)) log(P(x)) 是沒有任何意義的,考慮能不能讓 0 0 0 乘上負無窮使其變成 0 0 0,于是我們就得到了衡量混亂程度的指標: P ( x ) × log ? P ( x ) P(x)\times \log P(x) P(x)×logP(x),此 P ( x ) → 0 P(x)\rightarrow 0 P(x)→0 時, P ( x ) × log ? P ( x ) = 0 P(x)\times \log P(x)=0 P(x)×logP(x)=0,此時 P ( x ) P(x) P(x) 單調遞增, log ? ( P ( x ) ) \log (P(x)) log(P(x)) 單調遞減,相乘為單調遞減,由于我們希望概率越大,不確定性也即熵的大小越小,因此我們可以取負號,至此我們就得到了香農熵的形式,同時也被香農在數學上嚴格證明滿足資訊熵三個條件的隨機變數不確定性度量函式具有的唯一形式:
H ( X ) = ? ∑ i = 1 n P ( x i ) log ? P ( x i ) H\left(X\right)=-\sum_{i=1}^{n}P\left(x_i\right)\log{P\left(x_i\right)} H(X)=?i=1∑n?P(xi?)logP(xi?)
資訊論之父克勞德·香農,總結出的資訊熵的三條性質:
- 單調性,即發生概率越高的事件,其所攜帶的資訊熵越低,極端案例就是“太陽從東方升起”,因為為確定事件,所以不攜帶任何資訊量,從資訊論的角度,認為這句話沒有消除任何不確定性,
- 非負性,即資訊熵不能為負,這個很好理解,因為負的資訊,即你得知了某個資訊后,卻增加了不確定性是不合邏輯的,
- 累加性,即多隨機事件同時發生存在的總不確定性的量度是可以表示為各事件不確定性的量度的和,
??因此我們定義事件 X = x i X=x_i X=xi? 的資訊量 I ( x i ) = ? log ? P ( x i ) I(x_i)=-\log P(x_i) I(xi?)=?logP(xi?),此時資訊量的期望就是熵,也即:
H ( x ) = ? ∑ i = 1 n P ( x i ) log ? b P ( x i ) = E x ~ P [ I ( x ) ] = ? E x ~ P [ log ? P ( x ) ] \begin{aligned}H\left(\mathrm{x}\right)&=-\sum_{i=1}^{n}P\left(x_i\right)\log_b{P\left(x_i\right)}\\&=\mathbb{E}_{\mathrm{x}\sim P}\left[I\left(x\right)\right]=-\mathbb{E}_{\mathrm{x}\sim P}\left[\log{P\left(x\right)}\right]\end{aligned} H(x)?=?i=1∑n?P(xi?)logb?P(xi?)=Ex~P?[I(x)]=?Ex~P?[logP(x)]?
其中 P P P 為 X X X 的概率質量函式, n n n 表示事件的個數,引數 b b b 不同時對應的結果單位不同,在機器學習中,用自然對數 e e e 為底,單位為 奈特( n i t \mathrm{nit} nit),用 2 2 2 為底,單位為位元( b i t \mathrm{bit} bit),對于連續變數則被稱為 微分熵,
一個隨機變數 X X X 的熵 H ( X ) H(X) H(X) 的大小可以理解為事件資訊量的位元數,
??這里以
2
2
2 為底舉個例子,對于
4
4
4 分類問題,如果某個樣本的真實標簽是第
4
4
4 類,one-hot 編碼為
[
0
,
0
,
0
,
1
]
[0,0,0,1]
[0,0,0,1] ,即這張圖片的分類是唯一確定的,它屬于第
4
4
4 類的概率
(
𝑦
=
4
∣
𝑥
)
=
1
(𝑦=4|𝑥) = 1
(y=4∣x)=1,不確定性為
0
0
0,它的熵可以簡單的計算為
?
0
×
log
?
2
0
?
0
×
log
?
2
0
?
0
×
log
?
2
0
?
1
×
log
?
2
1
=
0
-0 \times \log _{2} 0-0 \times \log _{2} 0-0 \times \log _{2} 0-1 \times \log _{2} 1=0
?0×log2?0?0×log2?0?0×log2?0?1×log2?1=0
也就是,對于確定的分布,熵為 0 0 0,即不確定性最低,如果它預測的概率分布是 [ 0.1 , 0.1 , 0.1 , 0.7 ] [0.1,0.1,0.1,0.7] [0.1,0.1,0.1,0.7],它的熵可以計算為
? 0.1 × log ? 2 0.1 ? 0.1 × log ? 2 0.1 ? 0.1 × log ? 2 0.1 ? 0.7 × log ? 2 0.7 ≈ 1.356 ?? b i t -0.1 \times \log _{2} 0.1 - 0.1 \times \log _{2} 0.1 - 0.1 \times \log _{2} 0.1 - 0.7 \times \log _{2} 0.7 \approx 1.356\,\,\mathrm{bit} ?0.1×log2?0.1?0.1×log2?0.1?0.1×log2?0.1?0.7×log2?0.7≈1.356bit
??考慮隨機分類器,它每個類別的預測概率是均等的: [ 0.25 , 0.25 , 0.25 , 0.25 ] [0.25,0.25,0.25,0.25] [0.25,0.25,0.25,0.25],這種情況下的熵約為 2 2 2,
??由于
P
(
𝑖
)
∈
[
0
,
1
]
,
log
?
2
(
𝑖
)
≤
0
P(𝑖) ∈ [0,1], \log2 (𝑖) \le 0
P(i)∈[0,1],log2(i)≤0,因此熵總是大于等于
0
0
0,當熵取得最小值
0
0
0時,不確定性為
0
0
0,分類問題的 One-hot 編碼的分布就是熵為 0 的例子,我們可以使用 math.log 來組合計算熵,
??對于 0-1 分布問題,二值隨機變數的香農熵、伯努利分布熵,隨機變數
x
x
x 的取值為
{
0
,
1
}
\{0, 1\}
{0,1},此時熵的計算可以簡化為
H
(
x
)
=
?
P
(
x
)
log
?
(
P
(
x
)
)
?
(
1
?
P
(
x
)
)
log
?
(
1
?
P
(
x
)
)
H\left(\mathrm{x}\right)=-P\left(x\right)\log{\left(P\left(x\right)\right)}-\left(1-P\left(x\right)\right)\log\left(1-P\left(x\right)\right)
H(x)=?P(x)log(P(x))?(1?P(x))log(1?P(x))
??另一個經典的例子是:在一場賭馬比賽中,有 4 4 4 匹馬 { A , B , C , D } \{ A, B, C, D\} {A,B,C,D} ,獲勝概率分別為 { 1 2 , 1 4 , 1 8 , 1 8 } \{ \dfrac 1 2, \dfrac 14, \dfrac 18,\dfrac 18 \} {21?,41?,81?,81?},將哪一匹馬獲勝視為隨機變數 X X X 屬于 { A , B , C , D } \{ A, B, C, D \} {A,B,C,D},假定我們需要用盡可能少的二元問題來確定隨機變數 X X X 的取值,也即我們可以給出若干個詢問,每組詢問只能得到兩種答案:對或者錯,請問最少需要通過多少個問題,來知道最后是哪匹馬獲得了勝利?
例如:問題 1 : A A A 獲勝了嗎?問題 2 : B B B獲勝了嗎?問題 3 : C C C 獲勝了嗎?最后我們可以通過最多 3 3 3 個二元問題,來確定 X X X 的取值,也即最終是哪一匹馬獲得了勝利,
如果最終是 A A A 獲得勝利,也即 X = A X = A X=A ,那么只需要問 1 1 1 次(問題 1 ) 即可得到答案, A A A 獲勝的概率為 1 2 \dfrac 1 2 21?,
如果最終是 B B B 獲得勝利,也即 X = B X = B X=B ,那么需要問 2 2 2 次(問題 1 以及問題 2 ), B B B 獲勝的概率為 1 4 \dfrac 1 4 41? ,
如果最終是 C C C 獲得勝利,也即 X = C X = C X=C,那么需要問 3 3 3 次(問題 1,問題 2,問題 3 ), C C C 獲勝的概率為 1 8 \dfrac 1 8 81?,
如果最終是 D D D 獲得勝利,也即 X = D X = D X=D,那么需要問 3 3 3 次(問題 1 ,問題 2 ,問題 3 ), D D D 獲勝的概率為 1 8 \dfrac 1 8 81?,
那么為確定 X X X 取值的二元問題的數量期望次數為:
E ( N ) = 1 2 ? 1 + 1 4 ? 2 + 1 8 ? 3 + 1 8 ? 3 = 7 4 E(N)=\frac{1}{2} \cdot 1+\frac{1}{4} \cdot 2+\frac{1}{8} \cdot 3+\frac{1}{8} \cdot 3=\frac{7}{4} E(N)=21??1+41??2+81??3+81??3=47?
那么我們帶入到資訊熵的公式中,選取 log ? \log log 的底數為 2 2 2 ,即可得到:
H ( X ) = 1 2 log ? ( 2 ) + 1 4 log ? ( 4 ) + 1 8 log ? ( 8 ) + 1 8 log ? ( 8 ) = 1 2 + 1 2 + 3 8 + 3 8 = 7 4 bit H(X)=\frac{1}{2} \log (2)+\frac{1}{4} \log (4)+\frac{1}{8} \log (8)+\frac{1}{8} \log (8)=\frac{1}{2}+\frac{1}{2}+\frac{3}{8}+\frac{3}{8}=\frac{7}{4} \text { bit } H(X)=21?log(2)+41?log(4)+81?log(8)+81?log(8)=21?+21?+83?+83?=47? bit
??在二進制計算機中,一個位元為 0 0 0 或 1 1 1 ,其實就代表了一個二元問題的回答,平均碼長 L ( C ) = ∑ x ∈ X P ( x ) l ( x ) \displaystyle L(C)=\sum_{x\in X}P(x)l(x) L(C)=x∈X∑?P(x)l(x),其中 P ( x ) P(x) P(x) 為概率, l ( x ) l(x) l(x) 為碼長,在計算機中,我們給哪一匹馬奪冠這個事件進行編碼,所需要的平均碼長為 1.75 1.75 1.75 個位元,
??為了盡可能減少碼長,我們要給發生概率 P ( x ) P(x) P(x) 較大的事件,分配較短的碼長 l ( x ) l(x) l(x) ,這樣就可以得出霍夫曼編碼的概念,
??那么 { A , B , C , D } \{A,B,C,D\} {A,B,C,D} 四個事件,可以分別由 { 0 , 10 , 110 , 111 } \{0, 10, 110, 111\} {0,10,110,111} 表示,顯然我們要把最短的碼 0 0 0 分配給發生概率最高的事件 A A A ,以此類推,而且得到的平均碼長為 1.75 1.75 1.75 位元,如果我們硬要反其道而行之,給事件 A A A 分配最長的碼 111 111 111 ,那么平均碼長就會變成 2.625 2.625 2.625 位元,
??霍夫曼編碼就是利用了這種大概率事件分配短碼的思想,而且可以證明這種編碼方式是最優的,我們可以證明:
-
為了獲得資訊熵為 H ( X ) H(X) H(X) 的隨機變數 X X X 的一個樣本,平均需要拋擲均勻硬幣(或二元問題) H ( X ) H(X) H(X) 次(參考猜賽馬問題的案例)
-
資訊熵的大小是資料壓縮程序中能達到的一個臨界值,
3.3.2.2 聯合熵
??與聯合自資訊相同,我們可以定義兩個隨機變數 X X X 和 Y Y Y 的聯合熵為:
H ( X , Y ) = ? ∑ x ∈ X ∑ y ∈ Y P ( x , y ) log ? P ( x , y ) = ? ∑ x ∈ X ∑ y ∈ Y P ( x , y ) log ? ( P ( x ) P ( y ∣ x ) ) = ? ∑ x ∈ X ∑ y ∈ Y P ( x , y ) log ? P ( x ) ? ∑ x ∈ X ∑ y ∈ Y P ( x , y ) log ? P ( y ∣ x ) = ? ∑ x ∈ X P ( x ) log ? P ( x ) ? ∑ x ∈ X ∑ y ∈ Y P ( x , y ) log ? P ( y ∣ x ) = H ( X ) + H ( Y ∣ X ) \begin{aligned}H(X, Y)&=-\sum_{x \in X} \sum_{y \in Y} P(x, y) \log P(x, y) \\&=-\sum_{x \in X} \sum_{y \in Y} P(x, y) \log (P(x) P(y \mid x)) \\&=-\sum_{x \in X} \sum_{y \in Y} P(x, y) \log P(x)-\sum_{x \in X} \sum_{y \in Y} P(x, y) \log P(y \mid x) \\&=-\sum_{x \in X} P(x) \log P(x)-\sum_{x \in X} \sum_{y \in Y} P(x, y) \log P(y \mid x) \\&=H(X)+H(Y \mid X)\end{aligned} H(X,Y)?=?x∈X∑?y∈Y∑?P(x,y)logP(x,y)=?x∈X∑?y∈Y∑?P(x,y)log(P(x)P(y∣x))=?x∈X∑?y∈Y∑?P(x,y)logP(x)?x∈X∑?y∈Y∑?P(x,y)logP(y∣x)=?x∈X∑?P(x)logP(x)?x∈X∑?y∈Y∑?P(x,y)logP(y∣x)=H(X)+H(Y∣X)?
??在物理意義其度量了一個聯合分布的隨機系統的不確定度,觀察了該隨機系統的資訊量,
??當事件 X = A , Y = B X=A, Y=B X=A,Y=B 同時發生且相互獨立時,有 P ( X = A , Y = B ) = P ( X = A ) × P ( Y = B ) P(X=A,Y=B)=P(X=A)\times P(Y=B) P(X=A,Y=B)=P(X=A)×P(Y=B) ,此時資訊熵
H ( A , B ) = H ( A ) + H ( B ) H(A,B)=H(A)+H(B) H(A,B)=H(A)+H(B)
也即當隨機變數 X , Y X,Y X,Y 相互獨立時,有
H ( X , Y ) = H ( X ) + H ( Y ) H(X,Y)=H(X)+H(Y) H(X,Y)=H(X)+H(Y)
3.3.2.3 互資訊
??兩個隨機變數 X X X 和 Y Y Y 的互資訊定義為:
I ( X , Y ) = ∑ x ∈ X ∑ y ∈ Y P ( x , y ) log ? ( P ( x , y ) P ( x ) ? P ( y ) ) = ∑ x ∈ X ∑ y ∈ Y P ( x , y ) log ? P ( x , y ) ? ∑ x ∈ X ∑ y ∈ Y P ( x , y ) log ? ( P ( x ) ? P ( y ) ) = ? ∑ x ∈ X ∑ y ∈ Y P ( x , y ) log ? P ( x ) ? ∑ x ∈ X ∑ y ∈ Y P ( x , y ) log ? P ( y ) ? ( ? ∑ x ∈ X ∑ y ∈ Y P ( x , y ) log ? P ( x , y ) ) = ? ∑ x ∈ X P ( x ) log ? P ( x ) ? ∑ y ∈ Y P ( y ) log ? P ( y ) ? ( ? ∑ x ∈ X ∑ y ∈ Y P ( x , y ) log ? P ( x , y ) ) = H ( X ) + H ( Y ) ? H ( X , Y ) = H ( Y ) ? H ( Y ∣ X ) = H ( X ) ? H ( X ∣ Y ) = H ( X , Y ) ? H ( Y ∣ X ) ? H ( X ∣ Y ) \begin{aligned}I(X, Y)=&\sum_{x \in X} \sum_{y \in Y} P(x, y) \log \left(\frac{P(x, y)}{P(x) * P(y)}\right) \\&=\sum_{x \in X} \sum_{y \in Y} P(x, y) \log P(x, y)-\sum_{x \in X} \sum_{y \in Y} P(x, y) \log (P(x) * P(y)) \\&=-\sum_{x \in X} \sum_{y \in Y} P(x, y) \log P(x)-\sum_{x \in X} \sum_{y \in Y} P(x, y) \log P(y)-\left(-\sum_{x \in X} \sum_{y \in Y} P(x, y) \log P(x, y)\right) \\&=-\sum_{x \in X} P(x) \log P(x)-\sum_{y \in Y} P(y) \log P(y)-\left(-\sum_{x \in X} \sum_{y \in Y} P(x, y) \log P(x, y)\right) \\&=H(X)+H(Y)-H(X, Y) \\&=H(Y)-H(Y \mid X) \\&=H(X)-H(X \mid Y) \\&=H(X, Y)-H(Y \mid X)-H(X \mid Y)\end{aligned} I(X,Y)=?x∈X∑?y∈Y∑?P(x,y)log(P(x)?P(y)P(x,y)?)=x∈X∑?y∈Y∑?P(x,y)logP(x,y)?x∈X∑?y∈Y∑?P(x,y)log(P(x)?P(y))=?x∈X∑?y∈Y∑?P(x,y)logP(x)?x∈X∑?y∈Y∑?P(x,y)logP(y)?????x∈X∑?y∈Y∑?P(x,y)logP(x,y)???=?x∈X∑?P(x)logP(x)?y∈Y∑?P(y)logP(y)?????x∈X∑?y∈Y∑?P(x,y)logP(x,y)???=H(X)+H(Y)?H(X,Y)=H(Y)?H(Y∣X)=H(X)?H(X∣Y)=H(X,Y)?H(Y∣X)?H(X∣Y)?
??當
X
,
Y
X, Y
X,Y 不相互獨立時:
I
(
X
,
Y
)
=
H
(
X
)
+
H
(
Y
)
?
H
(
X
,
Y
)
I(X,Y)=H(X)+H(Y)-H(X,Y)
I(X,Y)=H(X)+H(Y)?H(X,Y)
??互資訊代表一個隨機變數包含另一個隨機變數資訊量的度量,其物理意義表明了兩事件單獨發生的資訊量是有重復的,互資訊度量了這種重復的資訊量大小,在一個點到點通信系統中,發送端信號為 X X X ,通過信道后,接收端接收到的信號為 Y Y Y ,那么資訊通過信道傳遞的資訊量就是互資訊 I ( X , Y ) I(X,Y) I(X,Y),根據這個概念,香農推出了非常偉大的公式,香農公式,給出了臨界通信傳輸速率的值,即信道容量:
C = B log ? ( 1 + S N ) C=B\log(1+\dfrac S N) C=Blog(1+NS?)
3.3.2.4 條件熵
??兩個隨機變數 X X X 和 Y Y Y 的條件熵定義為:
H ( Y ∣ X ) = ∑ x ∈ X P ( x ) H ( Y ∣ x ) = ? ∑ x ∈ X P ( x ) ∑ y ∈ Y P ( y ∣ x ) log ? P ( y ∣ x ) = ? ∑ x ∈ X ∑ y ∈ Y P ( x , y ) log ? P ( x , y ) P ( x ) = ? ∑ x ∈ X ∑ y ∈ Y P ( x , y ) log ? P ( x , y ) + ∑ x ∈ X ∑ y ∈ Y P ( x , y ) log ? P ( x ) = ? ∑ x ∈ X ∑ y ∈ Y P ( x , y ) log ? P ( x , y ) + ∑ x ∈ X P ( x ) log ? P ( x ) = H ( X , Y ) ? H ( X ) \begin{aligned}H(Y \mid X)&=\sum_{x \in X} P(x) H(Y \mid x)=-\sum_{x \in X} P(x) \sum_{y \in Y} P(y \mid x) \log P(y \mid x) \\&=-\sum_{x \in X} \sum_{y \in Y} P(x, y) \log \frac{P(x, y)}{P(x)} \\&=-\sum_{x \in X} \sum_{y \in Y} P(x, y) \log P(x, y)+\sum_{x \in X} \sum_{y \in Y} P(x, y) \log P(x) \\&=-\sum_{x \in X} \sum_{y \in Y} P(x, y) \log P(x, y)+\sum_{x \in X} P(x) \log P(x) \\&=H(X, Y)-H(X)\end{aligned} H(Y∣X)?=x∈X∑?P(x)H(Y∣x)=?x∈X∑?P(x)y∈Y∑?P(y∣x)logP(y∣x)=?x∈X∑?y∈Y∑?P(x,y)logP(x)P(x,y)?=?x∈X∑?y∈Y∑?P(x,y)logP(x,y)+x∈X∑?y∈Y∑?P(x,y)logP(x)=?x∈X∑?y∈Y∑?P(x,y)logP(x,y)+x∈X∑?P(x)logP(x)=H(X,Y)?H(X)?
??條件熵度量了在已知隨機變數 X X X 的條件下隨機變數 Y Y Y 的不確定性,也即在 X X X 已知的條件下,獲得 Y Y Y 對于整體資訊量的增加情況,有:
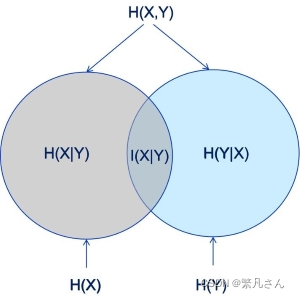
H ( X , Y ) = H ( X ) + H ( Y ∣ X ) = H ( Y ) + H ( X ∣ Y ) \begin{aligned}H(X,Y)&=H(X)+H(Y\mid X) \\&=H(Y)+H(X\mid Y)\end{aligned} H(X,Y)?=H(X)+H(Y∣X)=H(Y)+H(X∣Y)?
它們組成的 Venn 圖如圖 3.11 所示:
??
3.3.2.5 資訊熵的鏈式法則
三個隨機變數的互資訊可以表示成:
H ( X 1 , X 2 , X 3 ) = H ( X 1 ) + H ( X 2 ∣ X 1 ) + H ( X 3 ∣ X 1 , X 2 ) H\left(X_{1}, X_{2}, X_{3}\right)=H\left(X_{1}\right)+H\left(X_{2} \mid X_{1}\right)+H\left(X_{3} \mid X_{1}, X_{2}\right) H(X1?,X2?,X3?)=H(X1?)+H(X2?∣X1?)+H(X3?∣X1?,X2?)
則對于 n n n 個隨機變數 X 1 , … , X n X_1,\dots,X_n X1?,…,Xn? 以及 P ( x 1 , x 2 , … , x n ) P(x_1,x_2,\dots,x_n) P(x1?,x2?,…,xn?),它們的資訊熵可以由鏈式法則表達為:
H ( X 1 , X 2 , … X n ) = H ( X 1 ) + H ( X 2 ∣ X 1 ) + ? + H ( X n ∣ X n ? 1 … , X 1 ) = ∑ i = 1 n H ( X i ∣ X 1 , … , X i ? 1 ) \begin{aligned}H(X_1,X_2,\dots X_n)&=H(X_1)+H(X_2\mid X_1)+\cdots+H(X_n\mid X_{n-1}\dots,X_1)\\&=\sum_{i=1}^n H(X_i\mid X_1, \dots,X_{i-1})\end{aligned} H(X1?,X2?,…Xn?)?=H(X1?)+H(X2?∣X1?)+?+H(Xn?∣Xn?1?…,X1?)=i=1∑n?H(Xi?∣X1?,…,Xi?1?)?
3.3.3 相對熵(KL 散度)
??相對熵(Relative Entropy),也叫 KL 散度 (Kullback-Leibler Divergence),具有非負的特性,用于衡量兩個分布之間距離的指標,用 P P P 分布近似 Q Q Q 的分布,相對熵可以計算這個中間的損失,但是不對稱( P P P 對 Q Q Q 和 Q Q Q 對 P P P 不相等),因此不能表示兩個分布之間的距離,這種非對稱性意味著選擇 D K L ( P ∥ Q ) D_{\mathrm{KL}}(P\|Q) DKL?(P∥Q) 還是 D K L ( Q ∥ P ) D_{\mathrm{KL}}(Q\|P) DKL?(Q∥P) 影響很大,當 P = Q P =Q P=Q 時, 相對熵( K L \mathrm{KL} KL 散度) D K L ( P ∥ Q ) D_{\mathrm{KL}} (P\|Q) DKL?(P∥Q)取得最小值 0 0 0,
??如果對于同一個隨機變數 x {x} x 有兩個單獨的概率分布 P ( x ) P(x) P(x) 和 Q ( x ) Q(x) Q(x),我們就可以使用 K L \mathrm{KL} KL 散度來衡量這兩個分布的差異, K L \mathrm{KL} KL 散度越小,真實分布與近似分布之間的匹配就越好,
D K L ( P ∥ Q ) = E x ~ P [ log ? P ( x ) Q ( x ) ] = E x ~ P [ log ? P ( x ) ? log ? Q ( x ) ] D_{\mathrm{KL}}(P \| Q)=\mathbb{E}_{\mathrm{x} \sim P}\left[\log \frac{P(x)}{Q(x)}\right]=\mathbb{E}_{\mathrm{x} \sim P}[\log P(x)-\log Q(x)] DKL?(P∥Q)=Ex~P?[logQ(x)P(x)?]=Ex~P?[logP(x)?logQ(x)]
其中 D S K ( P ∥ Q ) D_{\mathrm SK}(P\|Q) DSK?(P∥Q) 的值域 P , Q P,Q P,Q 分布的接近程度是呈正相關的,
我們將
K
L
\mathrm{KL}
KL 散度公式變形得到:
D
K
L
(
P
∥
Q
)
=
E
x
~
P
[
log
?
P
(
x
)
?
log
?
Q
(
x
)
]
=
E
x
~
P
[
log
?
P
(
x
)
]
?
E
x
~
P
[
log
?
Q
(
x
)
]
=
?
H
(
P
)
?
E
x
~
P
[
log
?
Q
(
x
)
]
=
H
Q
(
P
)
?
H
P
(
P
)
\begin{aligned}D_{\mathrm{KL}}(P \| Q)&=\mathbb{E}_{\mathrm{x} \sim P}[\log P(x)-\log Q(x)]\\&=\mathbb{E}_{\mathrm{x}\sim{P}}[\log{P(x)}]-\mathbb{E}_{\mathrm{x}\sim{P}}[\log{Q(x)}]\\&=-H(P)-\mathbb{E}_{\mathbf{x}\sim P}[\log Q(x)]\\&=H_Q(P)-H_P(P)\end{aligned}
DKL?(P∥Q)?=Ex~P?[logP(x)?logQ(x)]=Ex~P?[logP(x)]?Ex~P?[logQ(x)]=?H(P)?Ex~P?[logQ(x)]=HQ?(P)?HP?(P)?
為了保證 K L \mathrm{KL} KL 散度的連續性,約定:
0 log ? 0 0 = 0 , 0 log ? 0 Q = 0 , P log ? P 0 = ∞ 0 \log \frac{0}{0}=0,0 \log \frac{0}{Q}=0, P \log \frac{P}{0}=\infty 0log00?=0,0logQ0?=0,Plog0P?=∞
當 P = Q P=Q P=Q 時,兩者之間的相對熵 D K L ( P ∥ Q ) = 0 D_{\mathrm{KL}}(P\|Q)=0 DKL?(P∥Q)=0
?? E q . ( ) Eq.() Eq.() 中的 H Q ( P ) H_Q(P) HQ?(P) 表示使用分布 Q Q Q ,對分布 P P P 進行編碼所需的平均編碼 b i t \mathrm{bit} bit 數, H P ( P ) H_P(P) HP?(P) 表示使用分布 P P P ,對分布 P P P 編碼所需的最小編碼 b i t \mathrm{bit} bit 數,因此相對熵的的意義可以理解為: D K L ( P ∥ Q ) D_{\mathrm{KL}}(P\|Q) DKL?(P∥Q) 表示對于分布 P P P ,使用 Q Q Q 分布進行編碼相較于使用真實分布 P P P 進行編碼(即最優編碼)多出來的 b i t \mathrm{bit} bit 數,也即是兩個分布之間的差異,
??在機器學習中,
P
P
P 往往用來表示樣本的真實分布,
Q
Q
Q 用來表示模型所預測的分布,那么
K
L
\mathrm{KL}
KL 散度就可以計算兩個分布的差異,也就是 損失函式
L
\mathcal L
L:
D
K
L
(
P
∥
Q
)
=
E
x
~
P
[
log
?
P
(
x
)
Q
(
x
)
]
=
∑
i
=
1
n
P
(
x
i
)
log
?
P
(
x
i
)
Q
(
x
i
)
D_{\mathrm{KL}}(P\|Q)=\mathbb{E}_{\mathrm{x} \sim P}\left[\log \frac{P(x)}{Q(x)}\right]=\sum_{i=1}^n{P(x_i)\log{\frac{P(x_i)}{Q(x_i)}}}
DKL?(P∥Q)=Ex~P?[logQ(x)P(x)?]=i=1∑n?P(xi?)logQ(xi?)P(xi?)?
離散:
D
K
L
(
P
∣
∣
Q
)
=
?
∑
i
P
(
i
)
ln
?
Q
(
i
)
P
(
i
)
=
∑
i
P
(
i
)
ln
?
P
(
i
)
Q
(
i
)
D_{\mathrm{KL}}(P||Q)=-\sum_iP(i)\ln\frac{Q(i)}{P(i)}=\sum_iP(i)\ln\frac{P(i)}{Q(i)}
DKL?(P∣∣Q)=?i∑?P(i)lnP(i)Q(i)?=i∑?P(i)lnQ(i)P(i)?
連續:
D
K
L
(
P
∣
∣
Q
)
=
∫
?
∞
∞
p
(
x
)
ln
?
p
(
x
)
q
(
x
)
d
x
D_{\mathrm{KL}}(P||Q)=\int_{-\infty}^{\infty}p(x)\ln\frac{p(x)}{q(x)}dx
DKL?(P∣∣Q)=∫?∞∞?p(x)lnq(x)p(x)?dx
我們可以利用不等式 log ? x ≤ x ? 1 \log x\le x-1 logx≤x?1 即可證明 K L \mathrm{KL} KL 散度一定大于 0 0 0:
考慮連續的 K L \mathrm{KL} KL 散度,設有兩個概率密度 P ( x ) , Q ( x ) P(x),Q(x) P(x),Q(x),假設 Q ( x ) > 0 Q(x)>0 Q(x)>0,則有 K L \mathrm{KL} KL 散度:
D ( P ∥ Q ) = ∫ P ( x ) log ? P ( x ) Q ( x ) dx = ? ∫ P ( x ) log ? Q ( x ) P ( x ) dx ≥ ? ∫ P ( x ) ( Q ( x ) P ( x ) ? 1 ) dx = ? ∫ Q ( x ) ? P ( x ) dx 【概率密度函式積分值等于 1】 = 0 \begin{aligned}D(P \| Q)&=\int P(x) \log \frac{P(x)}{Q(x)} \text{dx}\\&=-\int P(x) \log \frac{Q(x)}{P(x)} \text{dx} \\&\geq-\int P(x)\left(\frac{Q(x)}{P(x)}-1\right) \text{dx} \\&=-\int Q(x)-P(x) \text{dx}&\text{【概率密度函式積分值等于 1】}\\&=0\end{aligned} D(P∥Q)?=∫P(x)logQ(x)P(x)?dx=?∫P(x)logP(x)Q(x)?dx≥?∫P(x)(P(x)Q(x)??1)dx=?∫Q(x)?P(x)dx=0?【概率密度函式積分值等于 1】?
得證 □ \square □
更多 K L \mathrm{KL} KL 散度影像上的直觀解釋詳見:初學機器學習:直觀解讀KL散度的數學概念
3.3.4 交叉熵
??我們在上一節 3.3.3 相對熵(KL 散度) 中得到 K L \mathrm{KL} KL 散度的公式:
D K L ( P ∥ Q ) = H Q ( P ) ? H P ( P ) D_{\mathrm{KL}}(P \| Q)=H_Q(P)-H_P(P) DKL?(P∥Q)=HQ?(P)?HP?(P)
其中 H Q ( P ) H_Q(P) HQ?(P) 表示使用分布 Q Q Q ,對分布 P P P 進行編碼所需的平均編碼 b i t \mathrm{bit} bit 數, H P ( P ) H_P(P) HP?(P) 表示使用分布 P P P ,對分布 P P P 編碼所需的最小編碼 b i t \mathrm{bit} bit 數,
?????????? \,\,\,\,\,\,\,\,\,\, 因此我們定義 交叉熵(Cross Entropy) C E H ( P , Q ) = H Q ( P ) CEH(P,Q)=H_Q(P) CEH(P,Q)=HQ?(P),即:
C E H ( P , Q ) = H Q ( P ) = ? E x ~ P log ? Q ( x ) = ? ∑ i = 0 n P ( x i ) log ? b Q ( x i ) \begin{aligned}CEH(P,Q)&=H_Q(P)\\&=-\mathbb{E}_{x\sim P}\log{Q\left(x\right)}\\&=-\sum_{i=0}^n P(x_i) \log _{b}Q(x_i)\end{aligned} CEH(P,Q)?=HQ?(P)=?Ex~P?logQ(x)=?i=0∑n?P(xi?)logb?Q(xi?)?
表示使用分布 Q Q Q ,對分布 P P P 進行編碼所需的平均編碼 b i t \mathrm{bit} bit 數,
??至此,我們定義的 P P P 與 Q Q Q 之間的交叉熵 C E H CEH CEH 就等于 P P P 的熵 H ( P ) H(P) H(P) 與 P , Q P,Q P,Q 的 K L \mathrm{KL} KL 散度 D K L ( P ∥ Q ) D_{\mathrm{KL}}(P\|Q) DKL?(P∥Q) 之和:
C E H ( P , Q ) = H ( P ) + D K L ( P ∥ Q ) CEH(P,Q)=H(P)+D_{\mathrm{KL}}(P\|Q) CEH(P,Q)=H(P)+DKL?(P∥Q)
??????????
\,\,\,\,\,\,\,\,\,\,
由于
K
L
\mathrm{KL}
KL 散度是不對稱的,顯然交叉熵也是不對稱的:
C
E
H
(
P
,
Q
)
≠
C
E
H
(
Q
,
P
)
D
K
L
(
P
∣
Q
)
≠
D
K
L
(
Q
∣
P
)
\begin{aligned}CEH(P, Q) & \neq CEH(Q, P) \\D_{K L}(P \mid Q) & \neq D_{K L}(Q \mid P)\end{aligned}
CEH(P,Q)DKL?(P∣Q)??=CEH(Q,P)?=DKL?(Q∣P)?
??在機器學習任務中,我們希望使用分布 Q Q Q 去擬合分布 P P P ,需要評估標簽與預測值之間的差距,可以直接使用 K L \mathrm {KL} KL 散度,即 D K L ( y ∥ y ^ ) D_{\mathrm{KL}}(\mathbf{y}\|\hat{\mathbf{y}}) DKL?(y∥y^?),而由于分布 P P P 不變,即 H ( P ) H(P) H(P) 保持不變,交叉熵 C E H ( P , Q ) CEH(P,Q) CEH(P,Q) 的變化就可以直接反映出相對熵 D K L ( P ∥ Q ) D_{\mathrm{KL}}(P\|Q) DKL?(P∥Q) 的變化,由于相對熵 D K L ( P ∥ Q ) D_{\mathrm{KL}}(P\|Q) DKL?(P∥Q) 中包含定值 H ( P ) H(P) H(P) ,是一個不可優化的常數,且實驗表明交叉熵在訓練時相較于相對熵更加 健壯(robust),因此我們一般直接用交叉熵作為損失函式來評估模型,而不是使用相對熵 K L \mathrm{KL} KL 散度,
??交叉熵可以很好地衡量
2
2
2 個分布之間的差別,特別地,當分類問題中
y
y
y 的編碼分布
P
P
P 采用 one-hot 編碼時:
H
(
y
)
=
0
H(\boldsymbol{y}) = 0
H(y)=0,此時
C
E
H
(
y
,
o
)
=
H
(
y
)
+
D
K
L
(
y
∣
o
)
=
D
K
L
(
y
∣
o
)
CEH(\boldsymbol{y}, \boldsymbol{o})=H(\boldsymbol{y})+D_{K L}(\boldsymbol{y} | \boldsymbol{o})=D_{K L}(\boldsymbol{y} | \boldsymbol{o})
CEH(y,o)=H(y)+DKL?(y∣o)=DKL?(y∣o)
退化到真實標簽分布
y
\boldsymbol y
y 與輸出概率分布
o
\boldsymbol o
o 之間的
K
L
\mathrm{KL}
KL 散度上,
根據 K L \mathrm{KL} KL 散度的定義,我們推導分類問題中交叉熵的計算運算式:
C E H ( y , o ) = D K L ( y ∣ o ) = ∑ j y j log ? ( y j o j ) = 1 × log ? 1 o i + ∑ j ≠ i 0 × log ? ( 0 o j ) = ? log ? o i \begin{aligned}CEH(\boldsymbol{y}, \boldsymbol{o})&=D_{K L}(\boldsymbol{y} | \boldsymbol{o})=\sum_{j} y_{j} \log \left(\frac{y_{j}}{o_{j}}\right)\\&=1 \times \log \frac{1}{o_{i}}+\sum_{j \neq i} 0 \times \log \left(\frac{0}{o_{j}}\right) \\&=-\log o_{i}\end{aligned} CEH(y,o)?=DKL?(y∣o)=j∑?yj?log(oj?yj??)=1×logoi?1?+j?=i∑?0×log(oj?0?)=?logoi??
其中 𝑖 𝑖 i 為 one-hot 編碼中為 1 1 1 的索引號,也是當前輸入的真實類別,可以看到,損失函式 L \mathcal L L 只與真實類別 𝑖 𝑖 i 上的概率 o i \boldsymbol o_i oi? 有關,對應概率 o i \boldsymbol o_i oi? 越大, H ( 𝒚 , 𝒐 ) H(𝒚, 𝒐) H(y,o) 越小,當對應概率為 1 1 1 時,交叉熵 H ( 𝒚 , 𝒐 ) H(𝒚, 𝒐) H(y,o) 取得最小值 0 0 0 ,此時網路輸出 𝒐 𝒐 o 與真實標簽 𝒚 𝒚 y 完全一致,神經網路取得最優狀態,最小化交叉熵的程序也是最大化正確類別的預測概率的程序,
3.3.5 JS 散度
?????????? \,\,\,\,\,\,\,\,\,\, JS 散度 (Jensen-Shannon Divergence),度量了兩個概率分布的相似度,是基于 K L \mathrm{KL} KL 散度的變體,解決了 K L \mathrm{KL} KL 散度非對稱的問題,
??????????
\,\,\,\,\,\,\,\,\,\,
一般地,JS 散度是對稱的,其取值是
0
0
0 到
1
1
1 之間,定義如下:
J
S
(
P
1
∥
P
2
)
=
1
2
K
L
(
P
1
∥
P
1
+
P
2
2
)
+
1
2
K
L
(
P
2
∥
P
1
+
P
2
2
)
JS(P_1\|P_2)=\frac{1}{2}KL(P_1\|\frac{P_1+P_2}{2})+\frac{1}{2}KL(P_2\|\frac{P_1+P_2}{2})
JS(P1?∥P2?)=21?KL(P1?∥2P1?+P2??)+21?KL(P2?∥2P1?+P2??)
?????????? \,\,\,\,\,\,\,\,\,\, 因而JS散度擁有對稱性,并且在形式上更為平滑,更適合作為最后最大似然的函式,這點在生成對抗網路(GAN)的損失函式取得了不錯的成績,
KL 散度和 JS 散度的問題
?????????? \,\,\,\,\,\,\,\,\,\, 如果兩個分布 P , Q P,Q P,Q 離得很遠,完全沒有重疊的時候,那么 KL 散度值是沒有意義的,而 JS 散度值是一個常數,這在學習演算法中是比較致命的,這就意味著這一點的梯度為 0 0 0,出現了梯度消失現象,導致訓練失敗,
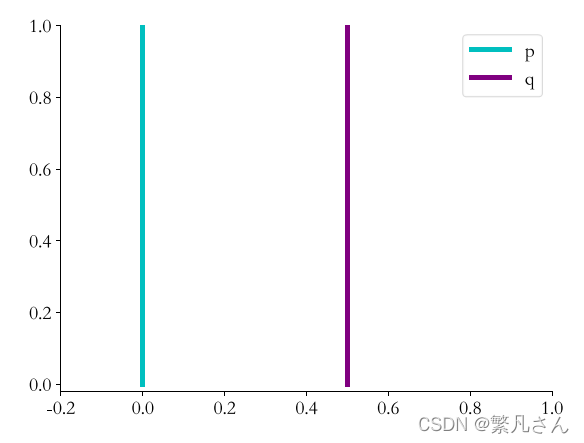
?????????? \,\,\,\,\,\,\,\,\,\, 這里通過一個簡單的分布實體來解釋 JS 散度的缺陷,考慮完全不重疊 ( θ ≠ 0 \theta\neq 0 θ?=0)的兩個分布 p p p 和 q q q ,其中分布 p p p 為:
? ( x , y ) ∈ p , x = 0 , y ~ U ( 0 , 1 ) \begin{array}{l}\forall(x, y) \in p, x=0, y \sim \mathrm{U}(0,1) \\\end{array} ?(x,y)∈p,x=0,y~U(0,1)?
分布 q q q 為:
? ( x , y ) ∈ q , x = θ , y ~ U ( 0 , 1 ) \forall(x, y) \in q, x=\theta, y \sim \mathrm{U}(0,1) ?(x,y)∈q,x=θ,y~U(0,1)
其中 θ ∈ R \theta \in \R θ∈R,當 θ = 0 \theta = 0 θ=0 時,分布 p p p 和 q q q 重疊,兩者相等;當 θ ≠ 0 \theta \neq 0 θ?=0 時,分布 p p p 和 q q q 不重疊,分布 p p p 和 q q q 的示意圖如圖 3.12 所示,
??
我們來分析上述分布 p p p 和 q q q 之間的 JS 散度隨 θ \theta θ 的變化情況,根據 KL 散度與 JS 散度的定義,計算 θ = 0 \theta = 0 θ=0 時的 JS 散度 D J S ( p ∥ q ) D_{\mathrm{JS}}(p\|q) DJS?(p∥q):
D K L ( p ∥ q ) = ∑ x = 0 , y ~ U ( 0 , 1 ) 1 ? log ? 1 0 = + ∞ D K L ( q ∥ p ) = ∑ x = θ , y ~ U ( 0 , 1 ) 1 ? log ? 1 0 = + ∞ D J S ( p ∥ q ) = 1 2 ( ∑ x = 0 , y ~ U ( 0 , 1 ) 1 ? log ? 1 1 / 2 + ∑ x = 0 , y ~ U ( 0 , 1 ) 1 ? log ? 1 1 / 2 ) = log ? 2 D_{K L}(p \| q)=\sum_{x=0, y \sim \mathrm{U}(0,1)} 1 \cdot \log \frac{1}{0}=+\infty \\D_{K L}(q \| p)=\sum_{x=\theta, y \sim \mathrm{U}(0,1)} 1 \cdot \log \frac{1}{0}=+\infty \\D_{J S}(p \| q)=\frac{1}{2}\left(\sum_{x=0, y \sim U(0,1)} 1 \cdot \log \frac{1}{1 / 2}+\sum_{x=0, y \sim U(0,1)} 1 \cdot \log \frac{1}{1 / 2}\right)=\log 2 DKL?(p∥q)=x=0,y~U(0,1)∑?1?log01?=+∞DKL?(q∥p)=x=θ,y~U(0,1)∑?1?log01?=+∞DJS?(p∥q)=21????x=0,y~U(0,1)∑?1?log1/21?+x=0,y~U(0,1)∑?1?log1/21????=log2
當 θ = 0 \theta =0 θ=0 時,兩個分布完全重疊,此時的 JS 散度和 KL 散度都取得最小值,即 D K L ( p ∥ q ) = D K L ( q ∥ p ) = D J S ( p ∥ q ) = 0 D_{K L}(p \| q)=D_{K L}(q \| p)=D_{J S}(p \| q)=0 DKL?(p∥q)=DKL?(q∥p)=DJS?(p∥q)=0,
至此我們可以得到 D J S ( q ∥ p ) D_{\mathrm{JS}}(q\|p) DJS?(q∥p) 隨 θ \theta θ 的變化趨勢:
D J S ( p ∥ q ) = { log ? 2 θ ≠ 0 0 θ = 0 D_{\mathrm{JS}}(p \| q)=\left\{\begin{array}{cc}\log 2 & \theta \neq 0 \\0 & \theta=0\end{array}\right. DJS?(p∥q)={log20?θ?=0θ=0?
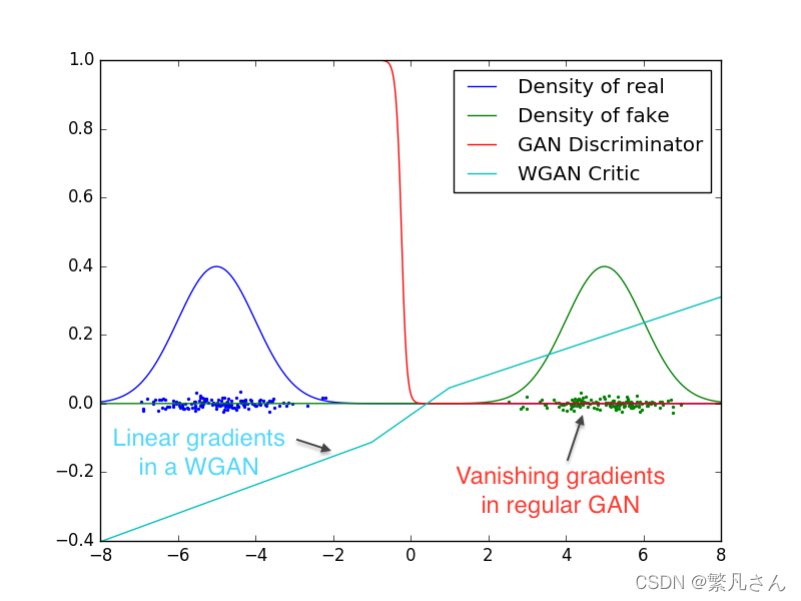
也就是說,當兩個分布完全不重疊時,無論分布之間的距離遠近,JS 散度為恒定值 log ? 2 \log 2 log2,此時 JS 散度將無法產生有效的梯度資訊;當兩個分布出現重疊時,JS 散度才會平滑變動,產生有效梯度資訊;當完全重合后,JS 散度取得最小值 0 0 0,如圖 3.13 中所示,紅色的曲線分割兩個正態分布,由于兩個分布沒有重疊,生成樣本位置處的梯度值始終為 0 0 0,無法更新生成網路的引數,從而出現網路訓練困難的現象,
??
因此,JS 散度在分布 p p p 和 q q q不重疊時是無法平滑地衡量分布之間的距離,從而導致此位置上無法產生有效梯度資訊,出現 GAN 訓練不穩定的情況,要解決此問題,需要使用一種更好的分布距離衡量標準,使得它即使在分布 p p p 和 q q q 不重疊時,也能平滑反映分布之間的真實距離變化,
3.3.6 Wasserstein 距離
Wasserstein距離 ,度量兩個概率分布之間的距離,WGAN 論文發現了 JS 散度導致 GAN 訓練不穩定的問題,并引入了一種新的分布距離度量方法:Wasserstein 距離,它表示了從一個分布變換到另一個分布的最小代價,定義如下:
W
(
P
1
,
P
2
)
=
inf
?
γ
~
∏
(
P
1
,
P
2
)
E
(
x
,
y
)
~
γ
[
∥
x
?
y
∥
]
W(P_1,P_2)=\inf_{\gamma\sim\prod(P_1,P_2)}\mathbb{E}_{(x,y)\sim\gamma}[\left\|x-y\right\|]
W(P1?,P2?)=γ~∏(P1?,P2?)inf?E(x,y)~γ?[∥x?y∥]
其中 ∏ ( P 1 , P 2 ) \prod(P_1,P_2) ∏(P1?,P2?) 是 P 1 P_1 P1? 和 P 2 P_2 P2? 分布組合起來的所有可能的聯合分布的集合,對于每一個可能的聯合分布 γ γ γ,可以從中采樣 ( x , y ) ~ γ (x,y)~γ (x,y)~γ 得到一個樣本 x x x 和 y y y,并計算出這對樣本的距離 ∥ x ? y ∥ \|x?y\| ∥x?y∥,所以可以計算該聯合分布 γ γ γ 下,樣本對距離的期望值 E ( x , y ) ~ γ [ ∣ ∣ x ? y ∣ ∣ ] E _{(x, y) ~ \gamma}[||x?y||] E(x,y)~γ?[∣∣x?y∣∣],在所有可能的聯合分布中能夠對這個期望值取到的下確界 inf ? γ ~ Π ( P 1 , P 2 ) E ( x , y ) ~ γ [ ∣ ∣ x ? y ∣ ∣ ] \inf_{\gamma ~ \Pi(P_1, P_2)} E _{(x, y) \sim \gamma}[||x?y||] infγ~Π(P1?,P2?)?E(x,y)~γ?[∣∣x?y∣∣] 就是 Wasserstein 距離,
直觀上可以把 E ( x , y ) ~ γ [ ∣ ∣ x ? y ∣ ∣ ] E _{(x, y) ~ \gamma}[||x?y||] E(x,y)~γ?[∣∣x?y∣∣] 理解為在 γ γ γ 這個路徑規劃下把土堆 P 1 P_1 P1? 挪到土堆 P 2 P_2 P2? 所需要的消耗,而 Wasserstein 距離就是在最優路徑規劃下的最小消耗,所以 Wesserstein 距離又稱推土機距離(Earth-Mover Distance,簡稱 EM 距離),
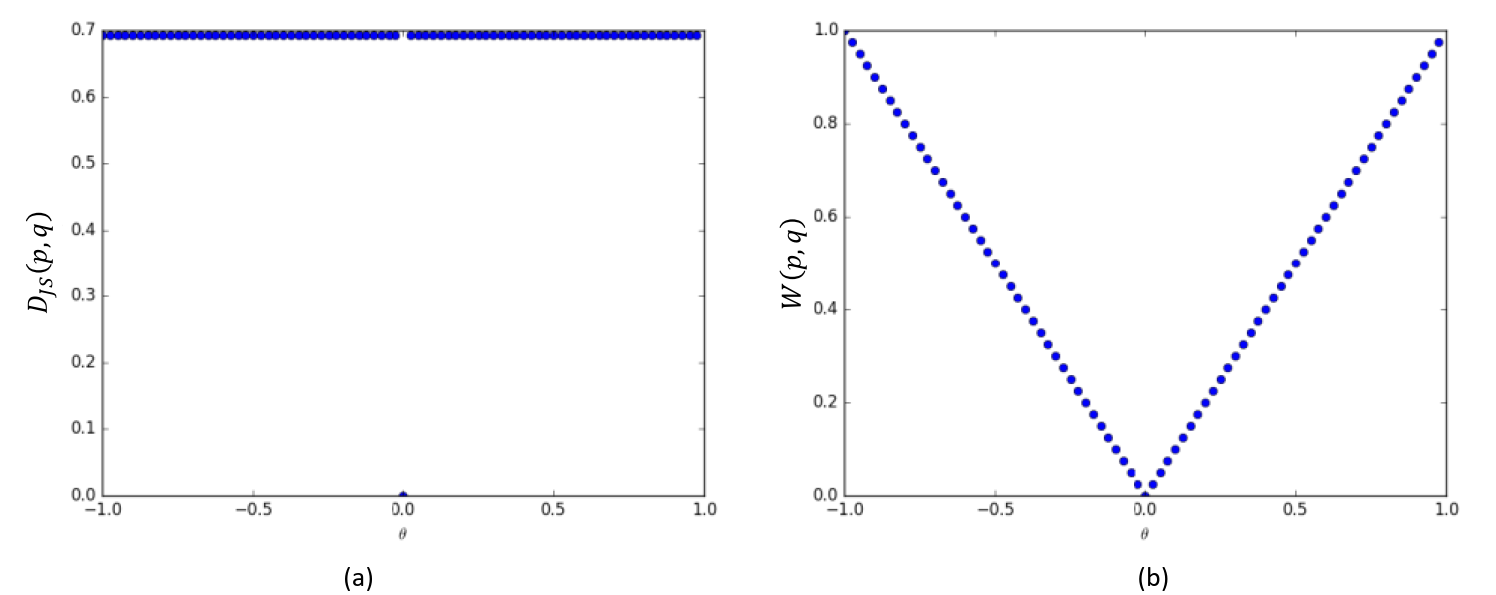
繼續考慮圖 3.12 中的示例,我們可以得出分布 p p p 和 q q q 之間的 EM 距離的運算式:
W ( p , q ) = ∣ θ ∣ W(p, q)=|\theta| W(p,q)=∣θ∣
繪制出 JS 散度和 EM 距離的曲線,如圖 3.14 所示,可以看到,JS 散度在 θ = 0 \theta=0 θ=0 處不連續,其他位置導數均為 0 0 0,而 EM 距離總能夠產生有效的導數資訊,因此 EM 距離相對于JS 散度更適合指導 GAN 網路的訓練,
??
Wessertein距離相比 KL 散度和 JS 散度的優勢在于:即使兩個分布的支撐集沒有重疊或者重疊非常少,仍然能反映兩個分布的遠近,而 JS 散度在此情況下是常量,KL 散度可能無意義,
更多關于Wasserstein 距離的講解詳見: GAN的Loss的比較研究(3)——Wasserstein Loss理解(1) 以及 令人拍案叫絕的Wasserstein GAN
參考資料
[1] 《2021春機器學習課程》李宏毅
https://speech.ee.ntu.edu.tw/~hylee/ml/2021-spring.html
[2]《TensorFlow深度學習》(龍龍老師)
https://github.com/dragen1860/Deep-Learning-with-TensorFlow-book
[3] Coursera吳恩達《神經網路與深度學習》
https://www.deeplearning.ai/
[4] 《動手學深度學習》第二版
https://zh-v2.d2l.ai/
[5] 《深度學習》(花書)
https://github.com/exacity/deeplearningbook-chinese
[6] relu函式為分段線性函式,為什么會增加非線性元素
https://www.cnblogs.com/lzida9223/p/10972783.html
[7] 【機器學習】神經網路-激活函式-面面觀(Activation Function)
https://blog.csdn.net/cyh_24/article/details/50593400
[8] Logistic Regression (LR) 詳解與更多相關的面試問題
https://blog.csdn.net/songbinxu/article/details/79633790
[9] 【機器學習】邏輯回歸(非常詳細)
https://zhuanlan.zhihu.com/p/74874291
[10] softmax回歸(Softmax Regression)
https://blog.csdn.net/u012328159/article/details/72155874
[11] 邏輯回歸演算法原理及用于解決多分類問題
https://blog.csdn.net/AIHUBEI/article/details/104301492
[12] 邏輯回歸(Logistic Regression)(二)
https://zhuanlan.zhihu.com/p/28415991
[13] 數學基礎_4——資訊論
https://blog.csdn.net/CesareBorgia/article/details/120817481
[14] 資訊論(1)——熵、互資訊、相對熵
https://zhuanlan.zhihu.com/p/36192699
[15] 一文讀懂機器學習分類演算法(附圖文詳解)
https://zhuanlan.zhihu.com/p/82114104
[16] An in-depth guide to supervised machine learning classification
https://builtin.com/data-science/supervised-machine-learning-classification
[17] 資訊熵是什么?- 知乎
https://www.zhihu.com/question/22178202/answer/223017546
[18] 熵 (資訊論) - 維基百科
https://zh.wikipedia.org/wiki/%E7%86%B5_(%E4%BF%A1%E6%81%AF%E8%AE%BA)
[19] 資訊熵到底是什么
https://blog.csdn.net/saltriver/article/details/53056816
[20] Visual Information Theory
https://colah.github.io/posts/2015-09-Visual-Information/#fnref1
[21] M. Arjovsky, S. Chintala 和 L. Bottou, “Wasserstein Generative Adversarial Networks,” Proceedings of the 34th International Conference on Machine Learning, International Convention Centre, Sydney, Australia, 2017.

??
轉載請注明出處:https://fanfansann.blog.csdn.net/
著作權宣告:本文為 CSDN 博主 「繁凡さん」(博客),知乎答主 「繁凡」(專欄),Github 「fanfansann」(全部原始碼),微信公眾號 「繁凡的小島來信」(文章 P D F 版))原創整理的文章,遵循CC 4.0 BY-NC-SA 著作權協議,轉載請附上原文出處鏈接及本宣告,
轉載請註明出處,本文鏈接:https://www.uj5u.com/qita/423690.html
標籤:AI