AI:大力出奇跡?Bigger is better?AI下一代浪潮?—人工智能的大語言模型(LLMs)的簡介、發展以及未來趨勢
目錄
人工智能的大語言模型(LLMs)—AI下一代浪潮?Bigger is better?大力出奇跡?
單體模型VS混合模型
大模型的意義
大模型的局限性
大模型的四個障礙
未來的AI藍圖要擁抱綠色低碳
2017年以來,大規模語言模型發展史
未來趨勢
人工智能的大語言模型(LLMs)—AI下一代浪潮?Bigger is better?大力出奇跡?
大型語言模型(LLMs)是在包含巨大資料量的大規模資料集上訓練的,中國工程院院士王恩東表示:“人工智能如何發展出像人類具備邏輯、意識和推理的認知能力,是人工智能研究一直探索的方向,目前來看,通過大規模資料訓練超大引數量的巨量模型,被認為是非常有希望實作通用人工智能的一個重要方向,”隨著巨量模型的興起,巨量化已成為未來人工智能發展非常重要的一個趨勢,而巨量化的一個核心特征就是模型引數多、訓練資料量大,
2018 年谷歌發布BERT,從此,預訓練模型(Pre-trained Models, PTMs)逐漸成為自然語言處理領域的主流,當然,預訓練模型如今已經成為深度學習研究中的一種主流范式,
2020年,GPT-3 橫空出世,這個具有 1750 億引數規模的預訓練模型所表現出來的零樣本與小樣本學習能力重繪了人們的認知,作為一個語言生成模型,GPT-3 不僅能夠生成流暢自然的文本,還能完成問答、翻譯、創作小說等一系列 NLP 任務,甚至進行簡單的算術運算,并且其性能在很多任務上都超越相關領域的專有模型,達到 SOTA 水平,從此,OpenAI開始引爆了 2021 年 AI 大模型研究的熱潮,大模型成為幾乎所有全球頭部AI公司的追逐目標,
在大模型的賽道上,算力公司、演算法公司、資料公司,研究機構正在展開新一輪競賽,
2021年,人工智能正式邁向“煉大模型”階段,開展了超大規模預訓練模型的“軍備競賽”,這一年,也被很多業界同行稱為超大規模預訓練模型的“爆發之年”,自去年 OpenAI 發布英文領域超大規模預訓練語言模型 GPT-3 后,中文領域同類模型的訓練行程備受關注,
國內外AI頭部公司,包括谷歌、微軟、英偉達、智源人工智能研究院、阿里、百度、華為、騰訊、浪潮等國內外科技巨頭和機構紛紛展開大模型研究和探索,近年來人工智能的發展,已經從“大煉模型”逐步邁向了“煉大模型”的階段,通過設計先進的演算法,整合盡可能多的資料,匯聚大量算力,集約化地訓練大模型,供大量企業使用,這是必然趨勢,
2021年1月,Google 推出的 Switch Transformer 模型以高達 1.6 萬億的引數量打破了 GPT-3 作為最大 AI 模型的統治地位,成為史上首個萬億級語言模型,
2021年6月,北京智源人工智能研究院發布了超大規模智能模型“悟道 2.0”,達到1.75 萬億引數,超過 Switch Transformer 成為全球最大的預訓練模型,
隨著處理能力和資料源的增長,深度學習中曾經的趨勢已經成為一個原則:越大越好,近年來,語言模型的規模越來越大,只有像Google、Microsoft、NVIDIA等大公司才可以玩轉千億/萬億級的大模型,而且事實證明以大模型為基礎探索通用智能的道路也遠遠沒有到盡頭,國內產業和學術界在對大模型的探索上也亦步亦趨,大規模的AI設備集群和通用性的軟硬體生態協同越來越成為資訊時代急需的基礎設施,未來制約人工智能發展的不僅僅是對人才的競爭,大科學裝置和對多場景應用的通用全堆疊式技術生態的不斷發展進化,也越來越重要,
單體模型VS混合模型
現在業界提高模型引數量有兩種技術路線,產生兩種不同的模型結構,一種是單體模型,一種是混合模型,如華為的盤古大模型、百度的文心大模型、英偉達聯合微軟發布的自然語言生成模型 MT-NLG 、浪潮的源大模型等走的都是單體模型路線;而智源的悟道模型、阿里 M6 等走的是混合模型路線,
大模型的意義
- 大模型被大多數專家認為是走向AGI的重要途徑之一,超大規模預訓練模型是從弱人工智能向通用人工智能的突破性探索,解決了傳統深度學習的應用碎片化難題,引發科研機構和企業重點投入,
- 大模型可以吸收海量知識,從里面提高模型的泛化能力,可以減少對領域資料標注的依賴,
- 超大規模預訓練模型在海量通用資料上進行預先學習和訓練,能有效緩解AI領域通用資料的激增與專用資料匱乏的矛盾,具備通用智能的雛形,
- 預訓練大模型普適性強,可滿足垂直行業的共性需求,預訓練大模型遷移性好,可滿足典型產品的技術要求,GPT-3凸顯了一種小樣本學習以及泛化能力,而且兩個層面的能力都非常優秀,
- 大模型承上啟下,深刻影響底層技術和上層應用的發展;向下驅動資料技術和計算架構能力的提升,支撐模型訓練、部署和優化,向上支撐上層應用的服務轉型,
- 模型的引數規模越大,優勢越明顯,
-
AIGC(AI生成內容)就是大模型落地的一個重要方向(內容消費/創意設計),
大模型的局限性
- 資本門檻:大模型的訓練,以GPT-3為例,訓練一次的成本是1200萬美金;
- 技術門檻:AI框架的深度優化和并行能力要求很高,
- 跨領域門檻:大模型多方向問題亟待解決,生態建設不容小覷,未來預訓練大模型將重點解決應用、可信、跨學科合作、資源不平衡和開放共享等問題,
大模型的四個障礙
Andrew NG 認為,構建越來越大的模型的努力帶來了自己的挑戰,龐大模型的開發人員必須克服四個巨大的障礙,
- 資料:大型模型需要大量資料,但網路和數字圖書館等大型來源可能缺乏高質量資料,例如,研究人員發現 BookCorpus 是一個包含 11,000 本電子書的集合,已被用于訓練 30 多個大型語言模型,可能會傳播對某些宗教的偏見,因為它缺乏討論基督教和伊斯蘭教以外信仰的文本, AI 社區越來越意識到資料質量至關重要,但尚未就編譯大規模、高質量資料集的有效方法達成共識,
- 速度:今天的硬體難以處理龐大的模型,當位反復進出記憶體時,這些模型可能會陷入困境,為了減少延遲,Switch Transformer 背后的 Google 團隊開發了一種方法,可以為每個令牌處理模型層的選定子集,他們最好的模型的預測速度比引數數量只有其 1/30 的模型快 66%,同時,微軟開發了 DeepSpeed 庫,它并行處理資料、單個層和層組,并通過在 CPU 和 GPU 之間劃分任務來減少冗余處理,
- 能源:訓練如此龐大的網路會消耗大量的電能, 2019 年的一項研究發現,使用化石燃料,在 8 個 Nvidia P100 GPU 上訓練一個 2 億引數的變壓器模型,在五年的駕駛程序中排放的二訊訓碳幾乎與一輛普通汽車一樣多,新一代有望加速人工智能的芯片,如 Cerebras 的 WSE-2 和谷歌最新的 TPU,可能有助于減少排放,同時風能、太陽能和其他清潔能源增加以滿足需求,
- 交付:這些龐大的模型太大而無法在消費者或邊緣設備上運行,因此大規模部署它們需要互聯網訪問(較慢)或精簡實施(能力較弱),
未來的AI藍圖要擁抱綠色低碳
不可否認,資料集和模型規模的增長,帶來了多種語言任務上準確率的顯著提升,并通過NLP 基準任務上的全面改進證明了這一點,
眾所周知,全球變暖是人類的行為造成地球氣候變化的后果,2020年9月,中國提出努力爭取在2060年前實作碳中和,為了能夠早日實作我國關于“碳中和”以及“碳達峰”的戰略目標,在今后的40年當中,中國在產業、消費、能源以及區域結構等方面都會做出重大整頓,
隨著“碳中和”逐步被提高到國家戰略的高度之上,人工智能行業,包括機器學習模型當然也要倡導追求碳中和,不應該把模型性能當作唯一標準,未來的AI藍圖要擁抱綠色低碳,助力實作碳達峰碳中和目標,
針對該問題,來自谷歌和美國加州大學伯克利分校的研究人員最近聯合發表一項研究論文,著重評估并比較了 5 個大型自然語言處理(NLP)模型的能耗和碳排放量,其中包括 T5、Meena、GShard、Switch Transformer 和 GPT-3,該論文提出,如果推出同時考量模型準確性和碳排放的標準,我們就可以想象一個良性回圈,通過加速演算法、系統、硬體、資料中心以及碳中和在效率和成本方面的創新,即可級訓機器學習任務碳足跡的日益增長,
相關文章:
《Carbon Emissions and Large Neural Network Training》 http://arxiv.org/abs/2104.10350v2
2017年以來,大規模語言模型發展史
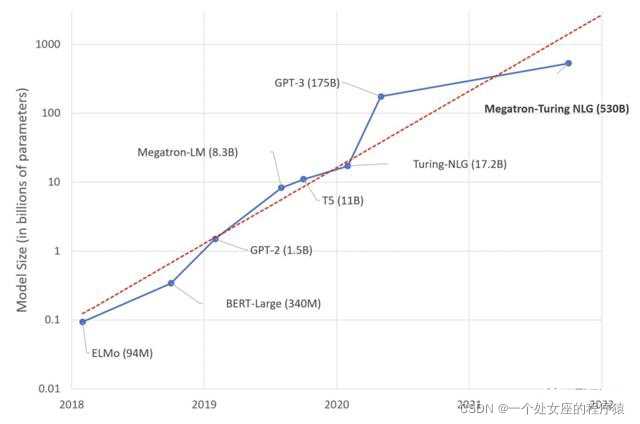
| 發布時間 | 大模型 | 引數量 | 訓練資料 | 多模態 | 功能 | 機構 |
| 2017年 | GPT-1 | 1.1億 | 文本 | OpenAI | ||
| 2018年 10月 | Bert | 3.4億 | 文本 | |||
| 2019年 08月 | GPT-2 | 15億 | 文本 | OpenAI | ||
| 2019年 08月 | MegatronLM | 83億 | 文本 | NVIDIA | ||
| 2020年01月 | Turing-NLG | 170 億 | 文本 | Microsoft | ||
| 2020年05月 | GPT-3 | 1750 億 | 45TB | 文本 | NLU,文本生成 | OpenAI |
| 2020年06月 | GShard | 6190 億 | 比擁有 1750 億引數的 GPT-3 消耗的能源少約 53 倍,凈碳排放量少約 127 倍,這主要得益于 GShard 在演算法+硬體上的多重優化, | |||
| 2021 年 01月 | Switch Transformer | 1.6萬億 | ||||
| 2021年03月 | CPM-1 (悟道2.0,文源) | 26億 | 文本 | NLU,文本生成 | 智源研究院 | |
| 2021年04月 | PLUG | 270億 | >1.1TB high-quality | 文本 | NLU,文本生成 | 阿里 |
| 2021年04月 | 盤古-α | 2000億 | 1.1TB high-quality | 文本 | NLU,文本生成 | 華為&回圈智能 |
| 2021年04月 | 孟子(BERT, T5,Oscar) | 10億 | 300GB | 文本,影像 | NLU,文本生成 | 瀾舟科技 |
| 2021年06月 | M6 | 1000億 | 1.9TB images | 文本,影像 | NLU,文本生成 | 阿里 |
| 2021年06月 | CPM-2 (悟道2.0) CPM-MoE | 總共1.75萬億 其中110億中文模型 110億中英模型 1980億中英MoE模型 | 2.3TB Chinese | 文本 | NLU,文本生成 | 智源研究院 |
| 2021年06月 | CogView(悟道-文匯) | 40億 | 30 million high-quality (Chinese) text-image pairs | 文本,影像 | 文本生成影像 | 智源研究院 |
| 2021年07月 | ERNIE3.0 | 100億 | 4TB text and KG | 文本 | NLU,文本生成 | 百度 |
| 2021年09月 | 源1.0 | 2457億 | 5TB high-quality | 文本 | NLU,文本生成 | 浪潮 |
| 2021年10月 | Megatron Turing-NLG 威震天-圖靈 | 5300億 | 文本 | NLU | Microsoft+NVIDIA | |
| 2021年10月 | 神農 | 10億 | 數百GB | 文本 | NLU,文本生成 | 騰訊 |
| 2021年12月 | Gopher | 2800億 | 10.5TB 的MassiveText語料庫 | 文本 | Gopher在 124 項評估任務中的 100 項中優于當前最先進的技術, | DeepMind |
| 2021年12月 | GLaM | 1.2 萬億 |
注:該表將持續更新
未來趨勢
清華大學教授、智源大模型技術委員會成員劉知遠說: “大規模預訓練模型是人工智能的最新技術高地,是對海量資料、高性能計算和學習理論原始創新的全方位考驗”,
大小模型協同進化,大模型引數競賽,在未來某個時刻,會進入冷靜期,大小模型將在云邊端協同進化,達摩院認為,因性能與能耗提升不成比例,受效率問題的限制,大模型引數競賽將進入冷靜期,大小模型云邊端協同進化會是未來趨勢, 大模型向邊、端的小模型輸出模型能力,小模型負責實際的推理與執行,同時小模型再向大模型反饋演算法與執行成效,讓大模型的能力持續強化,形成有機回圈的智能體系,
相關文章
NLP之PLUG:阿里達摩院發布最大中文預訓練語言模型PLUG的簡介、架構組成、模型訓練、使用方法之詳細攻略_一個處女座的程式猿-CSDN博客
Top AI Stories of 2021: Transformers Take Over, Models Balloon, Multimodal AI Takes Off, Governments Crack Down - The Batch | DeepLearning.AI
AI中文大模型匯總 - 知乎
轉載請註明出處,本文鏈接:https://www.uj5u.com/qita/423692.html
標籤:AI