文章目錄
- train_test_split()用法
- 獲取資料
- 劃分訓練集和測驗集
- 完整代碼腳手架
train_test_split()用法
python機器學習中常用 train_test_split()函式劃分訓練集和測驗集,其用法語法如下:
- X_train, X_test, y_train, y_test = train_test_split(train_data, train_target, test_size, random_state, shuffle)
| 變數 | 描述 |
|---|---|
| X_train | 劃分的訓練集資料 |
| X_test | 劃分的測驗集資料 |
| y_train | 劃分的訓練集標簽 |
| y_test | 劃分的測驗集標簽 |
| 引數 | 描述 |
|---|---|
| train_data | 還未劃分的資料集 |
| train_target | 還未劃分的標簽 |
| test_size | 分割比例,默認為0.25,即測驗集占完整資料集的比例 |
| random_state | 亂數種子,應用于分割前對資料的洗牌,可以是int,RandomState實體或None,默認值=None,設成定值意味著,對于同一個資料集,只有第一次運行是隨機的,隨后多次分割只要rondom_state相同,則劃分結果也相同, |
| shuffle | 是否在分割前對完整資料進行洗牌(打亂),默認為True,打亂 |
以sklearn庫內置的iris資料集(鳶尾資料集)為例,首先獲取資料:
獲取資料
from sklearn.model_selection import train_test_split
# 以sklearn庫內置的iris資料集(鳶尾資料集)為例
dataset = load_iris()
這里的dataset資料是sklearn.utils.Bunch型別的資料,比較像字典
將其列印出~
print(dataset)
如下所示

從中取出其data屬性和target屬性,X是特征陣列(也稱資料集),y表示類別陣列(也稱標簽)
X = dataset.data
y = dataset.target
此例中,有四個特征(即data的4串列示4個特征),分別是鳶尾植物的萼片的長,萼片的寬,花瓣的長,花瓣的寬,
X中共150行,即150個樣本,類別資料總共有150個資料(對應150個樣本的類別),
print(y)
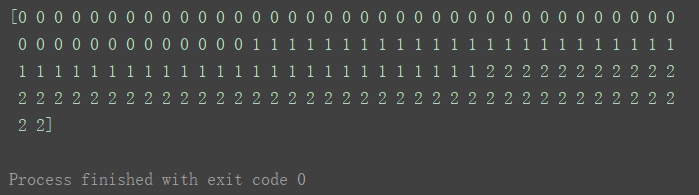
y的150個資料如上圖,其中,有0,1,2三個取值,表示三種花:
| 0 | 1 | 2 |
|---|---|---|
| Iris Setosa(山鳶尾) | Iris Versicolour(變色鳶尾) | Iris Virginica(維吉尼亞鳶尾) |
使用最簡單的離散化演算法,以均值為閾值,使大于閾值的特征值為1,小于閾值的特征值為0.
attribute_means = X.mean(axis=0)
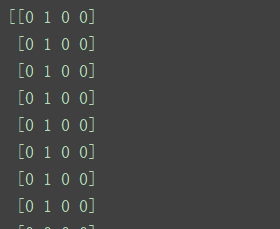
X_d = np.array(X >= attribute_means, dtype='int') # bool轉換
print(X_d)
運行結果(成功將X的資料轉換為bool型別):
劃分訓練集和測驗集
然后就是使用train_test_split()函式將資料劃分訓練集和測驗集了,
random_state = 10
# 以默認的0.25作為分割比例進行分割(訓練集:測驗集=3:1)
X_train, X_test, y_train, y_test = train_test_split(X_d, y, random_state=random_state)
print("There are {} training samples".format(y_train.shape[0]))
print("There are {} testing samples".format(y_test.shape[0]))

如圖得到的資料中112/38接近3:1,分割成功!
完整代碼腳手架
(將上述分步的代碼寫在一塊兒方便復制使用):
from sklearn.model_selection import train_test_split
dataset = load_iris()
X = dataset.data
y = dataset.target
attribute_means = X.mean(axis=0)
X_d = np.array(X >= attribute_means, dtype='int')
random_state = 10
X_train, X_test, y_train, y_test = train_test_split(X_d, y, random_state=random_state)
轉載請註明出處,本文鏈接:https://www.uj5u.com/qita/423694.html
標籤:AI