本文主要記錄個人學習筆記,參考了大量圖片,侵權聯系刪
Hadoop
狹義Hadoop:指的是HDFS,YARN,MAPREDUCE三大組件,值得注意的是2.x版本將原本負責資源管理和資料處理拆分位YARN 和 MR 兩個組件,這樣更加靈活,可以在2.0版本使用其他的資料處理組件比如Spark
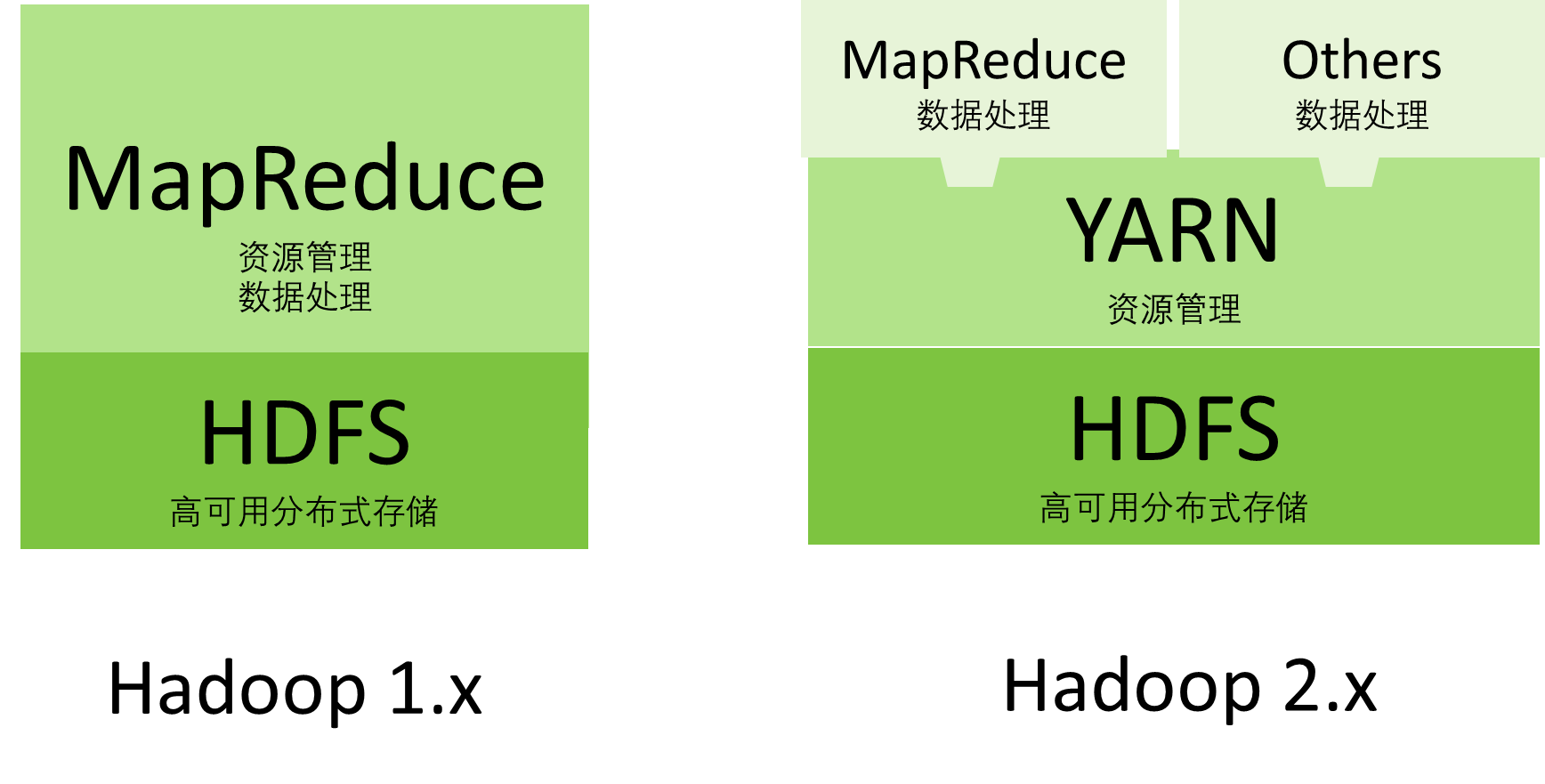
廣義Hadoop:指的是hadoop一系列的生態圈

1. HDFS架構
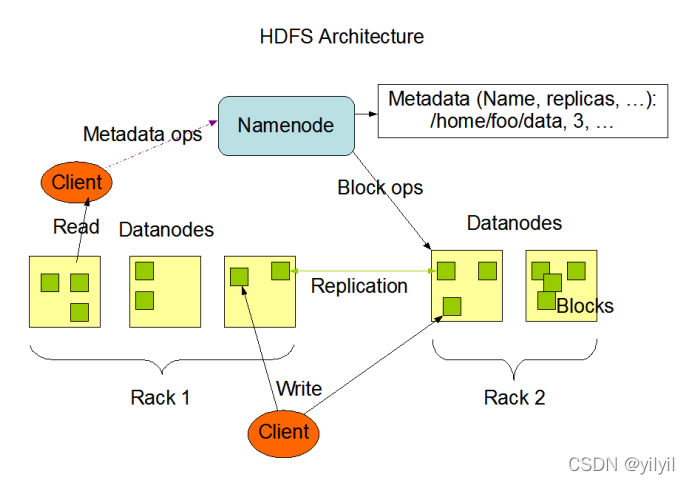
Hadoop Distributed File System (HDFS)是一個分布式檔案系統,與普通檔案系統不同的是,HDFS的檔案會被分為很多的Block分散存盤在不同機器上,高容量,高吞吐,高容錯,
1.1 NameNode與DataNode
NameNode是HDFS的核心,架構中的主角色,Client訪問入口,維護和管理檔案系統元資料(包括名稱空間目錄樹結構、檔案和塊的位置資訊、訪問權限等資訊)
NameNode是基于記憶體和磁盤的,因為要速度快,所以會將元資料放于記憶體中,記憶體斷點易失,所以需要持久化策略,采用基于快照疊加增量日志;其中磁盤上元資料檔案包括 FileSystemImage和 Edits log(Journal),對元資料產生增刪重命名會先往日志寫,另外的節點周期EditLog向FileSystemImage合并,減小EditLog大小,減少NameNode啟動時間(非HA使用SNN和HA使用StandbyNN)即New FileSystemImage= Old FileSystemImage+ EditsLog
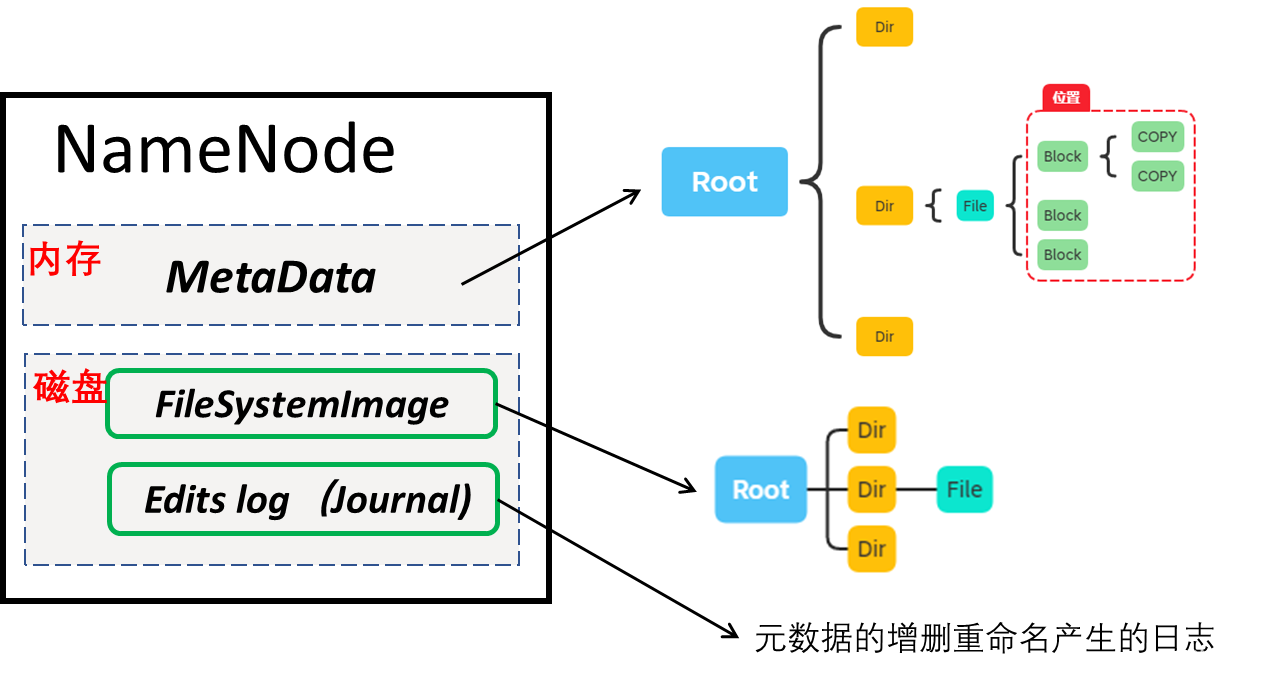
注意點
- NameNode不持久化存盤塊的位置資訊,這些資訊會在系統啟動時由DataNode匯報重建保存在記憶體中,并且如果有某些塊的副本數不足,不讓節點復制出對應的塊
- NameNode需要機器有大記憶體支持
DataNode:HDFS的檔案會被分為很多的Block基于本地磁盤存盤在一系列的DataNode中;保存block塊的校驗;與NameNode維持心跳匯報block串列狀態;執行由NameNode下達的創建洗掉復制的Block操作
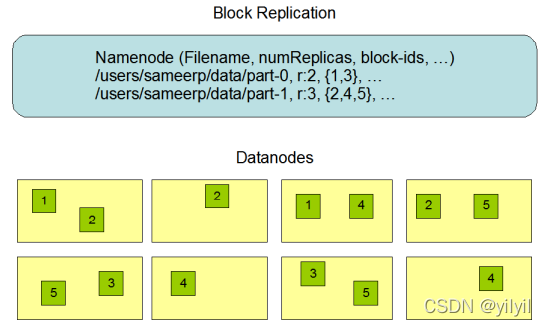
注意點:
- DataNode所在機器需要大磁盤支持
- 副本防治策略
- 第一個副本:本機DN,集群外提交,隨機挑選一臺磁盤不太滿,CPU不太忙的
- 第二個副本:與第一副本不同機架
- 第三個副本:與第二個副本同機架,不同服務器
- 更多副本:隨機節點
1.2 Block讀寫
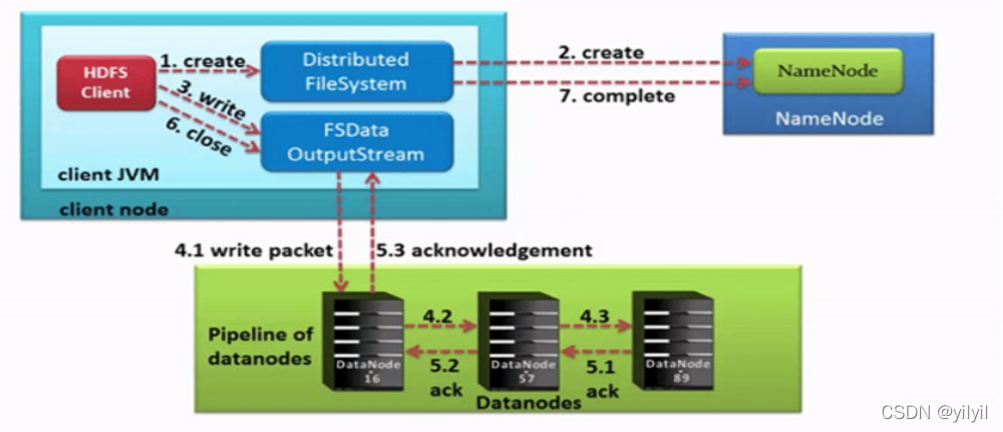
- HDFS客戶端創建物件實體
DistributedFileSystem, 該物件中封裝了與HDFS檔案系統操作的相關方法, - 呼叫
DistributedFileSystem物件的create()方法,通過RPC請求NameNode創建檔案,NameNode執行各種檢查判斷:目標檔案是否存在、父目錄是否存在、客戶端是否具有創建該檔案的權限,檢查通過,NameNode就會為本次請求記下一條記錄,回傳FSDataOutputStream輸出流物件給客戶端用于寫資料 - 客戶端通過
FSDataOutputStream輸出流開始寫入資料, - 客戶端寫入資料時,將資料分成一個個資料包(
packet 默認64k), 內部組件DataStreamer請求NameNode挑選出適合存盤資料副本的一組DataNode地址,默認是3副本存盤,DataStreamer將資料包流式傳輸到pipeline的第一個DataNode,該DataNode存盤資料包并將它發送到pipeline的第二個DataNode,同樣,第二個DataNode存盤資料包并且發送給第三個(也是最后一個)DataNode, - 傳輸的反方向上,會通過ACK機制校驗資料包傳輸是否成功;
- 客戶端完成資料寫入后,在
FSDataOutputStream輸出流上呼叫close()方法關閉, DistributedFileSystem聯系NameNode告知其檔案寫入完成,等待NameNode確認,
注意點:
- datanode之間采用pipeline線性傳輸,而不是拓撲式傳輸,這樣的好處在于避免了網路瓶頸和高延遲的連接,利用了每個機器的帶寬
- block分package傳輸,
- 為了pipeline傳輸的可靠性在用了pipeline上ack應答:pipeline反方向ack校驗
- NameNode怎么才算確認成功呢?因為namenode已經知道檔案由哪些塊組成(DataStream請求分配資料塊),因此僅需等待最小復制塊即可成功回傳,最小復制是由引數dfs.namenode.replication.min指定,默認是1.
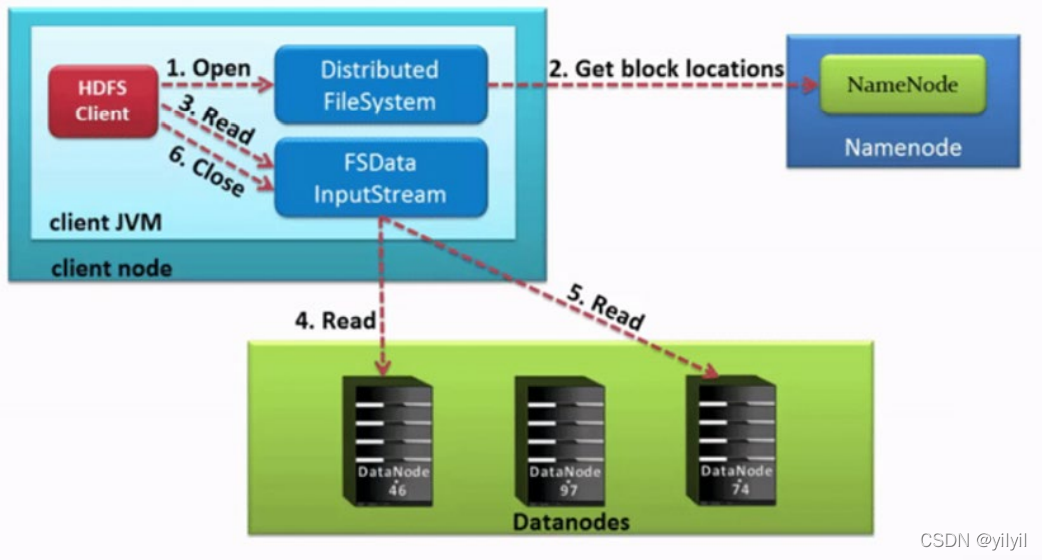
- HDFS客戶端創建物件實體
DistributedFileSystem, 呼叫該物件的open()方法來打開希望讀取的檔案, DistributedFileSystem使用RPC呼叫namenode來確定檔案中前幾個塊的塊位置(分批次讀取)資訊,對于每個塊,namenode回傳具有該塊所有副本的datanode位置地址串列,并且該地址串列是排序好的,與客戶端的網路拓撲距離近的排序靠前DistributedFileSystem將FSDataInputStream輸入流回傳到客戶端以供其讀取資料,- 客戶端在
FSDataInputStream輸入流上呼叫read()方法,然后,已存盤DataNode地址的InputStream連接到檔案中第一個塊的最近的DataNode,資料從DataNode流回客戶端,結果客戶端可以在流上重復呼叫read() - 當該塊結束時,FSDataInputStream將關閉與DataNode的連接,然后尋找下一個block塊的最佳datanode位置,這些操作對用戶來說是透明的,所以用戶感覺起來它一直在讀取一個連續的流,客戶端從流中讀取資料時,也會根據需要詢問NameNode來檢索下一批資料塊的DataNode位置資訊,
- 一旦客戶端完成讀取,就對FSDataInputStream呼叫close()方法
1.3 HDFS高可用
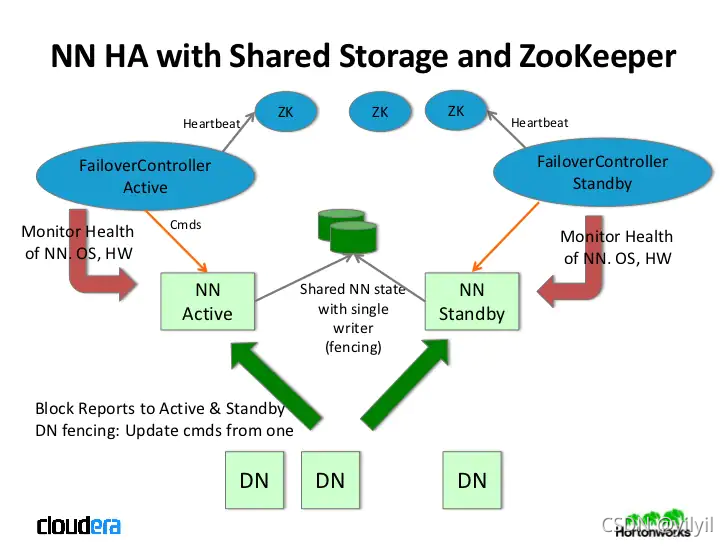
- 主備的NameNode:主備需要節點間資料,以保證切換可以使得集群正常運行,所以主備節點都與一組稱為"JournalNodes"(JN) 的單獨守護程式進行通信,當 Active 節點執行任何命名空間修改時,它會持久地將Edit log記錄到大多數這些 JN,Standby節點能夠從 JN 讀取Edit log,并不斷監視它們對Edit log的更改,發生修改,它會將它們應用于自己的命名空間,在發生故障轉移時,Standby 將確保在將自身提升為 active狀態之前,它會確保 JournalNodes 讀取了所有編輯內容,這可確保在發生故障轉移之前,命名空間狀態已完全同步;Standby節點還必須具有集群中塊位置的最新資訊,DataNode配置了所有NameNode的位置,并向所有NameNode發送塊位置資訊和檢測信號,
?必須至少有 3 個 JournalNode 守護程式,因為Edit log修改必須寫入大多數 JN,這將允許系統容忍單個計算機的故障,您也可以運行 3 個以上的 JournalNode,但為了實際增加系統可以容忍的故障數,您應該運行奇數個 JN(即 3、5、7 等),請注意,當使用 N 個JN運行時,系統最多可以容忍 (N - 1) / 2 次故障并繼續正常運行,?
2. MapReduce
MapReduce 易于編程,良好擴展,適合海量資料離線計算,但實時計算差,不能流式計算
分而治之的思想,分為兩個階段 map ,reduce
| map: 對一組資料元素進行某種重復式的處理 | reduce: 對Map的中間結果進行某種進一步的結果整理 |
|---|---|
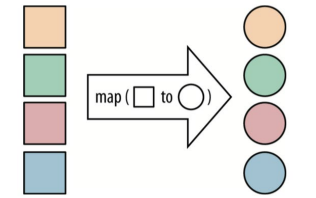 | 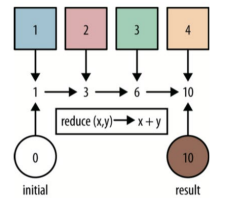 |
2.1 MAP
- 第一階段:把輸入目錄下檔案按照一定的標準逐個進行
邏輯切片,對input split 中的資料按照一定的規則讀取決議回傳<key,value>對,
邏輯切片:即將一批資料分成幾份處理,默認Split size = Block size(128M),得到多個input split,
每一個切片由一個MapTask處理
規則讀取:默認是按行讀取資料,key是每一行的起始位置偏移量,value是本行的文本內容,(TextInputFormat)
-
第二階段:呼叫Mapper類中的map方法處理資料,
每讀取決議出來的一個<key,value>,呼叫一次map方法 -
第三階段:Map輸出的中間結果會先放在記憶體緩沖區中,按照一定的規則對Map輸出的鍵值對進行磁區partition,
默認不磁區,因為只有一個reducetask,
磁區的數量就是reducetask運行的數量,
- 第四階段:Map輸出資料寫入記憶體緩沖區,達到比例溢位到磁盤上,溢位spill的時候根據key進行排序sort,
默認根據key字典序排序,
- 第五階段:對所有溢位檔案進行最終的merge合并,成為一個檔案
2.2 Reduce
- 第一階段:ReduceTask會
主動從MapTask復制拉取屬于需要自己磁區處理的資料, - 第二階段:把拉取來資料,
全部進行合并merge,即把分散的資料合并成一個大的資料,再對合并后的資料排序 - 第三階段:是對
排序后的鍵值對呼叫reduce方法,鍵相等的鍵值對呼叫一次reduce方法,最后把這些輸出的鍵值對寫入到HDFS檔案中
2.3 shuffle
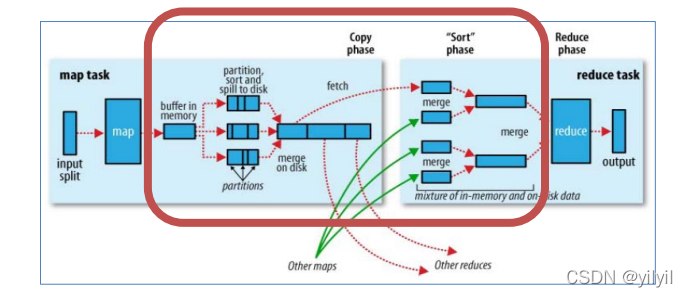
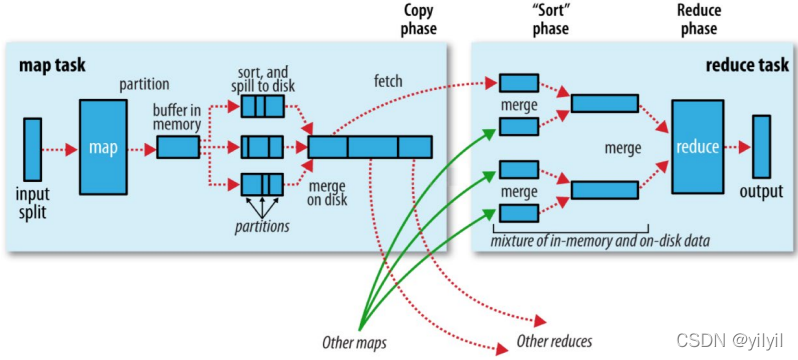
Map端Shuffle [收集-溢寫-合并]
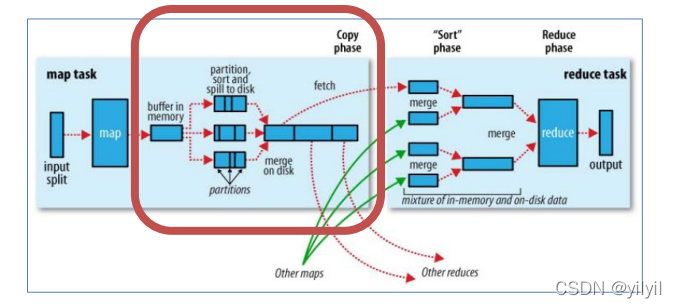
- Collect階段:將MapTask的結果收集輸出到默認大小為100M的環形緩沖區,保存之前會對key進行磁區的計算,
默認Hash磁區,
- Spill階段:當記憶體中的資料量達到一定的閥值的時候,就會將資料寫入本地磁盤,在將資料寫入磁盤之前需要對數
據進行一次排序的操作,如果配置了combiner,還會將有相同磁區號和key的資料進行排序,
- Merge階段:把所有溢位的臨時檔案進行一次合并操作,以確保一個MapTask最終只產生一個中間資料檔案
Reduce端shuffle [拉去-合并-排序]
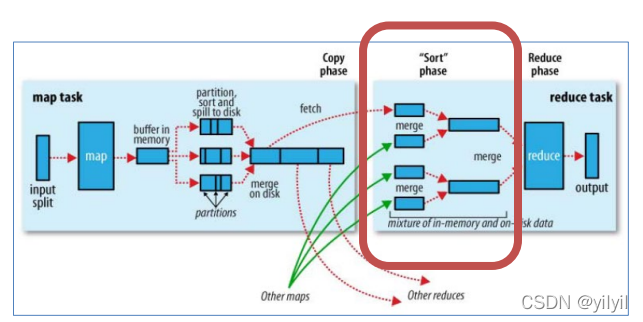
- Copy階段: ReduceTask啟動Fetcher執行緒到已經完成MapTask的節點上復制一份屬于自己的資料,
- Merge階段:在ReduceTask遠程復制資料的同時,會在后臺開啟兩個執行緒對記憶體到本地的資料檔案進行合并操作
- Sort階段:在對資料進行合并的同時,會進行排序操作,由于MapTask階段已經對資料進行了區域的排序,ReduceTask只需保證Copy的資料的最終整體有效性即可,
Shuffle弊端
- Shuffle是MapReduce程式的核心與精髓,是MapReduce的靈魂所在,
- Shuffle也是MapReduce被詬病最多的地方所在,MapReduce相比較于Spark、Flink計算引擎慢的原因,跟Shuffle機制有很大的關系,
- Shuffle中頻繁涉及到資料在記憶體、磁盤之間的多次往復,
注意:
- 一個MR只能包含一個,不能有多個連續的mapper,連續多個reduce
- MR程式,資料都是以k:v形式流轉,所以在每個階段我們要考慮清楚輸入輸出的kv是什么
- MapReduce計算引擎天生的弊端(慢),使用率小,但是某些軟體的背后還依賴MapReduce引擎
3. YARN
Apache Hadoop YARN (Yet Another Resource Negotiator,另一種資源協調者)是一種新的Hadoop資源管理器,YARN是一個通用資源管理系統和調度平臺,可為上層應用提供統一的資源管理和調度

- 資源管理系統:集群的硬體資源,和程式運行相關,比如記憶體、CPU等,
- 調度平臺:多個程式同時申請計算資源如何分配,調度的規則(演算法),
- 通用:不僅僅支持MapReduce程式,理論上支持各種計算程式,YARN不關心你干什么,只關心你要資源,在有的情況下給你,用完之后還我,正是因為YARN的包容,使得其他計算框架能專注于計算性能的提升
3.1 YARN 架構
YARN角色

物理資源管理角色:
ResourceManager:YARN集群中的主角色,決定系統中所有應用程式之間資源分配的最終權限,即最終仲裁者,有如下核心組件
- Resource Scheduler:負責根據application的要求
分配資源 - ApplicationsManager:
所有application的總負責人,負責接受client端的application
NodeManager:YARN中的從角色,一臺機器上一個,負責管理本機器上的計算資源,負責監容器資源(cpu,memory,disk,network)的使用,并報告給Scheduler
- MRAppMaster:
每個app的負責人,用戶提交的每個應用程式均包含一個AM - MapTask ,Ruduce Task:會根據分配,分配到對應的Node上
資源管理獨立出來
App Master 沒有資源管理,不是長啟動任務調度
3.1 YARN流程
MR程式有三類行程:
- MRAppMaster:負責整個MR程式的程序調度及狀態協調
- MapTask:負責map階段的整個資料處理流程
- ReduceTask:負責reduce階段的整個資料處理流程
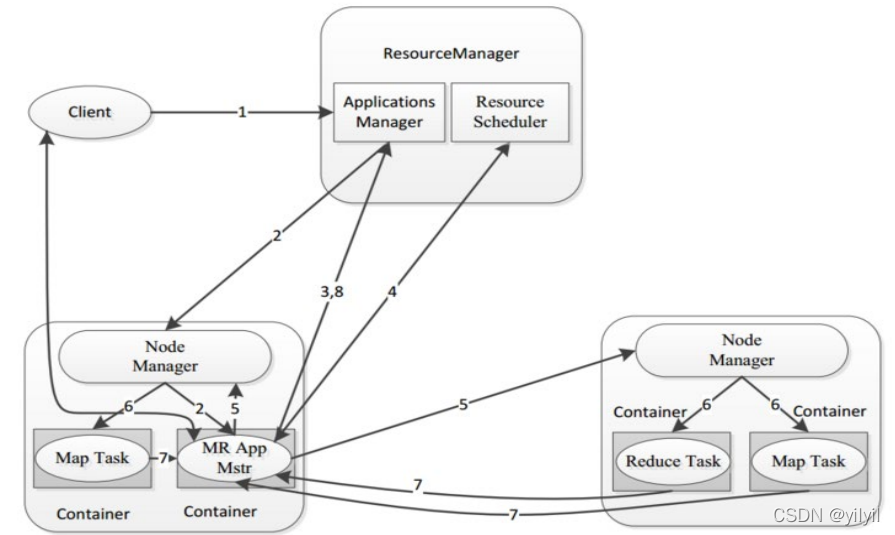
- 第1步:用戶通過客戶端向YARN中ResourceManager提交應用程式(比如hadoop jar提交MR程式);
- 第2步:ResourceManager為該應用程式分配第一個Container(容器),并與對應的NodeManager通信,要求它在這個Container中啟動這個應用程式的MRAppMaster
- 第3步:MRAppMaster啟動成功之后,首先向ResourceManager注冊并保持通信,這樣用戶可以直接通過ResourceManage查看應用程式的運行狀態(處理了百分之幾);
- 第4步:MRAppMaster為本次程式內部的各個Task任務向RM申請資源,并監控它的運行狀態;
- 第5步:一旦 MRAppMaster申請到資源后,便與對應的 NodeManager 通信,要求它啟動任務,
- 第6步:NodeManager 為任務設定好運行環境后,將任務啟動命令寫到一個腳本中,并通過運行該腳本啟動任務
- 第7步:各個任務通過某個 RPC 協議向 MRAppMaster匯報自己的狀態和進度,以讓 MRAppMaster隨時掌握各個任務的運行狀態,從而可以在任務失敗時重新啟動任務,在應用程式運行程序中,用戶可隨時通過
RPC 向 MRAppMaster查詢應用程式的當前運行狀態, - 第8步:應用程式運行完成后,MRAppMaster向 ResourceManager 注銷并關閉自己
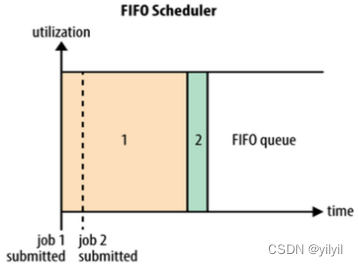
3.2 調度策略
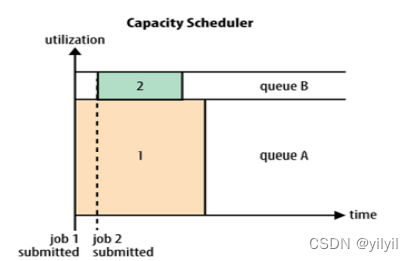
| FIFO | Capactiy | Fair |
|---|---|---|
 |  | Fair schedule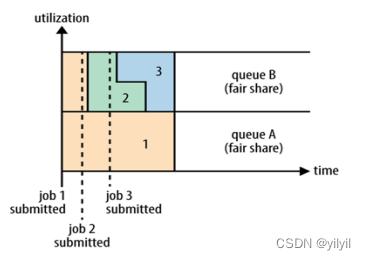 |
| 易容配置,不適合有優先順序的任 | 多組織共享集群資源,每個組織分配專門的佇列,,但容易產生浪費 | 隨著時間的流逝任務獲取公平的資源 |
hive 下載地址 https://dlcdn.apache.org/hive/hive-2.3.9/
hive 檔案: https://cwiki.apache.org/confluence/display/Hive/AdminManual
4. HIVE
4.1 數倉
資料倉庫(英語:Data Warehouse,簡稱數倉、DW),是一個用于存盤、分析、報告的資料系統,是一個集成化的專業的資料分析平臺,方便決策
數倉本身并不產生資料,資料來自于外部系統,同時不消費資料,結果給其他外部應用使用,所以才叫倉庫而不是工廠
聯機事務處理系統(OLTP)正好可以滿足上述業務需求開展, 其主要任務是執行聯機事務處理,其基本特征是前臺接收的用戶資料可以立即傳送到后臺進行處理,并在很短的時間內給出處理結果,關系型資料庫(RDBMS)是OLTP典型應用
為什么不在資料庫里分析?資料分析也是對資料進行讀取操作,會讓讀取壓力倍增,OLTP僅存盤數周或數月的資料,資料分散在不同系統不同表中,欄位型別屬性不統一
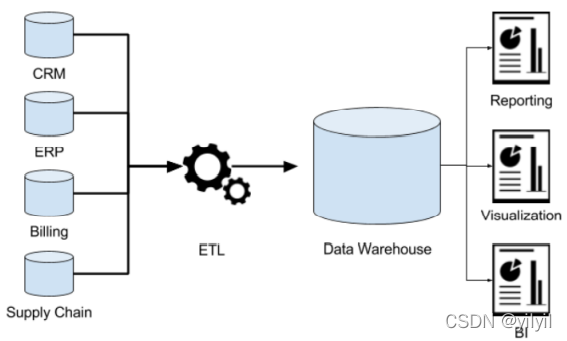
數倉特性:
- 面向主題:確定分析物件
- 集成性:各個資料源需要集成到數倉,并且各個系統對某一主題內部的命名與格式不同,所以不同資料源到數倉時需要去除這些不一致,經過ETL(抽取,轉換,加載)的操作
- 非易變性:只分析,很少不修改內容
- 時變性:離線分析往往分析過去的資料,資料會與時間有關,所以就有些T+1報表(第二天分析前一天)
4.2 HIVE
Hive的存盤用的HDFS,計算用的MR,本身并沒有干什么,主要提供了一種SQL來進行資料分析的能力,Hive核心是將HQL轉換為MapReduce程式,然后將程式提交到Hadoop群集執行
HIVE可以將存盤在Hadoop檔案中的結構化、半結構化資料檔案映射為一張資料庫表,基于表提供了一種類似SQL的查詢模型,稱為Hive查詢語言(HQL),用于訪問和分析存盤在Hadoop檔案中的大型資料集
HIVE也有局限性,結構化、半結構化的要求,無結構的圖片,視頻很難做映射,這種映射是需要存盤,存盤進去的往往就是一些元資料資訊
4.3 HIVE 架構
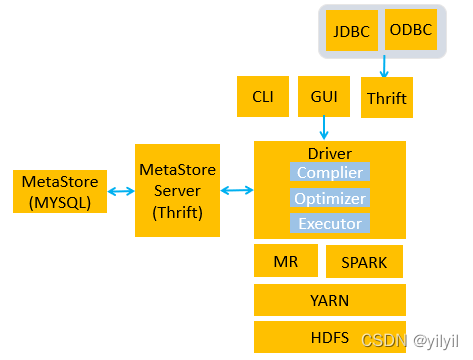
發請求給Driver源資料檢查是否有元資料是否存在,不存在直接回傳,有就編譯優化生成jar,driver提jar給hadoop執行
-
CLI(Command Line Interface):用戶可以使用Hive自帶的命令列介面執行Hive QL、設定引數等功能
-
JDBC/ODBC:用戶可以使用JDBC或者ODBC的方式在代碼中操作Hive
-
Web GUI:瀏覽器介面,用戶可以在瀏覽器中對Hive進行操作(2.2之后淘汰)
-
Thrift : Thrift服務運行客戶端使用Java、C++、Ruby等多種語言,通過編程的方式遠程訪問Hive
-
Driver:Hive Driver是Hive的核心,其中包含解釋器、編譯器、優化器等各個組件,完成從SQL陳述句到MapReduce任務的決議優化執行程序
- 解釋器:呼叫語法解釋器和語意分析器將SQL陳述句轉換成對應的可執行的java代碼或者業務代碼
- 編譯器:將對應的java代碼轉換成位元組碼檔案或者jar包
- 優化器:從SQL陳述句到java代碼的決議轉化程序中需要呼叫優化器,進行相關策略的優化,實作最優的 查詢性能
- 執行器:當業務代碼轉換完成之后,需要上傳到MapReduce的集群中執行
- metastore
? Hive的元資料存盤服務,一般將資料存盤在關系型資料庫中,為了實作Hive元資料的持久化操作,Hive的安裝包中自帶了Derby記憶體資料庫,但是在實際的生產環境中一般使用mysql來存盤元資料
why:Derby 記憶體 元資料不可以持久化了,意外這每次重啟都會有資料加載的程序;MYSQL 元資料可以持久化了
官方提供了兩種方式實作元資料管理中心
- 第一種:元資料存盤服務(MetaStore Server)沒有與HIVE分離
- 第二種:元資料存盤服務(MetaStore Server)與HIVE核心分離 ,這個單獨抽離的服務為Thrift,Thrift使得HIVE核心和元資料存盤(MetaStore)解耦,MYSQL可以變為Oracle;并且單獨抽離出來的Thrift,可以給其他提供服務(比如spark-sql)
4.4 HIVE 可用客戶端
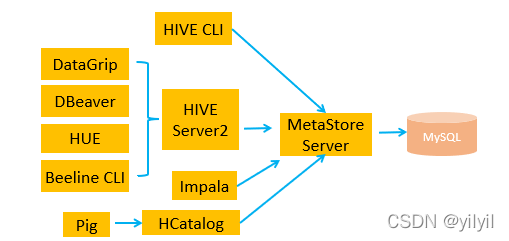
一般使用DataGrip和DBeaver這種可視化來方便開發
轉載請註明出處,本文鏈接:https://www.uj5u.com/qita/423704.html
標籤:其他
上一篇:【zookeeper】raft 共識演算法 影片演示 網站
下一篇:logstash消費延遲瓶頸排查