spark簡介
spark最初誕生于美國加州大學伯克利分校的AMP實驗室,是一個可用于大規模的
Spark是加州大學伯克利分校AMP實驗室(Algorithms, Machines, and People Lab)開發的通用記憶體并行計算框架
Spark使用Scala語言進行實作,它是一種面向物件、函式式編程語言,能夠像操作本地集合物件一樣輕松地操作分布式資料集,具有以下特點,
1.運行速度快:Spark擁有DAG執行引擎,支持在記憶體中對資料進行迭代計算,官方提供的資料表明,如果資料由磁盤讀取,速度是Hadoop MapReduce的10倍以上,如果資料從記憶體中讀取,速度可以高達100多倍,
2.易用性好:Spark不僅支持Scala撰寫應用程式,而且支持Java和Python和R語言進行撰寫,特別是Scala是一種高效、可拓展的語言,能夠用簡潔的代碼處理較為復雜的處理作業,
3.通用性強:Spark生態圈即BDAS包含了Spark Core、Spark SQL、Spark Streaming、MLLib和GraphX等組件,這些組件分別處理Spark Core提供記憶體計算框架、SparkStreaming的實時處理應用、Spark SQL的即席查詢、MLlib或MLbase的機器學習和GraphX的圖處理,
4.隨處運行:Spark具有很強的適應性,能夠讀取HDFS、Cassandra、HBase、S3和Techyon為持久層讀寫原生資料,能夠以Mesos、YARN和自身攜帶的Standalone作為資源管理器調度job,來完成Spark應用程式的計算
5.與Hadoop最大的區別就是spark會把計算資料和中間結果都保存在記憶體里,
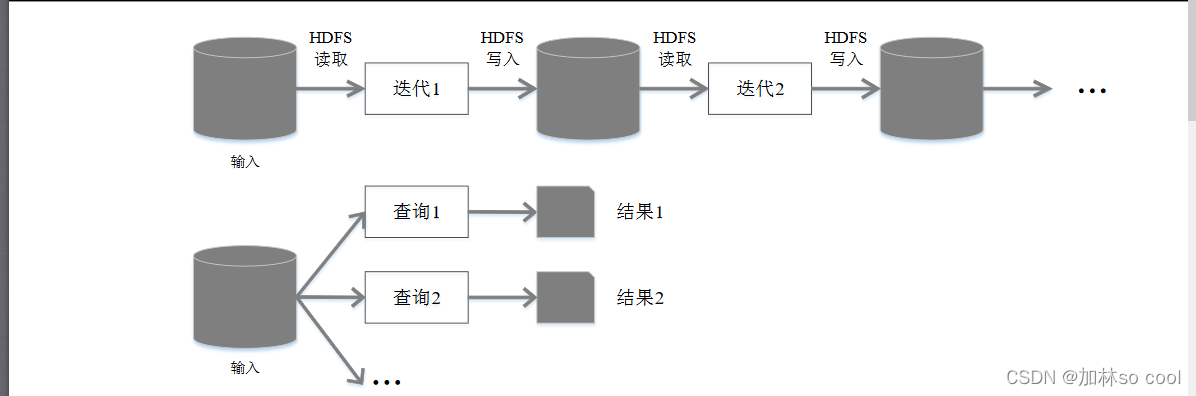
如圖是Hadoop的執行原理
下圖是spark的運行原理
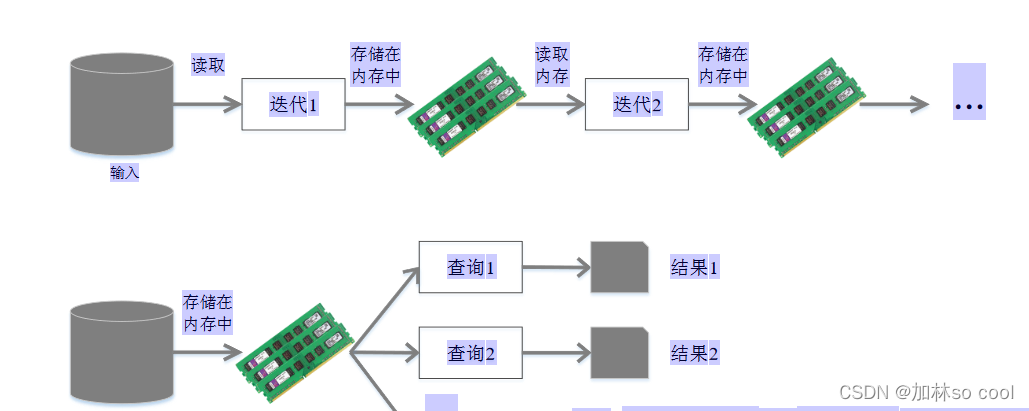
不難看出spark把資料存盤在記憶體里大大減輕了io在傳輸中的時間大大的減少了讀寫的time,
spark生態系統
在實際運用中大資料一般分為下面三種
- 復雜的批量資料處理:時間跨度在十幾分鐘到數小時之間,
- 基于歷史資料的互動式查詢
3.基于實時資料流的資料處理
但是以上三種場景都得需要不同的軟體來進行,spark就可以完美的完成這三點,
他們分別用sparkcore,sparksql,sparkstreaming,structstreing,
- sparkcore,是spark最核心的功能
- sparksql 適用于結果化資料處理的組件允許開發人員查詢hivehbase等等資料源、也可以直接處理rdd
- spark streaming 眾所周知,Hadoop不能進行實時的計算但是spark就可以完成,用sparkstreaming
轉載請註明出處,本文鏈接:https://www.uj5u.com/qita/423729.html
標籤:其他