目錄
- 前言
- 1.無約束最優化
- 2.梯度下降
- 3.梯度下降公式
- 4.學習率
- 5.全域最優化
- 6.梯度下降步驟
- 7.代碼模擬梯度下降
- 7.1 構建函式和導函式
- 7.2 函式可視化
- 7.3 求函式的最小值
- 7.3.1 導函式可解
- 7.3.2 導函式不可解(梯度下降)
前言
本文屬于 線性回歸演算法【AIoT階段三】(尚未更新),這里截取自其中一段內容,方便讀者理解和根據需求快速閱讀,本文通過公式推導+代碼兩個方面同時進行,因為涉及到代碼的編譯運行,如果你沒有 N u m P y NumPy NumPy, P a n d a s Pandas Pandas, M a t p l o t l i b Matplotlib Matplotlib 的基礎,建議先修文章:資料分析三劍客【AIoT階段一(下)】(十萬字博文 保姆級講解),本文是梯度下降的第一部分,后續還會有:梯度下降優化,梯度下降優化進階 (暫未更新)
1.無約束最優化
🚩無約束最優化問題(unconstrained optimizationproblem)指的是從一個問題的所有可能的備選方案中,選擇出依某種指標來說是最優的解決方案,從數學上說,最優化是研究在一個給定的集合S上泛函 J ( θ ) J(\theta) J(θ)的極小化或極大化問題:廣義上,最優化包括數學規劃、圖和網路、組合最優化、庫存論、決策論、排隊論、最優控制等,狹義上,最優化僅指數學規劃,
大白話說就是,比如對于一個二次函式我們要求其極值,無約束的意思就是 x x x 的取值是任意的,在 R R R 上都可取,對于有約束可以形象化理解為我們對 x x x 的范圍進行了限制,比如我們要求 x > 0 x>0 x>0 ,
2.梯度下降
🚩梯度下降法 ( G r a d i e n t (Gradient (Gradient D e s c e n t ) Descent) Descent) 是一個演算法,但不是像多元線性回歸那樣是一個具體做回歸任務的演算法,而是一個非常通用的優化演算法來幫助一些機器學習演算法(都是無約束最優化問題)求解出最優解, 所謂的通用就是很多機器學習演算法都是用梯度下降,甚至深度學習也是用它來求解最優解,所有優化演算法的目的都是期望以最快的速度把模型引數θ求解出來,梯度下降法就是一種經典常用的優化演算法,
之前利用正規方程求解的 θ \theta θ 是最優解的原因是 M S E MSE MSE 這個損失函式是凸函式,但是,機器學習的損失函式并非都是凸函式,設定導數為 0 0 0 會得到很多個極值,不能確定唯一解,
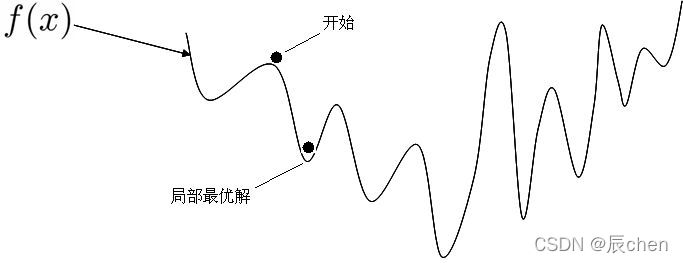
使用正規方程 θ = ( X T X ) ? 1 X T y \theta = (X^TX)^{-1}X^Ty θ=(XTX)?1XTy 求解的另一個限制是特征維度( X 1 、 X 2 … … 、 X n X_1、X_2……、X_n X1?、X2?……、Xn?)不能太多,矩陣逆運算的時間復雜度通常為 O ( n 3 ) O(n^3) O(n3) ,換句話說,就是如果特征數量翻倍,你的計算時間大致為原來的 2 3 2^3 23 倍,也就是之前時間的 8 8 8 倍,舉個例子, 2 2 2 個特征 1 1 1 秒, 4 4 4 個特征就是 8 8 8 秒, 8 8 8 個特征就是 64 64 64 秒, 16 16 16 個特征就是 512 512 512 秒,當特征更多的時候呢?運行時間會非常漫長~
所以正規方程求出最優解并不是機器學習甚至深度學習常用的手段,
之前我們令導數為 0 0 0,反過來求解最低點 θ \theta θ 是多少,而梯度下降法是一點點去逼近最優解!
其實這就跟生活中的情形很像,比如你問一個朋友的工資是多少,他說你猜?那就很難了,他說你猜完我告訴你是猜高了還是猜低了,這樣你就可以奔著對的方向一直猜下去,最后總會猜對!梯度下降法就是這樣的,多次嘗試,并且,在試的程序中還得想辦法知道是不是在猜對的路上,說白了就是得到正確的反饋再調整然后繼續猜才有意義~
這個就好比道士下山,我們把 L o s s Loss Loss (或者稱為 C o s t Cost Cost,即損失)曲線看成是山谷,如果走過了,就再往回返,所以是一個迭代的程序,
3.梯度下降公式
🚩這里梯度下降法的公式就是一個式子指導計算機迭代程序中如何去調整 θ \theta θ,可以通過泰勒公式一階展開來進行推導和證明:
- θ n + 1 = θ n ? α ? g r a d i e n t \theta^{n + 1} = \theta^{n} - \alpha * gradient θn+1=θn?α?gradient
其中 α \alpha α 表示步幅,也稱為學習率, g r a d i e n t gradient gradient 表示梯度,即導數, θ \theta θ 是方程系數
-
θ n + 1 = θ n ? α ? ? J ( θ ) ? θ \theta^{n + 1} = \theta^{n} - \alpha * \frac{\partial J(\theta)}{\partial \theta} θn+1=θn?α??θ?J(θ)?
有些公式,使用其他字母表示:
-
θ n + 1 = θ n ? η ? ? J ( θ ) ? θ \theta^{n + 1} = \theta^{n} - \eta * \frac{\partial J(\theta)}{\partial \theta} θn+1=θn?η??θ?J(θ)?
-
w j n + 1 = w j n ? η ? ? J ( θ ) ? θ j w_j^{n + 1} = w_j^{n} - \eta * \frac{\partial J(\theta)}{\partial \theta_j} wjn+1?=wjn??η??θj??J(θ)?
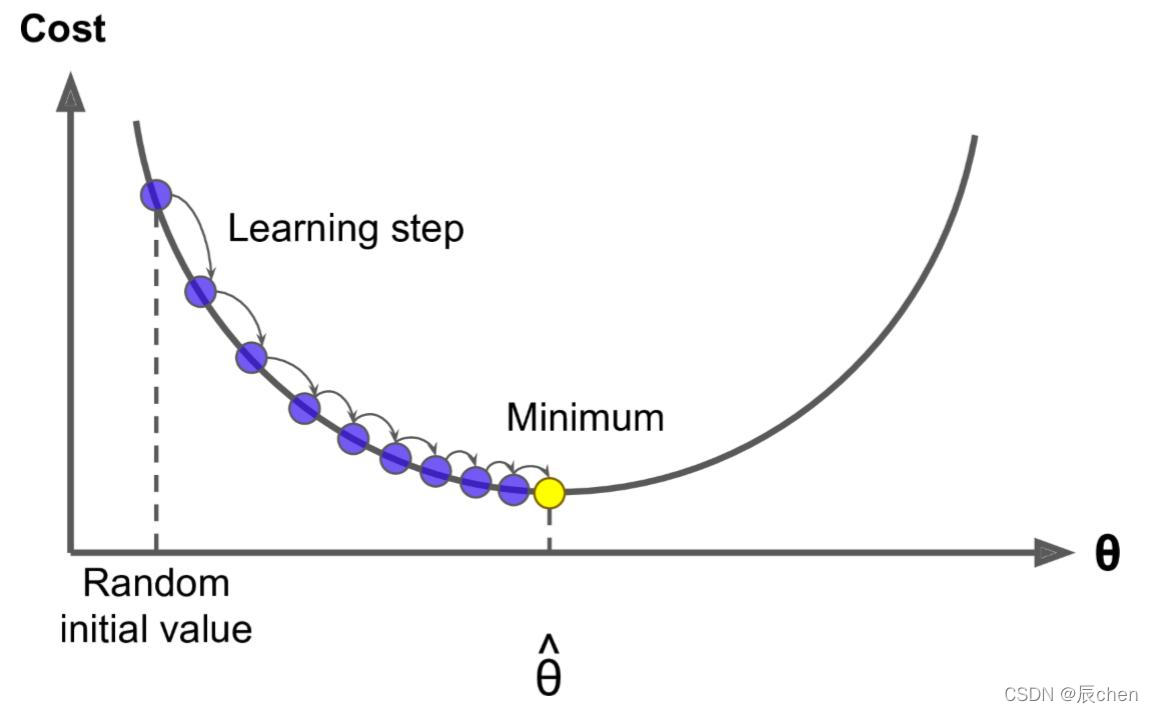
這里的 w j w_j wj? 就是 θ \theta θ 中的某一個 j = 0 , . . . , m j = 0,...,m j=0,...,m,這里的 η \eta η 就是梯度下降圖里的 l e a r n i n g learning learning s t e p step step,很多時候也叫學習率 l e a r n i n g learning learning r a t e rate rate,很多時候也用 α \alpha α 表示,這個學習率我們可以看作是下山邁的步子的大小,步子邁的大下山就快,
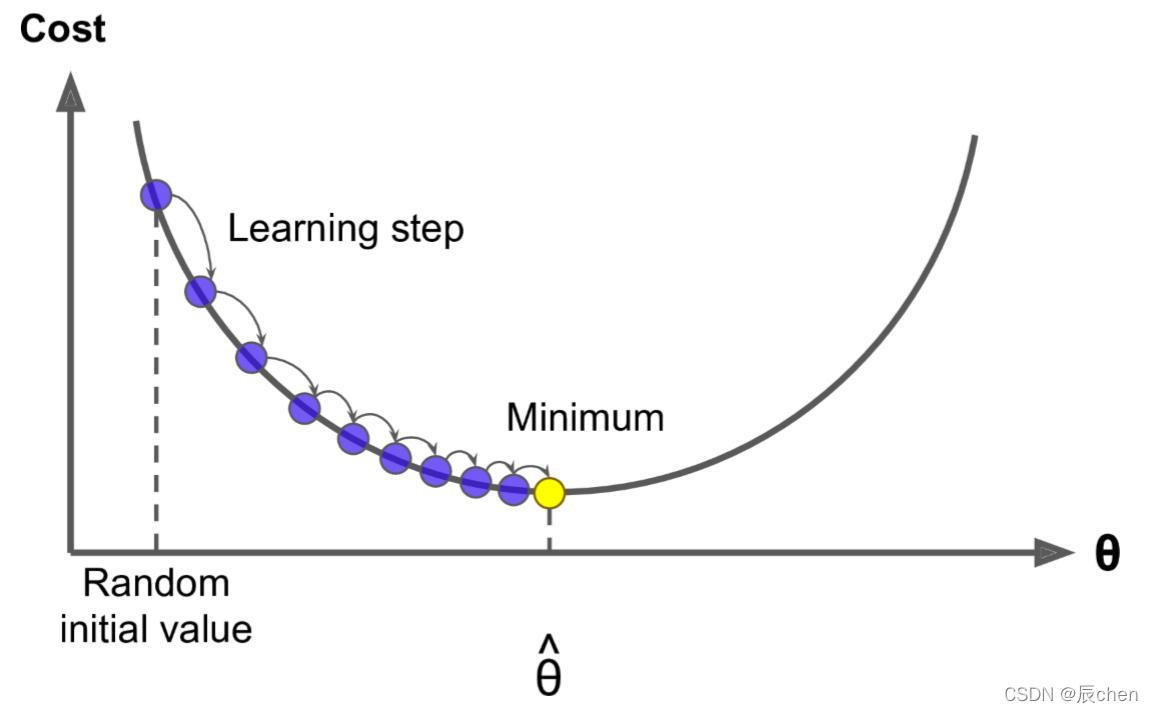
學習率一般都是正數,如果在山左側(曲線左半邊)梯度是負的,那么這個負號就會把
w
j
w_j
wj? 往大了調, 如果在山右側(曲線右半邊)梯度就是正的,那么負號就會把
w
j
w_j
wj? 往小了調,每次
w
j
w_j
wj? 調整的幅度就是
η
?
g
r
a
d
i
e
n
t
\eta * gradient
η?gradient,就是橫軸上移動的距離,
因此,無論在左邊,還是在右邊,梯度下降都可以快速找到最優解,實作快速下山~
如果特征或維度越多,那么這個公式用的次數就越多,也就是每次迭代要應用的這個式子多次(多少特征,就應用多少次),所以其實上面的圖不是特別準,因為 θ \theta θ 對應的是很多維度,應該每一個維度都可以畫一個這樣的圖,或者是一個多維空間的圖,
??如果特征或維度越多,那么這個公式用的次數就越多,也就是每次迭代要應用的這個式子多次(多少特征,就應用多少次),所以其實上面的圖不是特別準,因為 θ \theta θ 對應的是很多維度,應該每一個維度都可以畫一個這樣的圖,或者是一個多維空間的圖,
- w 0 n + 1 = w 0 n ? η ? ? J ( θ ) ? θ 0 w_0^{n + 1} = w_0^{n} - \eta * \frac{\partial J(\theta)}{\partial \theta_0} w0n+1?=w0n??η??θ0??J(θ)?
- w 1 n + 1 = w 1 n ? η ? ? J ( θ ) ? θ 1 w_1^{n + 1} = w_1^{n} - \eta * \frac{\partial J(\theta)}{\partial \theta_1} w1n+1?=w1n??η??θ1??J(θ)?
- ……
- w m n + 1 = w m n ? η ? ? J ( θ ) ? θ m w_m^{n + 1} = w_m^{n} - \eta * \frac{\partial J(\theta)}{\partial \theta_m} wmn+1?=wmn??η??θm??J(θ)?
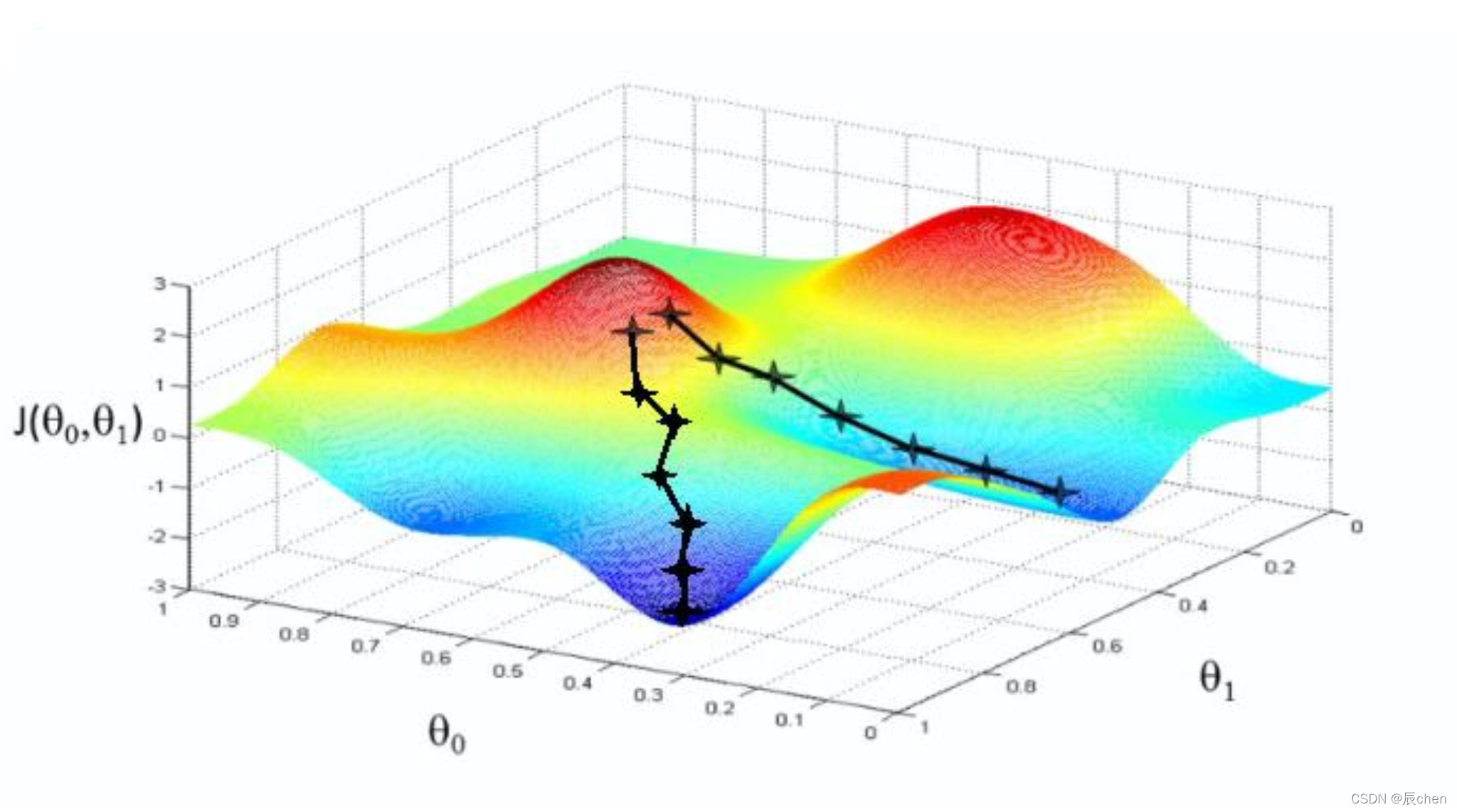
所以觀察上圖我們可以發現不是某一個 θ 0 \theta_0 θ0? 或 θ 1 \theta_1 θ1? 找到最小值就是最優解,而是它們一起找到 J ( θ ) J(\theta) J(θ) 最小值才是最優解,
4.學習率
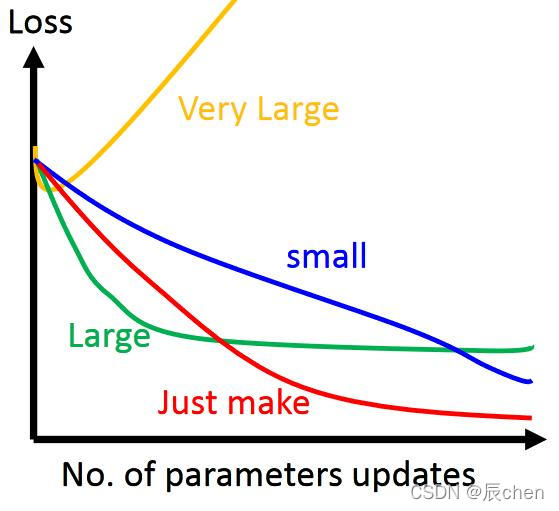
🚩根據我們上面講的梯度下降公式,我們知道 η \eta η 是學習率,設定大的學習率 w j w_j wj? 每次調整的幅度就大,設定小的學習率 w j w_j wj? 每次調整的幅度就小,然而如果步子邁的太大也會有問題,俗話說步子大了容易扯著蛋!學習率大,可能一下子邁過了,到另一邊去了(從曲線左半邊跳到右半邊),繼續梯度下降又露訓來, 使得來來回回震蕩,步子太小呢,就像蝸牛一步步往前挪,也會使得整體迭代次數增加,
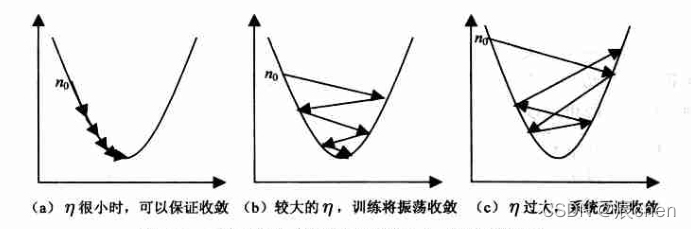
學習率的設定是門一門學問,一般我們會把它設定成一個比較小的正整數, 0.1 0.1 0.1、 0.01 0.01 0.01、 0.001 0.001 0.001、 0.0001 0.0001 0.0001,都是常見的設定數值(然后根據情況調整),一般情況下學習率在整體迭代程序中是不變,但是也可以設定成隨著迭代次數增多學習率逐漸變小,因為越靠近山谷我們就可以步子邁小點,可以更精準的走入最低點,同時防止走過,還有一些深度學習的優化演算法會自己控制調整學習率這個值,后面學習程序中這些策略在講解代碼中我們會一一講到,
5.全域最優化
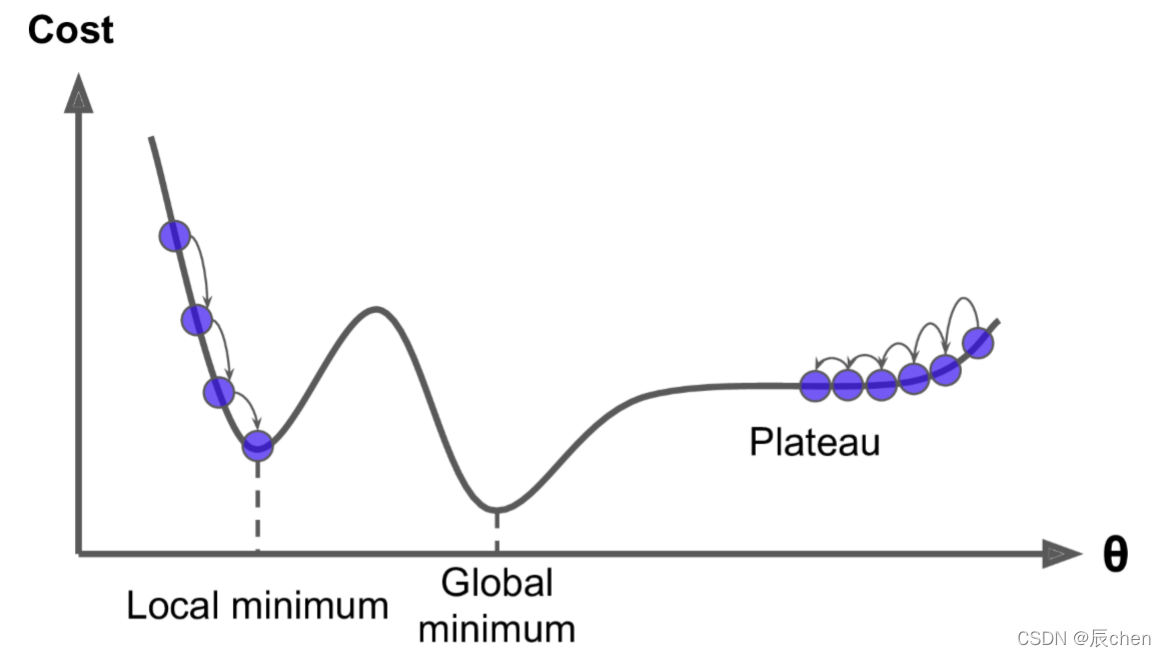
🚩上圖顯示了梯度下降的兩個主要挑戰:
- 若隨機初始化,演算法從左側起步,那么會收斂到一個區域最小值,而不是全域最小值;
- 若隨機初始化,演算法從右側起步,那么需要經過很長時間才能越過 P l a t e a u Plateau Plateau(函式停滯帶,梯度很小),如果停下得太早,則永遠達不到全域最小值;
而線性回歸的模型 M S E MSE MSE 損失函式恰好是個凸函式,凸函式保證了只有一個全域最小值,其次是個連續函式,斜率不會發生陡峭的變化,因此即便是亂走,梯度下降都可以趨近全域最小值,
上圖損失函式是非凸函式,梯度下降法是有可能落到區域最小值的,所以其實步長不能設定的太小太穩健,那樣就很容易落入區域最優解,雖說區域最小值也沒大問題, 因為模型只要是堪用的就好嘛,但是我們肯定還是盡量要奔著全域最優解去
6.梯度下降步驟
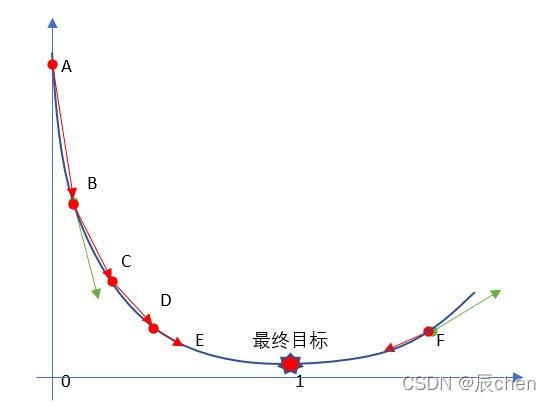
🚩梯度下降流程就是“猜”正確答案的程序:
-
1、“瞎蒙”, R a n d o m Random Random 亂數生成 θ \theta θ,隨機生成一組數值 w 0 、 w 1 … … w n w_0、w_1……w_n w0?、w1?……wn? ,期望 μ \mu μ 為 0 方差 σ \sigma σ 為 1 的正太分布資料,
-
2、求梯度 g g g ,梯度代表曲線某點上的切線的斜率,沿著切線往下就相當于沿著坡度最陡峭的方向下降
-
3、 i f if if g < 0 g < 0 g<0, θ \theta θ 變大, i f if if g > 0 g > 0 g>0, θ \theta θ 變小
-
4、判斷是否收斂 c o n v e r g e n c e convergence convergence,如果收斂跳出迭代,如果沒有達到收斂,回第 2 2 2 步再次執行 2 2 2 ~ 4 4 4 步
收斂的判斷標準是:隨著迭代進行損失函式 L o s s Loss Loss,變化非常微小甚至不再改變,即認為達到收斂
7.代碼模擬梯度下降
-
梯度下降優化演算法,比正規方程,應用更加廣泛
-
什么是梯度?
- 梯度就是導數對應的值!
-
下降?
- 涉及到優化問題,最小二乘法
-
梯度下降呢?
- 梯度方向下降,速度最快的~
接下來,我們使用代碼來描述上面梯度下降的程序:
方程如下:
f ( x ) = ( x ? 3.5 ) 2 ? 4.5 x + 10 f(x) = (x - 3.5)^2 - 4.5x + 10 f(x)=(x?3.5)2?4.5x+10
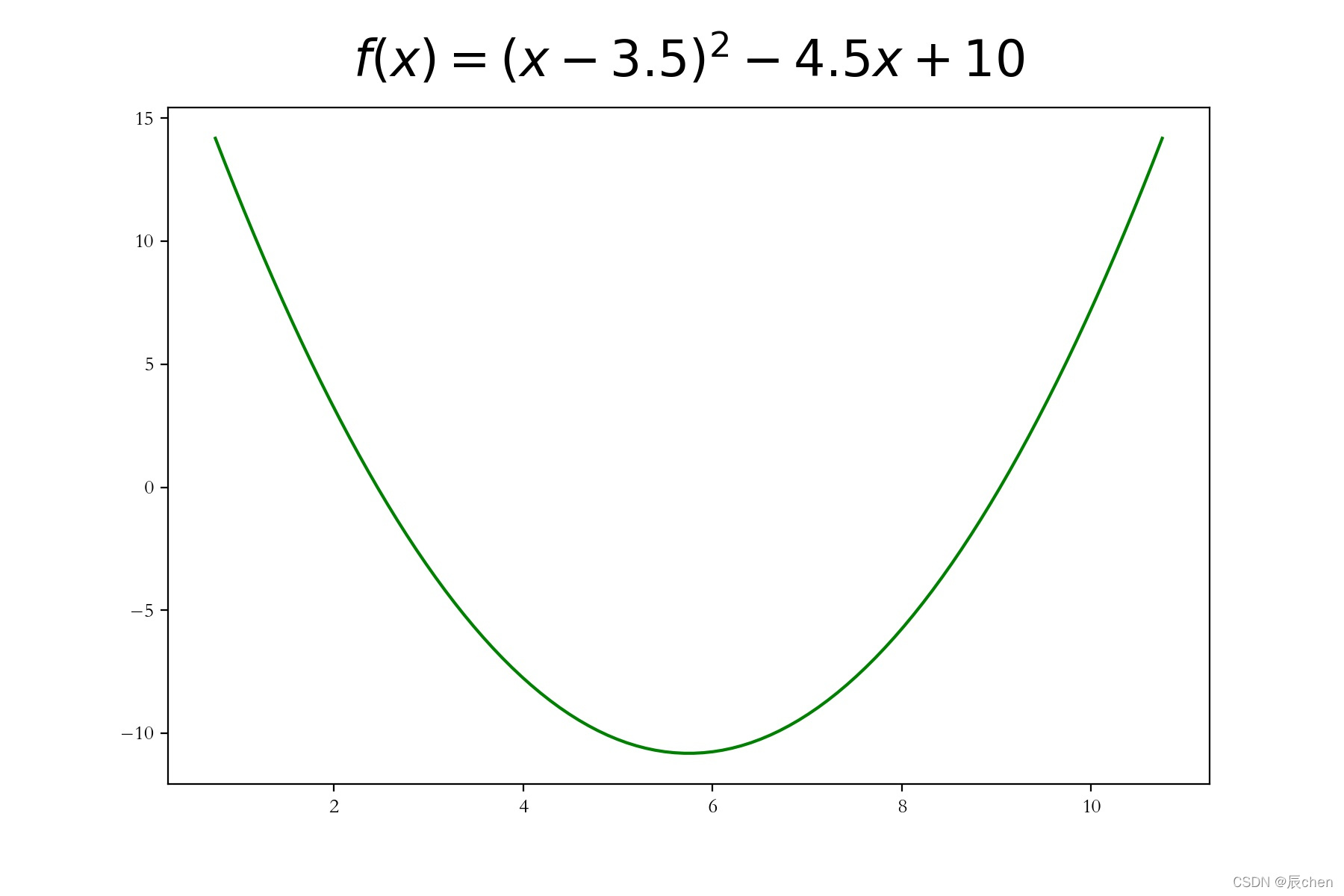
7.1 構建函式和導函式
import numpy as np
import matplotlib.pyplot as plt
# 構建方程
f = lambda x : (x - 3.5) ** 2 - 4.5 * x + 10
# 方程的導函式
g = lambda x : 2 * (x - 3.5) - 4.5
7.2 函式可視化
# 繪制函式影像
x = np.linspace(0, 11.5, 100)
y = f(x)
_ = plt.plot(x, y)
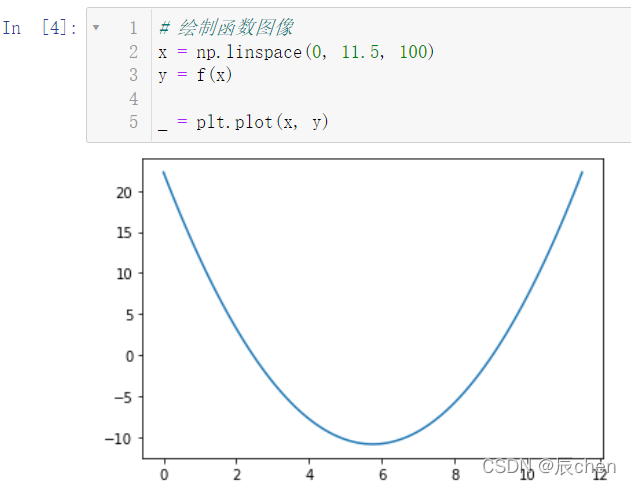
7.3 求函式的最小值
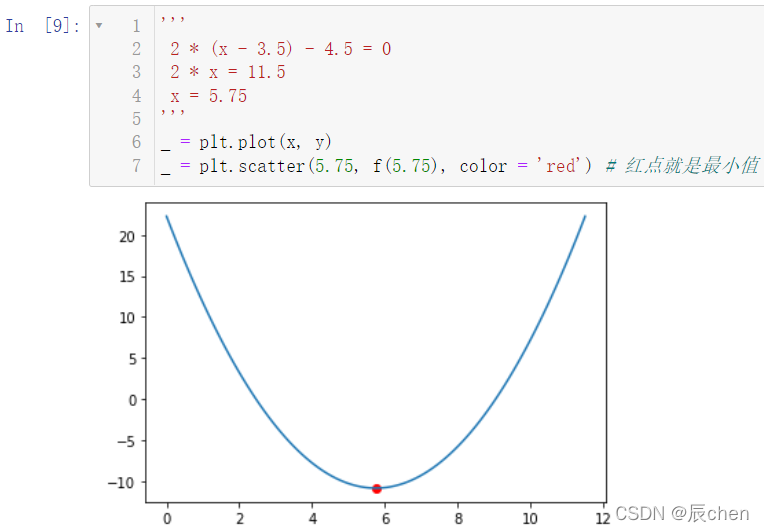
7.3.1 導函式可解
'''
2 * (x - 3.5) - 4.5 = 0
2 * x = 11.5
x = 5.75
'''
_ = plt.plot(x, y)
_ = plt.scatter(5.75, f(5.75), color = 'red') # 紅點就是最小值
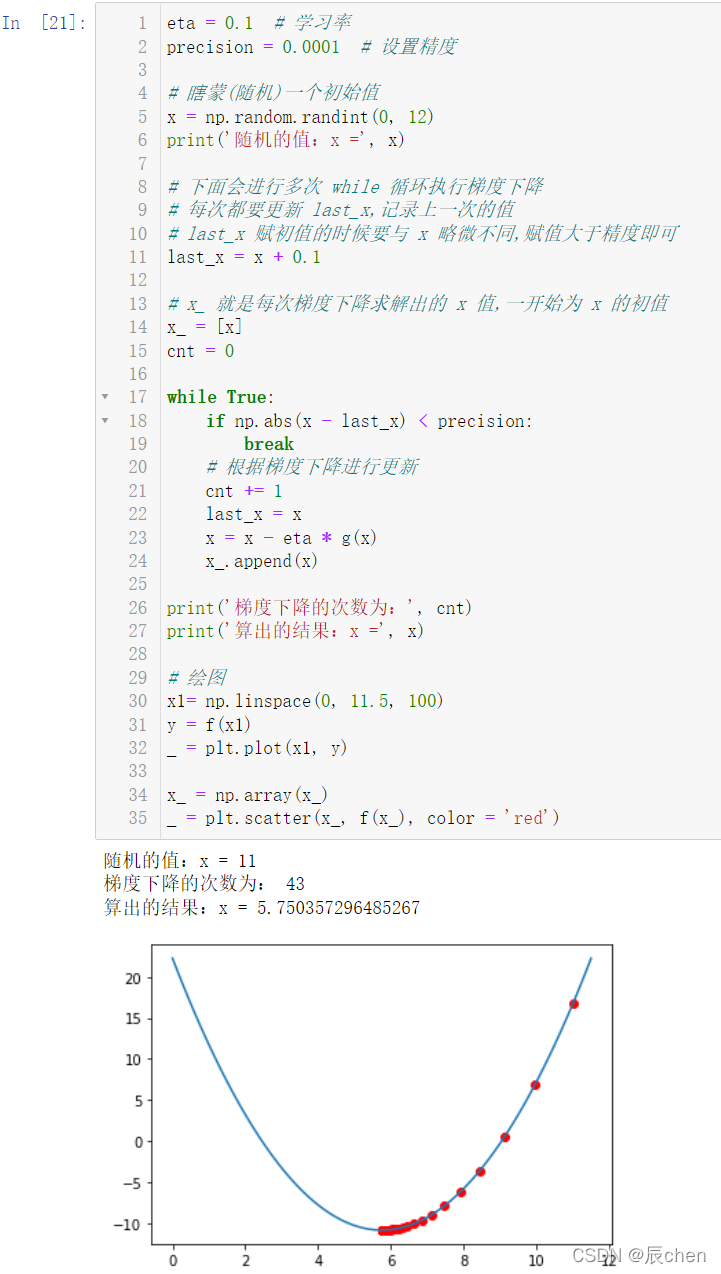
7.3.2 導函式不可解(梯度下降)
eta = 0.1 # 學習率
precision = 0.0001 # 設定精度
# 瞎蒙(隨機)一個初始值
x = np.random.randint(0, 12)
print('隨機的值:x =', x)
# 下面會進行多次 while 回圈執行梯度下降
# 每次都要更新 last_x,記錄上一次的值
# last_x 賦初值的時候要與 x 略微不同,賦值大于精度即可
last_x = x + 0.1
# x_ 就是每次梯度下降求解出的 x 值,一開始為 x 的初值
x_ = [x]
cnt = 0
while True:
if np.abs(x - last_x) < precision:
break
# 根據梯度下降進行更新
cnt += 1
last_x = x
x = x - eta * g(x)
x_.append(x)
print('梯度下降的次數為:', cnt)
print('算出的結果:x =', x)
# 繪圖
x1= np.linspace(0, 11.5, 100)
y = f(x1)
_ = plt.plot(x1, y)
x_ = np.array(x_)
_ = plt.scatter(x_, f(x_), color = 'red')
轉載請註明出處,本文鏈接:https://www.uj5u.com/qita/423741.html
標籤:AI
上一篇:小公司比較吃虧的兩道微服務面試題
下一篇:立體視覺入門指南(7):立體匹配