最近打算梳理訊息引擎系統,以Kafka和RocketMQ為主進行學習,關于Kafka打算寫兩篇文章,一篇是基礎知識,一篇是實踐,打算用Kafka收集日志,并實作報警功能,Kafka版本經常更新,有的知識可能和最新版本不一致,這點需注意,
基礎知識
Kafka是什么
Apache Kafka 是訊息引擎系統,也是一個分布式流處理平臺(Distributed Streaming Platform),本次主要討論其作為訊息引擎方面的內容,
訊息引擎系統是一組規范,企業利用這組規范在不同系統之間傳遞語意準確的訊息,實作松耦合的異步式資料傳遞,即系統 A 發送訊息給訊息引擎系統,系統 B 從訊息引擎系統中讀取 A 發送的訊息,
Kafka結構
我們通過一個實體,來認識Kafka的結構和核心術語,
角色
首先需要了解Kafka內部有哪些角色,它們的關系如何:
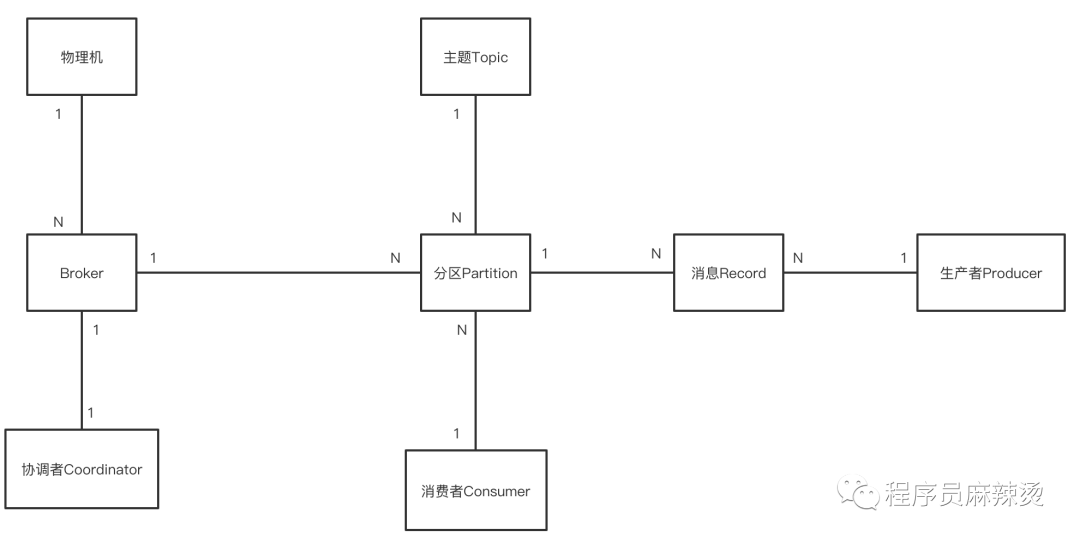
Broker:Kafka 的服務器端由被稱為 Broker 的服務行程構成,即一個 Kafka 集群由多個 Broker 組成,Broker 負責接收和處理客戶端發送過來的請求,以及對訊息進行持久化,一臺服務器可以啟動多個Broker,
協調者:Coordinator,它專門為 Consumer Group 服務,負責為 Group 執行Rebalance 以及提供位移管理和組成員管理等,所有 Broker 在啟動時,都會創建和開啟相應的 Coordinator 組件,也就是說,所有Broker 都有各自的 Coordinator 組件,
主題:Topic,主題是承載訊息的邏輯容器,在實際使用中用來區分具體業務,如訂單訊息主題、物流訊息主題,
磁區:Partition,一個有序不變的訊息序列,用于存放訊息,每個主題下可以有多個磁區,磁區可存在不同的Broker上,
訊息:Record,Kafka 是訊息引擎,這里的訊息就是指 Kafka 處理的主要物件,
生產者:Producer,向主題發布新訊息的應用程式,
消費者:Consumer,從主題訂閱新訊息的應用程式,
消費者組:Consumer Group,多個消費者實體共同組成的一個組,同時消費多個磁區以實作高吞吐,消費訊息時,一般都是用消費者組的形式,
實體
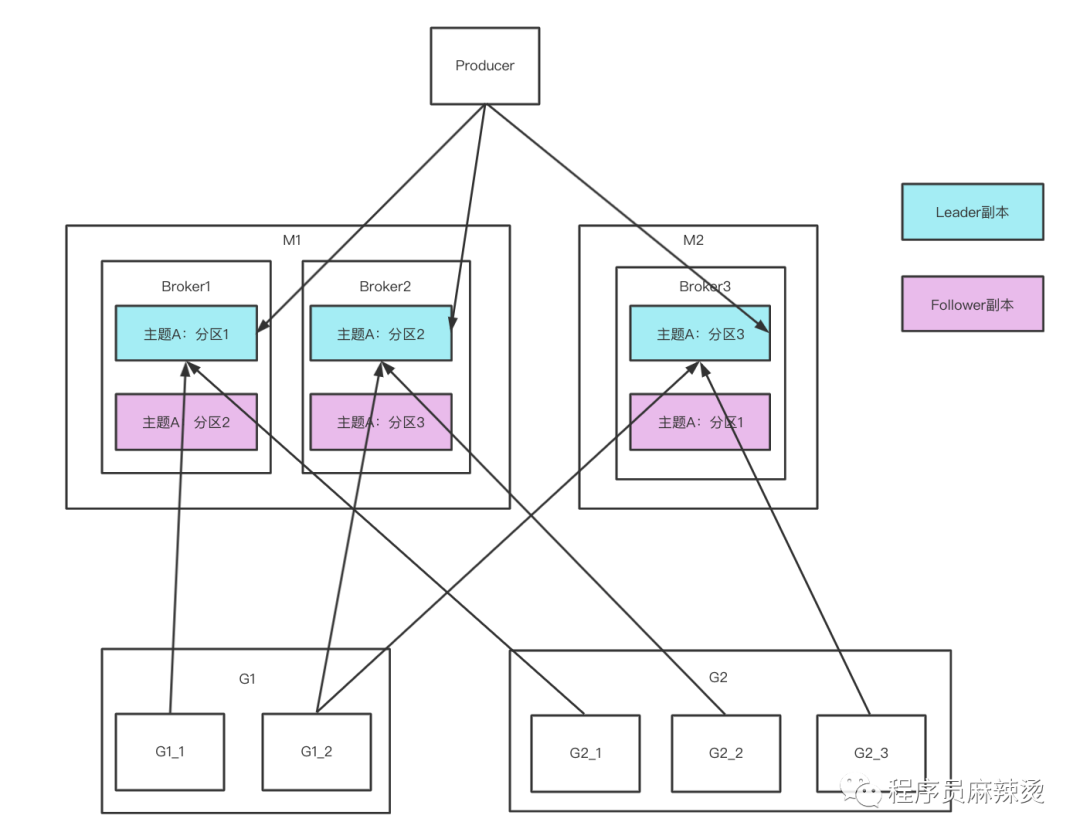
假設現有兩臺機器M1和M2,在M1機器上創建兩個Broker,在M2機器上創建一個Broker,創建主題A,設定該主題的磁區數為3、副本數為2,有一個生產者負責生產訊息,有兩個消費者組G1、G2負責消費訊息,G1包含2個消費者,G2包含3個消費者,概念圖如下:
-
創建主題時可以設定磁區數量,由Kafka配置磁區會分配到哪個Broker上,
-
創建主題時可以設定副本數量,
副本:Replica,Kafka 中同一條訊息能夠被拷貝到多個地方以提供資料冗余,這些地方就是所謂的副本,副本還分為領導者副本和追隨者副本,各自有不同的角色劃分,副本是在磁區層級下的,即每個磁區可配置多個副本實作高可用,
-
磁區可以有多個副本,只能有一個Leader副本,Leader副本負責和生產者、消費者互動,追隨者副本只負責冗余資料,
-
一個磁區只能被同一個消費者組里的一個消費者消費,但可以被多個消費者組消費,如G1_1、G2_1都能消費磁區1,
-
主題下所有磁區都需分配給消費者組里的一個消費者,如果消費者數量比磁區數量少,則一個消費者需要消費多個磁區,如G1_2需要消費磁區2和磁區3,如果消費者數量比磁區數量多,則有的消費者不會被分配磁區,無事可做,
執行流程
通過基礎知識,我們對Kafka有了基本的了解,現在我們按照訊息生產、存盤、消費流程,串聯Kafka的整個程序,
創建Broker
命令
要運行Kafka,首先需要創建Broker,使用命令為:bin/kafka-server-start.sh config/server.properties &,
控制器
產生
Broker 在啟動時,會嘗試去 ZooKeeper 中創建 /controller 節點,Kafka 當前選舉控制器的規則是:第一個成功創建 /controller 節點的 Broker 會被指定為控制器,
控制器組件(Controller),是 Apache Kafka 的核心組件,它的主要作用是在 Apache ZooKeeper 的幫助下管理和協調整個 Kafka 集群,集群中任意一臺 Broker 都能充當控制器的角色,但是,在運行程序中,只能有一個 Broker 成為控制器,行使其管理和協調的職責,換句話說,每個正常運轉的 Kafka 集群,在任意時刻都有且只有一個控制器,
作用
控制器可用于主題管理(創建、洗掉、增加磁區)、磁區重分配、 Preferred 領導者選舉、集群成員管理(新增 Broker、Broker 主動關閉、Broker 宕機)、資料服務(向其他 Broker 推送集群元資料資訊),
選舉
如果控制器故障,ZooKeeper 通過 Watch 機制感知到并洗掉了 /controller 臨時節點,所有存活的 Broker 開始競選新的控制器身份,成功地在 ZooKeeper 上重建了 /controller 節點最終贏得了選舉,成為最新的控制器,
生產者
生產者主要用于生成訊息,
連接Broker
-
在創建 KafkaProducer 實體時,生產者應用會在后臺創建并啟動一個名為 Sender 的執行緒,該 Sender 執行緒開始運行時首先會根據bootstrap.servers配置中記錄的Broker IP地址,創建與這些Broker 的連接,
-
Producer 向bootstrap.servers中的某一臺 Broker 發送了 METADATA 請求,嘗試獲取集群的元資料資訊,
-
當 Producer 獲取了集群的元資料資訊之后,如果發現與某些 Broker 當前沒有連接,那么它就會創建一個 TCP 連接,
至此,建立了Producer和Broker之間的連接,
交付可靠性
交付可靠性是指訊息丟失、重復發送情況,有以下三種型別:
最多一次(at most once):訊息可能會丟失,但絕不會被重復發送,
至少一次(at least once):訊息不會丟失,但有可能被重復發送,
精確一次(exactly once):訊息不會丟失,也不會被重復發送,
Kafka 默認提供的交付可靠性保障是第二種,即至少一次,
這三種型別,生產者的實作方案為:
-
至少一次:只有 Broker 成功“提交”訊息且 Producer 接到Broker 的應答才會認為該訊息成功發送,否則就不斷重試,這導致訊息可能重復,
-
最多一次:Producer禁止重試,這樣訊息要么寫入成功,要么寫入失敗,但絕不會重復發送,有可能導致訊息可能丟失,
-
精確一次:
-
創建冪等性 Producer,Kafka 自動做訊息的重復去重,
-
只能保證單磁區上的冪等性
-
只能實作單會話上的冪等性,Producer 行程重啟后,冪等性保證就喪失
-
創建事務型 Producer,要么全部寫入成功,要么全部失敗,
-
支持多磁區、多會話
-
比起冪等性 Producer,事務型 Producer 的性能更差
發送訊息
一個主題有多個磁區,磁區策略是決定生產者的訊息發送到哪個磁區的演算法,磁區策略主要有三種:
-
輪詢策略:也稱 Round-robin 策略,即順序分配,輪詢策略有非常優秀的負載均衡表現,它總是能保證訊息最大限度地被平均分配到所有磁區上,
-
隨機策略:也稱 Randomness 策略,所謂隨機就是隨意地將訊息放置到任意一個磁區上,
-
按訊息鍵保序策略:也稱 Key-ordering 策略,Kafka 允許為每條訊息定義訊息鍵,簡稱為 Key,一旦訊息被定義了 Key,那么就可以保證同一個Key 的所有訊息都進入到相同的磁區里面,
Kafka 默認磁區策略實際上同時實作了兩種策略:如果指定了 Key,那么默認實作按訊息鍵保序策略;如果沒有指定 Key,則使用輪詢策略,
資料存盤
存盤
Kafka 的訊息組織方式實際上是三級結構:主題 - 磁區 - 訊息,
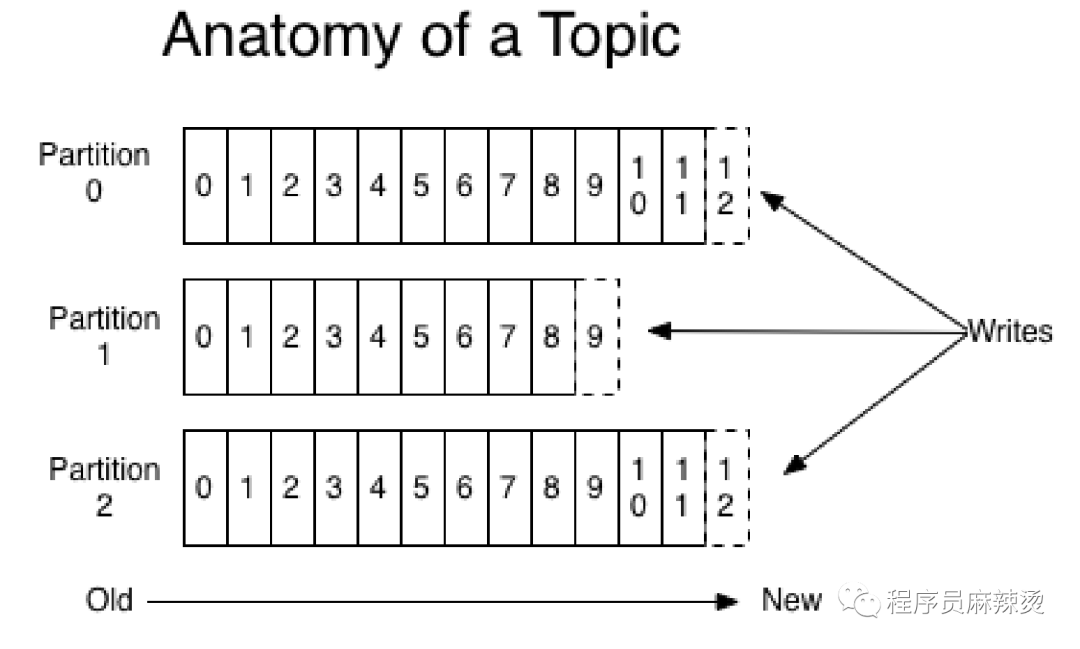
Kafka 使用訊息日志(Log)來保存資料,一個日志就是磁盤上一個只能追加寫(Append-only)訊息的物理文
件,因為只能追加寫入,故避免了緩慢的隨機 I/O 操作,改為性能較好的順序I/O 寫操作,這也是實作 Kafka 高吞吐量特性的一個重要手段,磁區存放訊息日志,磁區中包含若干條訊息,每條訊息的位移從 0 開始,依次遞增,
圖中的數字叫做訊息位移(Offset),表示磁區中每條訊息的位置資訊,是一個單調遞增且不變的值,
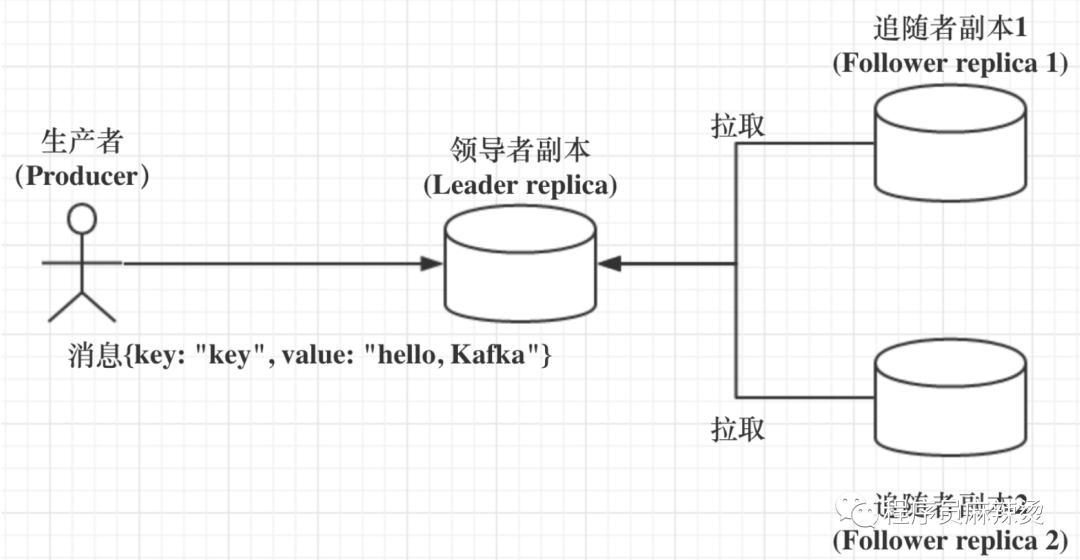
副本
在 Kafka 中,副本分成兩類:領導者副本(Leader Replica)和追隨者副本(Follower Replica),每個磁區在建時都要選舉一個副本,稱為領導者副本,其余的副本自動稱為追隨者副本,訊息寫入Leader副本后,Follower副本怎么獲取到新的訊息呢?
同步
追隨者副本不處理客戶端請求,它唯一的任務就是從領導者副本異步拉取訊息,并寫入到自己的提交日志中,從而實作與領導者副本的同步,
可見性
磁區里的訊息分為已提交訊息和未提交訊息,兩者以高水位(HW)進行分割,消費者只能消費已提交訊息,
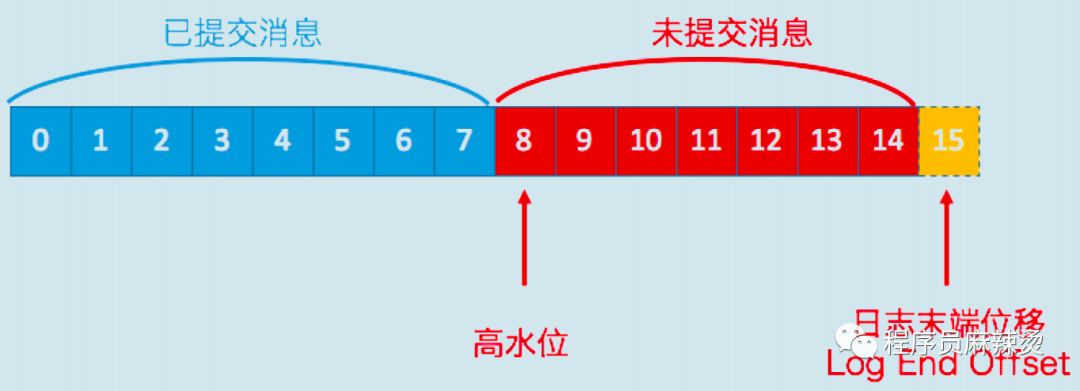
水位的定義:在時刻 T,任意創建時間(Event Time)為 T’,且 T’≤T 的所有事件都已經到達或被觀測到,那么 T 就被定義為水位,
高水位更新
那高水位是怎樣進行更新的呢?每個副本物件都保存了一組高水位值和 LEO 值,但實際上,在 Leader副本所在的 Broker 上,還保存了其他 Follower 副本的 LEO 值,
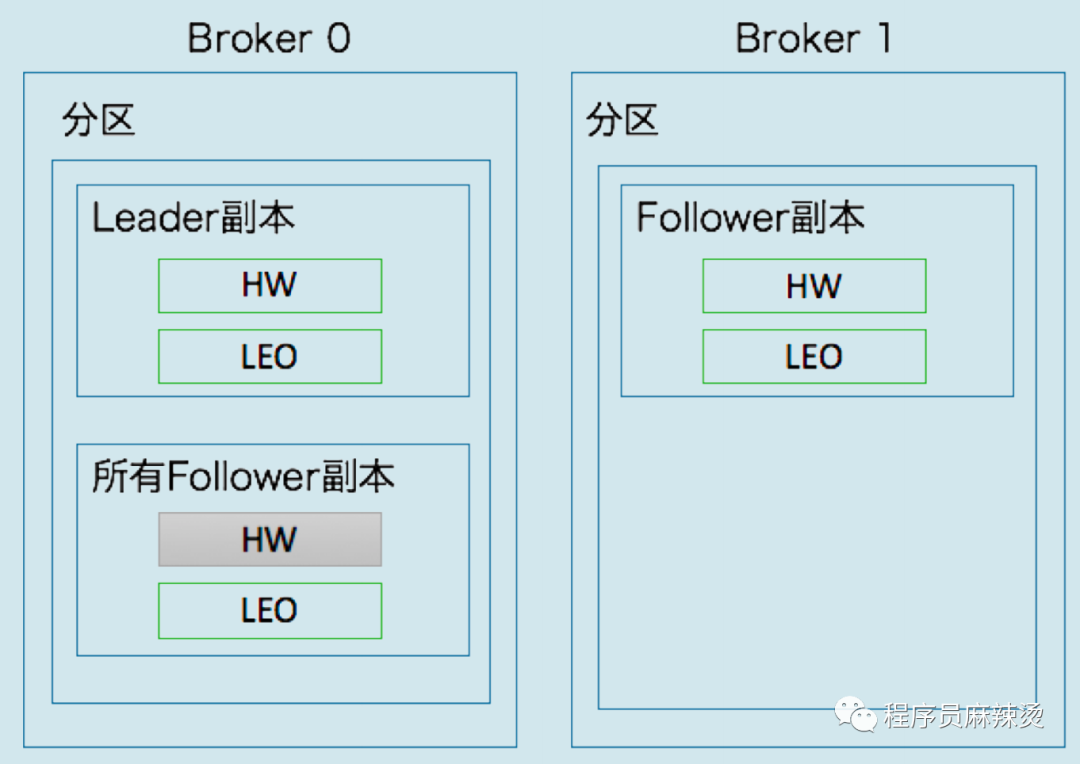
Leader 副本
處理生產者請求的邏輯如下:
-
寫入訊息到本地磁盤,
-
更新磁區高水位值,
i. 獲取 Leader 副本所在 Broker 端保存的所有遠程副本 LEO 值{LEO-1,LEO-2,……,LEO-n},
ii. 獲取 Leader 副本高水位值:currentHW,
iii. 更新 currentHW = min(currentHW, LEO-1,LEO-2,……,LEO-n),
處理 Follower 副本拉取訊息的邏輯如下:
-
讀取磁盤(或頁快取)中的訊息資料,
-
使用 Follower 副本發送請求中的位移值更新遠程副本 LEO 值,
-
更新磁區高水位值(具體步驟與處理生產者請求的步驟相同),
Follower 副本
從 Leader 拉取訊息的處理邏輯如下:
-
寫入訊息到本地磁盤,
-
更新 LEO 值,
-
更新高水位值,
i. 獲取 Leader 發送的高水位值:currentHW,
ii. 獲取步驟 2 中更新過的 LEO 值:currentLEO,
iii. 更新高水位為 min(currentHW, currentLEO),
簡單來說,是所有副本都拉取到的訊息,才能被消費者看到,
Leader Epoch
高水位在界定Kafka 訊息對外可見性以及實作副本機制等方面起到了非常重要的作用,但其設計上的缺陷給 Kafka 留下了很多資料丟失或資料不一致的潛在風險,為此,社區引入了 Leader Epoch機制,嘗試規避掉這類風險,
所謂 Leader Epoch,我們大致可以認為是 Leader 版本,它由兩部分資料組成,
-
Epoch,一個單調增加的版本號,每當副本領導權發生變更時,都會增加該版本號,小版本號的 Leader 被認為是過期 Leader,不能再行使 Leader 權力,
-
起始位移(Start Offset),Leader 副本在該 Epoch 值上寫入的首條訊息的位移,
Kafka Broker 會在記憶體中為每個磁區都快取 Leader Epoch 資料,同時它還會定期地將這些資訊持久化到一個 checkpoint 檔案中,當 Leader 副本寫入訊息到磁盤時,Broker 會嘗試更新這部分快取,如果該 Leader 是首次寫入訊息,那么 Broker 會向快取中增加一個Leader Epoch 條目,否則就不做更新,這樣,每次有 Leader 變更時,新的 Leader 副本會查詢這部分快取,取出對應的 Leader Epoch 的起始位移,以避免資料丟失和不一致的情況,
選舉
當領導者副本掛掉了,或者說領導者副本所在的 Broker 宕機時,Kafka 依托于ZooKeeper 提供的監控功能能夠實時感知到,并立即開啟新一輪的領導者選舉,從追隨者副本中選一個作為新的領導者,老 Leader 副本重啟回來后,只能作為追隨者副本加入到集群中,
一個磁區有多個Follower磁區,如何選舉呢?Kafka 引入了 In-sync Replicas,也就是所謂的 ISR 副本集合,
ISR 中的副本都是與 Leader 同步的副本,相反,不在 ISR 中的追隨者副本就被認為是與 Leader 不同步的,Broker 端引數 replica.lag.time.max.ms 的含義是Follower 副本能夠落后 Leader 副本的最長時間間隔,當前默認值是 10 秒,如果時間間隔在replica.lag.time.max.ms之內,則放入ISR,否則踢出ISR,
如果Broker 端引數 unclean.leader.election.enable 為false,非ISR中的磁區可以參加領導者選舉,否則只能在ISR中的磁區參加選舉,
此處大家會有疑問,即使是ISR中的磁區,也可能沒有完全同步完Leader副本的訊息,是否會導致訊息丟失?這里有一個核心點:Kafka只對已提交訊息做持久化保證,如果我們設定了最高等級的持久化需求,比如acks=all,那么follower副本沒有同步完成前這條訊息就不算已提交,就不算丟失了,
所以可以設定 min.insync.replicas > 1,這是 Broker 端引數,控制的是訊息至少要被寫入到多少個副本才算是“已提交”,設定成大于 1 可以提升訊息持久性,這樣能夠保證至少有多個副本是有完整的訊息,
消費者
位移主題
Kafka 中有一個內部主題(InternalTopic)__consumer_offsets,__consumer_offsets 在 Kafka 中叫位移主題,即 Offsets Topic,當Kafka 集群中的第一個 Consumer 程式啟動時,Kafka 會自動創建位移主題,也會自動設定該主題的磁區數和備份數,
consumer_offsets 的主要作用是保存 Kafka 消費者的位移資訊,本質上Consumer 的位移資料作為一條條普通的 Kafka 訊息,提交到 consumer_offsets 中,
consumer_offsets中主要存放三類訊息:
-
位移訊息,格式為K-V結構,其中Key:<Group ID A,主題名B,磁區號C >,Value是位移值,表示消費者組A,消費主題B的磁區C,已經消費到什么位置了,
-
用于保存 Consumer Group 資訊的訊息,
-
用于洗掉 Group 過期位移甚至是洗掉 Group 的訊息,
連接Broker
消費者創建和Broker的TCP 連接,是在呼叫 KafkaConsumer.poll 方法時被創建的,步驟為:
-
發起 FindCoordinator 請求
當消費者程式首次啟動呼叫 poll 方法時,它需要向 Kafka 集群發送一個名為 FindCoordinator 的請求,希望 Kafka 集群告訴它哪個 Broker 是管理它的協調者,消費者程式會向集群中當前負載最小的那臺 Broker 發送請求,計算協調者所在Broker的演算法為:
-
第 1 步:確定由位移主題的哪個磁區來保存該 Group 資料:
partitionId=Math.abs(groupId.hashCode() % offsetsTopicPartitionCount),
-
第 2 步:找出該磁區 Leader 副本所在的 Broker,該 Broker 即為對應的 Coordinator,
-
連接協調者
FindCoordinator回傳資料顯式地告訴消費者哪個 Broker 是真正的協調者,消費者知曉了真正的協調者后,會創建連向該 Broker 的 Socket 連接,只有成功連入協調者,協調者才能開啟正常的組協調操作,比如加入組、等待組分配方案、心跳請求處理、位移獲取、位移提交等,
-
消費資料
經過第二步,消費者組知道各個消費者需要消費哪個磁區的訊息,消費者會為每個要消費的磁區創建與該磁區領導者副本所在 Broker 連接的 TCP,
消費訊息
消費者位移
消費者連接對應Broker后,便可以消費指定磁區的訊息了,消費者也有一個位移,叫做消費者位移(Consumer Offset),表示消費者消費進度,每個消費者都有自己的消費者位移,
Consumer 需要向 Kafka 匯報自己的位移資料,這個匯報程序被稱為提交位移(Committing Offsets),因為 Consumer 能夠同時消費多個磁區的資料,所以位移的提交實際上是在磁區粒度上進行的,即Consumer 需要為分配給它的每個磁區提交各自的位移資料,
提交位移主要是為了表征 Consumer 的消費進度,這樣當 Consumer 發生故障重啟之后,就能夠從 Kafka 中讀取之前提交的位移值,然后從相應的位移處繼續消費,從而避免整個消費程序重來一遍,
當然,消費者的位移資料,就存放于位移主題中,
提交位移
消費者提交位移的方案有兩大類,自動提交和手動提交,
自動提交
Consumer 端引數 enable.auto.commit=true表示自動提交,Kafka 每auto.commit.interval.ms秒會自動提交一次位移,
-
優點:保證不出現消費丟失的情況,開啟自動提交,poll方法會先提交上一批訊息位移,后獲取訊息,
-
缺點:它可能會出現重復消費,如訊息已經處理,但未能及時提交位移,消費者便崩潰了,
手動提交
enable.auto.commit 設定為 false,然后呼叫API手動提交位移,手動提交API有三種:
- 同步提交:函式為KafkaConsumer#commitSync(),該方法會一直等待,直到位移被成功提交才會回傳,如果提交程序中出現例外,該方法會將例外資訊拋出,
-
優點:能夠自己把控位移提交的時機和頻率,
-
缺點:影響整個應用程式的 TPS,呼叫 commitSync() 時,Consumer 程式會處于阻塞狀態,直到遠端的 Broker 回傳提交結果,
- 異步提交:函式為KafkaConsumer#commitAsync(),呼叫 commitAsync() 之后,它會立即回傳,不會阻塞,Kafka 提供了回呼函式(callback),供我們實作提交之后的邏輯,比如記錄日志或處理例外等,
-
優點:不會影響 Consumer 應用的 TPS,
-
缺點:出現問題時它不會自動重試,重試也沒有價值
- 部分提交:Consumer位移提交,都是提交 poll 方法回傳的所有訊息的位移,如下兩個函式commitSync(Map<TopicPartition, OffsetAndMetadata>) 和commitAsync(Map<TopicPartition, OffsetAndMetadata>)支持部分提交poll下的位移,
- 優點:更加細粒度化地提交位移
實際上,手動提交也不能避免訊息重復消費,如果要避免重復消費,需要自行設計去重邏輯,
提交位移最佳實踐
如果是手動提交,我們需要將 commitSync 和 commitAsync 組合使用才能到達最理想的效果,原因有兩個:
-
我們可以利用 commitSync 的自動重試來規避那些瞬時錯誤,比如網路的瞬時抖動,Broker 端 GC 等,因為這些問題都是短暫的,自動重試通常都會成功,因此,我們不想自己重試,而是希望 Kafka Consumer 幫我們做這件事,
-
我們不希望程式總處于阻塞狀態,影響 TPS,
重平衡
時機
如果 Consumer Group 下的 Consumer 實體數量發生變化,就一定會引發重平衡(Rebalance),重平衡含義為:消費者組內某個消費者實體掛掉后,其他消費者實體自動重新分配訂閱主題磁區的程序,Rebalance 是 Kafka 消費者端實作高可用的重要手段,
其實有三個時機會引發重平衡:
-
組成員數量發生變化
-
訂閱主題數量發生變化
-
訂閱主題的磁區數發生變化
最常引起重平衡的時機是組成員數量變化,這種變化有可能確實是需要進行增減,也有可能是誤判:
-
每個Consumer實體都會定期地向Coordinator 發送心跳請求,表明它還存活著,所以需要合理設定session.timeout.ms 和 heartbeat.interval.ms,防止未能及時發送心跳,導致協調者誤將Consumer“踢出”Group”,
-
Consumer 程式如果在 max.poll.interval.ms 之內無法消費完 poll 方法回傳的訊息,那么 Consumer 會主動發起“離開組”的請求,Coordinator 也會開啟新一輪 Rebalance,所以需要合理設定max.poll.interval.ms,
重平衡程序
當協調者決定開啟新一輪重平衡后:
-
通知:每個Consumer實體都會定期地向Coordinator 發送心跳請求,Coordinator會將REBALANCE_IN_PROGRESS封裝進心跳請求的回應中,發還給消費者實體,當消費者實體發現心跳回應中包含了“REBALANCE_IN_PROGRESS”,就能立馬知道重平衡開始了,
-
加入組:消費者會向協調者發送 JoinGroup 請求,在該請求中,每個成員都要將自己訂閱的主題上報,這樣協調者就能收集到所有成員的訂閱資訊,
-
選舉消費者組領導者:一旦收集了全部成員的JoinGroup 請求后,協調者會從這些成員中選擇一個擔任這個消費者組的領導者,通常情況下,第一個發送 JoinGroup 請求的成員自動成為領導者,
-
訂閱資訊傳遞:選出領導者之后,協調者會把消費者組訂閱信息封裝進 JoinGroup 請求的回應體中,然后發給領導者,
-
制定磁區消費方案:領導者消費者的任務是收集所有成員的訂閱資訊,然后根據這些資訊,制定具體的磁區消費分配方案,
-
消費方案傳遞:領導者向協調者發送 SyncGroup 請求,將剛剛做出的分配方案發給協調者,
-
全員同步消費方案:協調者接收分配方案,然后統一以 SyncGroup 回應的方式分發給所有成員,這樣組內所有成員就都知道自己該消費哪些磁區了,
總結
終于梳理完整個流程了,太累了!閱讀資料后寫文章有三種方案:
一是先讀完一遍,然后一篇一篇重新讀,然后一篇一篇寫,使用的這個方案寫了《設計模式系列》
二是邊看邊寫,看一篇寫一篇,使用的這個方案寫了《MySQL系列》《演算法系列》
三是迅速讀完一遍,記錄核心點,心中重新梳理知識結構,趁著對知識的短期記憶,快速寫出文章,使用這個方案寫了《Kafka》
不得不說,第三個方案速度是真快,效果也很不錯,自己能夠清晰感受到隨著時間的流逝,記憶中的知識也在不斷消退,但是隨著文章的書寫,記憶會被重新喚起并被加深,但是這個方案需要注意力高度集中,并且能夠快速整理出核心知識點,后期可能會多使用方案三來進行學習,
最后
大家如果喜歡我的文章,可以關注我的公眾號(程式員麻辣燙)
我的個人博客為:https://shidawuhen.github.io/

往期文章回顧:
-
設計模式
-
招聘
-
思考
-
存盤
-
演算法系列
-
讀書筆記
-
小工具
-
架構
-
網路
-
Go語言
轉載請註明出處,本文鏈接:https://www.uj5u.com/qita/423755.html
標籤:其他