文章目錄
- 1 模型介紹
- 2 MLPConv
- 3 Global Average Pooling
- 4 模型特性
1 模型介紹
Network In Network (NIN)是由 M i n L i n Min Lin MinLin等人于2014年提出,在CIFAR-10和CIFAR-100分類任務中達到當時的最好水平,其網路結構是由三個多層感知機堆疊而被成,NiN模型論文《Network In Network》發表于ICLR-2014,NIN以一種全新的角度審視了卷積神經網路中的卷積核設計,通過引入子網路結構代替純卷積中的線性映射部分,這種形式的網路結構激發了更復雜的卷積神經網路的結構設計,GoogLeNet的Inception結構就是來源于這個思想,
2 MLPConv
作者認為,傳統CNN使用的線性濾波器(卷積核)是區域感受野下的一種廣義線性模型(Generalized linear model,GLM),所以用CNN進行特征提取時,其實就隱含地假設了特征是線性可分的,可實際問題往往是難以線性可分的,CNN中通過堆加卷積過濾器來產生更高層的特征表示,作者想到了除了像之前一樣堆加網路卷積層之外,還可以在卷積層里邊做特殊的設計,即使用更有效的非線性函式逼近器(nonlinear function approximator),來提高卷積層的抽象能力使得網路能夠在每個感受域提取更好的特征,
NiN中,在卷積層中使用了一種微型網路(micro network)提高卷積層的抽象能力,這里使用多層感知器(MLP)作為micro network,因為這個MLP衛星網路是位于卷積網路之中的,因此該模型被命名為“network in network” ,下圖對比了普通的線性卷積層和多層感知器卷積層(MlpConv Layer),
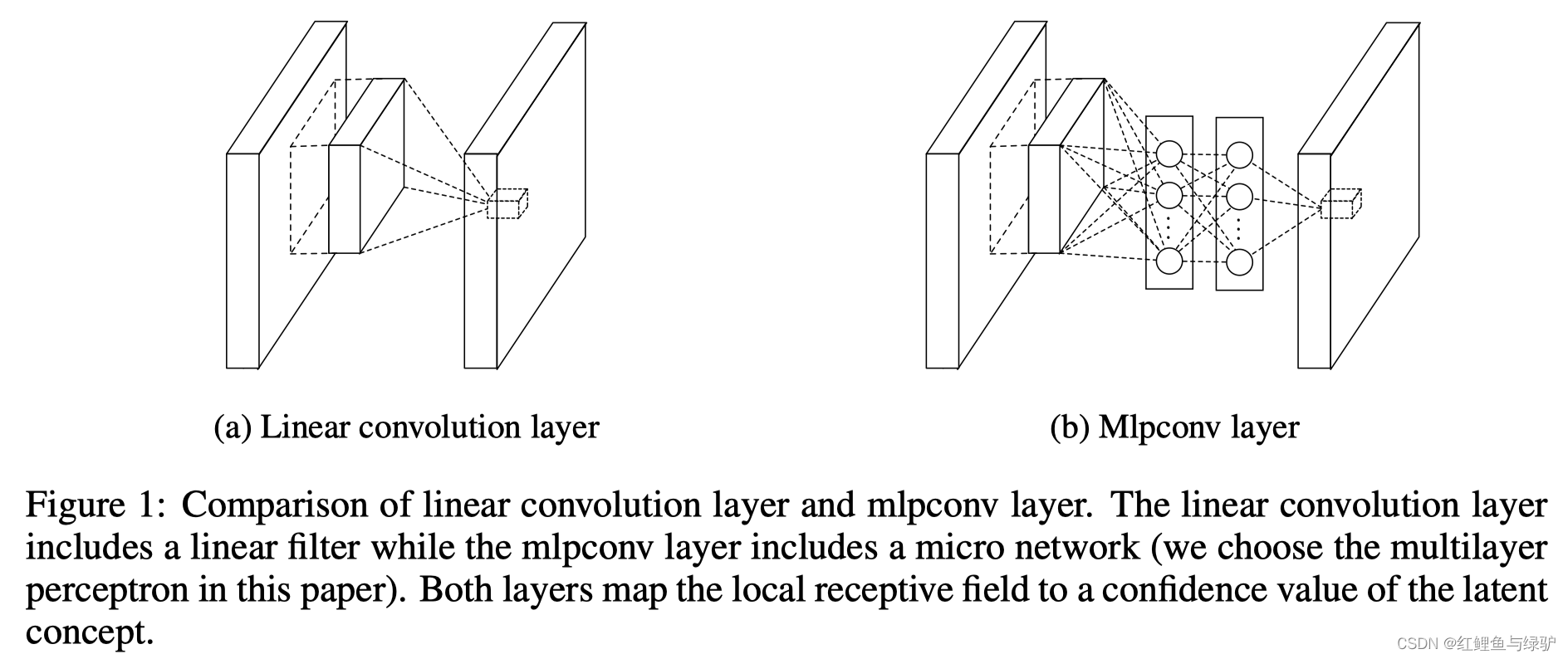
線性卷積層和MLPConv都是將區域感受野(local receptive field)映射到輸出特征向量,MLPConv核使用帶非線性激活函式的MLP,跟傳統的CNN一樣,MLP在各個區域感受野中共享引數的,滑動MLP核可以最終得到輸出特征圖,NIN通過多個MLPConv的堆疊得到,完整的NiN網路結構如下圖所示,
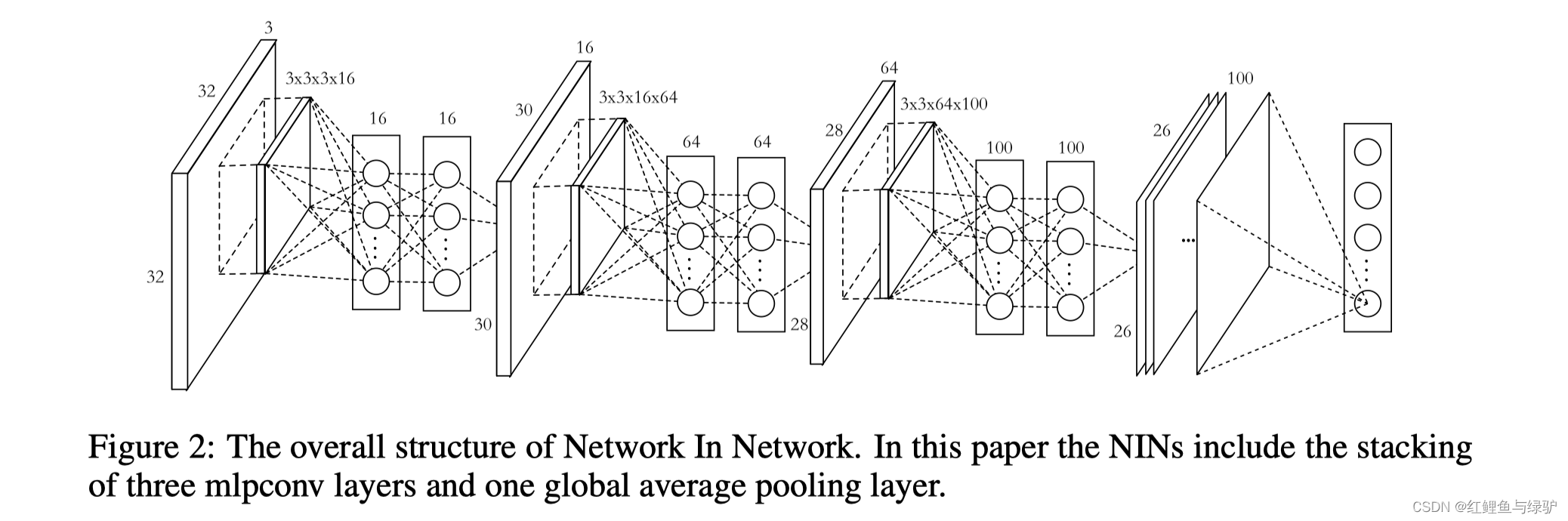
第一個卷積核是 3 × 3 × 3 × 16 3\times3\times3\times16 3×3×3×16,因此在一個patch塊上卷積的輸出是 1 × 1 × 96 1\times1\times96 1×1×96的feature map(一個96維的向量),在其后又接了一個MLP層,輸出仍然是96,因此這個MLP層就等價于一個 1 × 1 1\times1 1×1的卷積層,模型引數配置可參考下表,
| 網路層 | 輸入尺寸 | 核尺寸 | 輸出尺寸 | 引數個數 |
|---|---|---|---|---|
| 區域全連接層 L 11 L_{11} L11? | 32 × 32 × 3 32\times32\times3 32×32×3 | ( 3 × 3 ) × 16 / 1 (3\times3)\times16/1 (3×3)×16/1 | 30 × 30 × 16 30\times30\times16 30×30×16 | ( 3 × 3 × 3 + 1 ) × 16 (3\times3\times3+1)\times16 (3×3×3+1)×16 |
| 全連接層 L 12 L_{12} L12? | 30 × 30 × 16 30\times30\times16 30×30×16 | 16 × 16 16\times16 16×16 | 30 × 30 × 16 30\times30\times16 30×30×16 | ( ( 16 + 1 ) × 16 ) ((16+1)\times16) ((16+1)×16) |
| 區域全連接層 L 21 L_{21} L21? | 30 × 30 × 16 30\times30\times16 30×30×16 | ( 3 × 3 ) × 64 / 1 (3\times3)\times64/1 (3×3)×64/1 | 28 × 28 × 64 28\times28\times64 28×28×64 | ( 3 × 3 × 16 + 1 ) × 64 (3\times3\times16+1)\times64 (3×3×16+1)×64 |
| 全連接層 L 22 L_{22} L22? | 28 × 28 × 64 28\times28\times64 28×28×64 | 64 × 64 64\times64 64×64 | 28 × 28 × 64 28\times28\times64 28×28×64 | ( ( 64 + 1 ) × 64 ) ((64+1)\times64) ((64+1)×64) |
| 區域全連接層 L 31 L_{31} L31? | 28 × 28 × 64 28\times28\times64 28×28×64 | ( 3 × 3 ) × 100 / 1 (3\times3)\times100/1 (3×3)×100/1 | 26 × 26 × 100 26\times26\times100 26×26×100 | ( 3 × 3 × 64 + 1 ) × 100 (3\times3\times64+1)\times100 (3×3×64+1)×100 |
| 全連接層 L 32 L_{32} L32? | 26 × 26 × 100 26\times26\times100 26×26×100 | 100 × 100 100\times100 100×100 | 26 × 26 × 100 26\times26\times100 26×26×100 | ( ( 100 + 1 ) × 100 ) ((100+1)\times100) ((100+1)×100) |
| 全局平均采樣 G A P GAP GAP | 26 × 26 × 100 26\times26\times100 26×26×100 | 26 × 26 × 100 / 1 26\times26\times100/1 26×26×100/1 | 1 × 1 × 100 1\times1\times100 1×1×100 | 0 0 0 |
在NIN中,經過三層MLPConv后,不接全連接層(FC),而是將最后一個的MLPConv的輸出特征圖全域平均池化(global average pooling,GAP),下文對全域平均池化層做具體介紹,
3 Global Average Pooling
傳統的CNN模型先是使用堆疊的卷積層提取特征,輸入全連接層(FC)進行分類,這種結構沿襲自LeNet5,把卷積層作為特征抽取器,全連接層作為分類器,但是FC層引數數量太多,很容易過擬合,會影響模型的泛化性能,因此需要用Dropout增加模型的泛化性,
這里提出GAP代替傳統的FC層,主要思想是將每個分類對應最后一層MLPConv的輸出特征圖,對每個特征圖取平均,后將得到的池化后的向量softmax得到分類概率,GAP的優點有:
- 加強了特征映射和類別之間的對應,更適合卷積神經網路,特征圖可以被解釋類別置信度,
- GAP層不用優化引數,可以避免過擬合,
- GAP對空間資訊進行匯總,因此對輸入資料的空間變換有更好的魯棒性,
可以將GAP看做一個結構正則化器,顯性地強制特征圖映射為概念置信度,
4 模型特性
- 使用多層感知機結構來代替卷積的濾波操作,不但有效減少卷積核數過多而導致的引數量暴漲問題,還能通過引入非線性的映射來提高模型對特征的抽象能力,
- 使用全域平均池化來代替最后一個全連接層,能夠有效地減少引數量(沒有可訓練引數),同時池化用到了整個特征圖的資訊,對空間資訊的轉換更加魯棒,最后得到的輸出結果可直接作為對應類別的置信度,
轉載請註明出處,本文鏈接:https://www.uj5u.com/qita/423855.html
標籤:AI
上一篇:深度學習------用NN、CNN、RNN神經網路實作mnist資料集處理
下一篇:機器學習(十) 強化學習