目錄
走進XGBoost
什么是XGBoost?
XGBoost樹的定義
XGBoost核心演算法
正則項:樹的復雜程度
XGBoost與GBDT有什么不同
XGBoost需要注意的點
XGBoost重要引數詳解
調參步驟及思想
XGBoost代碼案例
相關性分析
n_estimators(學習曲線)
max_depth(學習曲線)
調整max_depth 和min_child_weight
調整gamma
調整subsample 和colsample_bytree
調整正則化引數
網格搜索
最終模型代碼
繪制特征重要性圖
XGBoost可視化
ROC曲線AUC面積
每文一語
👇👇🧐🧐??🎉🎉
歡迎點擊專欄其他文章(歡迎訂閱·持續更新中~)
機器學習之Python開源教程——專欄介紹及理論知識概述
機器學習框架及評估指標詳解
Python監督學習之分類演算法的概述
資料預處理之資料清理,資料集成,資料規約,資料變化和離散化
特征工程之One-Hot編碼、label-encoding、自定義編碼
卡方分箱、KS分箱、最優IV分箱、樹結構分箱、自定義分箱
特征選取之單變數統計、基于模型選擇、迭代選擇
機器學習分類演算法之樸素貝葉斯
【萬字詳解·附代碼】機器學習分類演算法之K近鄰(KNN)
《全網最強》詳解機器學習分類演算法之決策樹(附可視化和代碼)
機器學習分類演算法之支持向量機
機器學習分類演算法之Logistic 回歸(邏輯回歸)
機器學習分類演算法之隨機森林(集成學習演算法)
持續更新中~
作者簡介
👦博客名:王小王-123
👀簡介:CSDN博客專家、CSDN簽約作者、華為云享專家,騰訊云、阿里云、簡書、InfoQ創作者,公眾號:書劇可詩畫,2020年度CSDN優秀創作者,左手詩情畫意,右手代碼人生,歡迎一起探討技術
走進XGBoost
什么是XGBoost?
- 全稱:eXtreme Gradient Boosting
- 作者:陳天奇(華盛頓大學博士)
- 基礎:GBDT
- 所屬:boosting迭代型、樹類演算法,
- 適用范圍:分類、回歸
- 優點:速度快、效果好、能處理大規模資料、支持多種語言、支持自定義損失函式等等,
- 缺點:演算法引數過多,調參負責,對原理不清楚的很難使用好XGBoost,不適合處理超高維特征資料,
XGBoost是陳天奇等人開發的一個開源機器學習專案,高效地實作了GBDT演算法并進行了演算法和工程上的許多改進,被廣泛應用在Kaggle競賽及其他許多機器學習競賽中并取得了不錯的成績,
說到XGBoost,不得不提GBDT(Gradient Boosting Decision Tree),因為XGBoost本質上還是一個GBDT,但是力爭把速度和效率發揮到極致,所以叫X (Extreme) GBoosted,
XGBoost樹的定義
先來舉個例子,我們要預測一家人對電子游戲的喜好程度,考慮到年輕和年老相比,年輕更可能喜歡電子游戲,以及男性和女性相比,男性更喜歡電子游戲,故先根據年齡大小區分小孩和大人,然后再通過性別區分開是男是女,逐一給各人在電子游戲喜好程度上打分,如下圖所示,
?
就這樣,訓練出了2棵樹tree1和tree2,類似gbdt的原理,兩棵樹的結論累加起來便是最終的結論,所以小孩的預測分數就是兩棵樹中小孩所落到的結點的分數相加:2 + 0.9 = 2.9,爺爺的預測分數同理:-1 + (-0.9)= -1.9,具體如下圖所示:
?
? 這個圖形也可以使用XGBoost自帶方法可視化,和上面那個預測圖一樣的意義
如果你對gbdt有所了解,你會發現這不是一樣的嗎?
事實上,如果不考慮工程實作、解決問題上的一些差異,XGBoost與GBDT比較大的不同就是目標函式的定義,XGBoost的目標函式如下圖所示:
?
如果光看這一張圖片,你也許會有所疑惑,這些到底是什么?
紅色箭頭所指向的L 即為損失函式(比如平方損失函式:l(yi,yi)=(yi?yi)2)
紅色方框所框起來的是正則項(包括L1正則、L2正則)
紅色圓圈所圈起來的為常數項
對于f(x),XGBoost利用泰勒展開三項,做一個近似,f(x)表示的是其中一顆回歸樹,
再舉一個簡單的例子
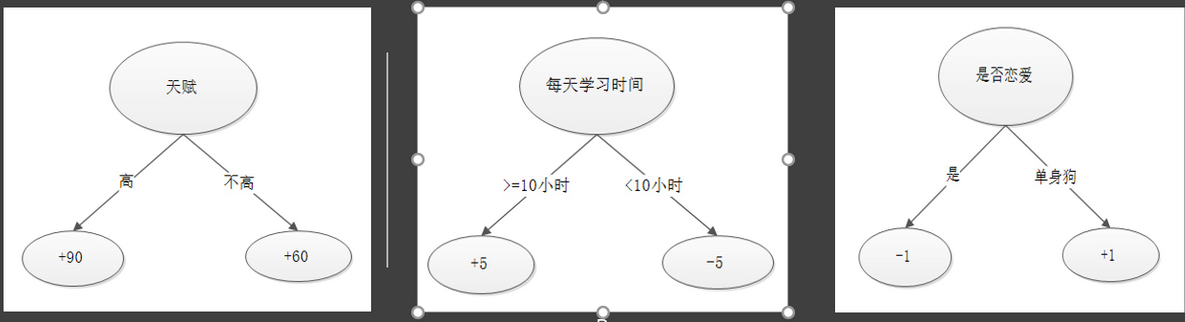 ? 首先我們初始化三個樣例的考試成績預測值為0,屬性為(天賦高、不戀愛、每天學習時間有16個小時),(天賦低、不戀愛、每天學習時間有16個小時),(天賦高、不戀愛、每天學習時間有6個小時),真實成績分別為100,70,86分,
? 首先我們初始化三個樣例的考試成績預測值為0,屬性為(天賦高、不戀愛、每天學習時間有16個小時),(天賦低、不戀愛、每天學習時間有16個小時),(天賦高、不戀愛、每天學習時間有6個小時),真實成績分別為100,70,86分,
Xgboost系統的每次迭代都會構建一顆新的決策樹,決策樹通過與真實值之間殘差來構建,(天賦高、不戀愛、每天學習時間有16個小時)的學霸考了100分,(天賦低、不戀愛、每天學習時間有16個小時)的小學霸考了70分,(天賦高、不戀愛、每天學習時間有6個小時)的小天才考了86分,那么三位同學通過第一個決策樹后預測結果分別為90分,60分,和90分,
在構建第二顆決策樹時就會考慮殘差(100-90=10),(70-60)=10,(86-90=-4)來構建一顆新的樹,我們通過最小化殘差學習到一個通過學習時間屬性來構建的決策樹的得到90+5,60+5,90-5的預測值,再繼續通過(100-95=5)(70-65)(86-85)的殘差構建下一個決策樹,以此類推,當迭代次數達到上限或是殘差不再減小是停止,就得到一個擁有多個(迭代次數)決策樹的強分類器,
當然分類器是需要考慮更多樣本的,我們可以把新加入的決策樹fi(x)看作是在N維空間(因為有N個樣本)中p(m)相對于點p(m-1)的增量,
XGBoost核心演算法
- 不斷地添加樹,不斷地進行特征分裂來生長一棵樹,每次添加一個樹,其實是學習一個新函式f(x),去擬合上次預測的殘差,
- 當我們訓練完成得到k棵樹,我們要預測一個樣本的分數,其實就是根據這個樣本的特征,在每棵樹中會落到對應的一個葉子節點,每個葉子節點就對應一個分數
- 最后只需要將每棵樹對應的分數加起來就是該樣本的預測值,
為了保證預測值和真實值的匹配
XGBoost也是需要將多棵樹的得分累加得到最終的預測得分(每一次迭代,都在現有樹的基礎上,增加一棵樹去擬合前面樹的預測結果與真實值之間的殘差),在前面也提到過,
 ?
?
那接下來,我們如何選擇每一輪加入什么 f 呢?答案是非常直接的,選取一個 f 來使得我們的目標函式盡量最大地降低,這里 f 可以使用泰勒展開公式近似,
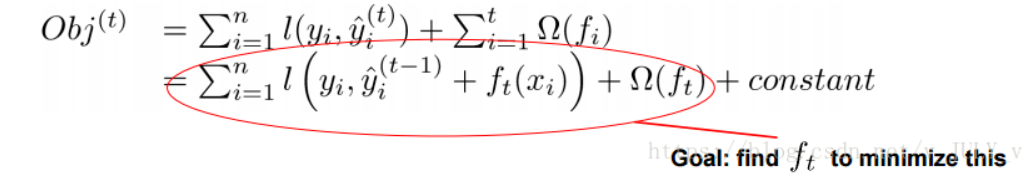 ?
?
實質是把樣本分配到葉子結點會對應一個obj,優化程序就是obj優化,也就是分裂節點到葉子不同的組合,不同的組合對應不同obj,所有的優化圍繞這個思想展開,
到目前為止我們討論了目標函式中的第一個部分:訓練誤差;下面就開始討論目標函式的第二個部分:正則項,即如何定義樹的復雜度,
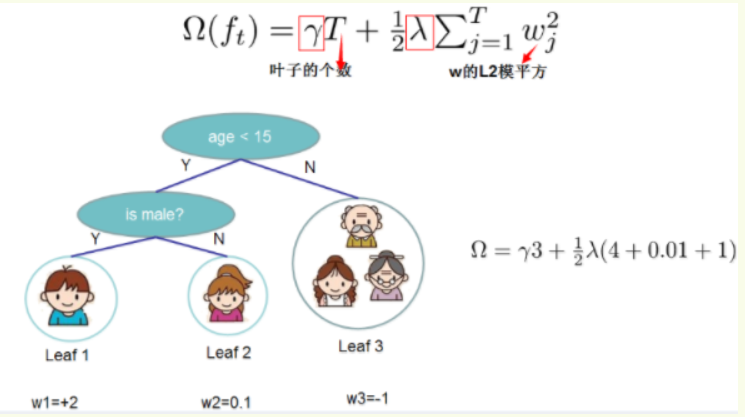
正則項:樹的復雜程度
XGBoost的復雜程度包含了兩個重要的部分,一個是樹里面葉子節點的個數T,一個是樹上葉子節點的得分w的L2模平方(對w進行L2正則化,相當于針對每個葉結點的得分增加L2平滑,目的是為了避免過擬合)
 ?
?
XGBoost的目標函式(損失函式揭示訓練誤差 + 正則化定義復雜度):
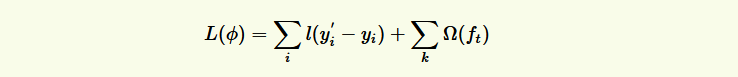 ?
?
總而言之,XGBoost使用了和CART回歸樹一樣的想法,利用貪婪演算法,遍歷所有特征的所有特征劃分點,不同的是使用的目標函式不一樣,具體做法就是分裂后的目標函式值比單子葉子節點的目標函式的增益,同時為了限制樹生長過深,還加了個閾值,只有當增益大于該閾值才進行分裂,從而繼續分裂,形成一棵樹,再形成一棵樹,每次在上一次的預測基礎上取最優進一步分裂/建樹,
 ?
?
XGBoost與GBDT有什么不同
- GBDT是機器學習演算法,XGBoost是該演算法的工程實作,
- 在使用CART作為基分類器時,XGBoost顯式地加入了正則項來控制模 型的復雜度,有利于防止過擬合,從而提高模型的泛化能力,
- GBDT在模型訓練時只使用了代價函式的一階導數資訊,XGBoost對代價函式進行二階泰勒展開,可以同時使用一階和二階導數,
- 傳統的GBDT采用CART作為基分類器,XGBoost支持多種型別的基分類器,比如線性分類器,
- 傳統的GBDT在每輪迭代時使用全部的資料,XGBoost則采用了與隨機森林相似的策略,支持對資料進行采樣,
- 傳統的GBDT沒有設計對缺失值進行處理,XGBoost能夠自動學習出缺 失值的處理策略,
XGBoost需要注意的點
是否需要做特征篩選?
XGBoost可以做特征篩選,也就是重要性特征排序,那么我們的模型演算法需要做特征篩選嗎?根據經驗來說是不一定,有時候不去剔除反而是最好的,看到網上帖子有一個生動形象的表達:
對于有懲罰項的機器學習演算法,不需要,特征選擇更多見到的是邏輯回歸這種有考慮置信區間的演算法,因為要考慮置信區間(達不到95%以上的可信度我就不要了),所以要做特征取舍,因為要做特征取舍,所以要考慮多重共線性問題,因為共線性會直接影響特征的重要性表現,
事實上也是如此,在前期的幾個文章里面,我們基于決策樹,隨機森林等做的特征篩選,反而沒有提高模型的效果,還降低了,
對于你不清楚的特征,需要謹慎,因為這有可能是只有短期有效的垃圾特征,
比如瓜長得大不大,跟國足踢球進沒進,就大概率沒關系,但有可能在特定的農場里有用,比如這個農場的管理員是個球迷,國足踢球踢進了,他就開心,就額外多施肥,那么“國足踢球進沒進”這個特征在這個農場里就是一個有力的特征,但放到其他農場里就沒用了,這就是一個泛化能力很弱的特征,這樣100個不同型別的特征進行刪減,可能只有兩三個是有用的,
是否需要對資料集歸一化?
“答案是不需要,首先,歸一化是對連續特征來說的,那么連續特征的歸一化,起到的主要作用是進行數值縮放,數值縮放的目的是解決梯度下降時,等高線是橢圓導致迭代次數增多的問題,而xgboost等樹模型是不能進行梯度下降的,因為樹模型是階越的,不可導,樹模型是通過尋找特征的最優分裂點來完成優化的,由于歸一化不會改變分裂點的位置,因此xgboost不需要進行歸一化,”
XGBoost重要引數詳解
1、booster [default=gbtree]
選擇每次迭代程序中需要運行的模型,一共有兩種選擇:gbtree:;tree-based models,但是一般選擇是樹,線性不是很好
2、eta [default=0.3, alias: learning_rate]
學習率,可以縮減每一步的權重值,使得模型更加健壯:典型值一般設定為:0.01-0.2
越大,迭代的速度越快,演算法的極限很快被達到,有可能無法收斂到真正的最佳, 越小,越有可能找到更精確的最佳值,更多的空間被留給了后面建立的樹,但迭代速度會比較緩慢,
3、min_child_weight [default=1]
定義了一個子集的所有觀察值的最小權重和,這個可以用來減少過擬合,但是過高的值也會導致欠擬合,因此可以通過CV來調整min_child_weight,
4、max_depth [default=6]
樹的最大深度,值越大,樹越復雜,這個可以用來控制過擬合,典型值是3-10,
5、gamma [default=0, alias: min_split_loss]
這個指定了一個結點被分割時,所需要的最小損失函式減小的大小,這個值一般來說需要根據損失函式來調整,
6、alpha [default=0, alias: reg_alpha]
L1正則化(與lasso回歸中的正則化類似:傳送門)這個主要是用在資料維度很高的情況下,可以提高運行速度,
7、objective [default=reg:linear]
這個主要是指定學習目標的:而分類,還是多分類或者回歸
“reg:linear” –linear regression:回歸
“binary:logistic”:二分類
“multi:softmax” :多分類,這個需要指定類別個數
?
8、subsample有放回隨機抽樣
我們都知道樹模型是天生過擬合的模型,并且如果資料量太過巨大,樹模型的計算會非常緩慢,因此,我們要對我們的原始資料集進行有放回抽樣(bootstrap),有放回的抽樣每次只能抽取一個樣本,若我們需要總共N個樣本,就需要抽取N次,每次抽取一個樣本的程序是獨立的,這一次被抽到的樣本會被放回資料集中,下一次還可能被抽到,因此抽出的資料集中,可能有一些重復的資料,
sklearn的隨機森林類中也有名為boostrap的引數來幫助我們控制這種隨機有放回抽樣,同時,這樣做還可以保證集成演算法中的每個弱分類器(每棵樹)都是不同的模型,基于不同的資料建立的自然是不同的模型,而集成一系列一模一樣的弱分類器是沒有意義的,
在sklearn中,我們使用引數subsample來控制我們的隨機抽樣,在xgb和sklearn中,這個引數都默認為1且不能取到0,這說明我們無法控制模型是否進行隨機有放回抽樣,只能控制抽樣抽出來的樣本量大概是多少,
 ?
?
從這個角度來看,我們的subsample引數對模型的影回應該會非常不穩定,大概率應該是無法提升模型的泛化能力的,但也不乏提升模型的可能性,
資料集過少,降低抽樣的比例反而讓資料的效果更低,不如就讓它保持默認
演算法引數過多,調參復雜,對原理不清楚的很難使用好XGBoost,這也是為什么XGBoost好,但是很多人卻用不好的原因之一,首先調參就是一個難題
調參步驟及思想
-
選擇較高的學習速率(learning rate),一般情況下,學習速率的值為0.1,但是,對于不同的問題,理想的學習速率有時候會在0.05到0.3之間波動,選擇對應于此學習速率的理想決策樹數量,XGBoost有一個很有用的函式“cv”,這個函式可以在每一次迭代中使用交叉驗證,并回傳理想的決策樹數量,
-
對于給定的學習速率和決策樹數量,進行決策樹特定引數調優(max_depth, min_child_weight, gamma, subsample, colsample_bytree),在確定一棵樹的程序中,我們可以選擇不同的引數,待會兒我會舉例說明,
-
xgboost的正則化引數的調優,(lambda, alpha),這些引數可以降低模型的復雜度,從而提高模型的表現,
-
降低學習速率,確定理想引數,
XGBoost代碼案例
XGBoost效果確實不錯,但是前提是要將引數不斷地優化和調整,這樣最終才能得到一個較好的模型,下面依然以一個實際的案例進行XGBoost代碼演示
#匯入所需要的包
from sklearn.metrics import precision_score
from sklearn.model_selection import train_test_split
import xgboost as xgb
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
from matplotlib.colors import ListedColormap
from sklearn.preprocessing import LabelEncoder
from sklearn.metrics import classification_report
from sklearn.model_selection import GridSearchCV #網格搜索
import matplotlib.pyplot as plt#可視化
import seaborn as sns#繪圖包
# 忽略警告
import warnings
warnings.filterwarnings("ignore")相關性分析
plt.figure(figsize=(20,20))
plt.rcParams['font.sans-serif']=['SimHei']
plt.rcParams['axes.unicode_minus']=False
sns.heatmap(df.corr(),cmap="YlGnBu",annot=True)
plt.title("相關性分析圖")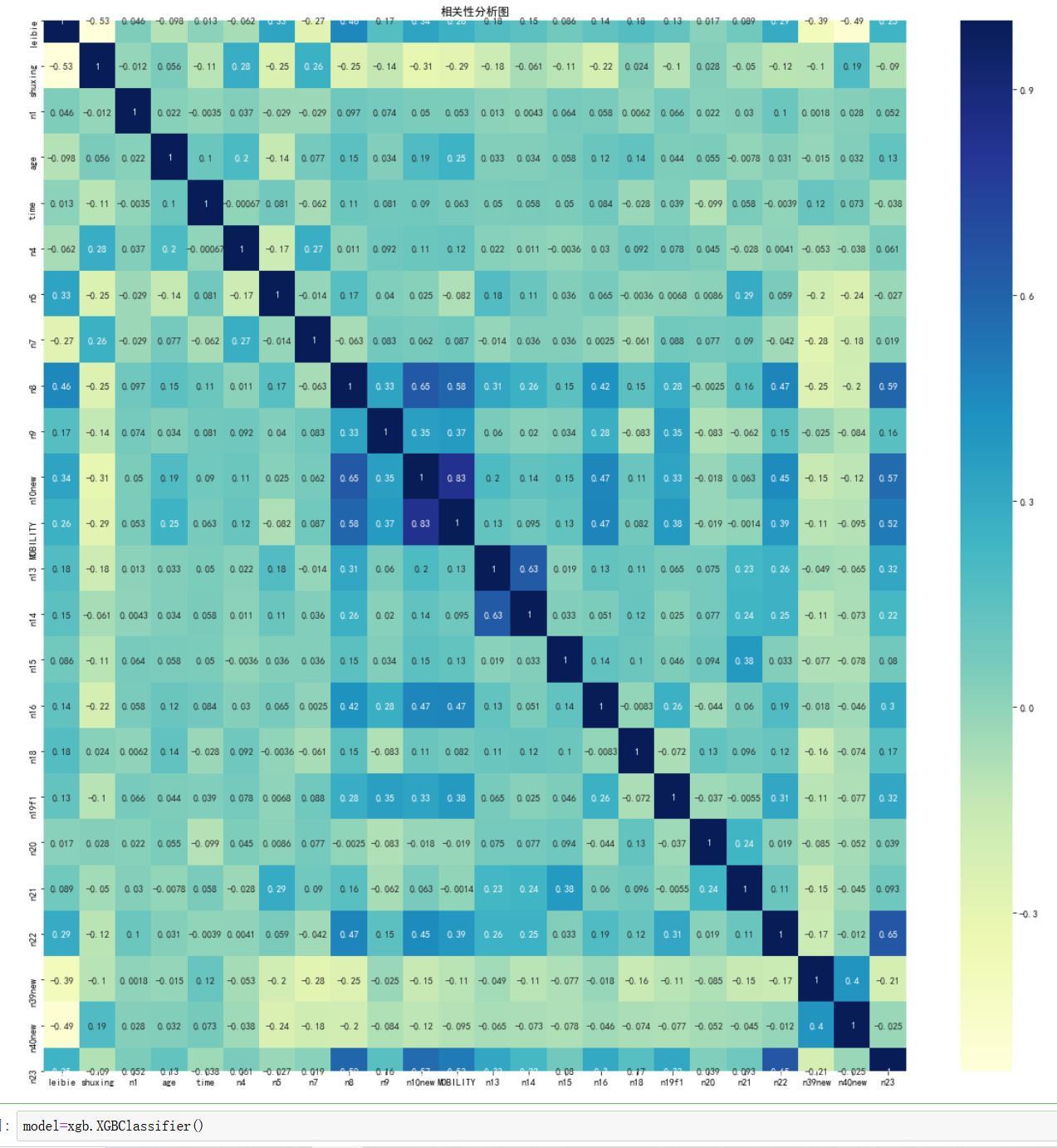 ?
?
XGBoost無引數模型
model=xgb.XGBClassifier()
# 訓練模型
model.fit(X_train,y_train)
# 預測值
y_pred = model.predict(X_test)
'''
評估指標
'''
# 求出預測和真實一樣的數目
true = np.sum(y_pred == y_test )
print('預測對的結果數目為:', true)
print('預測錯的的結果數目為:', y_test.shape[0]-true)
# 評估指標
from sklearn.metrics import accuracy_score,precision_score,recall_score,f1_score,cohen_kappa_score
print('預測資料的準確率為: {:.4}%'.format(accuracy_score(y_test,y_pred)*100))
print('預測資料的精確率為:{:.4}%'.format(
precision_score(y_test,y_pred)*100))
print('預測資料的召回率為:{:.4}%'.format(
recall_score(y_test,y_pred)*100))
# print("訓練資料的F1值為:", f1score_train)
print('預測資料的F1值為:',
f1_score(y_test,y_pred))
print('預測資料的Cohen’s Kappa系數為:',
cohen_kappa_score(y_test,y_pred))
# 列印分類報告
print('預測資料的分類報告為:','
',
classification_report(y_test,y_pred))
?
效果還是不錯,比之前用其他的模型反復的調優的效果還好,但是這不是XGBoost的最終效果
n_estimators(學習曲線)
scorel = []
for i in range(0,300,10):
model = xgb.XGBClassifier(n_estimators=i+1,
n_jobs=--4,
random_state=90).fit(X_train,y_train)
score = model.score(X_test,y_test)
scorel.append(score)
print(max(scorel),(scorel.index(max(scorel))*10)+1) #作圖反映出準確度隨著估計器數量的變化,51的附近最好
plt.figure(figsize=[20,5])
plt.plot(range(1,300,10),scorel)
plt.show()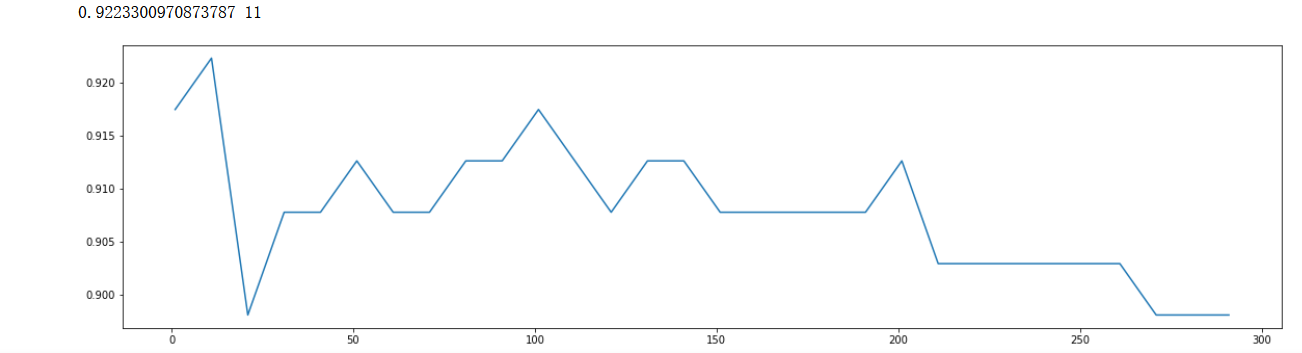 ?
?
繼續迭代優化,縮小范圍
scorel = []
for i in range(0,20,1):
model = xgb.XGBClassifier(n_estimators=i+1,
n_jobs=--4,
random_state=90).fit(X_train,y_train)
score = model.score(X_test,y_test)
scorel.append(score)
print(max(scorel),(scorel.index(max(scorel))*1)+1) #作圖反映出準確度隨著估計器數量的變化,51的附近最好
plt.figure(figsize=[20,5])
plt.plot(range(0,20,1),scorel)
plt.show()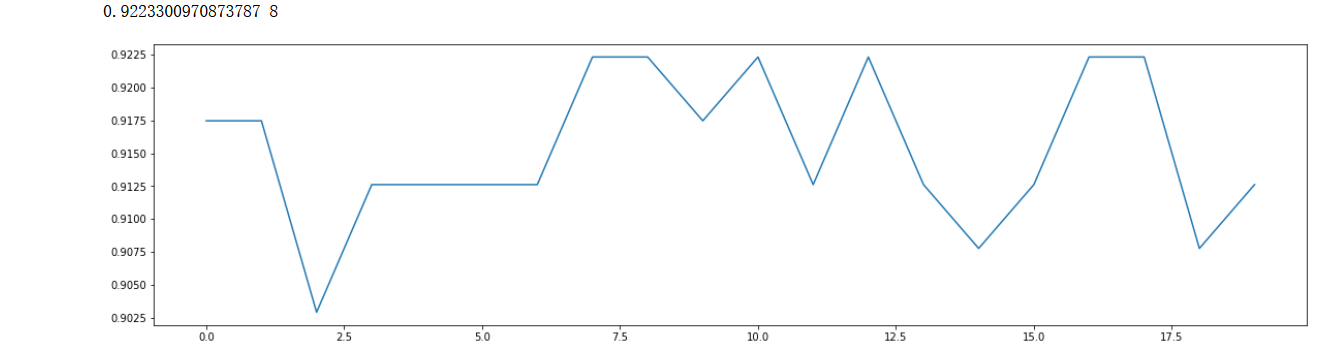 ?
?
max_depth(學習曲線)
scorel = []
for i in range(0,20,1):
model = xgb.XGBClassifier(max_depth =i,
n_estimators=8,
n_jobs=--4,
random_state=90).fit(X_train,y_train)
score = model.score(X_test,y_test)
scorel.append(score)
print(max(scorel),(scorel.index(max(scorel))*1)+1) #作圖反映出準確度隨著估計器數量的變化,51的附近最好
plt.figure(figsize=[20,5])
plt.plot(range(0,20,1),scorel)
plt.show()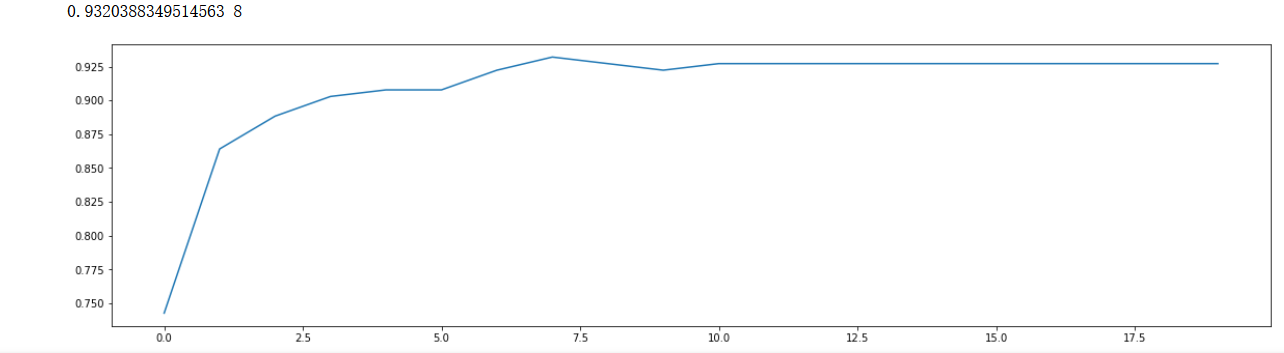 ?
?
效果有所提升,繼續調優,但是我們知道XGBoost的引數過于的多,如果按照傳統的學習曲線迭代調優,效果可能局限在區域最優 ,下面試試XGBoost的交叉驗證
調整max_depth 和min_child_weight
param_test1 = {
# 'n_estimators':list(range(3,15,1)),
'max_depth':list(range(3,10,2)),
'min_child_weight':list(range(1,6,2))
}
gsearch1 = GridSearchCV(estimator = xgb.XGBClassifier( learning_rate =0.1, n_estimators=8, max_depth=8,
min_child_weight=1, gamma=0, subsample=0.8, colsample_bytree=0.8,
objective= 'binary:logistic', nthread=4, scale_pos_weight=1, seed=27),
param_grid = param_test1, scoring='roc_auc',iid=False, cv=5)
gsearch1=gsearch1.fit(X,y)
gsearch1.best_params_, gsearch1.best_score_({'max_depth': 3, 'min_child_weight': 5}, 0.9200952807471878)
進一步調整
param_test1 = {
'max_depth':list(range(8,11,1)),
'min_child_weight':list(range(1,4,1))
}
gsearch1 = GridSearchCV(estimator = xgb.XGBClassifier( learning_rate =0.1, n_estimators=7, max_depth=3,
min_child_weight=5, gamma=0, subsample=0.8, colsample_bytree=0.8,
objective= 'binary:logistic', nthread=4, scale_pos_weight=1, seed=27),
param_grid = param_test1, scoring='roc_auc',iid=False, cv=5)
gsearch1.fit(X,y)
gsearch1.best_params_, gsearch1.best_score_({'max_depth': 8, 'min_child_weight': 3}, 0.9158850465045336)
調整gamma
param_test3 = {
'gamma':[i/10.0 for i in range(0,5)]
}
gsearch3 = GridSearchCV(estimator = xgb.XGBClassifier( learning_rate =0.1, n_estimators=8, max_depth=8,
min_child_weight=3, gamma=0, subsample=0.8, colsample_bytree=0.8,
objective= 'binary:logistic', nthread=4, scale_pos_weight=1,seed=27),
param_grid = param_test3, scoring='roc_auc',iid=False, cv=5)
gsearch3.fit(X,y)
gsearch3.best_params_, gsearch3.best_score_({'gamma': 0.4}, 0.9103697321364825)
調整subsample 和colsample_bytree
param_test5 = {
'subsample':[i/100.0 for i in range(75,90,5)],
'colsample_bytree':[i/100.0 for i in range(75,90,5)]
}
gsearch5 = GridSearchCV(estimator = xgb.XGBClassifier( learning_rate =0.1, n_estimators=8, max_depth=8,
min_child_weight=3, gamma=0.4, subsample=0.8, colsample_bytree=0.8,
objective= 'binary:logistic', nthread=4, scale_pos_weight=1,seed=27),
param_grid = param_test5, scoring='roc_auc',iid=False, cv=5)
gsearch5.fit(X_train,y_train)
gsearch5.best_params_, gsearch5.best_score_({'colsample_bytree': 0.85, 'subsample': 0.85}, 0.9420290874342445)
效果一下就有了顯著的提升,繼續調參,因為這個引數還是比較的重要有放回隨機抽樣
調整正則化引數
param_test6 = {
'reg_alpha':[1e-5, 1e-2, 0.1, 1, 100]
}
gsearch6 = GridSearchCV(estimator = xgb.XGBClassifier( learning_rate =0.1, n_estimators=8, max_depth=8,
min_child_weight=3, gamma=0.2, subsample=0.85, colsample_bytree=0.85,
objective= 'binary:logistic', nthread=4, scale_pos_weight=1,seed=27),
param_grid = param_test6, scoring='roc_auc',iid=False, cv=5)
gsearch6.fit(X_train,y_train)
gsearch6.best_params_, gsearch6.best_score_({'reg_alpha': 1e-05}, 0.9426155352636133)
param_test6 = {
'learning_rate':[0.01, 0.02, 0.1, 0.2]
}
gsearch6 = GridSearchCV(estimator = xgb.XGBClassifier( learning_rate =0.1, n_estimators=8, max_depth=8,
min_child_weight=1, gamma=0.2, subsample=0.8, colsample_bytree=0.85,
objective= 'binary:logistic', nthread=4, scale_pos_weight=1,seed=27),
param_grid = param_test6, scoring='roc_auc',iid=False, cv=5)
gsearch6.fit(X_train,y_train)
gsearch6.best_params_, gsearch6.best_score_({'learning_rate': 0.1}, 0.9506471151048836)
網格搜索
根據前面所出來的引數,可以進一步的縮放數值,最后采用暴力搜索網格調參,但是由于XGBoost本身就是一個運行速度慢,占據CPU的一個模型,加上網格搜索速度反而變的更慢了,所以這里需要謹慎設定引數,不然電腦會跑的嗡嗡響
# learning_rate =0.1, n_estimators=8, max_depth=8,
# min_child_weight=1, gamma=0.2, subsample=0.8, colsample_bytree=0.85,
# objective= 'binary:logistic', nthread=4, scale_pos_weight=1,seed=27
import numpy as np
from sklearn.model_selection import GridSearchCV
parameters = {'n_estimators':np.arange(6,10,1)
,'max_depth':np.arange(6,10,1)
,"colsample_bytree":np.arange(0.8,0.9,0.05)
,"subsample":np.arange(0.8,0.9,0.05)
,'gamma':np.arange(0.1,0.5,0.1)
,'min_child_weight':np.arange(1,3,1)
}
clf = xgb.XGBClassifier(random_state=25)
GS = GridSearchCV(clf, parameters, cv=5) # cv交叉驗證
GS.fit(X_train,y_train)
print(GS.best_params_)
print(GS.best_score_)
{'colsample_bytree': 0.8, 'gamma': 0.4, 'max_depth': 7, 'min_child_weight': 1, 'n_estimators': 8, 'subsample': 0.8}
0.9048780487804878
額,這么說呢,網格搜索的效果還不如自己之前的引數靠譜,事實上說明,我們在優化引數的時候,按照固定思維得出的數值只是一個參考值,我們自己還可以做一些調整(細微的)
最終模型代碼
model=xgb.XGBClassifier(eta =0.1, n_estimators=8, max_depth=8,
min_child_weight=2, gamma=0.8, subsample=0.85, colsample_bytree=0.8)
# 訓練模型
model.fit(X_train,y_train)
# 預測值
y_pred = model.predict(X_test)
'''
評估指標
'''
# 求出預測和真實一樣的數目
true = np.sum(y_pred == y_test )
print('預測對的結果數目為:', true)
print('預測錯的的結果數目為:', y_test.shape[0]-true)
# 評估指標
from sklearn.metrics import accuracy_score,precision_score,recall_score,f1_score,cohen_kappa_score
print('預測資料的準確率為: {:.4}%'.format(accuracy_score(y_test,y_pred)*100))
print('預測資料的精確率為:{:.4}%'.format(
precision_score(y_test,y_pred)*100))
print('預測資料的召回率為:{:.4}%'.format(
recall_score(y_test,y_pred)*100))
# print("訓練資料的F1值為:", f1score_train)
print('預測資料的F1值為:',
f1_score(y_test,y_pred))
print('預測資料的Cohen’s Kappa系數為:',
cohen_kappa_score(y_test,y_pred))
# 列印分類報告
print('預測資料的分類報告為:','
',
classification_report(y_test,y_pred))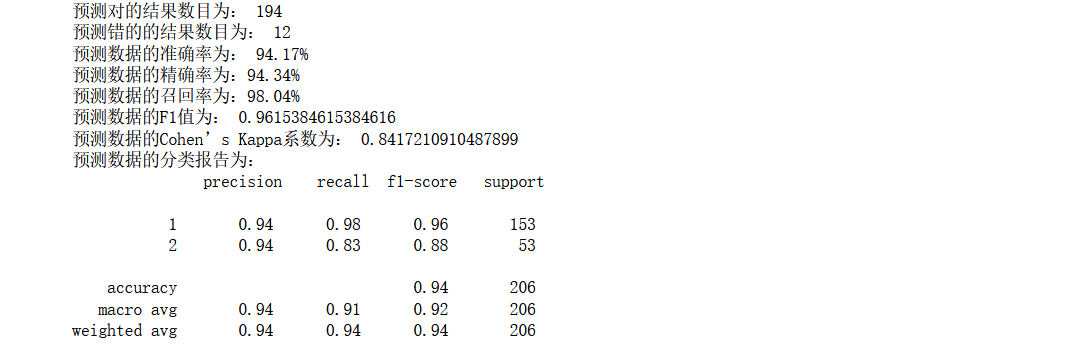 ?
?
效果還是不錯的,和隨機森林有點相近,從這里也可以看出集成學習的優勢所在
繪制特征重要性圖
from xgboost import plot_importance
# plt.figure(figsize=(15,15))
plt.rcParams["figure.figsize"] = (14, 8)
plot_importance(model)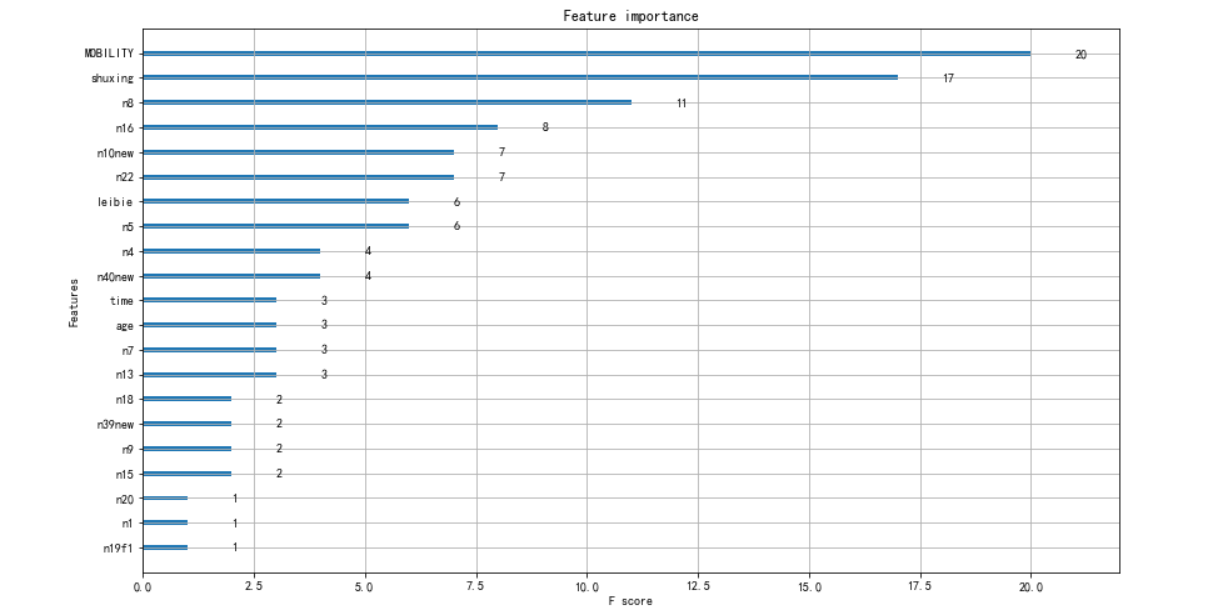 ?
?
XGBoost可視化
xgboosts=xgb.to_graphviz(model)
xgboosts.format = 'png'
xgboosts.view('./xgboost')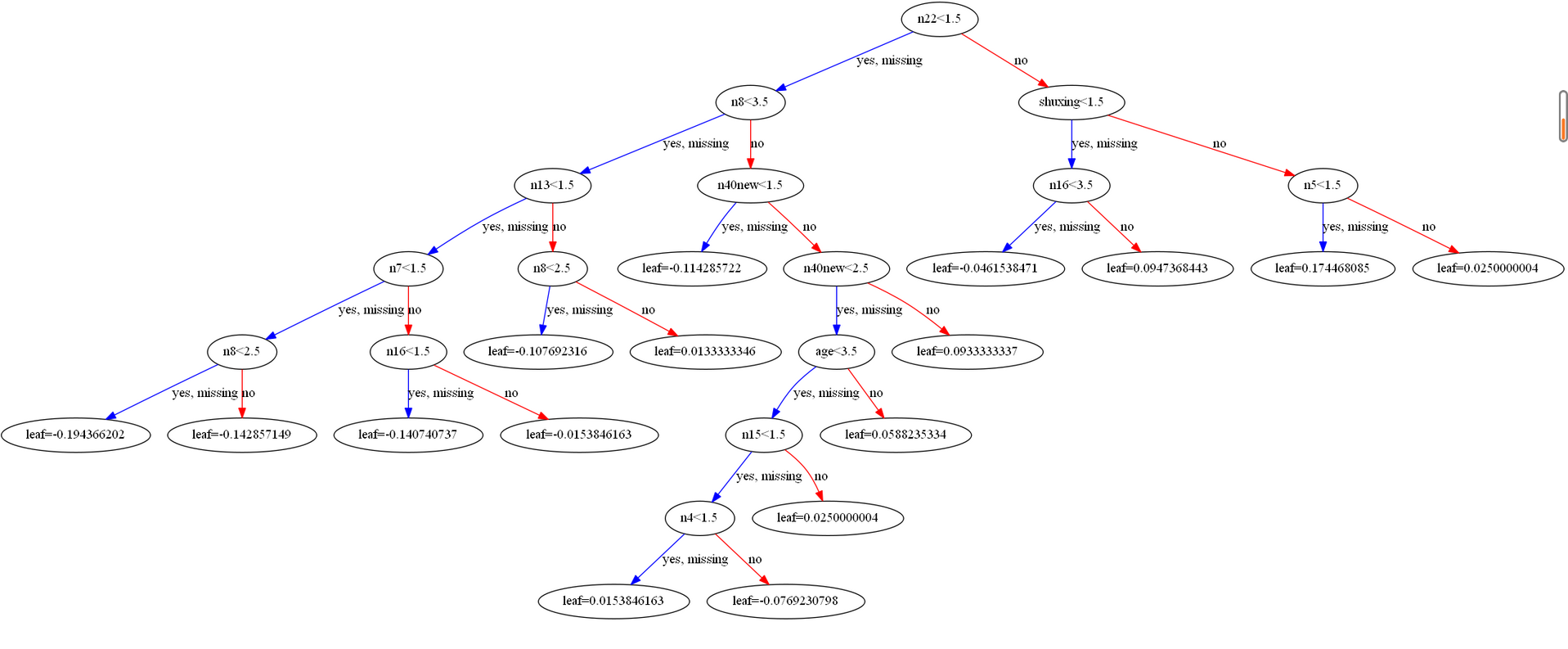 ?
?
這里繪制來一個樹的程序,其中leaf代表預測分數
ROC曲線AUC面積
# ROC曲線、AUC
from sklearn.metrics import precision_recall_curve
from sklearn import metrics
# 預測正例的概率
y_pred_prob=model.predict_proba(X_test)[:,1]
# y_pred_prob ,回傳兩列,第一列代表類別0,第二列代表類別1的概率
#https://blog.csdn.net/dream6104/article/details/89218239
fpr, tpr, thresholds = metrics.roc_curve(y_test,y_pred_prob, pos_label=2)
#pos_label,代表真陽性標簽,就是說是分類里面的好的標簽,這個要看你的特征目標標簽是0,1,還是1,2
roc_auc = metrics.auc(fpr, tpr) #auc為Roc曲線下的面積
# print(roc_auc)
plt.figure(figsize=(8,6))
plt.plot([0, 1], [0, 1], color='navy', lw=2, linestyle='--')
plt.plot(fpr, tpr, 'r',label='AUC = %0.2f'% roc_auc)
plt.legend(loc='lower right')
# plt.plot([0, 1], [0, 1], 'r--')
plt.xlim([0, 1.1])
plt.ylim([0, 1.1])
plt.xlabel('False Positive Rate') #橫坐標是fpr
plt.ylabel('True Positive Rate') #縱坐標是tpr
plt.title('Receiver operating characteristic example')
plt.show()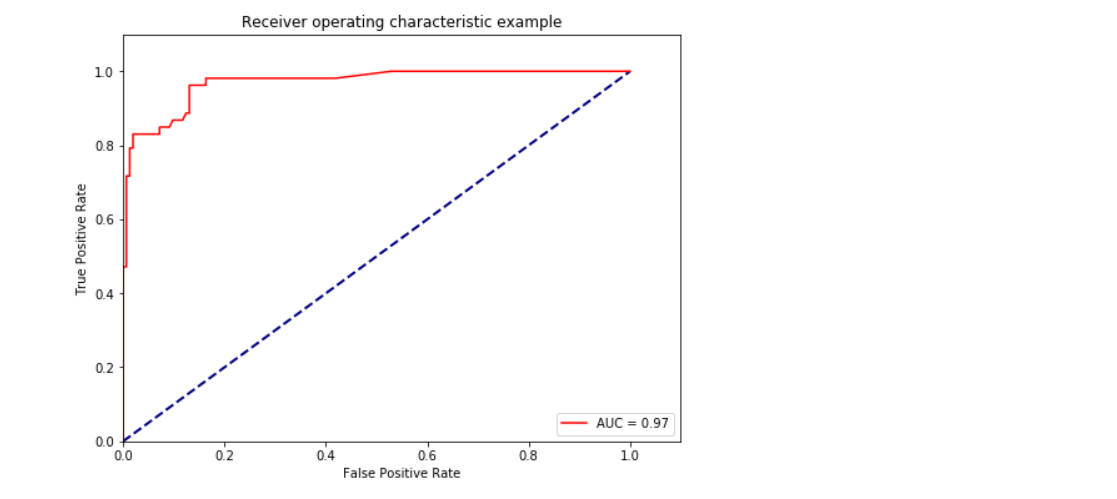 ?
?
在使用XGBoost的程序中,遇到了很多的引數調優問題,其次就是CPU不足,運行網格搜索的時候,最后有人推薦去使用lightGBM這種輕量級的,但是好像也有資料量的局限性,后期可以測驗一下效果,
資料的數量每天都在增加,對于傳統的資料科學演算法來說,很難快速的給出結果,LightGBM的前綴‘Light’表示速度很快,LightGBM可以處理大量的資料,運行時占用很少的記憶體,另外一個理由,LightGBM為什么這么受歡迎是因為它把重點放在結果的準確率上,LightGBM還支持GPU學習,因此,資料科學家廣泛的使用LightGBM來進行資料科學應用的部署,
不建議在小資料集上使用LightGBM,LightGBM對過擬合很敏感,對于小資料集非常容易過擬合,對于多小屬于小資料集,并沒有什么閾值,但是從我的經驗,我建議對于10000+以上的資料的時候,再使用LightGBM,
每文一語
忙碌也是一種充實的快樂!
轉載請註明出處,本文鏈接:https://www.uj5u.com/qita/423864.html
標籤:AI
上一篇:三種梯度下降方法與代碼實作