資料的底層存盤是檔案

hive的計算框架是mapreduce,mapreduce的原理:
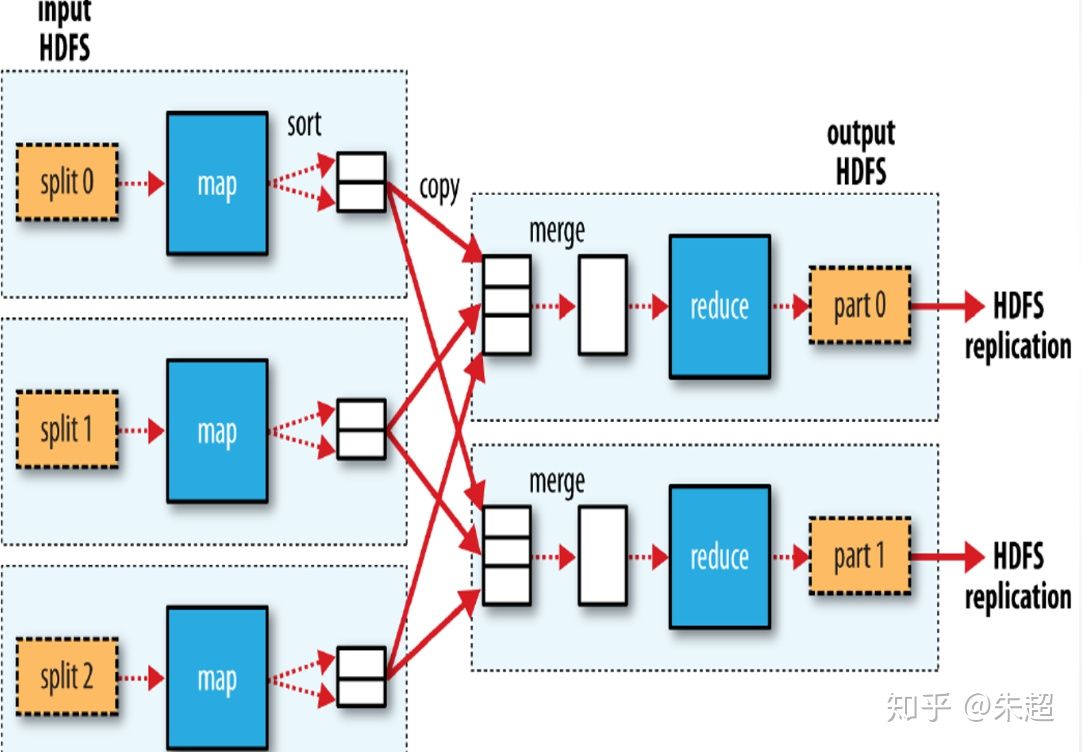
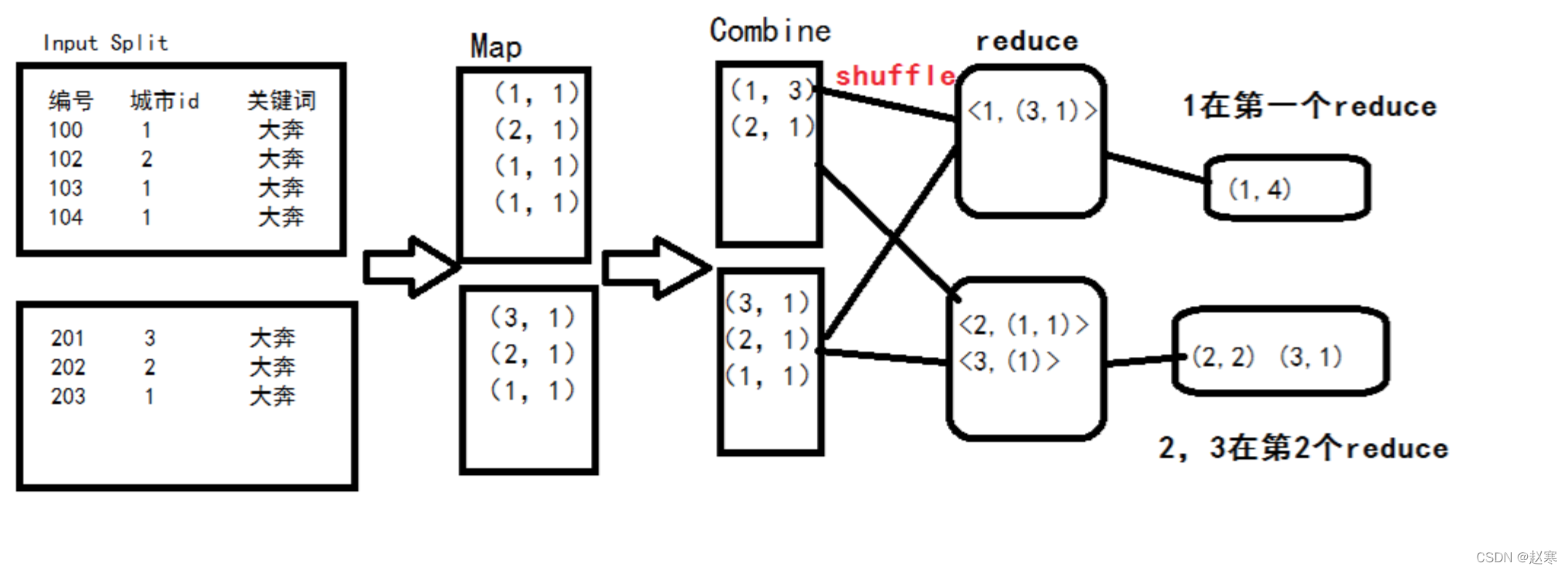
- 圖上是整個mapreduce的運行程序,在各自的分片中,都是把資料分割以后每個值都對應一個1得到<key,1>,再經過本地reduce(combine程序)把key一樣的value=1相加,得到新的<key,values>,再經過shuffle程序,把所有分片中的<key,values>,key一致的values相加,又得到最終的<key,values>,
- combiner其實是一個本地的reduce主要就是為了減輕reduce的負擔,但并不是所有的場景都會發生combiner,例如求平均數
- 不會發送combiner的操作主要體現在不帶 group by 的count(distinct) 這種操作,所有的資料都會分發的一個reduce上,資料產出極慢
轉載請註明出處,本文鏈接:https://www.uj5u.com/qita/423872.html
標籤:其他
上一篇:2022DeepbrainChain雙周報第104期(01.16-02.15)
下一篇:Hive函式大全