我有一個包含 2 列的 pandas 資料框:預測時間和實際時間。我想要包含真值或假值的第三列。換句話說,如果對于每個預測時間行,時間與同一行中的實際時間之一匹配,或者預測時間介于這些實際時間之一之間,則將“真”添加到第三列值。否則,在行中添加“False”。
任何想法從哪里開始?我假設這需要兩件事:用于比較和迭代每一行以產生新寫入的行值的日期時間模塊?
當前資料框:
;Predicted time;Actual times
0;[2017-09-09 06:53:37, 2017-09-09 06:53:46];[2017-09-09 06:54:11, 2017-09-09 06:54:21,] [2017-09-09 06:54:29, 2017-09-09 06:55:14], [2017-09-09 06:55:30, 2017-09-09 06:55:51]]
1;[2017-09-09 06:54:19, 2017-09-09 06:54:43];[2017-09-09 06:54:11, 2017-09-09 06:54:21, 2017-09-09 06:54:29, 2017-09-09 06:55:14, 2017-09-09 06:55:30, 2017-09-09 06:55:51]
2;[2017-09-09 06:54:44, 2017-09-09 06:54:48];[2017-09-09 06:54:11, 2017-09-09 06:54:21,] [2017-09-09 06:54:29, 2017-09-09 06:55:14], [2017-09-09 06:55:30, 2017-09-09 06:55:51]]
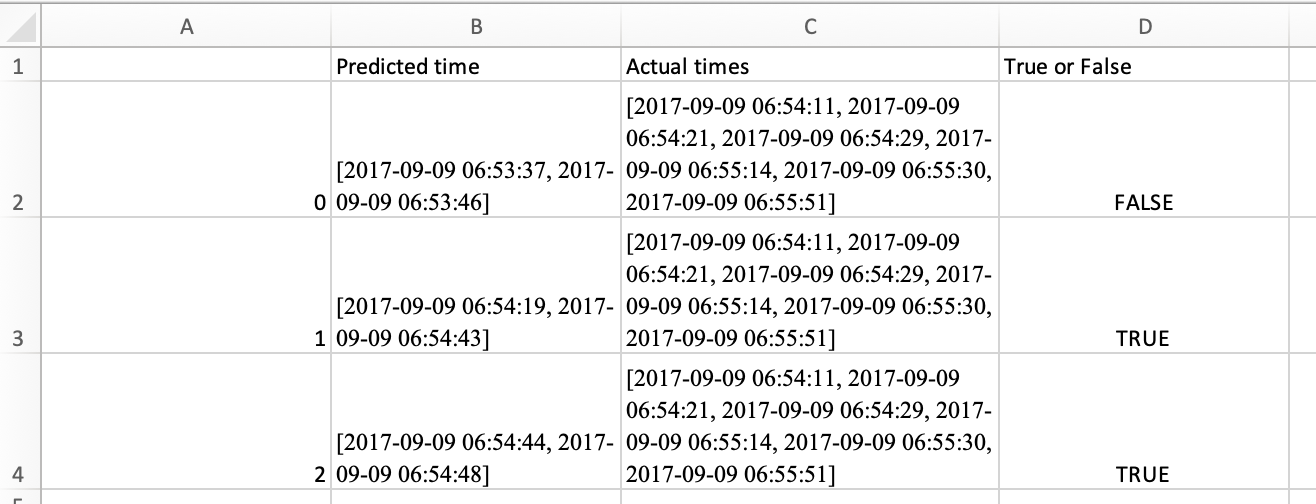
期望的輸出
;Predicted time;Actual times;True or False
0;[2017-09-09 06:53:37, 2017-09-09 06:53:46];[2017-09-09 06:54:11, 2017-09-09 06:54:21,] [2017-09-09 06:54:29, 2017-09-09 06:55:14], [2017-09-09 06:55:30, 2017-09-09 06:55:51]];FALSE
1;[2017-09-09 06:54:19, 2017-09-09 06:54:43];[2017-09-09 06:54:11, 2017-09-09 06:54:21, 2017-09-09 06:54:29, 2017-09-09 06:55:14, 2017-09-09 06:55:30, 2017-09-09 06:55:51];TRUE
2;[2017-09-09 06:54:44, 2017-09-09 06:54:48];[2017-09-09 06:54:11, 2017-09-09 06:54:21,] [2017-09-09 06:54:29, 2017-09-09 06:55:14], [2017-09-09 06:55:30, 2017-09-09 06:55:51]];TRUE
我還附上了一張圖片,以更清楚地顯示所需的輸出。
uj5u.com熱心網友回復:
下面函式中的大部分作業是將資料框中的字串轉換為datetime可用于比較的物件集合 -
def pred_intersects_act(row):
#Convert predicted times to list of datetime objects
predicted_time = re.sub(r'\[|\]', '', row['predicted_time'])
predicted_time = re.sub(r',\ *', ',', predicted_time)
pt_list = predicted_time.split(',')
pt_list = [dt.strptime(_, '%Y-%m-%d %H:%M:%S') for _ in pt_list]
#Convert actual times to list of datetime objects
actual_times = re.sub(r'\[|\]', '', row['actual_times'])
actual_times = re.sub(r',\ *', ',', actual_times)
at_list = actual_times.split(',')
at_list = [dt.strptime(_, '%Y-%m-%d %H:%M:%S') for _ in at_list]
#pair up actual times and check for intersection
for pair in zip(at_list[:-1], at_list[1:]):
exact_match = any(_ in pair for _ in pt_list)
approx_match = any(bisect.bisect(pair, _) == 1 for _ in pt_list)
if exact_match or approx_match:
return True
return False
df.apply(pred_intersects_act, axis=1)
0 False
1 True
2 True
dtype: bool
uj5u.com熱心網友回復:
使用串列推導與測驗值之間any的測驗至少一個True:
#for converting to datetimes, in Actual times was removed nested lists
f = lambda x: pd.to_datetime(x.strip('[]').split(', ')).tolist()
df[['Actual times', 'Predicted time']] = df[['Actual times', 'Predicted time']].applymap(f)
df['True or False'] = [any((s < y) & (e > y) for y in x)
for (s, e), x in zip(df['Predicted time'], df['Actual times'])]
print (df)
Predicted time \
0 [2017-09-09 06:53:37, 2017-09-09 06:53:46]
1 [2017-09-09 06:54:19, 2017-09-09 06:54:43]
2 [2017-09-09 06:54:44, 2017-09-09 06:54:48]
Actual times True or False
0 [2017-09-09 06:54:11, 2017-09-09 06:54:21, 201... False
1 [2017-09-09 06:54:11, 2017-09-09 06:54:21, 201... True
2 [2017-09-09 06:54:11, 2017-09-09 06:54:21, 201... False
轉載請註明出處,本文鏈接:https://www.uj5u.com/qita/424461.html
上一篇:python定義從API檢索資料然后放入資料框的函式
下一篇:鏈表實作出錯