我在 SQL Server 2019 中有數百萬條記錄的表中有四列(Col1、Col2、Col3、Col4)。
在存盤程序中,我必須傳遞四個輸入引數@Col1、@Col2、@Col3、@Col4,它應該回傳成功/失敗是否找到所有四個值,而與列順序無關。例如@Col1 可以與 Col2 匹配。
Col2、Col3、Col4 中的某些值可以為 null,但 Col1 中總會有一些資料。
我準備了一些我測驗過的樣本資料和場景。
CREATE TABLE SampleData(Id INT IDENTITY(1,1), Col1 VARCHAR(20), Col2 VARCHAR(20), Col3 VARCHAR(20), Col4 VARCHAR(20))
INSERT INTO SampleData(Col1, Col2, Col3, Col4)
SELECT 'ABC','DEF','GHI','JKL' UNION
SELECT '123','456','789','100' UNION
SELECT 'ABC','XYZ','','' UNION
SELECT '9898','6565',NULL,NULL UNION
SELECT '989844','D656555','','' UNION
SELECT '8888','9999','7777','6666' UNION
SELECT '1234','5678','4321',NULL UNION
SELECT '465456465',NULL,NULL,NULL
存盤程序
CREATE PROC dbo.ValidateSampleData(
@Col1 VARCHAR(20) = NULL
,@Col2 VARCHAR(20) = NULL
,@Col3 VARCHAR(20) = NULL
,@Col4 VARCHAR(20) = NULL
)
AS
BEGIN
Declare @a as bit = 0, @Message VARCHAR(50) = 'Data Not Matched'
if(@Col1 is NULL or @Col2 is NULL or @Col3 is NULL or @Col4 is NULL )
begin
set @a = 1
end
SELECT @Message = 'Data Matched '
FROM SampleData SD
where (Col1 in (@Col1,@Col2,@Col3,@Col4) or (Col1 is null and @a = 1))
and (Col2 in (@Col1,@Col2,@Col3,@Col4) or (Col2 is null and @a = 1))
and (Col3 in (@Col1,@Col2,@Col3,@Col4) or (Col3 is null and @a = 1))
and (Col4 in (@Col1,@Col2,@Col3,@Col4) or (Col4 is null and @a = 1))
and (select sum( (case when Col1 is null then 1 else 0 end)
(case when Col2 is null then 1 else 0 end)
(case when Col3 is null then 1 else 0 end)
(case when Col4 is null then 1 else 0 end)
) from SampleData where Id = SD.Id) =
(select sum( (case when @Col1 is null then 1 else 0 end)
(case when @Col2 is null then 1 else 0 end)
(case when @Col3 is null then 1 else 0 end)
(case when @Col4 is null then 1 else 0 end)))
SELECT @Message
END
這是我嘗試過的一些樣本資料集
DECLARE
@Col1 VARCHAR(20) = NULL
,@Col2 VARCHAR(20) = NULL
,@Col3 VARCHAR(20) = NULL
,@Col4 VARCHAR(20) = NULL
--Case 0 - Should not matched
SELECT @Col1 = 'ABC', @Col2 = 'XYZ' , @Col3 = 'testtest' , @Col4 = ''
EXEC ValidateSampleData @Col1=@Col1, @Col2=@Col2, @Col3=@Col3, @Col4=@Col4
--Case 1
SELECT @Col1 = 'ABC', @Col2 = 'DEF' , @Col3 = 'GHI' , @Col4 = 'JKL'
EXEC ValidateSampleData @Col1=@Col1, @Col2=@Col2, @Col3=@Col3, @Col4=@Col4
--Case 2
SELECT @Col1 = 'DEF', @Col2 = 'JKL' , @Col3 = 'ABC' , @Col4 = 'GHI'
EXEC ValidateSampleData @Col1=@Col1, @Col2=@Col2, @Col3=@Col3, @Col4=@Col4
--Case 3
SELECT @Col1 = '123', @Col2 = '456' , @Col3 = '789' , @Col4 = '100'
EXEC ValidateSampleData @Col1=@Col1, @Col2=@Col2, @Col3=@Col3, @Col4=@Col4
--Case 4
SELECT @Col1 = '1234', @Col2 = '5678' , @Col3 = '4321' , @Col4 = NULL
EXEC ValidateSampleData @Col1=@Col1, @Col2=@Col2, @Col3=@Col3, @Col4=@Col4
--Case 5
SELECT @Col1 = '465456465', @Col2 = NULL , @Col3 = NULL , @Col4 = NULL
EXEC ValidateSampleData @Col1=@Col1, @Col2=@Col2, @Col3=@Col3, @Col4=@Col4
--Case 6
SELECT @Col1 = '8888', @Col2 = '9999' , @Col3 = '7777' , @Col4 = '6666'
EXEC ValidateSampleData @Col1=@Col1, @Col2=@Col2, @Col3=@Col3, @Col4=@Col4
--Case 7
SELECT @Col1 = '9898', @Col2 = '6565' , @Col3 = NULL , @Col4 = NULL
EXEC ValidateSampleData @Col1=@Col1, @Col2=@Col2, @Col3=@Col3, @Col4=@Col4
--Case 8
SELECT @Col1 = '989844', @Col2 = 'D656555' , @Col3 = '' , @Col4 = ''
EXEC ValidateSampleData @Col1=@Col1, @Col2=@Col2, @Col3=@Col3, @Col4=@Col4
--Case 9
SELECT @Col1 = 'ABC', @Col2 = 'XYZ' , @Col3 = '' , @Col4 = ''
EXEC ValidateSampleData @Col1=@Col1, @Col2=@Col2, @Col3=@Col3, @Col4=@Col4
--Case 10 - Should not matched
SELECT @Col1 = 'ABC', @Col2 = 'XYZ' , @Col3 = 'tet' , @Col4 = ''
EXEC ValidateSampleData @Col1=@Col1, @Col2=@Col2, @Col3=@Col3, @Col4=@Col4
在某些情況下,我已經達到了預期的結果,但它與表中的 NULL 值不正確。案例 0 不應匹配
此外,它在大量資料上看起來沒有優化并且非常慢。
In simple words, I want to check if all 4 values appear in the table, with NULL matching NULL? If they do, return a match, if not, a non match?
uj5u.com熱心網友回復:
我的方法是首先創建一個包含 4 個值的所有可能組合的表。這可以通過創建一個有 4 行的派生表來完成,然后將其連接到自身 4 次,每次連接確保您沒有選擇已經選擇的行,即
DECLARE @Values TABLE
(
Col1 VARCHAR(20),
Col2 VARCHAR(20),
Col3 VARCHAR(20),
Col4 VARCHAR(20)
UNIQUE (Col1, Col2, Col3, Col4)
);
WITH Data AS
( SELECT Value, v.Ordinal
FROM (VALUES (1, @Col1), (2, @Col2), (3, @Col3), (4, @Col4)) AS v (Ordinal, Value)
)
INSERT @Values(Col1, Col2, Col3, Col4)
SELECT DISTINCT d1.Value, d2.Value, d3.Value, d4.Value
FROM Data AS d1
INNER JOIN Data AS d2
ON d2.Ordinal NOT IN (d1.Ordinal)
INNER JOIN Data AS d3
ON d3.Ordinal NOT IN (d1.Ordinal, d2.Ordinal)
INNER JOIN Data AS d4
ON d4.Ordinal NOT IN (d1.Ordinal, D2.Ordinal, d3.Ordinal);
有一個非常簡單的例子 where @Col1= 'A', and all others areNULL你最終會得到類似的東西:
| Col1 | Col2 | Col3 | Col4 |
|---|---|---|---|
| 空值 | 空值 | 空值 | 一個 |
| 空值 | 空值 | 一個 | 空值 |
| 空值 | 一個 | 空值 | 空值 |
| 一個 | 空值 | 空值 | 空值 |
然后,您可以使用INTERSECT來檢查您的表。INTERSECT這樣做的好處是NULL匹配,即SELECT NULL INTERSECT SELECT NULL會回傳一條記錄,而SELECT NULL WHERE NULL = NULL不會。
IF EXISTS
( SELECT Col1, Col2, Col3, Col4
FROM SampleData
INTERSECT
SELECT Col1, Col2, Col3, Col4
FROM @Values
)
BEGIN
SELECT 'Data Matched';
END
ELSE
BEGIN
SELECT 'Data not Matched';
END
此方法的主要優點(除了回傳您的預期結果)是它可以利用 SampleData 上的索引,所以如果您添加:
CREATE INDEX IX_SampleData ON dbo.SampleData (Col1, Col2, Col3, Col4);
然后這將在使用時使用INTERSECT,但不符合您的邏輯:
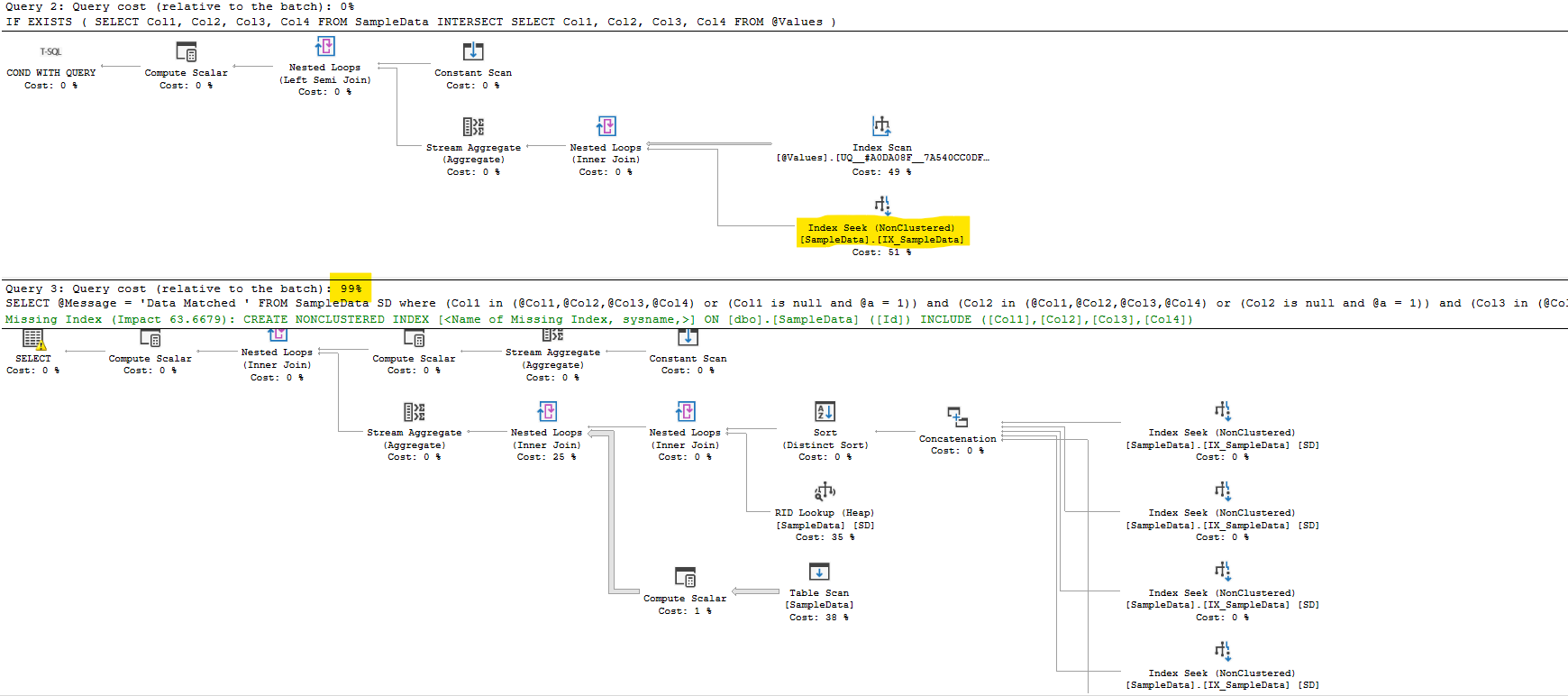
就目前的小資料集而言,這并沒有太大的區別,但是對于更大的資料集,它會起作用。以上是 SampleData 中的 200k 行。
因此,您的完整程式將類似于:
CREATE OR ALTER PROC dbo.ValidateSampleData(
@Col1 VARCHAR(20) = NULL
,@Col2 VARCHAR(20) = NULL
,@Col3 VARCHAR(20) = NULL
,@Col4 VARCHAR(20) = NULL
)
AS
BEGIN
DECLARE @Values TABLE
(
Col1 VARCHAR(20),
Col2 VARCHAR(20),
Col3 VARCHAR(20),
Col4 VARCHAR(20)
UNIQUE (Col1, Col2, Col3, Col4)
);
WITH Data AS
( SELECT Value, v.Ordinal
FROM (VALUES (1, @Col1), (2, @Col2), (3, @Col3), (4, @Col4)) AS v (Ordinal, Value)
)
INSERT @Values(Col1, Col2, Col3, Col4)
SELECT DISTINCT d1.Value, d2.Value, d3.Value, d4.Value
FROM Data AS d1
INNER JOIN Data AS d2
ON d2.Ordinal NOT IN (d1.Ordinal)
INNER JOIN Data AS d3
ON d3.Ordinal NOT IN (d1.Ordinal, d2.Ordinal)
INNER JOIN Data AS d4
ON d4.Ordinal NOT IN (d1.Ordinal, D2.Ordinal, d3.Ordinal);
IF EXISTS
( SELECT Col1, Col2, Col3, Col4
FROM SampleData
INTERSECT
SELECT Col1, Col2, Col3, Col4
FROM @Values
)
BEGIN
SELECT 'Data Matched';
END
ELSE
BEGIN
SELECT 'Data not Matched';
END
END
加號
To answer the question in the comment:
I got this warning while creating Index on actual table. Can you explain ? Warning! The maximum key length for a nonclustered index is 1700 bytes.
The index 'IX_SampleData' has maximum length of 2000 bytes. For some combination of large values, the insert/update operation will fail.
Presumably your actual columns are larger than specified in the question (VARCHAR(20))? As the warning says, the maximum key length is 1700bytes., so the required storage for all 4 columns must be less than that. Each VARCHAR character requires one byte of storage, so the maximum for VARCHAR(20) is 20 bytes, for 4 columns your maximum is 80 bytes. If however your columns are VARCHAR(500) then your maximum size is 2000 bytes. Since VARCHAR is variable, each value will only take as much space as needed. So if you enter A into a column defined as VARCHAR(500) it will still only take ` byte.
Assuming that your columns are VARCHAR(500) and you try and add the following:
INSERT INTO SampleData(Col1, Col2, Col3, Col4)
SELECT REPLICATE('A', 500), REPLICATE('B', 500), REPLICATE('C', 500), REPLICATE('D', 500)
In summary, if you are going to use all 500 characters in all 4 columns, then your insert will fail. If you have been very liberal with your column length, and the total length in all 4 columns is always going to be less than 1700 characters, then you will be fine (although, if you have been liberal with your column length, then perhaps resize them accordingly - although there is no cost in terms of additional storage there are other costs with defining columns larger than you need, so best to be as accurate as possible with column lengths).
uj5u.com熱心網友回復:
一種解決方案是將四列拆分為行,對它們進行排序和編號;對四個值執行相同的操作。然后,您可以比較這兩組:
with cols as (
select id, value, row_number() over (partition by id order by value) as rn
from t
cross apply (values (col1), (col2), (col3), (col4) ) as x(value)
), vals as (
select value, row_number() over (order by value) as rn
from (values (@col1), (@col2), (@col3), (@col4) ) as x(value)
)
select id
from cols
join vals on cols.rn = vals.rn and (cols.value = vals.value or cols.value is null and vals.value is null)
group by id
having count(*) = 4
DB<>小提琴
轉載請註明出處,本文鏈接:https://www.uj5u.com/qita/425848.html
標籤:sql sql-server tsql stored-procedures null