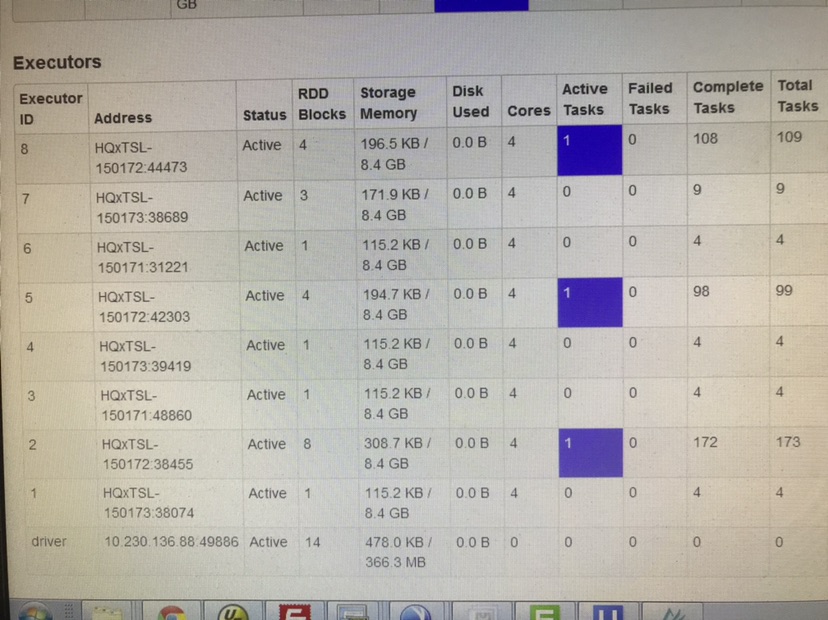
代碼是spark.sql("insert into.......select... ")結構,執行jar包后發現任務很慢,資源分的不小,后來看了下執行情況,發現任務分配有些問題,除錯了下還是不行,請大神指點一二
uj5u.com熱心網友回復:
求大神啊!!!!uj5u.com熱心網友回復:
干嘛一定插入到hive,spark sql執行完成后將結果保留到hadoop環境;hive 通過外部表的形式鏈接過去就可以了吧
uj5u.com熱心網友回復:
注冊成臨時表的那個DataFrame重磁區,減少磁區數量,這樣hive表中的檔案資料就是磁區的資料量,沒有那么多小檔案應該就快了uj5u.com熱心網友回復:
批量插入,減小碎片轉載請註明出處,本文鏈接:https://www.uj5u.com/qita/42618.html
標籤:Spark