我撰寫了一個網頁抓取程式,該程式會進入像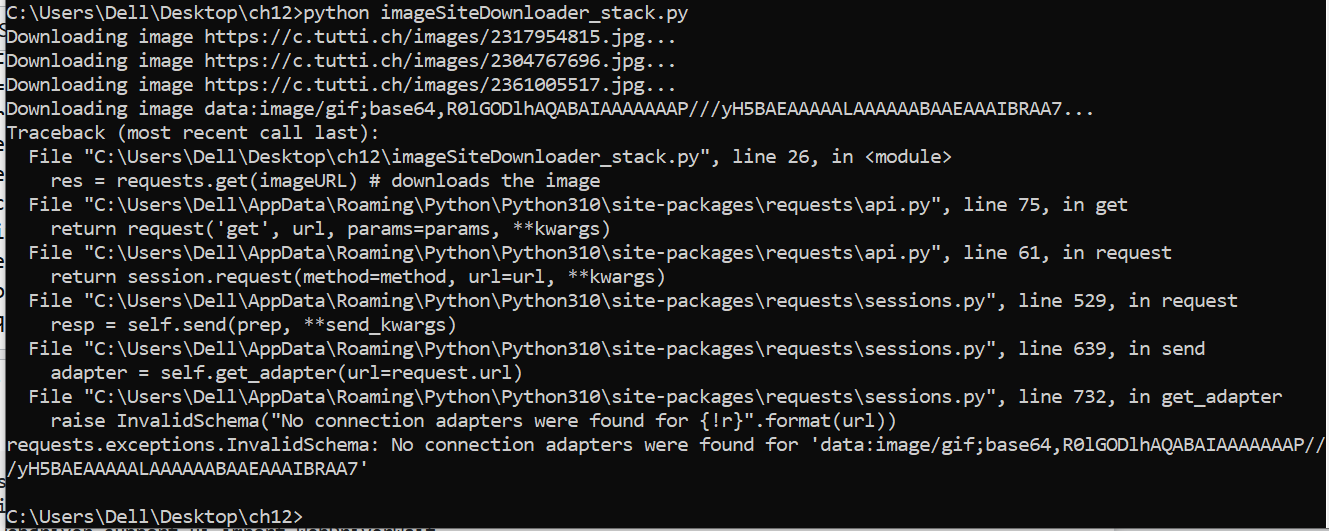
該程式正確下載了前幾張照片,但隨后突然崩潰。
在stackoverflow上尋找解決方案,我發現了這篇文章:請求:沒有找到連接配接器,Python3中的錯誤
上面帖子的答案表明問題是由于 URL 中的換行符引起的。
我檢查了無法下載的 HTML 代碼中的照片的源 URL。他們似乎沒事。
The problem seems to be either the browser.find_elements() method which parses the 'src' attribute values incorrectly or the .get_attribute() method which cannot fetch some of the URLs correctly. Instead of getting something like
https://c.tutti.ch/images/23452346536.jpg
the method gives back strings like
data:image/gif;base64,R0lGODlhAQABAIAAAAAAAP///yH5BAEAAAAALAAAAAABAAEAAAIBRAA7
Of course, this is not a valid URL which the requests.get() method can use to download the image. I did some research and I have found out that this might be a base64 string...
Why does the .get_attribute() method return a base64 string in some of the cases? Can I prevent it to do so? Or do I have to convert it to a normal string?
Update: Another approach using beautifulsoup for parsing instead ob WebDriver. (This code is not working yet. The Data URLs are still a problem)
import requests, sys, os, bs4
from selenium import webdriver
from selenium.webdriver.support.ui import WebDriverWait
from selenium.webdriver.common.by import By
from selenium.webdriver.support import expected_conditions as EC
browser = webdriver.Firefox() # Opens Firefox webbrowser
browser.get('https://www.tutti.ch/') # Go to tutti.ch website
wait = WebDriverWait(browser, 10)
wait.until(EC.element_to_be_clickable((By.CSS_SELECTOR, "#onetrust-accept-btn-handler"))).click()
wait.until(EC.presence_of_element_located((By.CSS_SELECTOR, "._1CFCt > input:nth-child(1)"))).send_keys(sys.argv[1:])
wait.until(EC.element_to_be_clickable((By.CSS_SELECTOR, "button[id*='1-val-searchLabel']"))).click() # https://www.tutorialspoint.com/how-to-locate-element-by-partial-id-match-in-selenium
os.makedirs('tuttiBilder', exist_ok=True)
url = browser.current_url
print('Downloading page %s...' % url)
res = requests.get(url)
res.raise_for_status()
soup = bs4.BeautifulSoup(res.text, 'html.parser')
#Check for errors from here
images = soup.select('div[style] > img')
for im in images:
imageURL = im.get('src') # get the URL of the image
print('Downloading image %s...' % (imageURL))
res = requests.get(imageURL) # downloads the image
res.raise_for_status()
imageFile = open(os.path.join('tuttiBilder', os.path.basename(imageURL)), 'wb') # creates an image file
for chunk in res.iter_content(100000): # writes to the image file
imageFile.write(chunk)
imageFile.close()
print('Done.')
browser.quit()
uj5u.com熱心網友回復:
當您嘗試使用 base64 編碼字串(不是有效的影像 URL)下載檔案(影像)時,程式崩潰。這些 base64 字串出現在您的影像串列中的原因是每個影像(在<img>標簽中)最初似乎是一個 base64 字串,一旦加載,src值就會更改為有效的影像 url(您可以通過打開 DevTools 來檢查在您的瀏覽器中訪問您的網站時https://...ganze-schweiz?q=Gartenstuhl,并在 DevTools 的 Elements 部分中搜索“base64”。通過移動到搜索結果中的下一個影像 - 使用箭頭按鈕 - 您會注意到上述行為)。這也是僅找到并下載 3 到 5 個影像的原因(如您的 cmd 視窗片段所示,并且我自己也對其進行了測驗)。那是因為這 5 張圖片是出現在頁面頂部的圖片,并且在訪問頁面時成功加載并提供了有效的圖片 URL;而其余的<img>標簽仍然包含一個 base64 字串。
因此,第一步是 - 一旦“搜索結果”操作完成 - 慢慢向下滾動頁面,以便加載頁面中的每個影像并提供有效的 URL。您可以使用此處描述的方法來實作。您可以根據需要調整速度,只要它允許專案/影像正確加載。
第二步是確保只有有效的 URL 被傳遞給requests.get()方法。盡管由于上述修復,每個 base64 字串都將被一個有效的 URL 替換,但串列中可能仍然存在無效的影像 URL;事實上,似乎有一個(與專案無關)以 . 開頭https://bat.bing.com/action/0?t....。因此,謹慎的做法是在嘗試下載請求的 URL 之前檢查它們是否是有效的影像 URL。您可以通過使用str.endswith()方法來做到這一點,查找以特定(擴展名)結尾的字串suffixes,例如".png"和".jpg". 如果影像串列中的字串確實以上述任何擴展名結尾,則您可以繼續下載影像。下面給出了作業示例(請注意,下面將下載出現在搜索結果第一頁中的影像。如果您需要下載更多影像結果,您可以擴展程式以導航到下一頁,然后重復與以下)。
更新 1
下面的代碼已經更新,因此可以通過導航到以下頁面并下載影像來獲得進一步的結果。next_pages_no您可以通過調整變數來設定希望從中獲得結果的“下一頁”的數量。
import requests, os
from selenium import webdriver
from selenium.webdriver.support.ui import WebDriverWait
from selenium.webdriver.common.by import By
from selenium.webdriver.support import expected_conditions as EC
suffixes = (".png", ".jpg")
next_pages_no = 3
browser = webdriver.Firefox() # Opens Firefox webbrowser
#browser = webdriver.Chrome() # Opens Chrome webbrowser
wait = WebDriverWait(browser, 10)
os.makedirs('tuttiBilder', exist_ok=True)
def scroll_down_page(speed=40):
current_scroll_position, new_height= 0, 1
while current_scroll_position <= new_height:
current_scroll_position = speed
browser.execute_script("window.scrollTo(0, {});".format(current_scroll_position))
new_height = browser.execute_script("return document.body.scrollHeight")
def save_images(images):
for im in images:
imageURL = im.get_attribute('src') # get the URL of the image
if imageURL.endswith(suffixes):
print('Downloading image %s...' % (imageURL))
res = requests.get(imageURL) # downloads the image
res.raise_for_status()
imageFile = open(os.path.join('tuttiBilder', os.path.basename(imageURL)), 'wb') # creates an image file
for chunk in res.iter_content(100000): # writes to the image file
imageFile.write(chunk)
imageFile.close()
def get_first_page_results():
browser.get('https://www.tutti.ch/')
wait.until(EC.element_to_be_clickable((By.CSS_SELECTOR, "#onetrust-accept-btn-handler"))).click() # accepts cookies terms
wait.until(EC.presence_of_element_located((By.CSS_SELECTOR, "._1CFCt > input:nth-child(1)"))).send_keys('Gartenstuhl') # enters search key word
wait.until(EC.element_to_be_clickable((By.CSS_SELECTOR, "button[id*='1-val-searchLabel']"))).click() # clicks submit button
scroll_down_page() # scroll down the page slowly for the images to load
images = browser.find_elements(By.TAG_NAME, 'img') # stores every img element in a list
save_images(images)
def get_next_page_results():
wait.until(EC.visibility_of_element_located((By.XPATH, '//button//*[name()="svg"][@data-testid="NavigateNextIcon"]'))).click()
scroll_down_page() # scroll down the page slowly for the images to load
images = browser.find_elements(By.TAG_NAME, 'img') # stores every img element in a list
save_images(images)
get_first_page_results()
for _ in range(next_pages_no):
get_next_page_results()
print('Done.')
browser.quit()
更新 2
As per your request, here is an alternative approach to the problem, using Python requests to download the HTML content of a given URL, as well as BeautifulSoup library to parse the content, in order to get the image URLs. As it appears in the HTML content, both base64 strings and actual image URLs are included (base64 strings occur exactly in the same number as image URLs). Thus, you can use the same approach as above to check for their suffixes, before proceeding downloading them. Complete working example below (adjust the page range in the for loop as you wish).
import requests
from bs4 import BeautifulSoup as bs
import os
suffixes = (".png", ".jpg")
os.makedirs('tuttiBilder', exist_ok=True)
def save_images(imageURLS):
for imageURL in imageURLS:
if imageURL.endswith(suffixes):
print('Downloading image %s...' % (imageURL))
res = requests.get(imageURL) # downloads the image
res.raise_for_status()
imageFile = open(os.path.join('tuttiBilder', os.path.basename(imageURL)), 'wb') # creates an image file
for chunk in res.iter_content(100000): # writes to the image file
imageFile.write(chunk)
imageFile.close()
def get_results(page_no, search_term):
response = requests.get('https://www.tutti.ch/de/li/ganze-schweiz?o=' str(page_no) '&q=' search_term)
soup = bs(response.content, 'html.parser')
images = soup.findAll("img")
imageURLS = [image['src'] for image in images]
save_images(imageURLS)
for i in range(1, 4): # get results from page 1 to page 3
get_results(i, "Gartenstuhl")
Update 3
To clear things up, the base64 strings are all the same i.e., R0lGODlhAQABAIAAAAAAAP///yH5BAEAAAAALAAAAAABAAEAAAIBRAA7. You can check this by saving the received HTML content in a file (to do this, please add the code below in the get_results() method of the second solution), opening it with a text editor and searching for "base64".
with open("page.html", 'wb') as f:
f.write(response.content)
If you enter the above base64 string into a "base64-to-image" converter online, then download and open the image with a graphics editor (such as Paint), you will see that it is a 1px image (usually called a "tracking pixel"). This "tracking pixel" is used in Web beacon technique to check that a user has accessed some content - in your case, a product in the list.
The base64 string is not an invalid URL that somehow turns into a valid one. It is an encoded image string, which can be decoded to recover the image. Thus, in the first solution using Selenium, when scrolling down on the page, those base64 strings are not converted into valid image URLs, but rather, tell the website that you have accessed some content, and then the website removes/hides them; that is the reason they do not show up in the results. The images (and hence, the image URLs) appear as soon as you scroll down to a product, as a common technique, called "Image Lazy Loading" is used (which is used to improve performance, user experience, etc.). Lazy-loading instructs the browser to defer loading of images that are off-screen until the user scrolls near them. In the second solution, since requests.get() is used to retrieve the HTML content, the base64 strings are still in the HTML document; one per each product. Again, those base64 strings are all the same, and are 1px images used for the purpose mentioned earlier. So, you don't need them in your results and should be ignored. Both solutions above download all the product images present in the webpage. You can check that by looking into the tuttiBilder folder, after running the programs. If you still, however, want to save those base64 images (which is worthless, as they are all the same and not useful), replace the save_images()第二種解決方案中的方法(即使用BeautifulSoup)與下面的方法。確保匯入額外的庫(如下所示)。下面會將所有 base64 影像以及產品影像保存在同一tuttiBilder檔案夾中,并為它們分配唯一識別符號作為檔案名(因為它們不帶有檔案名)。
import re
import base64
import uuid
def save_images(imageURLS):
for imageURL in imageURLS:
if imageURL.endswith(suffixes):
print('Downloading image %s...' % (imageURL))
res = requests.get(imageURL) # downloads the image
res.raise_for_status()
imageFile = open(os.path.join('tuttiBilder', os.path.basename(imageURL)), 'wb') # creates an image file
for chunk in res.iter_content(100000): # writes to the image file
imageFile.write(chunk)
imageFile.close()
elif imageURL.startswith("data:image/"):
base64string = re.sub(r"^.*?/.*?,", "", imageURL)
image_as_bytes = str.encode(base64string) # convert string to bytes
recovered_img = base64.b64decode(image_as_bytes) # decode base64string
filename = os.path.join('tuttiBilder', str(uuid.uuid4()) ".png")
with open(filename, "wb") as f:
f.write(recovered_img)
uj5u.com熱心網友回復:
這不是任何型別的 URL。實際的影像資料存盤在那里,因此它是 base 64 編碼的。嘗試將其復制到瀏覽器中(從 data: 部分開始),您將看到影像。
剛剛發生的事情是影像不是托管在單獨的 URL 上,而是嵌入到網站中,您的瀏覽器僅解碼該資料以呈現影像。如果你想獲取原始影像資料,base64decode all after ;base64,part。
uj5u.com熱心網友回復:
我可以建議不要使用 Selenium,有一個后端 api 為每個頁面提供資料。唯一棘手的是,對 api 的請求需要具有特定的 uuid 哈希值,該哈希值位于登錄頁面的 HTML 中。因此,當您轉到登錄頁面時,您可以得到它,然后使用它來簽署您后續的 api 呼叫,這是一個示例,它將遍歷每個帖子的頁面和影像:
import requests
import re
import os
search = 'Gartenstuhl'
headers = {'user-agent':'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/96.0.4664.110 Safari/537.36'}
url = f'https://www.tutti.ch/de/li/ganze-schweiz?q={search}'
step = requests.get(url,headers=headers)
print(step)
uuids = re.findall( r'[a-fA-F0-9]{8}-[a-fA-F0-9]{4}-[a-fA-F0-9]{4}-[a-fA-F0-9]{4}-[a-fA-F0-9]{12}',step.text)
print(f'tutti hash code: {uuids[0]}') #used to sign requests to api
os.makedirs('tuttiBilder', exist_ok=True)
for page in range(1,10):
api = f'https://www.tutti.ch/api/v10/list.json?aggregated={page}&limit=30&o=1&q={search}&with_all_regions=true'
new_headers = {
'user-agent':'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/97.0.4692.99 Safari/537.36',
'x-tutti-hash':uuids[0],
'x-tutti-source':'web latest-staging'
}
resp = requests.get(api,headers=new_headers).json()
for item in resp['items']:
for image in item['image_names']:
image_url = 'https://c.tutti.ch/images/' image
pic = requests.get(image_url)
with open(os.path.join('tuttiBilder', os.path.basename(image)),'wb') as f:
f.write(pic.content)
print(f'Saved: {image}')
轉載請註明出處,本文鏈接:https://www.uj5u.com/qita/426258.html
標籤:python selenium-webdriver web-scraping exception python-requests