目錄
- 復雜度介紹
- 復雜度
- 時間復雜度
- 大O表示法
- 大O的法則
- 獲取最大量級復雜度(一段代碼)
- 加法法則(只有一種資料規模)
- 加法法則(兩種或者多種資料規模)
- 乘法法則
- 常見的復雜度量級
- 多項式階
- 非多項式階
- 幾種量級的復雜度執行效率圖
- 空間復雜度
- 最好情況時間復雜度
- 最壞時間復雜度
- 平均時間復雜度
- 最好,最壞,平均時間復雜度應用場景
- 均攤時間復雜度(攤還分析)
- 應用場景
- 學習資料結構與演算法的目的
- 參考資料
復雜度介紹
在正式學習資料結構與演算法之前,我們需要知道一個概念復雜度(時間復雜度和空間復雜度),它是干啥的? 它是學習資料結構與演算法的基礎,掌握了它就掌握了一半的資料結構與演算法.
我們在平常開發或者代碼review,程式壓測,都需要進行評測代碼執行效率和占用空間的大小.
以往我們在這方面的作業是,采用的是通過生產環境/預生產環境,進行程式壓測,得到壓測結果(包含代碼執行時間和占用空間),用來評測該程式是否能在極端情況下正常運行.
這種測驗方法叫做事后統計法,即根據硬體,網路設備,資料庫,運行的程式環境等軟硬體得到的壓測結果.
這種測驗方法的優點是:上手簡單快速,易出結果.但是缺點也很明顯,就是受制于軟硬體,運行的程式環境的影響很大.不同的軟硬體,程式運行環境所得到的壓測結果也不同,也比較耗時財力
所以,為了能夠得到一個較為準確的程式執行效率和占用空間的結果,我們引入了復雜度這一概念.
復雜度描述的是演算法執行時間(或占用空間)與資料規模的增長關系,
復雜度
時間復雜度
就是指代碼執行的效率問題,如以下代碼
int cal(int n) {
int sum = 0;
int i = 1;
for (; i <= n; ++i) {
sum = sum + i;
}
return sum;
}
當前代碼的第2,3行,都會執行一次,這個執行一次的時間叫做unit_time,第4,5行是個回圈,它會回圈n次,即執行的就是2nunit_time,那么該程式執行的時間效率為(時間復雜度):T(n) = (2nunit_time)+(2*unit_time).
按照現在的思路,再來分析一個例子
int cal(int n) {
int sum = 0;
int i = 1;
int j = 1;
for (; i <= n; ++i) {
j = 1;
for (; j <= n; ++j) {
sum = sum + i * j;
}
}
}
當前代碼的第2,3,4行,都會執行一次,這個執行一次的時間叫做unit_time,第5,6行是個回圈,它會回圈n次,即執行的就是2n*unit_time,第7,8行也是個回圈,那么他的執行時間2n^2 * unit_time
那么該程式執行的時間效率為(時間復雜度):T(n) = (2nunit_time+2n^2 * unit_time)+(3unit_time)轉化一下(2n^2 + 2n+3)*unit_time.
根據上面兩個例子的推導,我們雖然不知道unit_time,但是可以發現一個規律,就是所有代碼的執行時間 T(n) 與每行代碼的執行次數 f(n) 成正比,
大O表示法
在第一個例子中的 T(n) = O(2n+2),在第二個例子中的 T(n) = O(2n2+2n+3),這就是大 O 時間復雜度表示法,
大 O 時間復雜度實際上并不具體表示代碼真正的執行時間,而是表示代碼執行時間隨資料規模增長的變化趨勢,所以,也叫作漸進時間復雜度(asymptotic time complexity),簡稱時間復雜度,
大O的法則
獲取最大量級復雜度(一段代碼)
只關注回圈執行次數最多的一段代碼
加法法則(只有一種資料規模)
只關注回圈執行次數最多的一段代碼
加法法則(兩種或者多種資料規模)
需要將兩種或者多種復雜度量級相加(即O(m+n+...)),如下例子
int cal(int m, int n) {
int sum_1 = 0;
int i = 1;
for (; i < m; ++i) {
sum_1 = sum_1 + i;
}
int sum_2 = 0;
int j = 1;
for (; j < n; ++j) {
sum_2 = sum_2 + j;
}
return sum_1 + sum_2;
}
乘法法則
嵌套代碼的復雜度等于嵌套內外代碼復雜度的乘積
常見的復雜度量級
多項式階
隨著資料規模的增長,演算法的執行時間和空間占用,按照多項式的比例增長,包括,O(1)(常數階)、O(logn)(對數階)、O(n)(線性階)、O(nlogn)(線性對數階)、O(n^2) (平方階)、O(n^3) (立方階)
非多項式階
隨著資料規模的增長,演算法的執行時間和空間占用暴增,這類演算法性能極差,包括,O(2^n)(指數階)、O(n!)(階乘階)
幾種量級的復雜度執行效率圖
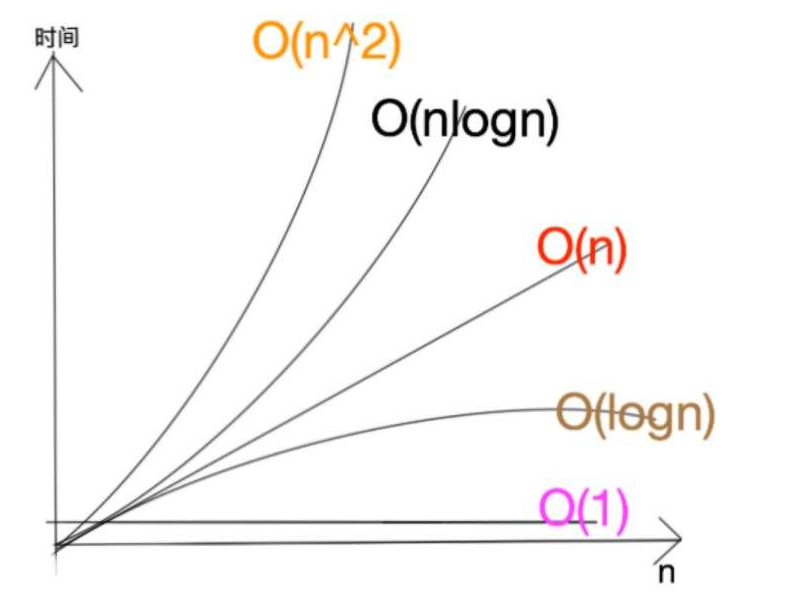
空間復雜度
表示演算法的存盤空間與資料規模之間的增長關系(就是指代碼執行時所占用空間的關系)
void print(int n) {
int i = 0;
int[] a = new int[n];
for (i; i <n; ++i) {
a[i] = i * i;
}
for (i = n-1; i >= 0; --i) {
print out a[i]
}
}
跟時間復雜度分析一樣,我們可以看到,第 2 行代碼中,我們申請了一個空間存盤變數 i,但是它是常量階的,跟資料規模 n 沒有關系,所以我們可以忽略,
第 3 行申請了一個大小為 n 的 int 型別陣列,除此之外,剩下的代碼都沒有占用更多的空間,所以整段代碼的空間復雜度就是 O(n),
我們常見的空間復雜度就是 O(1)、O(n)、O(n2 ),像 O(logn)、O(nlogn) 這樣的對數階復雜度平時都用不到,
而且,空間復雜度分析比時間復雜度分析要簡單很多,所以,對于空間復雜度,掌握剛我說的這些內容已經足夠了,
最好情況時間復雜度
指的是在理想狀態下代碼執行的復雜度,例子
// n表示陣列array的長度
int find(int[] array, int n, int x) {
int i = 0;
int pos = -1;
for (; i < n; ++i) {
if (array[i] == x) {
pos = i;
break;
}
}
return pos;
}
根據上面的代碼,我們可以知道當前最好情況復雜度為o(1)
最壞時間復雜度
指的是在極端狀態下代碼執行的復雜度
// n表示陣列array的長度
int find(int[] array, int n, int x) {
int i = 0;
int pos = -1;
for (; i < n; ++i) {
if (array[i] == x) {
pos = i;
break;
}
}
return pos;
}
根據上面的代碼,我們可以知道當前最壞情況復雜度為o(n)
平均時間復雜度
我們都知道,最好情況時間復雜度和最壞情況時間復雜度對應的都是極端情況下的代碼復雜度,發生的概率其實并不大,
為了更好地表示平均情況下的復雜度,我們需要引入另一個概念:平均情況時間復雜度,后面我簡稱為平均時間復雜度,
如下例子
// n表示陣列array的長度
int find(int[] array, int n, int x) {
int i = 0;
int pos = -1;
for (; i < n; ++i) {
if (array[i] == x) {
pos = i;
break;
}
}
return pos;
}
該平均時間情況復雜度為o(n)
最好,最壞,平均時間復雜度應用場景
只有同一塊代碼在不同的情況下,時間復雜度有量級的差距,我們才會使用這三種復雜度表示法來區分,
均攤時間復雜度(攤還分析)
就是特殊的平均情況時間復雜度分析
如下例子
// array表示一個長度為n的陣列
// 代碼中的array.length就等于n
int[] array = new int[n];
int count = 0;
void insert(int val) {
if (count == array.length) {
int sum = 0;
for (int i = 0; i < array.length; ++i) {
sum = sum + array[i];
}
array[0] = sum;
count = 1;
}
array[count] = val;
++count;
}
該均攤時間復雜度為o(1)
應用場景
對一個資料結構進行一組連續操作中,大部分情況下時間復雜度都很低,只有個別情況下時間復雜度比較高,而且這些操作之間存在前后連貫的時序關系,這個時候,我們就可以將這一組操作放在一塊兒分析,看是否能將較高時間復雜度那次操作的耗時,平攤到其他那些時間復雜度比較低的操作上,
而且,在能夠應用均攤時間復雜度分析的場合,一般均攤時間復雜度就等于最好情況時間復雜度,
學習資料結構與演算法的目的
升值加薪;夯實基礎;職業生涯能更遠一些
參考資料
- 資料結構與演算法之美
- 小學生也能看懂的時間復雜度(大概吧)
轉載請註明出處,本文鏈接:https://www.uj5u.com/qita/426394.html
標籤:其他
下一篇:中式英語之鑒讀書筆記(上)