什么是并查集
1.將n個不重復的元素( distinct elements ), 分配到幾個不相交集合( disjoint sets )的應用,
- 換句話說,一個不相交的集合(disjoint sets)是一組集合,其中任何項都不能出現在一個以上的集合中,
( A disjoint set is a group of sets where no item can be in more than one set. )
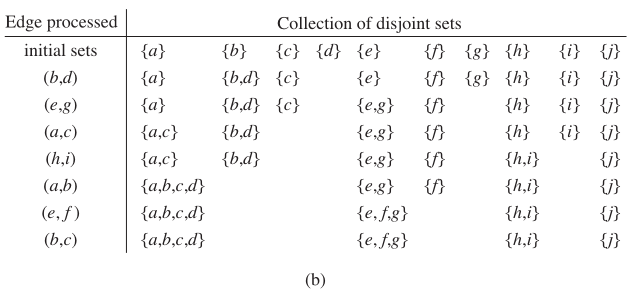
- 一般將最終得到的不相交集合稱為組件( component ).
并查集的操作規范
1.符合并查集問題的元素的一些基本特征:
- 連接沒有方向,即a連接b,等同于b連接a.( 由此此類問題只需要考慮兩個節點是否連通即可 )
- 連接具有傳遞性,a連接b,b連接c,等同于a連接c. ( 即所有連接元素處于同一個集合中或擁有同一個類別 )
2.基本操作:
MakeSet(int N); // initilize N nodes with integer names( 0 to N-1 )
void Union(int a, int b); // add connection between a and b
int Find(int a); // component identifier for p ( 0 to N-1 )
boolean Connected(int a, int b) // return true if a and b are in the same component
int Count(); // number of components
- MakeSet( int n ) 利用陣列id[ ]的整數不重復索引下標來初始化.
利用陣串列達并查集
- 因為并查集的每個元素都是不重復的( distinct element ),所以總是可以利用陣列下標[ index ]為整數且互不重復的特性來表達其元素標識( element identifier ).
- 而每個陣列元素對應的值(value)用來表示其元素所在組件標識( component identifier ),其初始化值由其對應的下標來賦值. ( id[ index ] = index )
- [ index ] => element identifier, id[ index ] => component identifier.
vector<int> id; // 用來獲取組件標識(component identifier)
int Count; // 組件數量
MakeSet(int n){
Count = n;
id(n);
for(int i = 0; i < n; i++)
id[i] = i;
}
- boolean Connected( int a, int b ) 判定節點a和b是否擁有同一component index( 即是否處于同一集合中 ).
boolean Connected(int a, int b){
return find(a) == find(b);
}
- int Count() 以獨立節點個數n初始化component的個數,每進行一次Union()操作,將component的個數減1.
int count(){
return Count;
}
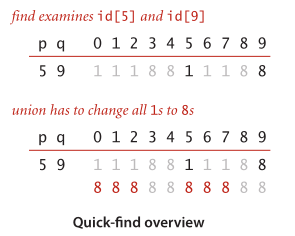
基于快速查詢( Quick-Find )下的Find()與Union()操作實作
1.通過陣列id[ ]獲取節點的速度將非常快速.
- int Find(int a) 找到節點a所在component的component identifier.
int Find(int a){
return id[a];
}
- void Union(int a ,int b) 將a所在集合中的所有同類合并到b的集合中.
void Union(int a ,int b){
// 找得到a和b的對應component identifier
int aID = find(a);
int bID = find(b);
// 如何索引值相等,說明在同一集合中,直接回傳
if(aID == bID) return;
// 否則將b的索引值賦值給a(即將a合并b所在的集合名稱下)
for(int i = 0; i < id.size(); ++i)
if (id[i] == aID) id[i] == bID;
Count--;
}
Quick-Find 的缺點
- 將a所在component中的所有元素合并到b中,涉及到對陣列id[ ]值的修改操作.
- 意味著需要對id[ ]陣列進行遍歷,意味著時間復雜度將幾何增加 O(n^2).
基于快速合并( Quick-Union )下的Find()與Union()操作實作
1.為了降低組數修改操作帶來的時間復雜度增加,將使用并查集森林( Disjoint-Set Forests )形式來表達.
依然基于陣列結構(id[ ])下的抽象解釋
- 該結構(Disjoint-Set Forests)意味著id[ ]將采用樹( tree )結構,并使用parent-link運算式.
- 雖然初始化資料依然采用陣列,但可以將每個組數元素其想象成獨立節點.
- 每個陣列元素剛初始化時,其對應component里只有它自己一個元素,所以其向父節點的連接( parent-link )指向它自己( self-link )或Null.
- 每個component擁有其唯一的根節點 ( root ),其父節點是它自己或Null.
- 利用根節點的唯一性,該component的component identifier使用root節點所對應值.
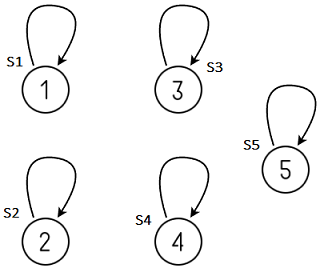
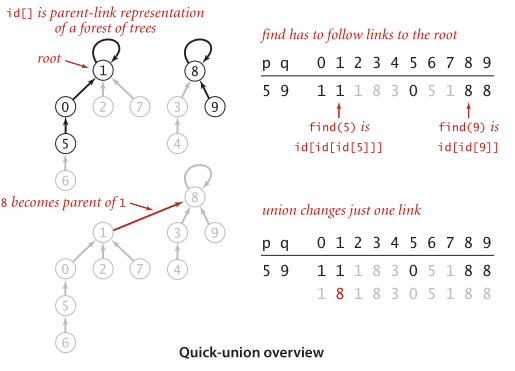
- int Find(int a) 與Quick-Find中的id[ index ]作為compnont identifier不同,這里的id[ index ]可以理解為[ index ]的聯通路徑(father identifier).
- 如同一根帶箭頭的線段,雖然在實際應用中常常省略,因為最終都會連向根節點.
int Find(int a){
while(a != id[a]) a = id[a]; // 沿父節點攀爬,直到根節點
return a;
}
- void Union(int a ,int b) 將a的根節點指向b的根節點 (即合并后的集合根節點為b,其值作為component identifier).
void Union(int a ,int b){
int aRoot = Find(a);
int bRoot = Find(b);
if(aRoot == bRoot) return;
id[aRoot] = bRoot; // 將a的根節點,本來是指向自己的箭頭,指向了b的根節點
Count --;
2.Find()在Quick-Union中扮演著重要角色.
- 可以看到,雖然Quick-Union不用遍歷陣列,但是Find()中的向父節點攀爬程序,如果遇到最壞的情況,即鏈式結構,其時間復雜度也接近于遍歷.
- 并且Union()和Connect()中都會使用到Find(),所以其總的時間復雜度由Find()起到決定作用,而Find()的復雜度又由樹結構的高度( height )所影響.
衡量樹的名詞定義
- 大小( size ): 表示一棵樹含有節點的總數.
- 深度( depth ): 表示一個節點到其根節點所進過的連接路徑總數.
- 高度( height ): 表示一棵樹其中節點深度的最大值.
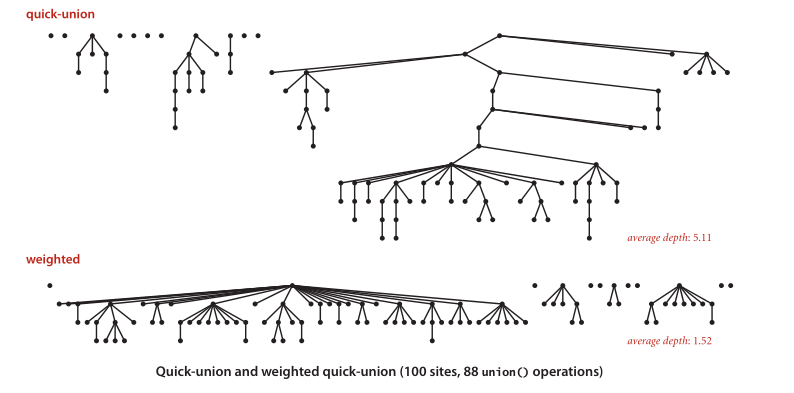
提高1:在Union()階段按rank或者size優化的Weighted Quick-Union
1.維護另一個陣列來追蹤樹的大小,在合并時,總是將較小的樹合并到較大的樹中去,以此來平衡整個樹的高度( height ).
- 初始化時增加維護樹大小的陣列sz[ ],并將其初始化.
vector<int> sz; // size of component for roots
MakeSet(int n){
sz(n);
for(int i = 0; i < n ; ++i) sz[i] = 1;
}
- 在合并時,將size較小的樹合并到較大中去,并將兩者size的相加計入到大樹中.
void Union(int a ,int b){
int aRoot = Find(a);
int bRoot = Find(b);
if(aRoot == bRoot) return;
if(sz[aRoot] < sz[bRoot]){
id[aRoot] = bRoot;
sz[bRoot] += sz[aRoot];
}
else {
id[bRoot] = aRoot;
sz[aRoot] += sz[bRoot];
}
Count --;
}
提高2: 在Find()階段使用路徑壓縮(Path Compression)優化的Weighted Quick-Union
1.不完全壓縮:讓查詢程序中經歷的"部分結點"指向它的父親結點的父親結點,相對于「完全壓縮」而言,壓縮沒有那么徹底,
- 只需要在Weighted Quick-Union的Find()中增加一行代碼即可.
int Find(int a){
while(a != id[a]){
id[a] = id[id[a]];
a = id[a];
}
return a;
}
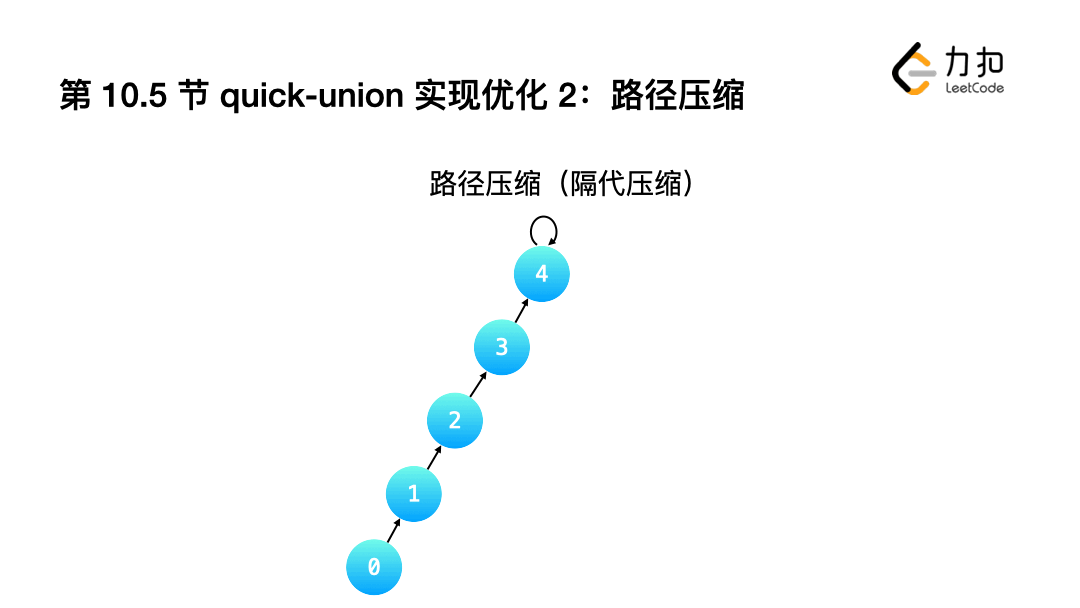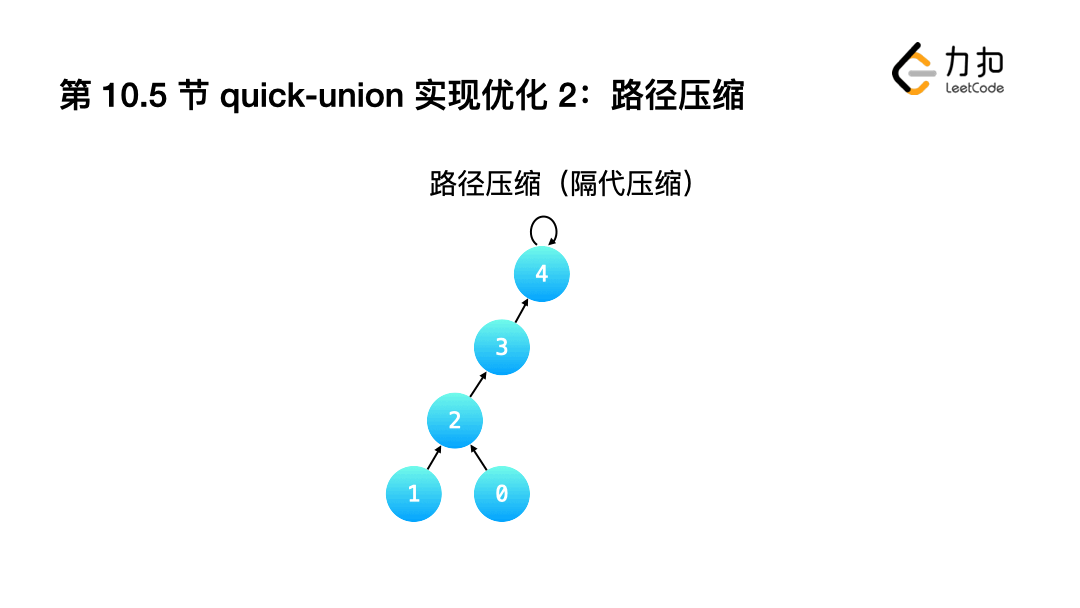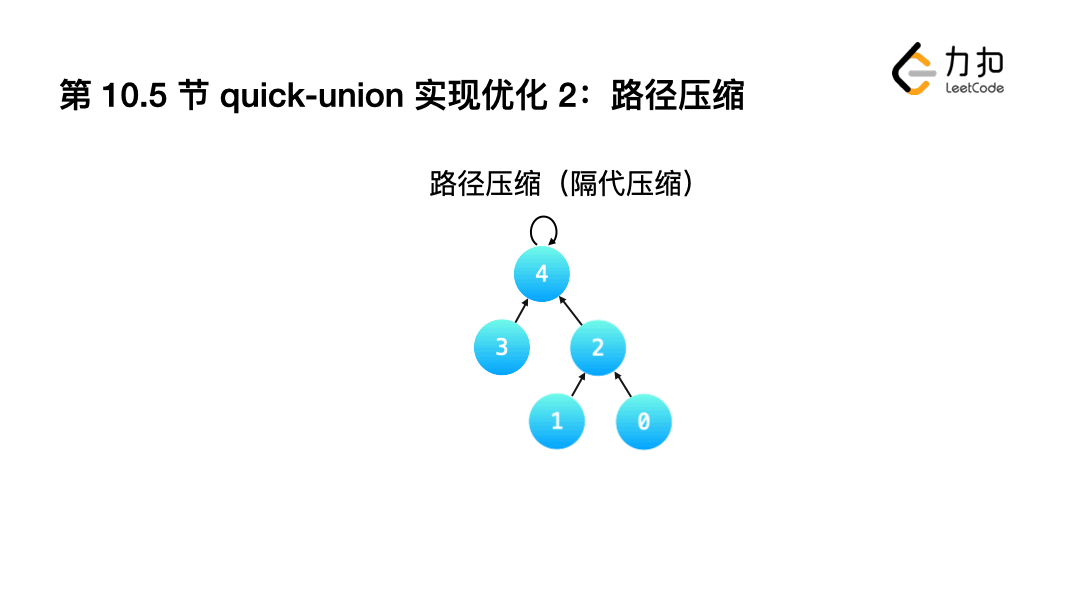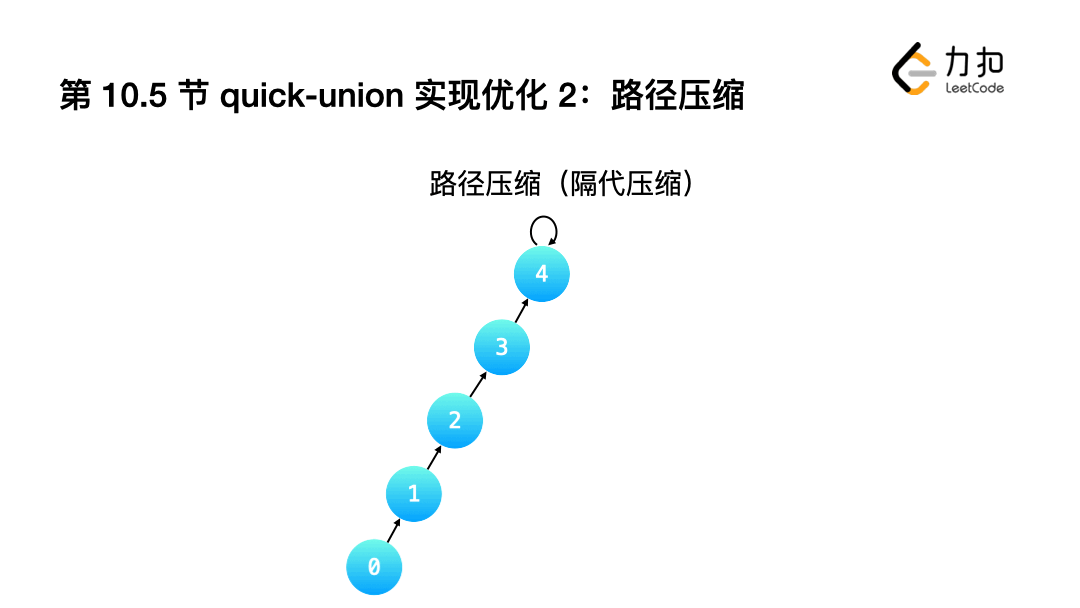
2.完全壓縮: 讓查詢根結點的程序中,沿途經過的"所有結點"指向都指向根結點.
int Find(int a){
if(a != id[a]){
id[a] = Find(id[a]);
}
return id[a];
}
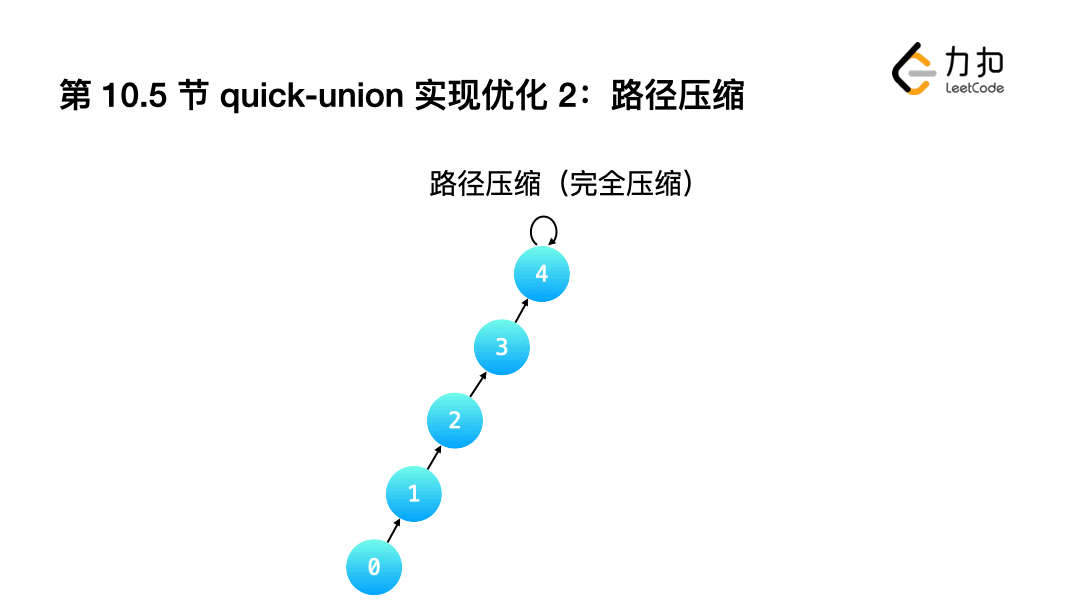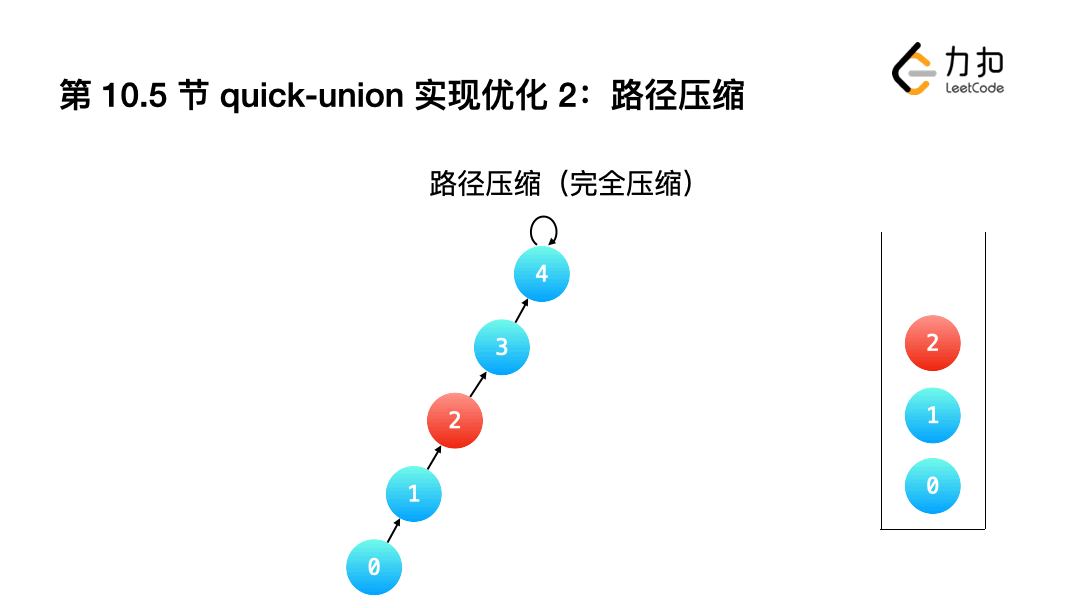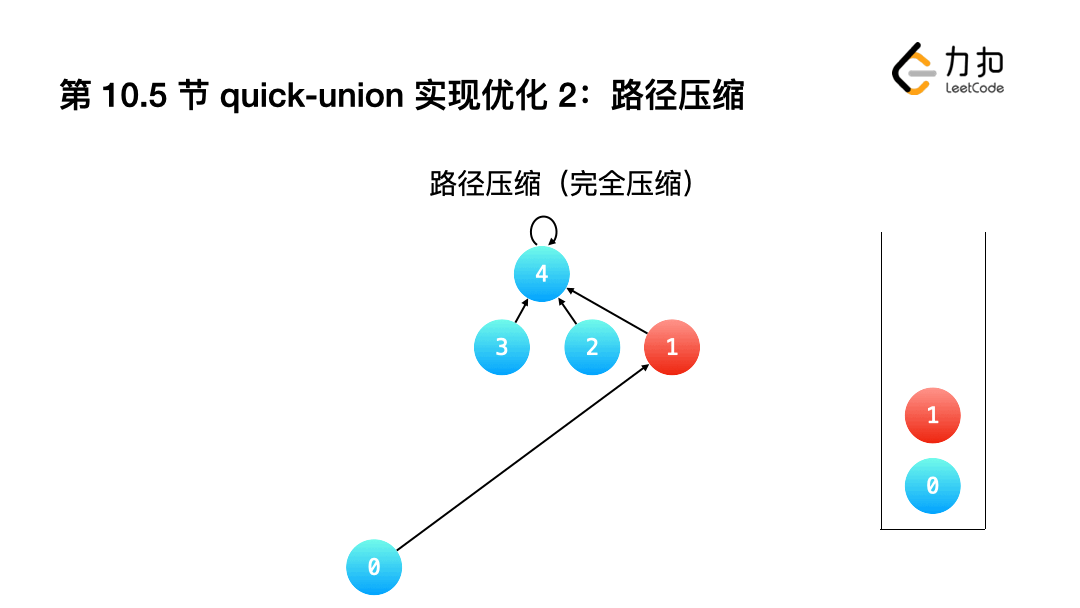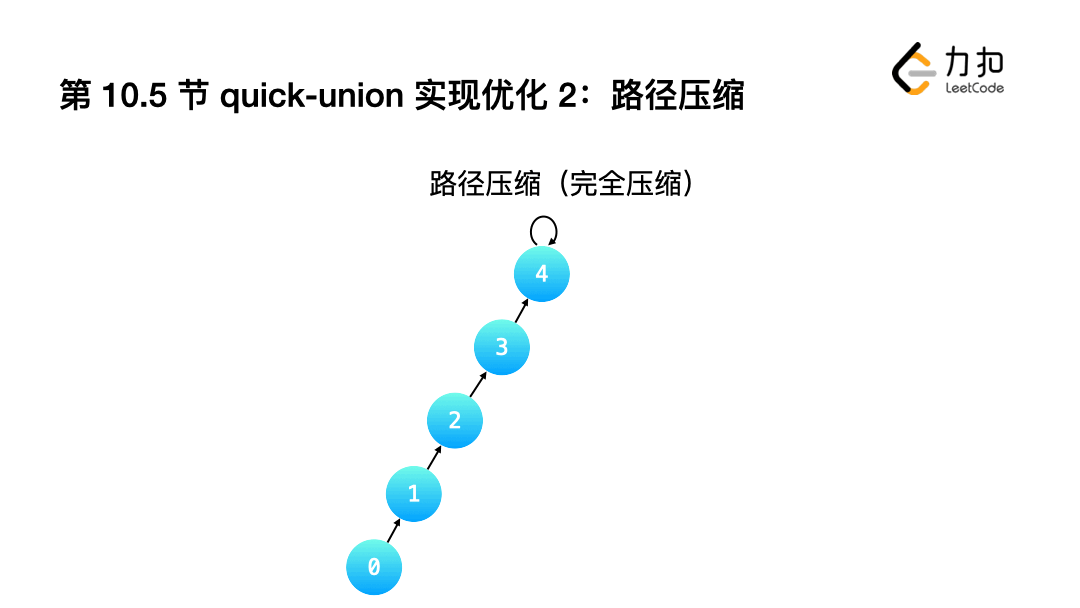
小結
1.各方法時間復雜度分析:
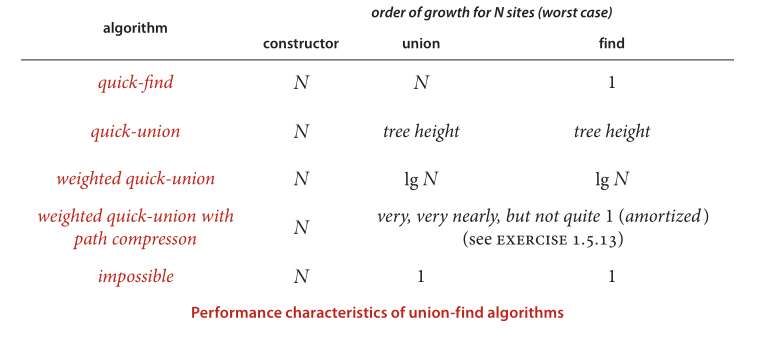
- 在實際大型問題應用中,Weighted Quick-Union with Path Compression(不完全壓縮)非常接近線性時間復雜度,因此成為常用的優化方法.
寫在最后
- 作為初學者,我以為演算法的學習還是應該以思維訓練為主,以此來加深對編程思想的理解.如果僅僅只是當做一個manual來套路化、模板化的使用,雖然能快速入門,不過應該是很難走更遠的.
- 寫這篇文章之前我在leecode上,google上,看了諸多博主寫的關于并查集的文章后. 初衷是想走捷徑,快速掌握,不過在實際問題應用分析時,卻發現有許多不易察覺的細節難以把控.
- 思來想去還是覺得沒有從根上去理解整個演算法的核心思想,于是又回到《演算法第四版》經典書籍的學習中,搭建起骨架,在遇到難以理解的細節分支,再去google上尋找后來人的各種解讀,從而加深理解.
- 經典書籍只所以經典,是因為其經歷了時間的考驗,其整個思維體系的完整性是一般創作者難以企及的.
主要參考資料
- 《演算法第四版》第 1 章第 5 節.
- Leecode 《零起步學演算法》.
轉載請註明出處,本文鏈接:https://www.uj5u.com/qita/426409.html
標籤:其他