大家好,我是代碼搬運工,最近在利用FlinkSQL進行開發連接Hive資料庫的時候遇到了一些小問題,接下來分享給大家以免以后踩坑,
在一個專案中我主要利用FlinkSQL來連接Hive資料庫并執行Insert動態插入陳述句來關聯設備資訊,話不多說我們直接開始,
maven的依賴如下
<dependency>
<groupId>org.slf4j</groupId>
<artifactId>slf4j-log4j12</artifactId>
<version>1.7.15</version>
</dependency>
<!--FLinkSQL依賴-->
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-table-api-java-bridge_2.12</artifactId>
<version>1.12.2</version>
</dependency>
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-table-api-java</artifactId>
<version>${flink.version}</version>
</dependency>
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-table-common</artifactId>
<version>${flink.version}</version>
</dependency>
<!-- flink table包 -->
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-connector-hive_2.12</artifactId>
<version>${flink.version}</version>
</dependency>
<!-- Hive Dependency -->
<!--<dependency>
<groupId>org.apache.hive</groupId>
<artifactId>hive-exec</artifactId>
<version>2.3.2</version>
</dependency>-->
<!--hadoop -->
<dependency>
<groupId>org.apache.hadoop</groupId>
<artifactId>hadoop-common</artifactId>
<version>2.8.1</version>
</dependency>
<!--Hive-->
<dependency>
<groupId>javax.xml.bind</groupId>
<artifactId>jaxb-api</artifactId>
<version>2.2.11</version>
</dependency>
<dependency>
<groupId>org.apache.hive</groupId>
<artifactId>hive-exec</artifactId>
<version>3.1.2</version>
<exclusions>
<exclusion>
<artifactId>log4j-api</artifactId>
<groupId>org.apache.logging.log4j</groupId>
</exclusion>
<exclusion>
<artifactId>log4j</artifactId>
<groupId>log4j</groupId>
</exclusion>
<exclusion>
<artifactId>log4j-core</artifactId>
<groupId>org.apache.logging.log4j</groupId>
</exclusion>
<exclusion>
<artifactId>log4j-slf4j-impl</artifactId>
<groupId>org.apache.logging.log4j</groupId>
</exclusion>
<exclusion>
<artifactId>slf4j-api</artifactId>
<groupId>org.slf4j</groupId>
</exclusion>
</exclusions>
</dependency>
<dependency>
<groupId>org.apache.hive</groupId>
<artifactId>hive-serde</artifactId>
<version>${hive.version}</version>
<exclusions>
<exclusion>
<artifactId>log4j-api</artifactId>
<groupId>org.apache.logging.log4j</groupId>
</exclusion>
<exclusion>
<artifactId>log4j-core</artifactId>
<groupId>org.apache.logging.log4j</groupId>
</exclusion>
<exclusion>
<artifactId>log4j-slf4j-impl</artifactId>
<groupId>org.apache.logging.log4j</groupId>
</exclusion>
<exclusion>
<artifactId>slf4j-api</artifactId>
<groupId>org.slf4j</groupId>
</exclusion>
</exclusions>
</dependency>
<dependency>
<groupId>org.apache.hive</groupId>
<artifactId>hive-jdbc</artifactId>
<version>${hive.version}</version>
<exclusions>
<exclusion>
<artifactId>slf4j-log4j12</artifactId>
<groupId>org.slf4j</groupId>
</exclusion>
<exclusion>
<artifactId>log4j-slf4j-impl</artifactId>
<groupId>org.apache.logging.log4j</groupId>
</exclusion>
<exclusion>
<artifactId>log4j-web</artifactId>
<groupId>org.apache.logging.log4j</groupId>
</exclusion>
<exclusion>
<artifactId>log4j-core</artifactId>
<groupId>org.apache.logging.log4j</groupId>
</exclusion>
<exclusion>
<artifactId>log4j-api</artifactId>
<groupId>org.apache.logging.log4j</groupId>
</exclusion>
<exclusion>
<artifactId>log4j-1.2-api</artifactId>
<groupId>org.apache.logging.log4j</groupId>
</exclusion>
<exclusion>
<artifactId>netty-all</artifactId>
<groupId>io.netty</groupId>
</exclusion>
<exclusion>
<artifactId>hive-common</artifactId>
<groupId>org.apache.hive</groupId>
</exclusion>
<exclusion>
<artifactId>parquet-hadoop-bundle</artifactId>
<groupId>org.apache.parquet</groupId>
</exclusion>
<exclusion>
<groupId>xerces</groupId>
<artifactId>xercesImpl</artifactId>
</exclusion>
<exclusion>
<artifactId>hbase-client</artifactId>
<groupId>org.apache.hbase</groupId>
</exclusion>
<exclusion>
<artifactId>curator-framework</artifactId>
<groupId>org.apache.curator</groupId>
</exclusion>
<exclusion>
<artifactId>zookeeper</artifactId>
<groupId>org.apache.zookeeper</groupId>
</exclusion>
<exclusion>
<artifactId>slf4j-api</artifactId>
<groupId>org.slf4j</groupId>
</exclusion>
<exclusion>
<artifactId>httpcore</artifactId>
<groupId>org.apache.httpcomponents</groupId>
</exclusion>
<exclusion>
<artifactId>httpclient</artifactId>
<groupId>org.apache.httpcomponents</groupId>
</exclusion>
<exclusion>
<artifactId>commons-cli</artifactId>
<groupId>commons-cli</groupId>
</exclusion>
<exclusion>
<artifactId>commons-compress</artifactId>
<groupId>org.apache.commons</groupId>
</exclusion>
<exclusion>
<artifactId>commons-lang</artifactId>
<groupId>commons-lang</groupId>
</exclusion>
<exclusion>
<artifactId>guava</artifactId>
<groupId>com.google.guava</groupId>
</exclusion>
<exclusion>
<artifactId>gson</artifactId>
<groupId>com.google.code.gson</groupId>
</exclusion>
<exclusion>
<artifactId>avro</artifactId>
<groupId>org.apache.avro</groupId>
</exclusion>
<exclusion>
<artifactId>hbase-common</artifactId>
<groupId>org.apache.hbase</groupId>
</exclusion>
<exclusion>
<artifactId>hbase-hadoop2-compat</artifactId>
<groupId>org.apache.hbase</groupId>
</exclusion>
<exclusion>
<artifactId>hbase-server</artifactId>
<groupId>org.apache.hbase</groupId>
</exclusion>
<exclusion>
<artifactId>tephra-hbase-compat-1.0</artifactId>
<groupId>co.cask.tephra</groupId>
</exclusion>
<exclusion>
<artifactId>hbase-hadoop-compat</artifactId>
<groupId>org.apache.hbase</groupId>
</exclusion>
<exclusion>
<artifactId>log4j</artifactId>
<groupId>log4j</groupId>
</exclusion>
</exclusions>
</dependency>
</dependencies>
1.首先我們先用FlinkSQL連接Hive
!注意,這里我們要使用阿里的Blanner 我在這里踩了巨坑,一定要用阿里的Blanner才可以執行動態insert
因為Flink是流式處理,
如果我們構建table的環境是流式環境的話,資料是源源不斷得輸入進來,如下所示
// 構建運行流處理的運行環境
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
// 構建table環境
StreamTableEnvironment tableEnv = StreamTableEnvironment.create(env);
這樣的話我們執行動態操作的時候,例如 Insert intoXXXX Select * from XXX等陳述句是會報錯誤的,Hive Table SInk是不支持這樣的,
我們查看原始碼可知,
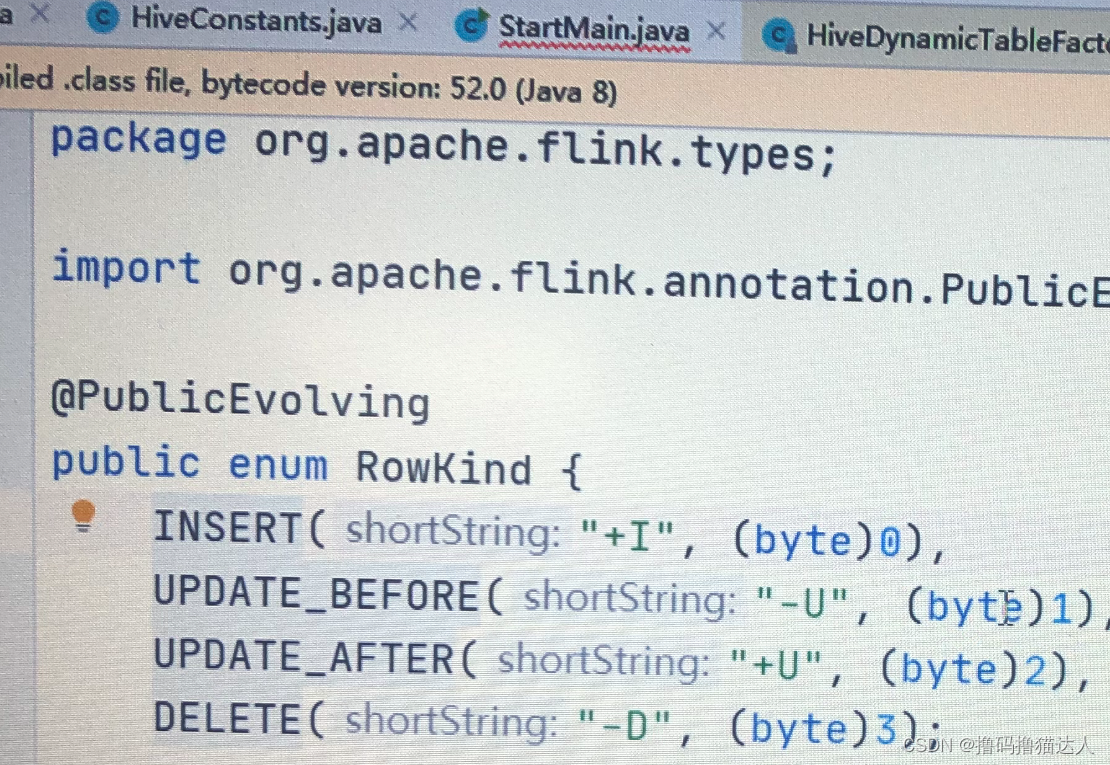
Hive Table的INSERT只支持帶有"+I"的資料,不允許帶有-U和+U就是會改變的資料,
那怎么解決呢,不可能我想寫個動態sql都不行吧,暈,,,,,
還好國內阿里進行了FlinkSQL優化,解決方法是利用阿里的BlinkPlanner來構建表環境,阿里已經內部幫你優化好了,
//使用阿里的Planner
EnvironmentSettings settings = EnvironmentSettings.newInstance().useBlinkPlanner().inBatchMode().build();
// 構建table環境
TableEnvironment tableEnv = TableEnvironment.create(settings);
//TODO 設定env的checkpoint等其他資訊
//設定方言 不同資料庫的陳述句有差別
tableEnv.getConfig().setSqlDialect(SqlDialect.HIVE);
2.HiveCatalog連接Hive
構建好表環境后我們直接利用HiveCatalog來連接Hive資料庫(里面我只是舉例子,公司里一般寫在常量里,直接呼叫就行,在公司這樣寫代碼不被罵死我都服你)
//構造hive catalog 直接呼叫hiveconstans就可以
// Catalog名稱,定義一個唯一的名稱表示
String NAME="myhive";
// 默認Hive資料庫名稱
String DEFAULTDATABASE="lwtest";
//hive-site.xml路徑 運行Flink的Linux目錄下
String HIVECONFDIRPATH="/etc/hive/conf";
//hive版本
String VERSION="3.1.2";
HiveCatalog myHive=new HiveCatalog(NAME, DEFAULTDATABASE,HIVECONFDIRPATH, VERSION);
//注冊指定名字的catalog
tableEnv.registerCatalog("myhive",myHive);
//使用上面注冊的catalog
tableEnv.useCatalog("myhive");
3.撰寫sql
然后我們就可以寫自己的sql代碼啦
//執行邏輯
Table tableResult = tableEnv.sqlQuery(sql);
//獲取的結果直接列印
tableResult1.execute().print();
//獲取結果的迭代器,可以回圈迭代器獲取結果
CloseableIterator<Row> rows = tableResult.execute().collect();
//利用executeSql執行插入更新代碼
//例如insert into table xxxx select * from xxxx;
TableResult tableResult1 = tableEnv.executeSql(sql);
呼叫executeSql不需要呼叫execute,如果里面有datastream api就需要execute
完整代碼如下
//使用阿里的Planner
EnvironmentSettings settings = EnvironmentSettings.newInstance().useBlinkPlanner().inBatchMode().build();
// 構建table環境
TableEnvironment tableEnv = TableEnvironment.create(settings);
//TODO 設定env的checkpoint等其他資訊
//設定方言 不同資料庫的陳述句有差別
tableEnv.getConfig().setSqlDialect(SqlDialect.HIVE);
//構造hive catalog 直接呼叫hiveconstans就可以
// Catalog名稱,定義一個唯一的名稱表示
String NAME="myhive";
// 默認Hive資料庫名稱
String DEFAULTDATABASE="lwtest";
//hive-site.xml路徑 運行Flink的Linux目錄下
String HIVECONFDIRPATH="/etc/hive/conf";
//hive版本
String VERSION="3.1.2";
HiveCatalog myHive=new HiveCatalog(NAME, DEFAULTDATABASE,HIVECONFDIRPATH, VERSION);
//注冊指定名字的catalog
tableEnv.registerCatalog("myhive",myHive);
//使用上面注冊的catalog
tableEnv.useCatalog("myhive");
// 執行邏輯
String sql="select * from xxxx";
Table tableResult1 = tableEnv.sqlQuery(sql);
tableResult1.execute().print();
//獲取結果的迭代器,可以回圈迭代器獲取結果
CloseableIterator<Row> rows = tableResult1.execute().collect();
//執行executeSql 插入或更新資料庫
String executeSql="insert into table xxxx select * from xxxx";
TableResult tableResult6 = tableEnv.executeSql(executeSql);
轉載請註明出處,本文鏈接:https://www.uj5u.com/qita/426522.html
標籤:其他